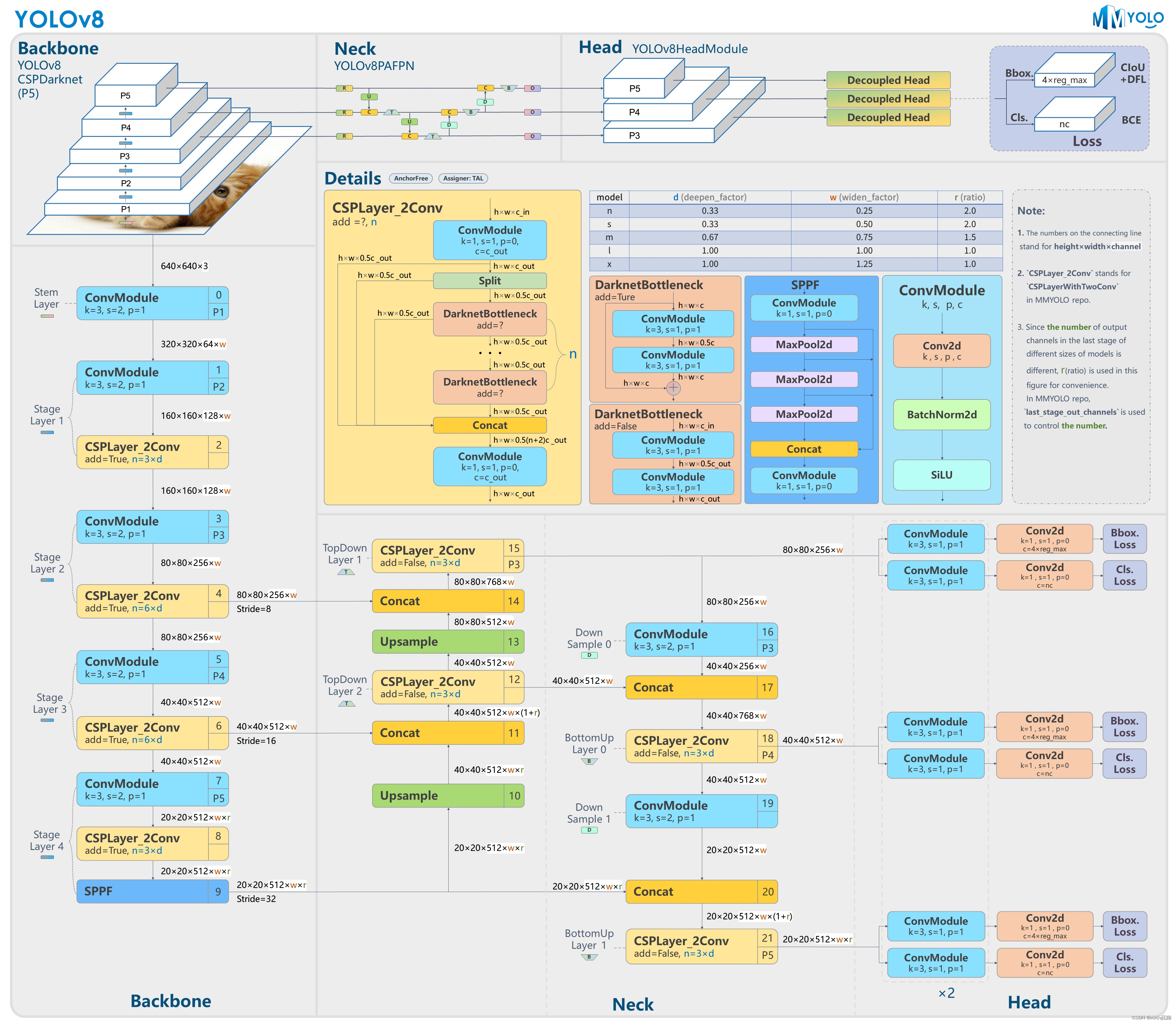
") 在英特爾酷睿Ultra處理器上優(yōu)化和部署YOLOv8模型
在英特爾酷睿Ultra處理器上優(yōu)化和部署YOLOv8模型

英特爾 酷睿 Ultra處理器是英特爾公司推出的一個高端處理器品牌,其第一代產(chǎn)品基于Meteor Lake架構(gòu),使用Intel 4制程,單顆芯片封裝了 CPU、GPU(Intel Arc Graphics)和 NPU(Intel AI Boost),具有卓越的AI性能。
本文將詳細介紹使用OpenVINO工具套件在英特爾 酷睿Ultra處理器上實現(xiàn)對YOLOv8模型的INT8量化和部署。
1
第一步:環(huán)境搭建
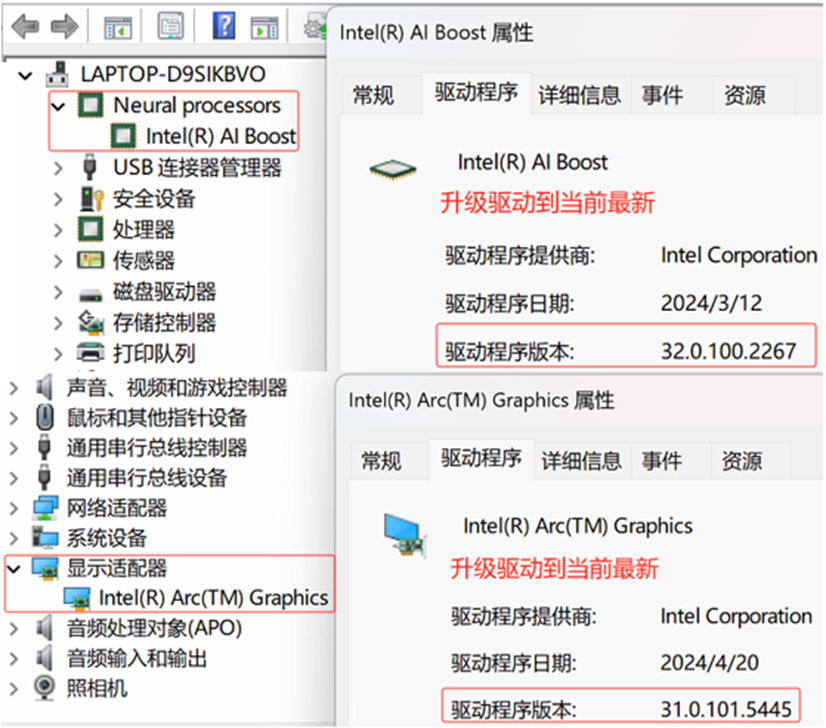
首先,請下載并安裝最新版的NPU和顯卡驅(qū)動:
NPU 驅(qū)動:https://www.intel.cn/content/www/cn/zh/download/794734/intel-npu-driver-windows.html
顯卡驅(qū)動:
https://www.intel.cn/content/www/cn/zh/download/785597/intel-arc-iris-xe-graphics-windows.html
然后,請下載并安裝Anaconda,然后創(chuàng)建并激活名為npu的虛擬環(huán)境:(下載鏈接:https://www.anaconda.com/download)
conda create -n npu python=3.11 #創(chuàng)建虛擬環(huán)境 conda activate npu #激活虛擬環(huán)境 python -m pip install --upgrade pip #升級pip到最新版本
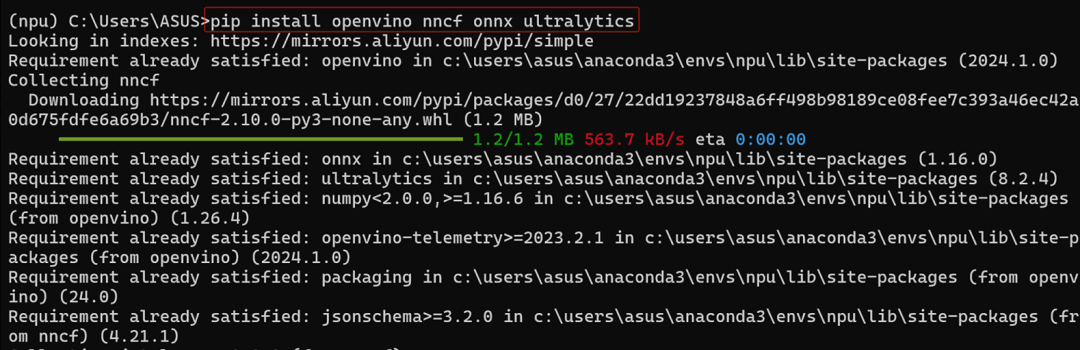
最后,請安裝openvino、nncf、onnx和ultralytics:
pip install openvino nncf onnx ultralytics
2
第二步:導(dǎo)出yolov8s模型并實現(xiàn)INT8量化
使用yolo命令導(dǎo)出yolov8s.onnx模型:
yolo export model=yolov8s.pt format=onnx
使用ovc命令導(dǎo)出OpenVINO格式,F(xiàn)P16精度的yolov8s模型
ovc yolov8s.onnx

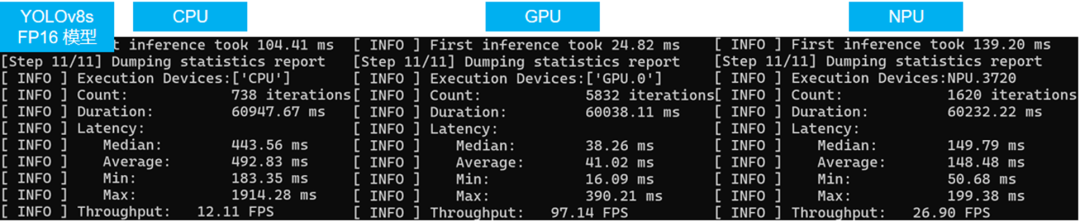
使用benchmark_app程序依次測試FP16精度的yolov8s模型在CPU,GPU和NPU上的AI推理性能,結(jié)果如下圖所示:
benchmark_app -m yolov8s.xml -d CPU #此處依次換為GPU,NPU
用NNCF實現(xiàn)yolov8s模型的INT8量化
NNCF全稱Neural Network Compression Framework,是一個實現(xiàn)神經(jīng)網(wǎng)絡(luò)訓練后量化(post-training quantization)和訓練期間壓縮(Training-Time Compression)的開源工具包,如下圖所示,通過對神經(jīng)網(wǎng)絡(luò)權(quán)重的量化和壓縮以最低精度損失的方式實現(xiàn)推理計算的優(yōu)化和加速。
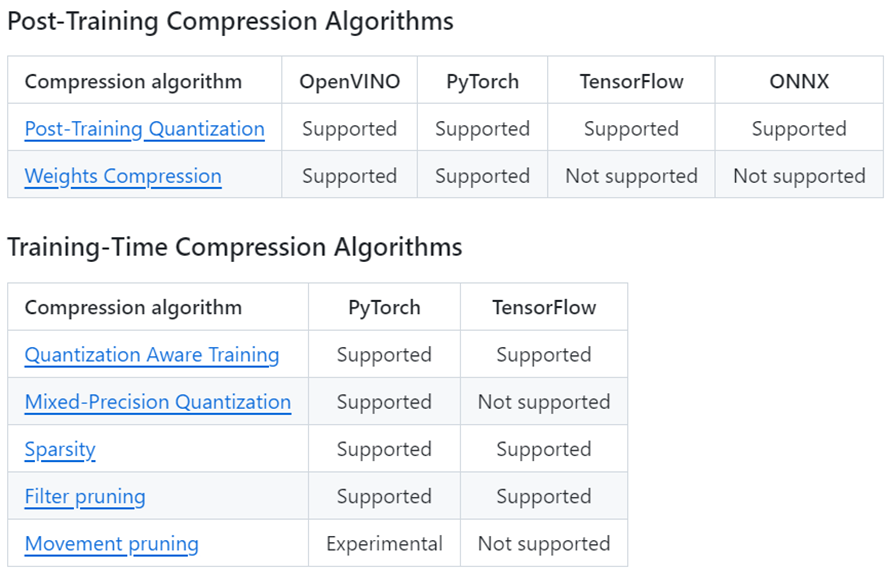
NNCF提供的量化和壓縮算法
在上述量化和壓縮算法中,訓練后INT8量化(Post-Training INT8 Quantization)是在工程實踐中應(yīng)用最廣泛的,它無需重新訓練或微調(diào)模型,就能實現(xiàn)模型權(quán)重的INT8量化,在獲得顯著的性能提升的同時,僅有極低的精度損失,而且使用簡便。
用NNCF實現(xiàn)YOLOv8s模型INT8量化的范例代碼yolov8_PTQ_INT8.py,如下所示:
import torch, nncf import openvino as ov from torchvision import datasets, transforms # Specify the path of model and dataset model_dir = r"yolov8s.xml" dataset = r"val_dataset" # Instantiate your uncompressed model model = ov.Core().read_model(model_dir) # Provide validation part of the dataset to collect statistics needed for the compression algorithm val_dataset = datasets.ImageFolder(dataset, transform=transforms.Compose([transforms.ToTensor(),transforms.Resize([640, 640])])) dataset_loader = torch.utils.data.DataLoader(val_dataset, batch_size=1) # Step 1: Initialize transformation function def transform_fn(data_item): images, _ = data_item return images.numpy() # Step 2: Initialize NNCF Dataset calibration_dataset = nncf.Dataset(dataset_loader, transform_fn) # Step 3: Run the quantization pipeline quantized_model = nncf.quantize(model, calibration_dataset) # Step 4: Save the INT8 quantized model ov.save_model(quantized_model, "yolov8s_int8.xml")
運行yolov8_PTQ_INT8.py,執(zhí)行結(jié)果如下所示:
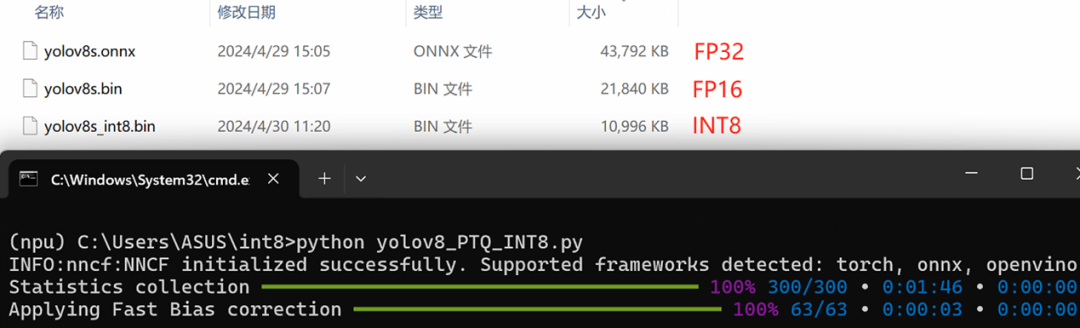
使用benchmark_app程序依次測試INT8精度的yolov8s模型在CPU,GPU和NPU上的AI推理性能,結(jié)果如下圖所示:
benchmark_app -m yolov8s_int8.xml -d CPU #此處依次換為GPU,NPU
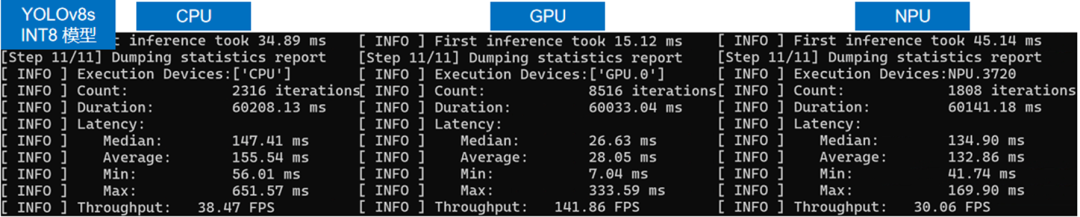
從上圖可以看出,yolov8s模型經(jīng)過INT8量化后,相比FP16精度模型,無論在Latency還是Throughput上,都有明顯提升。
3
第三步:編寫YOLOv8推理程序
yolov8目標檢測模型使用letterbox算法對輸入圖像進行保持原始寬高比的放縮,據(jù)此,yolov8目標檢測模型的預(yù)處理函數(shù)實現(xiàn),如下所示:
from ultralytics.data.augment import LetterBox # 實例化LetterBox letterbox = LetterBox() # 預(yù)處理函數(shù) def preprocess_image(image: np.ndarray, target_size=(640, 640))->np.ndarray: image = letterbox(image) #YOLOv8用letterbox按保持圖像原始寬高比方式放縮圖像 blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=target_size, swapRB=True) return blob
yolov8目標檢測模型的后處理函數(shù)首先用非極大值抑制non_max_suppression()算法去除冗余候選框,然后根據(jù)letterbox的放縮方式,用scale_boxes()函數(shù)將檢測框的坐標點還原到原始圖像上,如下所示:
# 后處理函數(shù): 從推理結(jié)果[1,84,8400]的張量中拆解出:檢測框,置信度和類別
def postprocess(pred_boxes, input_hw, orig_img, min_conf_threshold = 0.25,
nms_iou_threshold = 0.7, agnosting_nms = False, max_detections = 300):
# 用非極大值抑制non_max_suppression()算法去除冗余候選框
nms_kwargs = {"agnostic": agnosting_nms, "max_det":max_detections}
pred = ops.non_max_suppression(
torch.from_numpy(pred_boxes),
min_conf_threshold,
nms_iou_threshold,
nc=80,
**nms_kwargs
)[0]
# 用scale_boxes()函數(shù)將檢測框的坐標點還原到原始圖像上
shape = orig_img.shape
pred[:, :4] = ops.scale_boxes(input_hw, pred[:, :4], shape).round()
return pred
完整代碼詳細參見:yolov8_infer_ov.py,其運行結(jié)果如下所示:

4
總結(jié)
英特爾 酷睿 Ultra處理器內(nèi)置了CPU、GPU和NPU,相比之前,無論是能耗比、顯卡性能還是AI性能,都有顯著提升;通過OpenVINO和NNCF,可以方便快捷實現(xiàn)AI模型的優(yōu)化和INT量化,以及本地化部署,獲得非常不錯的端側(cè)AI推理性能。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
20298瀏覽量
253585 -
英特爾
+關(guān)注
關(guān)注
61文章
10310瀏覽量
180835 -
GPU芯片
+關(guān)注
關(guān)注
1文章
307瀏覽量
6540 -
OpenVINO
+關(guān)注
關(guān)注
0文章
118瀏覽量
801
原文標題:在英特爾? 酷睿? Ultra處理器上優(yōu)化和部署YOLOv8模型 | 開發(fā)者實戰(zhàn)
文章出處:【微信號:英特爾物聯(lián)網(wǎng),微信公眾號:英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
性能再越級!英特爾推出全新酷睿Ultra 200HX Plus系列移動處理器
釋放極致游戲性能!英特爾酷睿Ultra 200S Plus發(fā)布
輕薄、AI、數(shù)日續(xù)航、性能強勁,第三代英特爾酷睿Ultra新品重磅上市
18核/24核雙旗艦!英特爾酷睿Ultra 200S Plus發(fā)布,游戲性能大漲15%

相當完美的新一代移動級處理器!英特爾酷睿Ultra X9 388H首測

大顯存突破!解鎖120B MoE大模型,英特爾酷睿Ultra 285H拓展AI新應(yīng)用

英特爾舉辦行業(yè)解決方案大會,共同打造機器人“芯”動脈

使用ROCm?優(yōu)化并部署YOLOv8模型
硬件與應(yīng)用同頻共振,英特爾Day 0適配騰訊開源混元大模型
RV1126 yolov8訓練部署教程
英特爾酷睿Ultra 200HX游戲本發(fā)布
在英特爾酷睿Ultra AI PC上部署多種圖像生成模型




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論