 Spark基于DPU的Native引擎算子卸載方案
Spark基于DPU的Native引擎算子卸載方案

1.背景介紹
Apache Spark(以下簡稱Spark)是一個開源的分布式計算框架,由UC Berkeley AMP Lab開發,可用于批處理、交互式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。Spark使用內存加載保存數據并進行迭代計算,減少磁盤溢寫,同時支持 Java、Scala、Python和 R等多種高級編程語言,這使得Spark可以應對各種復雜的大數據應用場景,例如金融、電商、社交媒體等。
Spark 經過多年發展,作為基礎的計算框架,不管是在穩定性還是可擴展性方面,以及生態建設都得到了業界廣泛認可。盡管Apache社區對Spark逐步引入了諸如鎢絲計劃、向量化 Parquet Reader等一系列優化,整體的計算性能也有兩倍左右的提升,但在 3.0版本以后,整體計算性能的提升有所減緩,并且隨著存儲、網絡以及IO技術的提升,CPU也逐漸成為Spark計算性能的瓶頸。如何在Spark現有框架上,增強大數據計算能力,提高CPU利用率,成為近年來業界的研究方向。
2.開源優化方案
Spark本身使用scala語言編寫,整體架構基于 JVM開發,只能利用到一些比較基礎的 CPU指令集。雖然有JIT的加持,但相比目前市面上的Native向量化計算引擎而言,性能還是有較大差距。因此考慮如何將具有高性能計算能力的Native向量引擎引用到 Spark里來,提升 Spark的計算性能,突破 CPU瓶頸,成為一種可行性較高的解決方案。
隨著Meta在2022年超大型數據庫國際會議(VLDB)上發表論文《Velox:Meta's Unified Execution Engine》,并且Intel創建的Gluten項目基于Apache Arrow數據格式和Substrait查詢計劃的JNI API將Spark JVM和執行引擎解耦,從而將Velox集成到Spark中,這使得使用Spark框架+Native向量引擎的大數據加速方案成為現實。
3.DPU計算卡與軟件開發平臺
AI大模型的發展,金融、電商等領域數據處理需求的增加,生活應用虛擬化程度的加深,都對現代化數據中心提出嚴峻的考驗。未來數據中心的發展趨勢,逐步演變成CPU + DPU + GPU三足鼎立的情況,CPU用于通用計算,GPU用于加速計算,DPU則進行數據處理。將大數據計算卸載到具有高度定制化和數據處理優化架構的大規模數據計算DPU卡上,可以有效提高計算密集型應用場景下數據中心的性能和效率,降低其成本和能耗。
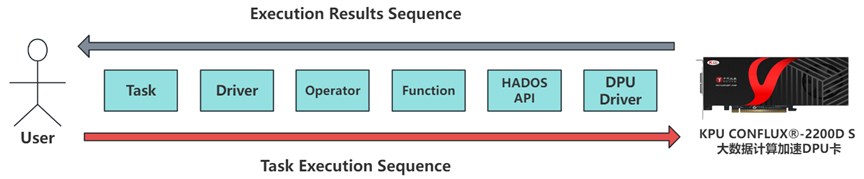
中科馭數CONFLUX?-2200D大數據計算DPU卡主要應用于大數據計算場景。CONFLUX?-2200D通過計算DPU卸載加速,存儲DPU卸載加速和網絡DPU卸載加速實現大數據計算性能3-6倍提升。CONFLUX?-2200D是基于中科馭數自主知識產權的KPU(Kernel Processing Unit)架構、DOE(Data Offloading Engine)硬件數據庫運算卸載引擎和LightningDMA中科馭數自主知識產權的基于DMA的直接內存寫入技術提出的領域專用DPU卡。能夠滿足無侵入適配、自主可控、安全可靠,支持存算一體、存算分離等不同場景。
中科馭數HADOS是中科馭數推出的專用計算敏捷異構軟件開發平臺。HADOS?數據查詢加速庫通過提供基于列式數據的查詢接口,供數據查詢應用,目前Spark、PostgreSQL已通過插件的形式適配。支持Java、Scala、C和C++語言的函數調用,主要包括列數據管理、數據查詢運行時函數、任務調度引擎、函數運算代價評估、內存管理、存儲管理、硬件管理、DMA引擎、日志引擎等模塊,目前對外提供數據管理、查詢函數、硬件管理、文件存儲相關功能API。
4.Spark框架+Gluten-Velox向量化執行引擎+DPU加速卡
4.1方案簡介
隨著SSD和萬兆網卡普及以及I/O技術的提升,Spark用戶的數據負載計算能力逐漸受到CPU性能瓶頸的約束。由于Spark本身基于JVM的Task計算模型的CPU指令優化,要遠遠遜色于其他的Native語言(C++等),再加上開源社區的Native引擎已經發展得比較成熟,具備優秀的量化執行能力,這就使得那些現有的Spark用戶,如果想要獲得這些高性能計算能力就需要付出大量的遷移和運維成本。
Gluten解決了這一關鍵性問題,讓Spark用戶無需遷移,就能享受這些成熟的Native引擎帶來的性能優勢。Gluten最核心的能力就是通過Spark Plugin的機制,把Spark查詢計劃攔截并下發給Native引擎來執行,跳過原生Spark不高效的執行路徑。整體的執行框架仍沿用Spark既有實現,并且對于Native引擎無法承接的算子,Gluten安排Fallback回正常的Spark執行路徑進行計算,從而保證Spark任務執行的穩定性。同時Gluten還實現了Fallback、本地內存管理等功能,使得Spark可以更好利用Native引擎帶來的高性能計算能力。
Velox是一個集合了現有各種計算引擎優化的新穎的C++數據加速庫,其重新設計了數據模型以支持復雜數據類型的高效計算,并且提供可重用、可擴展、高性能且與上層軟件無關的數據處理組件,用于構建執行引擎和增強數據管理系統。
由于Velox只接收完全優化的查詢計劃作為輸入,不提供 SQL解析器、dataframe層、其他 DSL或全局查詢優化器,專注于成為大數據計算的執行引擎。這就使得Gluten+Velox架構可以各司其職,從而實現數據庫組件模塊化。

要將Gluten+Velox優化過的Spark計算任務卸載到DPU卡,還缺少一個異構中間層,為此中科馭數研發了HADOS異構執行庫,該庫提供列數據管理、數據查詢運行時函數、任務調度引擎、函數運算代價評估、內存管理等多種DPU能力的API接口,并且支持Java,C++等多種大數據框架語言的調用,擁有極強的拓展性,以及與現有生態的適配性。HADOS敏捷異構軟件平臺可以適應復雜的大數據軟件生態,在付出較小成本的情況下為多種計算場景提供DPU算力加速。Spark框架集成Gluten+Velox向量化執行引擎,然后使用HADOS平臺,就可以將經過向量化優化的計算任務,利用DPU執行,從而徹底釋放CPU,實現DPU高性能計算。
4.2 DPU算力卸載
velox是由C++實現的向量化計算引擎,其核心執行框架涵蓋了任務(Task)、驅動(Driver)和操作器(Operator)等組件。velox將Plan轉換為由PlanNode組成的一棵樹,然后將PlanNode轉換為Operator。Operator作為基礎的算子,是實際算法執行的邏輯框架,也是實現DPU計算卸載的關鍵。
4.2.1邏輯框架
Operator作為實際算法的邏輯框架,承載著各種表達式的抽象,每一個Operator中包含一個或多個表達式來實現一個復雜完整的計算邏輯塊,表達式的底層是由function來具體實現。Velox向開發人員提供了API可以實現自定義scalar function,通過實現一個異構計算版本的function,然后將這個function注冊到Velox的函數系統中,就可以將計算任務卸載到DPU卡上。任務執行過程如下圖:
中科馭數的CONFLUX?-2200DS大數據計算加速DPU卡可以實現列式計算,并且HADOS平臺支持C++語言,所以可以直接解析Velox的向量化參數。對于列式存儲的數據,經過對數據類型的簡單處理之后,可以直接交給DPU執行計算任務,免去了數據行列轉換的性能損失,同時也降低了DPU計算資源集成的運維難度,大大提高了Velox異構開發的效率。
4.2.2算子卸載
以我們實現卸載的Filter算子為例,對于cast(A as bigint)>1這一具體的表達式,來探究如何實現”>”這一二元運算符的卸載。
Filter算子的Operator中會使用有一個 std::unique_ptr exprs_的變量,用來執行過濾和投影的計算。ExprSet是Filter算子計算的核心,其本質是一顆表達式樹。cast(A as bigint)>1的表達式樹以及表達式樹的靜態節點類型如下:
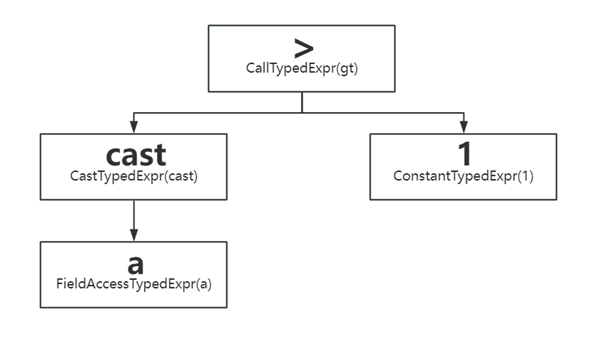
| 節點類型 | 作用 |
| FieldAccessTypedExpr | 表示RowVector中的某一列,作為表達式的葉子節點 |
| ConstantTypedExpr | 表示常量值,作為表達式的葉子節點 |
| CallTypedExpr |
表示函數調用表達式,子節點表示輸入參數 表示特殊類型表達式,包括 if/and/or/switch/cast/try/coalesce等 |
| CastTypedExpr | 類型轉換 |
| LambdaTypedExpr | Lambda表達式,作為葉子節點 |
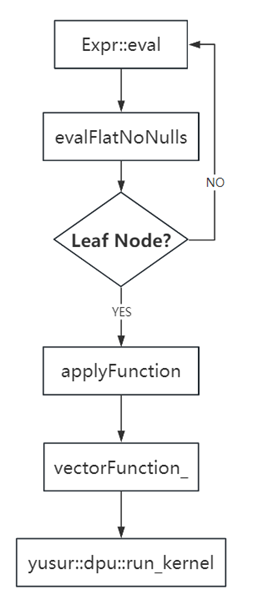
在表達式的所有子節點執行完后,會執行applyFunction,說明當前表達式節點是一個函數調用,然后調用vectorFunction_的apply來對結果進行處理,輸入是inputValues_數組,該數組長度與函數的表達式葉子節點數相等(文中示例表達式的葉子節點為2),作為函數的參數,result為輸出,結果為VectorPtr,程序流程圖如下:
4.2.3 Fallback
現階段我們只實現了Filter算子的部分表達式,后續還會繼續支持更多的算子和表達式。對于一些無法執行的算子和表達式,還是需要退回給Velox,交由CPU執行,從而保證SQL的正常執行。由于處理的是列式數據,所以回退的執行計劃可以不需要任何處理,就可以直接從HADOS退還給Velox,幾乎無性能損失。
4.2.4 DPU資源管理
HADOS平臺會對服務器的DPU資源進行統一管理。對于卸載的計算任務根據現有的DPU資源進行動態分配,從而實現計算資源的高效利用。同時HADOS平臺還會對計算任務中所需的內存進行合理的分配,動態申請和釋放系統內存,從而減少額外的內存開銷。
4.3加速效果
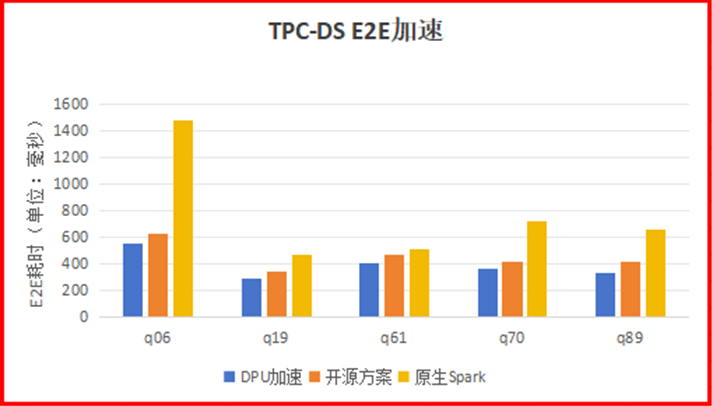
單機單線程local模式,使用1G數據集,僅卸載Filter算子的部分表達式的場景下,TPC-DS語句中有5條SQL語句,可以將使用開源方案的加速效果提升15-20%左右。q70語句,在開源方案提升100%的基礎上,提升了15%;q89語句,在開源方案提升50%的基礎上,提升了27%;q06在開源方案提升170%的基礎上,提升了13%。
單一運算符場景下(SELECT a FROM t WHERE a = 100),使用DPU運算符相比 Spark原生的運算符的加速比最高達到12.7。
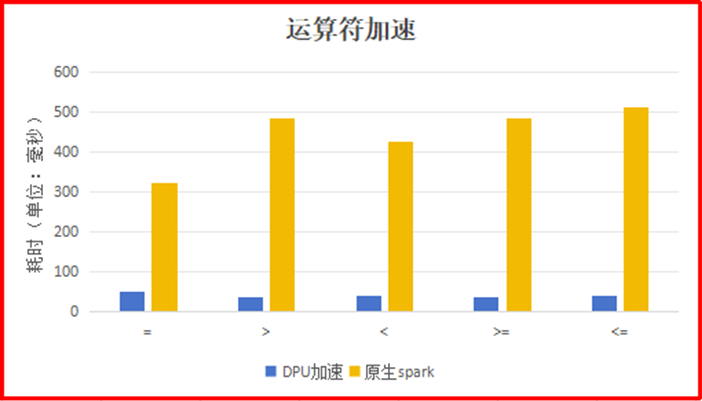
5.不足和展望
中科馭數HADOS敏捷異構軟件平臺可以十分輕松地與現有開源大數據加速框架相結合,并且為開源框架提供豐富的算力卸載功能。HADOS平臺在完美發揮開源加速框架優勢的前提下,為大數據任務提供硬件加速能力。由于現在我們只實現了較小部分算子卸載的驗證,在執行具有復雜算子操作的SQL時無法發揮出DPU的全部實力,并且因為開源方案在設計之處并沒有考慮到使用DPU硬件,所以在磁盤IO,算子優化等方面的性能還有待優化。后續我們也會從一下幾個方面來進一步做特定優化:
開發更多較復雜的算子,例如重量級的聚合算子會消耗CPU大量的計算能力從而影響Spark作業,通過將聚合算子卸載到DPU硬件來解放CPU能力,從而使得加速效果更加明顯;
優化DPU的磁盤讀寫,讓DPU可以直接讀取硬盤數據,省去數據在服務器內部的傳輸時間,可以減少數據準備階段的性能損耗;
RDMA技術,可以直讀取遠端內存數據,數據傳輸內容直接卸載到網卡,減少數據在系統內核中額外的數據復制與移動,可以減少大數據任務計算過程中的性能損耗。
審核編輯 黃宇
-
cpu
+關注
關注
68文章
11229瀏覽量
223218 -
DPU
+關注
關注
0文章
408瀏覽量
26317 -
SPARK
+關注
關注
1文章
108瀏覽量
21121
發布評論請先 登錄
如何在DGX Spark上運行NVIDIA Omniverse

NVIDIA DGX Spark系統恢復過程與步驟

NVIDIA在ISC 2025分享最新超級計算進展
NVIDIA DGX Spark助力構建自己的AI模型

NVIDIA DGX Spark快速入門指南

安泰新能源發布新一代智能跟蹤支架AT-Spark,為大型光伏電站提供一體化解決方案
NVIDIA推出全新BlueField-4 DPU
NVIDIA DGX Spark桌面AI計算機開啟預訂

RISC-V DPU,重塑數據中心算力格局?
中科馭數攜DPU全棧產品亮相福州數博會,賦能智算時代算力基建

DPU232—高度集成USB到UART橋接控制器 國產替代方案
NVIDIA加速的Apache Spark助力企業節省大量成本

hyper 卸載,Hyper卸載:如何徹底卸載hyper-v并恢復系統設置
在NVIDIA BlueField-3 DPU上運行WEKA客戶端的實際優勢






 工商網監
工商網監
評論