 機器學習如何應對失衡類別
機器學習如何應對失衡類別

前言
實際應用中的分類問題往往不像教科書上人造的例子那樣齊整,類別往往存在某種程度上的失衡。Towards Data Science博主Devin Soni簡要介紹了應對失衡分類的常用方法。
介紹
大多數真實世界的分類問題都呈現出某種程度的類別失衡,即每個類別在數據集中的比例不同。恰當地調整指標和方法以適應目標非常重要。否則,你可能最終會為一個對你的用例無意義的度量指標進行優化。
例如,假設你有兩個類——A和B。A類占數據集的90%,B類占10%,但你最感興趣的是識別B類的實例。你可以每次都預測分類為A,這樣輕易就能達到90%的精確度,但對你的預期用例而言,這是一個無用的分類器。相反,經過恰當地校準的方法可能精確度較低,但會有較高的真陽率(或召回),這才是你應該優化的指標。在進行檢測時,這是常常發生的場景,例如檢測在線惡意內容或醫療數據中的疾病標記。
現在我將討論幾種可以用來緩解類別失衡的技術。一些技術適用于大多數分類問題,而其他技術可能更適合具備特定的失衡水平的問題。本文將從二元分類的角度來討論這些問題,但大多數情況下,這些技術同樣適用于多類分類問題。本文同時假設目標是識別少數類別,否則,這些技術并不是真的很有必要。
指標
一般來說,這個問題涉及召回率(recall,真陽性實例被分類為陽性實例的百分比)和準確率(precision,被分類為真陽性的實例中確實是陽性的百分比)之間的折衷。當我們想要檢測少數類別實例時,我們通常更關心召回率而不是準確率,因為在檢測的情境中,錯過正面實例的成本通常高于錯誤地標記負面實例為正面實例。例如,如果我們試圖檢測惡意內容,那么手動審核糾正被誤認為惡意內容的正常內容是微不足道的,但要識別甚至從未被標記為惡意內容的內容就要困難很多了。因此,比較適用于失衡分類問題的方法時,請考慮使用精確度之外的指標,例如召回率,準確率和AUROC。在選擇參數和模型時,切換優化指標可能就足以提供偵測少數類別所需的表現。
成本敏感學習
在通常的學習中,我們平等對待所有錯誤分類,這在失衡分類問題中會導致問題,因為相比識別出主要類別,識別出少數類別并不會有額外的獎勵。成本敏感學習改變了這一點,使用函數C(p, t)(通常表示為矩陣)指定將t類實例錯誤分類為p類實例的成本。這讓我們可以給錯誤分類少數類別更多的懲罰,以便增加真陽率。一個常用的方案是讓成本等于類別在數據集中所占比例的倒數。這樣,當類別尺寸縮小時,懲罰會增加。

采樣
解決失衡數據集的一個簡單方法就是平滑它們,過采樣少數類別,或者欠采樣主要類別。這讓我們創建一個平衡的數據集,理論上能使分類器不偏向其中一個類。然而,這些簡單的采樣方法實際上存在缺陷。過采樣少數類別會導致模型過擬合,因為它會引入從已經很小的實例池中抽取的重復實例。同樣,欠采樣主要類別可能最終導致遺漏體現了兩個類別之間的重要差別的重要實例。
還存在比簡單的過采樣或欠采樣更強大的采樣方法。最著名的例子是SMOTE,SMOTE通過構建相鄰實例的凸組合來創建少數類別的新實例。如下圖所示,它有效地繪制了特征空間中少數點之間的線條,并沿著這些線條采樣。這使我們能夠平衡我們的數據集,而不會過多地過擬合,因為我們創建了新的合成示例,而沒有使用重復樣本。不過這并不能防止所有過擬合,因為這些合成數據點仍然是基于現有數據點創建的。
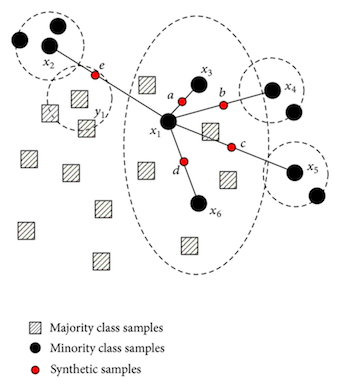
可視化SMOTE。陰影方塊:主要類別樣本;黑點:少數類別樣本;紅點:生成樣本
異常偵測
在更極端的情況下,將分類問題考慮成異常檢測(anomaly detection)問題可能會更好。在異常檢測問題中,我們假設有一個或一組“正常”的數據點分布,而任何與該分布足夠偏離的東西都是異常值。將分類問題置于異常檢測的框架下以后,我們將主要類別視為點的“正常”分布,將少數類別視為異常。有許多用于異常檢測的算法,例如聚類(clustering)方法,單類SVM(One-class SVM)和孤立森林(Isolation Forests)。
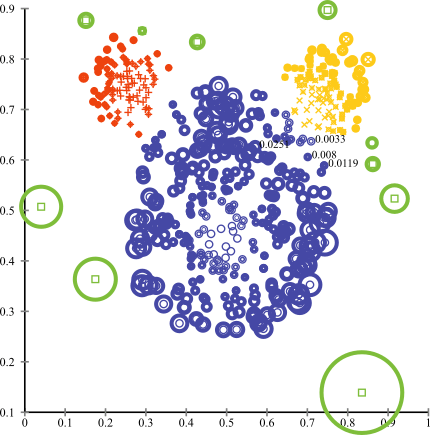
可視化用于異常檢測的聚類方法
結論
希望這些方法的某些組合可以讓你創建一個更好的分類器。像我之前說的那樣,這些技術中的某些技術更適合不同程度的失衡。例如,簡單的采樣技術可以讓你克服輕微失衡,而極端失衡可能需要異常檢測方法。基本上,對于這個問題,沒有包治百病的靈丹妙藥,你需要嘗試每種方法,看看它們應用到你的特定用例和指標的效果如何。
-
機器學習
+關注
關注
66文章
8554瀏覽量
136983
原文標題:機器學習如何應對失衡類別
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于NVIDIA Isaac Lab拓展多模態機器人學習

人工智能與機器學習在這些行業的深度應用
強化學習會讓自動駕駛模型學習更快嗎?

機器學習和深度學習中需避免的 7 個常見錯誤與局限性

半導體缺陷檢測升級:機器學習(ML)攻克類別不平衡難題,小數據也能精準判,降本又提效!

NVIDIA神經網絡創新研究重塑機器人學習
NVIDIA開源物理引擎與OpenUSD加速機器人學習
量子機器學習入門:三種數據編碼方法對比與應用

如何在機器視覺中部署深度學習神經網絡

AI 驅動三維逆向:點云降噪算法工具與機器學習建模能力的前沿應用




 工商網監
工商網監
評論