 對標OpenAI GPT-4,MiniMax國內首個MoE大語言模型全量上線
對標OpenAI GPT-4,MiniMax國內首個MoE大語言模型全量上線

1 月 16 日,InfoQ 獲悉,經過了半個月的部分客戶的內測和反饋,MiniMax 全量發布大語言模型 abab6,該模型為國內首個 MoE(Mixture-of-Experts)大語言模型。
早在上個月舉辦的數字中國論壇成立大會暨數字化發展論壇的一場分論壇上,MiniMax 副總裁魏偉就曾透露將于近期發布國內首個基于 MoE 架構的大模型,對標 OpenAI GPT-4。
在 MoE 結構下,abab6 擁有大參數帶來的處理復雜任務的能力,同時模型在單位時間內能夠訓練足夠多的數據,計算效率也可以得到大幅提升。改進了 abab5.5 在處理更復雜、對模型輸出有更精細要求場景中出現的問題。 為什么選擇 MoE 架構?
那么,MoE 到底是什么?MiniMax 的大模型為何要使用使用 MoE 架構?
MoE 架構全稱專家混合(Mixture-of-Experts),是一種集成方法,其中整個問題被分為多個子任務,并將針對每個子任務訓練一組專家。MoE 模型將覆蓋不同學習者(專家)的不同輸入數據。
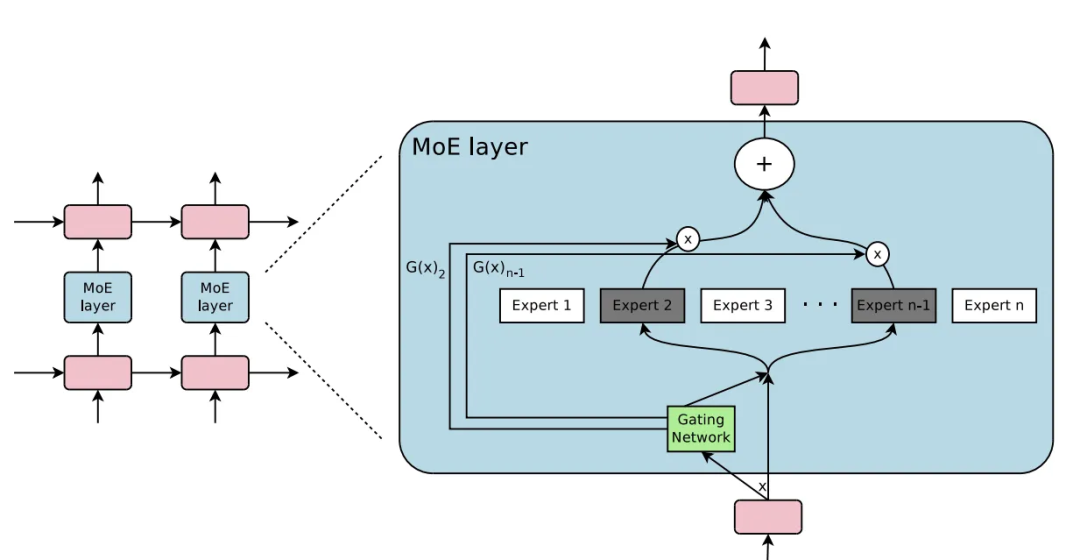
圖片來源:https ://arxiv.org/pdf/1701.06538.pdf
有傳聞稱,GPT-4 也采用了相同的架構方案。
2023 年 4 月,MiniMax 發布了開放平臺。過去半年多,MiniMax 陸續服務了近千家客戶,包括金山辦公、小紅書、騰訊、小米和閱文在內的多家頭部互聯網公司,MiniMax 開放平臺平均單日的 token 處理量達到了數百億。
MiniMax 在官微中發文稱:“這半年多來,客戶給我們提供了很多有價值的反饋和建議。例如,大家認為我們做得比較好的地方有:在寫作、聊天、問答等場景中,abab5.5 的表現不錯,達到了 GPT-3.5 的水平。”
但是和最先進的模型 GPT-4 相比,仍有明顯差距。這主要體現在處理更復雜的、對模型輸出有精細要求的場景時,存在一定概率違反用戶要求的輸出格式,或是在推理過程中發生錯誤。當然,這不僅是 abab5.5 的問題,也是目前除 GPT-4 以外,幾乎所有大語言模型存在的缺陷。
為了解決這個問題,進一步提升模型在復雜任務下的效果,MiniMax 技術團隊從去年 6 月份起開始研發 MoE 模型——abab6 是 MiniMax 的第二版 MoE 大模型(第一版 MoE 大模型已應用于其 C 端產品中)。
雖然MiniMax 并未透露Abab6 的具體參數,但據MiniMax 透露,Abab6 比上一個版本大了一個量級。更大的模型意味著 abab6 可以更好的從訓練語料中學到更精細的規律,完成更復雜的任務。
但僅擴大參數量會帶來新的問題:降低模型的推理速度以及更慢的訓練時間。在很多應用場景中,訓練推理速度和模型效果同樣重要。為了保證 abab6 的運算速度,MiniMax 技術團隊使用了 MoE (Mixture of Experts 混合專家模型)結構。在該結構下,模型參數被劃分為多組“專家”,每次推理時只有一部分專家參與計算。基于 MoE 結構,abab6 可以具備大參數帶來的處理復雜任務的能力;計算效率也會得到提升,模型在單位時間內能夠訓練足夠多的數據。
目前大部分大語言模型開源和學術工作都沒有使用 MoE 架構。為了訓練 abab6,MiniMax 還自研了高效的 MoE 訓練和推理框架,也發明了一些 MoE 模型的訓練技巧。到目前為止,abab6 是國內第一個千億參數量以上的基于 MoE 架構的大語言模型。
測評結果
為了對比各模型在復雜場景下的表現,MiniMax 對 abab6、abab5.5、GPT-3.5、GPT-4、Claude 2.1 和 Mistral-Medium 商用進行了自動評測。在簡單的任務上,abab5.5 已經做得比較好,因此 MiniMax 選擇了三種涵蓋了較復雜的問題的評測方法:
IFEval:這個評測主要測試模型遵守用戶指令的能力。在測試時,提問者會問模型一些帶有約束條件的問題,例如“以 XX 為標題,列出三個具體對方法,每個方法的描述不超過兩句話”,然后統計有多少回答嚴格滿足了約束條件。
MT-Bench:這個評測衡量模型的英文綜合能力。提問者會問模型多個類別的問題,包括角色扮演、寫作、信息提取、推理、數學、代碼、知識問答。MiniMax 技術團隊會用另一個大模型(GPT-4)對模型的回答打分,并統計平均分。
AlignBench:該評測反映了模型的中文綜合能力測試,測試形式與 MT-Bench 類似。
測評及對比結果如下:

注:對比模型均選擇各自最新、效果最好的版本,分別為 Claude-2.1、Mistral-Medium 商用、GPT-3.5-Turbo-0613、GPT-4-1106-preview;GPT-3.5-Turbo-0613 略好于 GPT-3.5-Turbo-1106 。abab6 是 1 月 15 號的版本。
可以看出,abab6 在三個測試集中均明顯好于前一代模型 abab5.5。在指令遵從、中文綜合能力和英文綜合能力上,abab6 大幅超過了 GPT-3.5。和 Claude 2.1 相比,abab6 也在指令遵從、中文綜合能力和英文綜合能力上略勝一籌。相較于 Mistral 的商用版本 Mistral-Medium,abab6 在指令遵從和中文綜合能力上都優于 Mistral-Medium,在英文綜合能力上與 Mistral- Medium 旗鼓相當。
如果想體驗 MiniMax MoE 大模型,可訪問 MiniMax 開放平臺官網:api.minimax.chat
ps:MiniMax 方面稱,模型還在持續訓練中,遠沒有收斂,歡迎大家反饋。
-
語言模型
+關注
關注
0文章
571瀏覽量
11310 -
OpenAI
+關注
關注
9文章
1245瀏覽量
10058 -
大模型
+關注
關注
2文章
3648瀏覽量
5179
原文標題:對標OpenAI GPT-4,MiniMax 國內首個 MoE 大語言模型全量上線
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GPT-5震撼發布:AI領域的重大飛躍

登臨科技KS系列GPU產品全面適配MiniMax M2.5模型

沐曦曦云C500/C550 GPU產品深度適配MiniMax M2.5模型
NVIDIA Grace Blackwell平臺實現MoE模型性能十倍提升

GPT-5.1發布 OpenAI開始拼情商
OpenAI Sora 2模型上線微軟Azure AI Foundry國際版

中科曙光助力首個地質大模型“坤樞”上線
NVIDIA從云到邊緣加速OpenAI gpt-oss模型部署,實現150萬TPS推理

澎峰科技完成OpenAI最新開源推理模型適配
訊飛星辰MaaS平臺率先上線OpenAI最新開源模型
SuperX全新發布多種規格的多模型一體機:全新定義企業級智能生產力




 工商網監
工商網監
評論