 數據科學工作流原理
數據科學工作流原理

數據科學工作流是一個動態、迭代的過程,其核心在于將數據轉化為有價值的信息和決策支持。以下,是對數據科學工作流原理的探討,請大家參考。
數據科學工作流的核心組件
數據收集:這是工作流的起點,涉及從各種來源(如數據庫、社交媒體、物聯網設備等)獲取相關數據。數據收集應確保數據的完整性、準確性和時效性。
數據預處理:包括數據清洗、格式轉換、缺失值處理、異常值檢測與處理等,旨在提高數據質量,為后續分析奠定基礎。
數據探索與可視化:通過統計分析和可視化技術(如直方圖、散點圖、熱力圖等),探索數據的分布特征、趨勢和關聯關系,為后續建模提供線索。
特征選擇與工程:從原始數據中提取或構造對預測目標有影響的特征,是提升模型性能的關鍵步驟。
模型選擇與訓練:根據問題類型(如分類、回歸、聚類等)選擇合適的算法,并使用預處理后的數據進行模型訓練。
模型評估與優化:通過交叉驗證、混淆矩陣、ROC曲線等方法評估模型性能,并根據評估結果進行參數調整或算法優化。
結果解釋與報告:將模型預測結果轉化為業務可理解的洞察,撰寫詳細的報告或演示文稿,向非技術背景的決策者傳達關鍵信息。
部署與監控:將經過驗證的模型集成到生產環境中,實施實時預測或決策支持,并持續監控模型性能,確保其長期有效性。
實踐中的挑戰與應對策略
數據隱私與安全:當今,保護數據隱私已成為不可忽視的問題。應對策略包括數據脫敏、加密存儲和傳輸、以及遵循最小必要原則收集數據。
數據質量與一致性:數據質量問題可能導致模型偏差。建立數據治理框架,實施數據質量監控和審計,是提升數據可靠性的有效手段。
模型可解釋性:復雜模型(如深度學習)雖性能優越,但解釋性差。通過集成學習方法、特征重要性分析或采用可解釋模型(如線性回歸、決策樹)來提高模型透明度。
技術與人才缺口:數據科學領域快速發展,技術與工具日新月異。企業應持續投資于員工培訓和技術更新,同時考慮與外部專家合作,彌補內部資源不足。
AI部落小編溫馨提示:以上就是小編為您整理的《數據科學工作流原理》相關內容,更多關于數據科學工作流的專業科普及petacloud.ai優惠活動可關注我們。
審核編輯 黃宇
-
AI
+關注
關注
91文章
39763瀏覽量
301366 -
數據科學
+關注
關注
0文章
168瀏覽量
10794
發布評論請先 登錄
是德科技與三星攜手英偉達展示端到端AI-RAN驗證工作流程
虛幻引擎5在建筑可視化中的應用:趨勢、挑戰與基于Perforce P4的工作流程

利用NVIDIA Nemotron開放模型構建智能文檔處理系統
安寶特方案丨AI 識別遇上 AR 工作流,PCB 質控迎來新的「黃金時代」

小藝開放平臺平臺功能
全面解析:n8n是什么以及它的工作原理
生命科學領先企業采用 NVIDIA BioNeMo 平臺加速 AI 驅動的藥物研發
芯片ATE測試詳解:揭秘芯片測試機臺的工作流程

ADI Power Studio工作流程與工具概述
恩智浦i.MX RT1180跨界MCU驅動EtherCAT的工作流程
【產品介紹】Altair SimLab可連接CAD的多物理場工作流

泰克設備在微流控技術研究中的應用
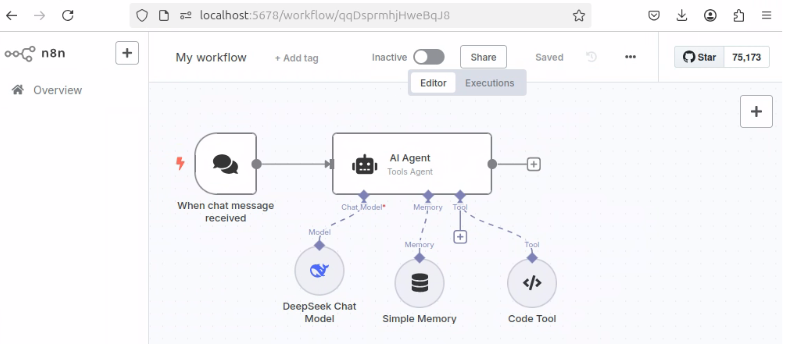
非技術人員如何用n8n + DeepSeek打造AI自動化工作流?
NVIDIA Blackwell RTX PRO 提供工作站和服務器兩種規格,助力設計師、開發者、數據科學家和創作人員構建代理式




 工商網監
工商網監
評論