 聲智科技全球首發新一代人機交互框架
聲智科技全球首發新一代人機交互框架

全球人工智能產業正經歷人機交互范式升級。過去兩個月中,以OpenAI、Meta為代表的行業領軍企業加速推進交互技術創新迭代,推動產業進入關鍵變革期。值得關注的是,a16z合伙人Olivia Moore與Anish Acharya在深度訪談中系統闡釋了"語音交互將成為AI應用最具突破潛力的核心接口"這一戰略判斷,明確指出在消費級市場,語音交互極可能發展為用戶接觸AI系統的首要觸點,甚至演進為主導型交互模態。
作為聲學計算與人機交互領域的深耕者,聲智科技自創立以來始終致力于聲學計算與人機交互核心技術研發。在AIoT發展初期階段,公司即構建起具備行業領先性的人機交互技術架構,成功賦能智能音箱、攝像頭等終端設備實現語音交互功能,形成"技術前瞻布局-產品快速迭代-市場精準適配"的良性發展模式。
在全球化AI技術競速背景下,聲智科技率先取得革命性突破。2025年5月正式發布了創新性論文《面向真實世界人機交互的非線性聲學計算與強化學習協同框架》。
論文題目:A Synergistic Framework of Nonlinear Acoustic Computing and Reinforcement Learning for Real-World Human-Robot Interaction
代碼鏈接:?https://github.com/soundai2016/nonlinear-acoustic-rl-hri
論文鏈接:https://arxiv.org/abs/2505.01998
論文首次提出與國際標準接軌的新一代真實世界人機交互框架,并同步公布全棧算法的測試數據,多項指標均處于業界領先水平。
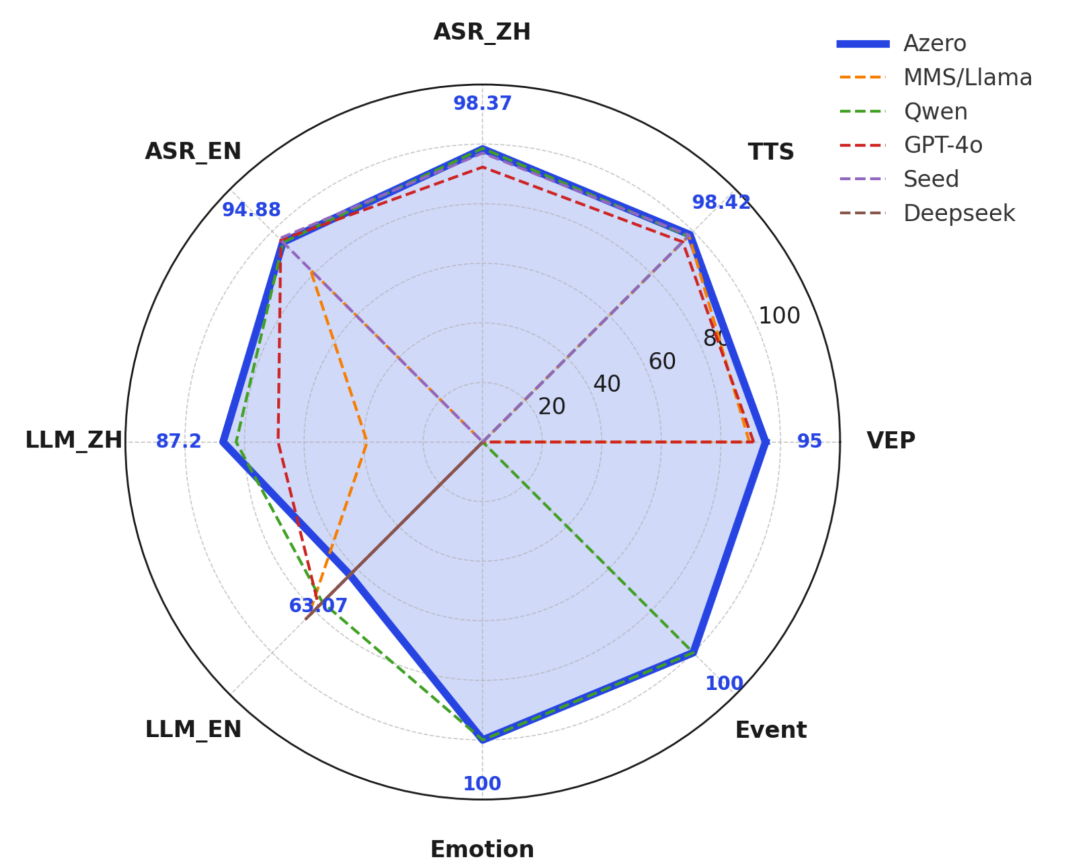
以上數據來源于公開論文,對 Azero、MMS/Llama、Qwen、GPT-4o、Seed 和 Deepseek 六家公司的系列模型在八項關鍵指標(語音增強模型VEP、語音克隆模型TTS、語音識別中文模型ASR_ZH、語音識別英文模型ASR_EN、語言模型中文能力LLM_ZH、語言模型英文能力LLM_EN、聲音情感識別模型Emotion、聲學事件識別模型Event)上的統一測評,結果顯示 Azero 以信號藍粗實線突出其卓越表現:在聲學語音增強(VEP 95)和語音克隆合成質量(TTS 98.42)上穩居榜首,中英文識別準確率分別達到 98.37% 和 94.88%,中文理解能力 87.2 分優于多數競品;值得一提的是,Azero 兼具實時的聲音情感和聲學事件識別能力,充分證明了其在遠場聲學、語音克隆、多語交互及語言理解上的全棧算法與領先實力。
該研究突破傳統線性聲學模型限制,通過非線性計算與強化學習的協同優化,成功實現復雜場景下的自適應交互能力,為"AI融入真實世界(Real World Experience)"戰略目標提供了關鍵技術支撐。在持續深化技術布局的同時,聲智著力構建基于聽覺感知的入口級技術,致力于打造具備真實場景理解能力的人機交互架構,為下一代AI應用產品落地提供底層技術架構支持,推動人機交互從"被動接收"向"主動感知"的跨越式發展。
全場景語音識別:
暢通真實世界的"溝通橋梁"
聲智科技在聲學信號處理領域的突破,本質上是對"復雜環境聽覺能力"的革命性重構。
噪聲抑制:
從 "可聽" 到 "聽清" 的質變跨越
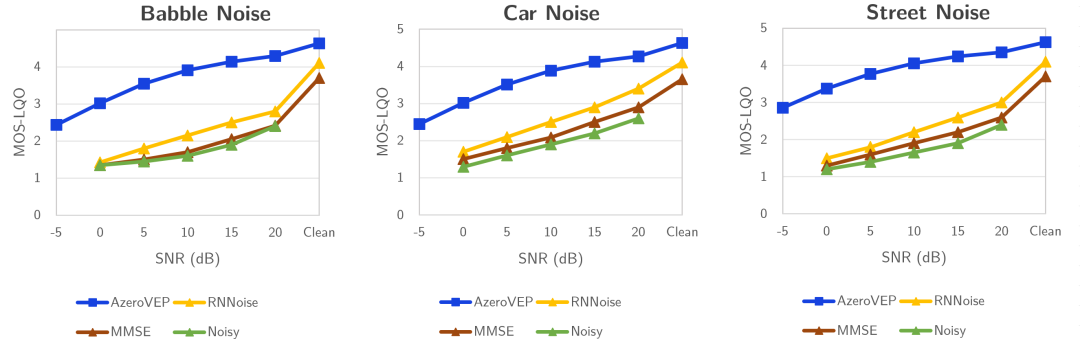
在對聲音降噪算法進行深入分析時,通常會在多種信噪比(SNR)條件下進行系統測試——從極端低信噪比(如–5dB的強噪環境)到高信噪比(如20dB的低噪環境),并結合多種評測指標(如PESQ、MOS-LQO、STOI、SDR等)來全面量化算法在不同噪聲強度與類型(白噪、Babble噪聲、交通噪聲、街道噪聲等)下的性能表現。通過對比各個SNR點上的語音清晰度、可懂度和音質恢復效果,可以直觀地評估算法的低信噪比魯棒性、高信噪比分辨力以及對多場景噪聲的普適適應能力。
在極端噪聲環境下,聲智噪聲分離模型可實現信噪比提升,首次在超高頻噪聲場景中實現"噪聲隔離級"清晰語音還原。
以下是聲智Azero算法在本次測試中展現的兩大核心優勢特性。
一是極低信噪比魯棒性,在-5dB極低信噪比噪聲環境下,僅有Azero算法能夠處理 ,并且性能表現良好,具有更好的魯棒性和實時性。
二是多場景普適性,在Babble Noise、 Car Noise、Street Noise 等真實場景中,降噪性能均大幅領先海外降噪技術評測結果(詳見下圖藍色線條),且對噪聲類型的識別范圍更寬泛、在極低信噪比的惡劣環境下仍能進行高清晰度的人聲增強,真正實現"地鐵喧嘩中聽清耳語,鬧市街頭精準拾音"。
聲音克隆:
音色相似度與合成準確率評測雙登頂
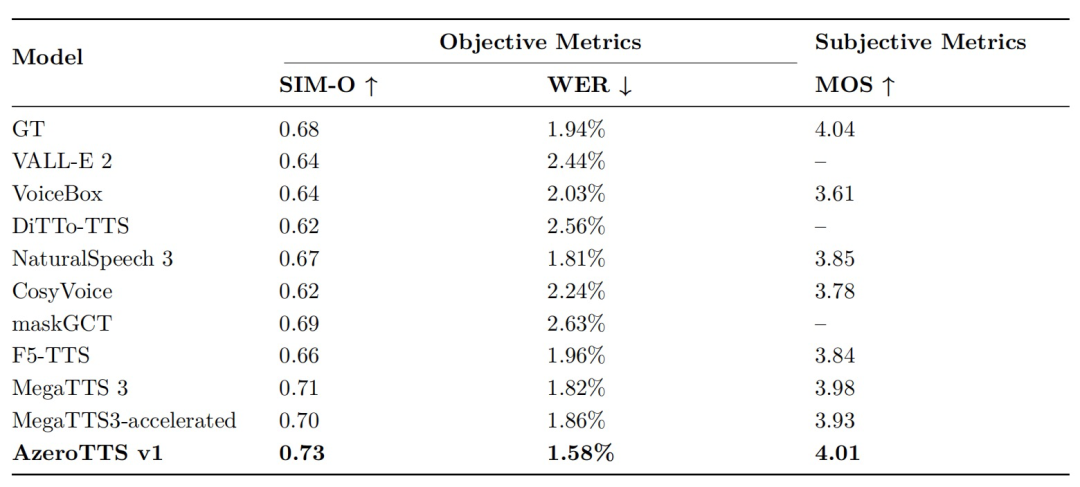
在聲音克隆技術中,AzeroTTS的SIM-O音色相似度達0.73,詞錯率WER低至1.58%,MOS自然度評分4.01,等同于真實語音。對比LibriSpeech數據集,其內容準確率超越VALL-E2、VoiceBox等國際頂尖模型,在低成本的真實環境下能夠實現"音色復刻如臨其境,內容還原分毫不差"。自創始以來,聲智科技十分注重面向真實場景的用戶服務落地,聲音克隆技術目前已在聲智APP上線,面向全球用戶不斷提升體驗感。
情感感知:
實時捕捉人類情緒的"第六感官"
在強噪聲環境下,可精準區分多種聲音情感及400+聲學環境事件(如爆竹聲、引擎轟鳴聲、嬰兒笑聲)。即使在車水馬龍的街頭,也能通過語音語調變化捕捉用戶的細微情緒,為智能設備賦予超強"共情力"。
毫秒級響應:
構建低延遲交互基石
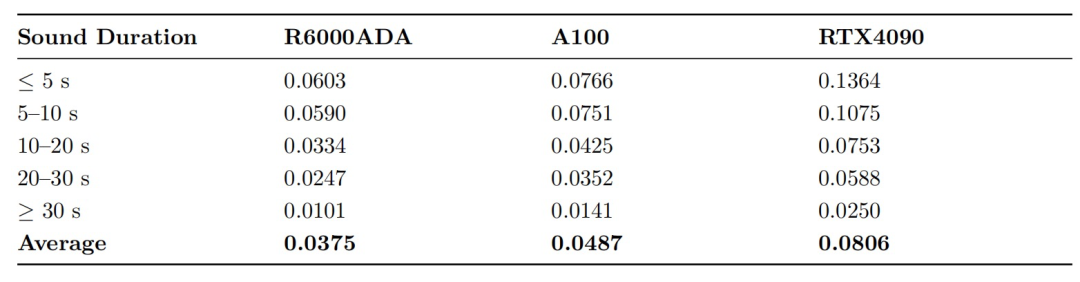
通過波束成形與殘差網絡優化,在RTX6000Ada平臺上,平均RTF低至0.0375(A100為0.0487,RTX4090為0.0806),即使在30秒以上長音頻處理中,RTF僅0.0101,真正滿足實時通話、直播降噪等毫秒級延遲敏感場景需求。
全場景語音識別:
暢通真實世界的"溝通橋梁"
聲智的語音技術優勢,不僅在于"聽得清",更在于"聽得準""聽得懂"。
復雜噪聲精準識別:
準確率超越OpenAI
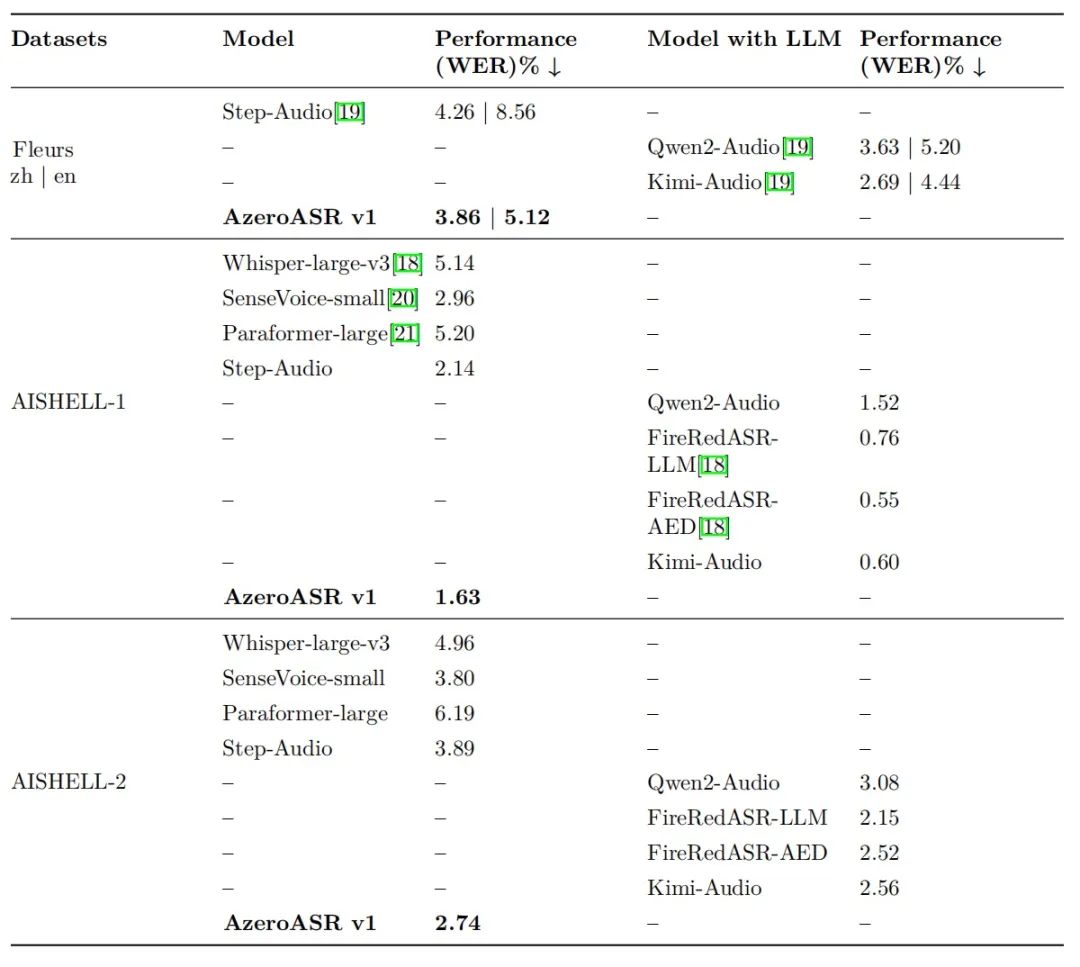
中文場景:在AISHELL-1數據集上,WER指標優于其他模型;AISHELL-2復雜場景下,領先行業平均水平。
英文場景:Fleurs數據集上WER指標測評表現優異,且不依賴大型語言模型做后處理校正,純模型原始輸出即達行業頂尖水平。
多種語言混雜識別:
真實場景21種語言識別準確率90%+
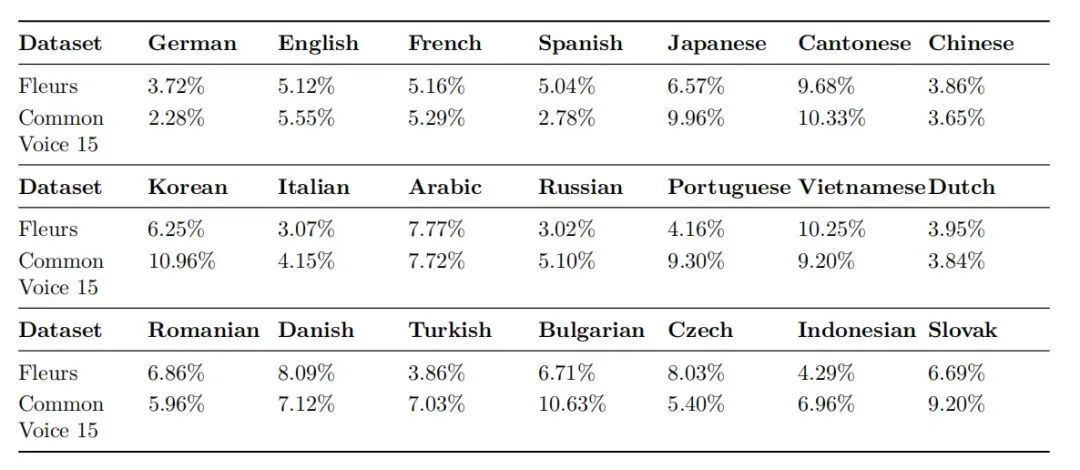
在真實語言場景下,香港、新加坡、馬來西亞等具有典型多語系特征的區域,因其獨特的語言生態對智能系統的多語交互能力提出了更高要求。這些地區涉及不同語言變體的復雜轉換——香港的粵語夾雜英語詞匯的港式表達、新加坡融合福建方言的華語形態、馬來西亞帶有馬來語元素的華文語境,都要求語言識別技術具備深度文化適應能力。
面向此種真實環境需求,聲智在Fleurs和CommonVoice兩個國際權威的多語種語音數據集上進行了全面測試,實驗結果表明,聲智的語音識別模型在不同語種下均表現出色,識別準確率穩定保持在90%以上。從歐洲小語種到亞洲地方語言,實現"一套模型,全球通聽"的跨語言識別與翻譯。
"輕量""智答"語言模型:
讓機器學會"耳腦協同"的交互藝術
在新一代人機交互的技術架構中,語言模型從"算力競賽"轉向"效能突圍"。基于聲學技術構建的底層感知系統,輕量級語言模型承擔著人機交互的"認知中樞"角色,通過精準的語義泛化、邏輯推理與意圖提煉,在低成本的算力條件下實現語音指令的高效解析與自然響應,構建貼近真實場景的交互體驗。這種"小而精"的技術路徑,使語言模型真正成為連接用戶需求與設備功能的效能樞紐,推動人機交互從"技術堆砌"向"體驗優先"轉型,為智能硬件和AI應用服務落地提供可持續的技術底座。
"小而精"技術路徑:
評測位列第一梯隊
AzeroGPT:依托數億級參數量基底,在權威榜單中表現亮眼;
C-Eval:人文社科領域、STEM領域排名靠前,超越多數語言大模型;
Livebenchcode_v5:輕量化設計使其算力需求遠低于傳統大模型,性價比優勢顯著。

從技術構想走向場景落地:
開啟主動感知人機交互新紀元
“ 在人工智能技術高速迭代的今天,當行業目光逐漸從模型參數競賽轉向真實場景價值落地,聲智科發布的人機交互框架,正以"可落地、可驗證、可生長"的技術特質,打破"實驗室技術"與"現實應用"的壁壘,讓"機器理解人類"不再停留在理論構想,而是成為觸手可及的交互體驗。聲智的 "主動感知" 框架深度錨定三大核心體驗維度:"聞聲知意,懂你所需"、"聞聲辨境,知你所求"、"聽你所言,知你所想"。聲智的技術突圍,源于對"場景價值"的深度解構,通過非線性聲學計算技術穿透復雜環境噪聲,結合強化學習構建場景化決策模型,形成"感知 - 理解 - 預測 - 優化"的閉環能力。這種"輕量架構 + 重場景適配"的設計,在智能汽車、工業機器人、智慧醫療等領域實現低成本快速部署,同時保持復雜環境指令解析準確率。
智慧生活:
設備從"聽見"到"聽懂"再到"預判需求"
在智慧生活場景下使設備具備"聽覺認知"能力,用戶可感知到設備從"被動接收指令"轉變為"主動適應場景,核心技術閉環(聲學采樣→動態優化→環境分析→精準輸出)能帶來核心生活場景革新,如通勤、辦公、居家等,從喧囂鬧市到靜謐空間,每一次聲音的處理都是"主動感知"技術的生動演繹,它正引領我們邁向面向真實世界的多場景自適應人機交互新紀元,讓智慧感知深度融入生活,重塑每一個與聲音相伴的瞬間,為生活注入更智能、更貼心的體驗。
智慧醫療健康:
個性化監測與關懷
智慧醫療健康場景正呈現"感知-解析-響應"全鏈路的突破性革新 。例如AI助聽設備可精準處理環境音,濾除干擾,動態補償個體聽覺差異,讓用戶清晰感知聲音,實現更貼心的健康關懷。當用戶發現自己的咳嗽聲能被轉化為肺炎風險指數,當帕金森患者從語音震顫分析中獲得黃金干預期,當地方方言不再成為醫患溝通壁壘,語音交互已超越工具屬性,成為貫穿預防-診斷-治療-康復全流程的醫療新界面。這種變革不僅體現在參數提升,更讓每個生命個體感知到:醫療健康服務開始真正"聽懂"并"理解"人類最自然的表達方式。
AI機器人:
聽覺系統的場景化演進
AI機器人可通過聲學智能實現從物理執行到環境共生的跨越式進化,通過AI聲學降噪算法與AI聲學分類算法的處理,AI機器人能夠精準捕捉真實世界的聲音信息,并對聲音事件與聲音情感進行深度解析,實時構建環境模型,讓機器人能夠理解所處的聲學環境。家庭服務機器人能根據廚房環境底噪中的燃氣泄漏特征音提前2秒報警,當教育機器人從兒童斷續抽泣聲中識別焦慮指數并切換安撫模式,人類正見證機器人突破物理傳感器的局限,它們不僅能“聽見”聲音,更能理解聲波背后隱藏的機器狀態、生理特征與情感意圖,這種基于聲學全息感知的交互進化,讓人機協作從精準響應升級為預見性共融。
聲智科技在人機交互框架領域取得的技術突破,不僅體現在評測體系性能指標的量化提升,更重要的是實現了從基礎功能實現到體驗價值創造的全鏈路技術升級。伴隨全球AI產業的高速演進,工業機器人、智能汽車、精準醫療及航天科技等戰略領域正面臨智能化升級的迫切需求。依托新一代人機交互框架的技術優勢,聲智通過構建智能聽覺感知系統與決策中樞系統的深度協同,以非線性聲學計算為技術底座,推動AI交互范式從被動響應向主動認知演進。該系統不僅能實現毫秒級實時需求響應,更通過多模態行為建模與預測算法,在用戶需求顯性化前完成服務預判。
我們創新性地將非線性聲學計算與深度強化學習相結合,構建出具備環境認知與意圖推理能力的智能交互系統。這種技術融合使機器系統突破傳統規則引擎的限制,形成場景自適應的動態決策能力:通過實時聲場建模準確解析物理環境特征,結合強化學習算法持續優化交互策略,最終實現"場景理解-用戶認知-行為預判"的三維智能閉環。這種進化將重新定義人機交互范式,使智能設備具備情境感知與自主決策能力,推動智能服務向認知智能階段演進。
值得強調的是,真實場景數據與用戶體驗指標的深度融合正成為技術迭代的核心驅動力。聲智建立的"數據-算法-體驗"協同進化機制,不僅加速非線性聲學模型的場景適應能力,更通過強化學習框架實現交互策略的持續優化。這種雙向賦能的技術路徑,正在重塑人機協作的底層邏輯,為各行業智能化轉型提供可進化的認知中樞系統。但我們需要清醒認識到,真正的真實世界體驗模型尚未真正落地,特別是在物理規律約束建模、多模態感知融合等關鍵領域仍存在突破空間,AI時代才剛剛開始。
-
機器人
+關注
關注
213文章
31311瀏覽量
223365 -
AI
+關注
關注
91文章
40715瀏覽量
302373 -
聲智科技
+關注
關注
0文章
89瀏覽量
2368
原文標題:聲智全球首發新一代人機交互框架:非線性聲學與強化學習讓AI融入真實世界
文章出處:【微信號:聲智科技,微信公眾號:聲智科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
10寸人機交互裝置引領開關柜智能運維新時代

人機界面交互裝置:10KV開關柜的“智慧中樞”

從“人機交互”到“數字預演”:詳解 HMI、SCADA 與虛擬調試的閉環架構

中科創達旗下Rightware攜手高通發布智能汽車人機交互解決方案
時識科技CES 2026趨勢看點前瞻
澎峰科技榮獲2025新一代人工智能創業大賽總決賽二等獎
CIE全國RISC-V創新應用大賽 呼吸機人機交互系統
眼電EOG人機交互會是未來交互的一種主流嗎?

AI眼鏡或成為下一代手機?谷歌、蘋果等巨頭扎堆布局
重構未來自適應人機交互的創新技術

邊聊安全 | 人機交互對功能安全的影響

人機交互:連接人類與數字世界的橋梁




 工商網監
工商網監
評論