 芯動力與聯想攜手打造獨立加速器(dNPU)解決方案,賦能AI PC浪潮
芯動力與聯想攜手打造獨立加速器(dNPU)解決方案,賦能AI PC浪潮

隨著DeepSeek效應持續讓AI產業巨震,其在提供出色性能的基礎上,降低了對于算力的需求,可使AI更高效、更低成本地部署在端側設備,既而推動AIoT從“萬物互聯”邁向“萬物智聯”的同時,也為邊緣AI“主力軍”AI PC的端側部署大模型提供了全新的解題思路。
據IDC預測,AI PC在中國PC市場中新機的裝配比例將在未來幾年中快速攀升,將于2027年達到85%,成為PC市場主流。市場總規模將從2023年的3900萬臺增至2027年的5000萬臺以上,增幅接近28%。
眾所周知,端側大模型的快速演變對AI芯片性價比和適配能力提出了更高的要求,AI PC中的AI生成任務對計算資源和處理能力的要求不盡相同,需要從以通用計算為核心的計算架構向更加高性能的異構AI計算架構升級,讓CPU、GPU和NPU等不同的計算單元“各司其職”協同作戰,賦能AI PC增強的生成式AI體驗。在這一過程中,AI芯片重任在肩,而究竟哪類芯片能擔當重任呢?

作為PC界的龍頭,聯想給出了自己的答案。在2025年3月3日在西班牙巴塞羅那的MWC Barcelona2025盛會上,聯想展示了全面升級的AI PC。新款AI PC首次采用國內珠海市芯動力科技有限公司基于可重構并行處理器RPP的AzureBlade M.2加速卡,并將其命名為dNPU,不僅顯著提升了推理速度和整體性能,讓系統運行更加流暢,而且還顯著降低了系統整體功耗,實現了高效運行和節能降耗的雙重目標和雙重優化。
“dNPU代表了未來大模型在PC等本地端推理的技術方向和趨勢。”上述負責人強調。
端側AI算力追求極致性價比 GPGPU站上舞臺中央
隨著大模型為主的生成式AI技術取得快速發展,各大PC廠商不僅在積極探索全新的AI PC形態,為推動大模型推理快速高效實現也在積極采納和部署強勁的AI芯片。
傳統AI PC解決方案是在CPU中嵌入iNPU,在運行大語言模型時,通常依賴GPU進行加速,iNPU只有在特定的場景中才能被調用。然而,GPU在處理大模型時可能會面臨一些性能瓶頸,如GPU的架構雖然適合并行計算,但在處理深度學習任務時,會導致資源利用率不足或延遲較高。此外,GPU在推理階段的功耗相對較高。
而且在群雄逐鹿的通用GPU市場中,面臨著英偉達、英特爾、AMD等巨頭的強大競爭,國內廠商要在重重壁壘中開辟自己的天地,需要獨辟蹊徑,打造全生態。芯動力敏銳地觀察到,高性價比是邊緣計算核心要求,且性能與TOPS不直接掛鉤,不同計算階段對性能要求不同,采用探索創新型的計算機架構的GPGPU是解決通用高算力和低功耗需求的必由之路,并已成為業界共識。
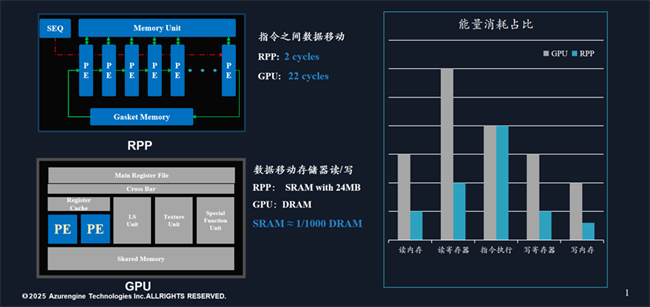
基于這一深刻洞察,芯動力推出了可重構并行處理器(RPP)架構,通過底層創新RPP架構,解決了高性能與通用性難兼以得的矛盾,利用數據流結構來避免了數據反復調用帶來的效率損失。并且芯動力具有編譯器、運行時環境、高度優化的RPP庫,可全面兼容CUDA的端到端完整軟件棧,從而實現邊緣AI應用的快速高效部署。
基于上述架構和設計創新,芯動力開發了AzureBlade M.2加速卡集成的AE7100芯片,作為一款高能效GPGPU,相比傳統GPU,針對神經網絡的計算特點進行了優化,通過集成大量專用的計算單元(如矢量內核或神經加速器)和片上內存,可高效處理矩陣乘法和卷積等操作,從而在通用性、低時延、低功耗、低成本和快速部署等方面展現出顯著優勢,成為解鎖端側各大模型的關鍵,并成為聯想AI PC落地的新動能。

(AI NOW不做大模型推理:右側 GPU usage 和 dNPU 占用率均為 0%)
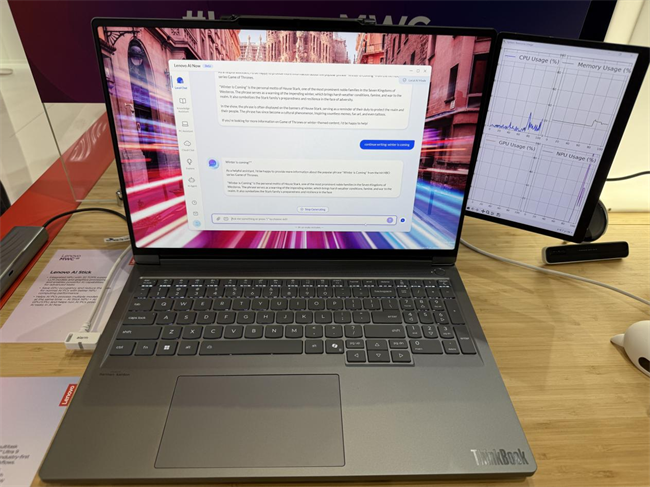
(AI NOW進行大模型推理:右側 GPU usage 仍為 0%,dNPU 在 40% 上下波動)
“一是系統運行更絲滑。dNPU 在執行深度學習任務時,無需占用CPU、顯存或GPU資源,這種設計不僅最大限度地減少了對傳統GPU和顯存的依賴,還通過dNPU的高效計算能力,顯著提升了推理速度和整體性能,讓系統運行更加絲滑流暢,大幅提升用戶體驗。二是低功耗優勢。通過實測,在未啟用AI NOW推理時,CPU的功耗僅為 7.52W,而推理時功耗上升至14.88W。dNPU的架構設計賦予其低功耗的特性,同時釋放了原本由GPU占用的高功耗資源,進一步優化了系統能效,不僅實現了推理任務的高效執行,更顯著降低了系統整體功耗,為用戶帶來性能與能效的雙重優化體驗。”聯想工作人員介紹dNPU在處理大模型時的顯著優勢時表示,“因而,聯想AI PC在AI計算、AI擴展、多模態交互、智能化等層面,均實現了顯著的提升。”
憑借芯動力的底層創新、深厚積淀和積極拓展,不僅在AI PC領域取得了開門紅,在同樣廣闊的泛安防/邊緣服務器、工業影像/機器視覺、信號處理/醫療影像、機器人等邊緣AI應用市場都已有眾多應用落地,并與眾多重要企業達成了戰略合作。
這些市場的廣闊發展前景也在徐徐展開,以安防IPC芯片市場為例,2026年全球規模將達 10.9億美元,2025全球3D視覺識別芯片市場規模將達27億美元;在工業影像/機器視覺市場,芯動力RPP架構GPU可對標英偉達AI算力顯卡+高端FPGA;針對泛安防/邊緣服務器市場,國產邊緣算力芯片之外提供新的選擇;在信號處理市場,更是可直接替代國外高端DSP,而更多的客戶合作和應用落地。
AI芯片實現高能效低功耗 加速卡成就“全武行”
芯動力開發的AzureBlade M.2加速卡被PC巨頭聯想成功合作,無疑再次佐證了芯動力RPP芯片的硬核實力。

具象來看,AE7100芯片作為此款M.2加速卡的核心,是芯動力基于RPP架構自主研發的AI芯片,其尺寸僅為17mm×17mm,堪稱業界最小、最薄的GPU。它不僅可以輕松放入標準M.2卡,還具備強大的計算能力,支持32Tops算力。
集成了耀眼AE7100芯片的AzureBlade M.2加速卡,更是將高性能、低功耗、小體積的優勢發揮到極致。它的尺寸僅為22mm×80mm,大約半張名片大小,卻擁有高達32TOPs的算力以及60GB/s的內存帶寬,功耗也可以做到動態控制。
值得一提的是,為將芯片融入筆記本電腦,芯動力還革新了封裝技術,采用扇出型封裝,實現了無基板的FC-BGA,實現了低成本先進封裝。此封裝方式提升了線密度至5微米,通過三層金屬線設計減小了芯片面積,降低了芯片的厚度。優化了散熱與電氣性能,封裝后的M.2卡為AI PC提供了dNPU解決方案。
眾所周知,無生態不AI。而在軟件層面,AE7100實現了從底層指令集到上層驅動的全面兼容,巧妙沿用英偉達軟件棧,并進行了SIMT指令集、驅動層和開發庫的優化,極大地提升了開發效率與邏輯實現的直觀性。由于該加速卡兼容CUDA和ONNX,能夠滿足各類AI應用的多樣化需求,其高算力和出色的內存帶寬確保了數據的高效穩定處理與傳輸。
對于AI PC 來說,依靠本地算力能夠推動更大參數規模的模型推理亦是AI PC功能實現的關鍵。而芯動力的M.2加速卡已可完美支撐大模型在AI PC等設備上的流暢運行,并且適配了Deepseek、Llama3-8B、Stable Diffusion、通義千問等開源模型。
在聯想將芯動力RPP架構GPGPU命名為dNPU之際,也表明dNPU正成為推動AI PC蓬勃發展的關鍵驅動力,不僅能夠提升AI模型的推理速度、降低功耗與提升能效,還可支持多樣化的AI應用,推動AI PC的創新與落地。有判斷稱,未來dNPU極有可能如同當下的GPU一般,成為電腦的一項常規可選配置,一旦電腦配備dNPU,用戶便能在終端設備上自由地提出問題,它會憑借強大的運算能力迅速給出精準解答。
從成本角度來看,傳統做法是將dNPU集成到CPU中,這會導致成本大幅增加。以某大廠處理器為例,采用3NM工藝制造,其研發與生產成本極高,導致產品價格居高不下,而大多消費者對這種高成本的配置并沒有強烈需求。與之相比,將dNPU作為獨立的標準化插件,具有更高的性價比和靈活性。
屆時,dNPU將作為標準化插件,廣泛出現在市面上所有可選擇配置的電腦機型中。無論是追求極致性能的專業人士,還是日常使用電腦的普通用戶,都能從中受益。它將為各類用戶提供強大的AI運算支持,極大地提升電腦在如智能語音交互、圖像識別處理、數據分析預測等豐富多樣的人工智能應用場景下的性能表現,為用戶帶來更為高效、智能的使用體驗。
持續精進RPP和適配大模型 邁向芯征程
所謂眾行者遠。芯動力作為聯想AI PC產品dNPU方案的合作伙伴,不僅是對芯動力GPGPU創新性架構的最佳背書,還為AI PC等端側設備提供了革命性支持,解決了大模型在端側部署的關鍵技術難題。這一創新技術必將加速大模型在端側設備的普及與應用,為行業創造前所未有的價值。
不僅如此,它在工業自動化、泛安防、內容過濾、醫療影像及信號處理等眾多領域都展現出了廣泛的應用潛力,為邊緣AI的智能化發展提供了強大的動力。
展望未來,隨著大語言模型向支持多模態、多專家系統的復雜模型轉變,對存儲能力和計算靈活性要求更高,可重構芯片以其低功耗和高靈活性將成為極具潛力的解決方案。
而且,算力產品與各類模型的適配將成為標準化的流程,模型適配程度將直接影響應用了算力產品的AI PC在模型推理方面的表現。同時,算力廠商不能只針對特定的應用進行調優,鑒于AI PC中應用將主要以插件的形式被大模型調用,對各類大小模型以及其調用的應用進行綜合適配才最為重要。因而,AI算力廠商還要持續深入建立通用、兼容的AI開發框架,并降低大模型和應用開發適配門檻。
芯動力還觀察到,邊緣計算作為云端算力有效補充,是AI大模型落地的必然趨勢。未來邊緣AI時代加速到來,將滲透至物理世界各個角落,持續打造高性價比dNPU、適配DeepSeek等新型大模型等是AI芯片廠商的“馬拉松”。芯動力將繼續秉承創新精神,基于RPP架構實現算力及性價比的持續提升,還將推出基于RPP集成Chiplet的8nm R36 GPU,2027年將推出更高性能的3nm R72 GPU。同時,深入提升軟件適配能力,強化對更大規模模型的支持,擴展智算生態合作圈,全面推動邊緣AI技術的部署與落地。
DeepSeek的技術突破,使AI更高效、更低成本地部署在端側設備,推動AIoT持續邁向“萬物智聯”。我們有理由相信,基于RPP架構的GPU及后續更高性能的迭代芯片不僅是AIPC加速處理器的理想選擇,在對延遲、功耗和體積有著極高要求的邊緣應用中也將持續綻放光芒。
審核編輯 黃宇
-
加速器
+關注
關注
2文章
839瀏覽量
40097 -
聯想
+關注
關注
3文章
2744瀏覽量
64651 -
AI
+關注
關注
91文章
39755瀏覽量
301355 -
DeepSeek
+關注
關注
2文章
835瀏覽量
3255
發布評論請先 登錄
兆芯攜手生態伙伴打造智能辦公“內腦”解決方案
后摩智能M50芯片亮相聯想集團首屆創新加速器開放日
軟通動力攜手金盤科技共拓智能制造新紀元
重磅合作!Quintauris 聯手 SiFive,加速 RISC-V 在嵌入式與 AI 領域落地
邊緣計算中的AI加速器類型與應用

軟通動力攜手華為昇騰推進AI智能體規模化部署
此芯科技發布“合一”AI加速計劃,賦能邊緣與端側AI創新

軟通動力入選828精選AI行業聯合解決方案
兆芯攜手聯想開天在WAIC 2025展示智能教育體方案
軟通動力攜手華為云推出AI知識引擎與數據工程融合創新解決方案
芯原可擴展的高性能GPGPU-AI計算IP賦能汽車與邊緣服務器AI解決方案
江蘇電信攜手華為打造面向AI WAN的融合邊緣解決方案
軟通動力攜手華為云舉辦行業賦能主題活動
軟通動力攜手伙伴發布六大聯合解決方案




 工商網監
工商網監
評論