 使用自監督學習重建動態駕駛場景
使用自監督學習重建動態駕駛場景


無論是單調的高速行車,還是平日的短途出行,駕駛過程往往平淡無奇。因此,在現實世界中采集的用于開發自動駕駛汽車(AV)的大部分訓練數據都明顯偏向于簡單場景。
這給部署魯棒的感知模型帶來了挑戰。自動駕駛汽車必須接受全面的訓練、測試和驗證,以便能夠應對復雜的場景,而這需要大量涵蓋此類場景的數據。
在現實世界中,收集此類場景數據要耗費大量時間和成本。而現在,仿真提供了另一個可選方案。但要大規模生成復雜動態場景仍然困難重重。
在近期發布的一篇論文中,NVIDIA Research 展示了一種基于神經輻射場(NeRF)的新方法——EmerNeRF 及其如何使用自監督學習準確生成動態場景。通過自監督方法訓練,EmerNeRF 在動靜態場景重建上的表現超越了之前其他 NeRF 方法。詳細情況請參見 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision。



圖 1. EmerNeRF 重建動態駕駛場景的示例
相比其他 NeRF 重建方法,EmerNeRF 的動態場景重建準確率高出 15%,靜態場景高出 11%。新視角合成的準確率也高出 12%。
打破 NeRF 方法的局限性
NeRF 將一組靜態圖像重建成逼真的 3D 場景。這使得依據駕駛日志重建用于 DNN 訓練、測試驗證的高保真仿真環境成為可能。
然而,目前基于 NeRF 的重建方法在處理動態物體時十分困難,而且實踐證明難以擴展。例如有些方法可以生成靜態和動態場景,但它們依賴真值(GT)標簽。這就意味著必須使用自動標注或人工標注員先來準確標注出駕駛日志中的每個物體。
其他 NeRF 方法則依賴于額外的模型來獲得完整的場景信息,例如光流。
為了打破這些局限性,EmerNeRF 使用自監督學習將場景分解為靜態、動態和流場(flow fields)。該模型從原始數據中學習前景、背景之間的關聯和結構,而不依賴人工標注的 GT 標簽。然后,對場景做時空渲染,并不依賴外部模型來彌補時空中的不完整區域,而且準確性更高。

圖 2. EmerNeRF 將圖 1 第一段視頻中的場景分解為動態場、靜態場和流場
因此,其他模型往往會產生過于平滑的背景和精度較低的動態物體(前景),而 EmerNeRF 則能重建高保真的背景及動態物體(前景),同時保留場景的細節。
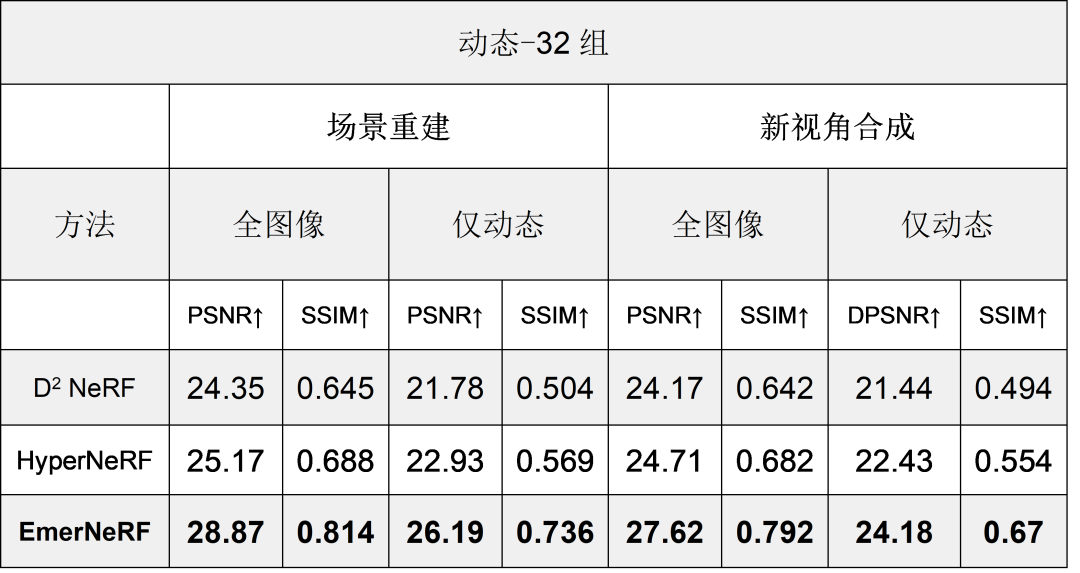
表 1. 將 EmerNeRF 與其他基于 NeRF 的動態場景重建方法進行比較后的評估結果,分為場景重建性能和新視角合成性能兩個類別
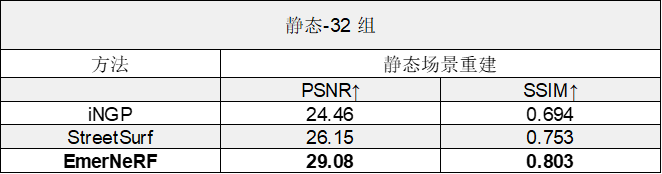
表 2. 將 EmerNeRF 與其他基于 NeRF 的靜態場景重建方法進行比較后的評估結果
EmerNeRF 方法
EmerNeRF 使用的是自監督學習,而非人工注釋或外部模型,這使得它能夠避開之前方法所遇到的難題。
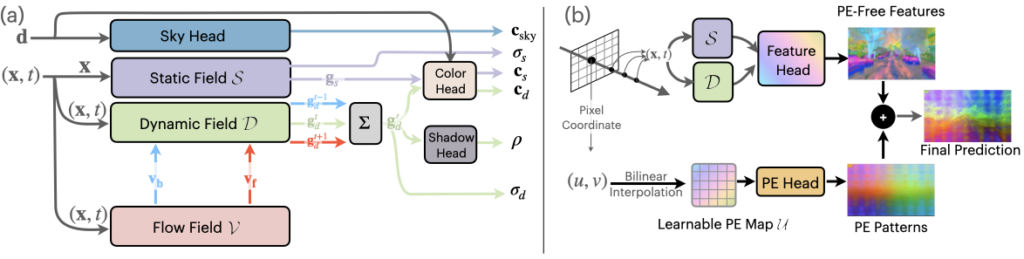
圖 3.EmerNeRF 分解和重建管線
EmerNeRF 將場景分解成動態和靜態元素。在場景分解的同時,EmerNeRF 還能估算出動態物體(如汽車和行人)的流場,并通過聚合流場在不同時間的特征以進一步提高重建質量。其他方法會使用外部模型提供此類光流數據,但通常會引入偏差。
通過將靜態場、動態場和流場結合在一起,EmerNeRF 能夠充分表達高密度動態場景,這不僅提高了重建精度,也方便擴展到其他數據源。
使用基礎模型加強語義理解
EmerNeRF 對場景的語義理解,可通過(視覺)基礎大模型監督進一步增強。基礎大模型具有更通用的知識(例如特定類型的車輛或動物)。EmerNeRF 使用視覺 Transformer(ViT)模型,例如 DINO, DINOv2,將語義特征整合到場景重建中。
這使 EmerNeRF 能夠更好地預測場景中的物體,并執行自動標注等下游任務。

圖 4. EmerNeRF 使用 DINO 和 DINOv2 等基礎模型加強對場景的語義理解
不過,基于 Transformer 的基礎模型也帶來了新的挑戰:語義特征可能會表現出與位置相關的噪聲,從而大大限制下游任務的性能。

圖 5. EmerNeRF 使用位置嵌入消除基于 Transformer 的基礎模型所產生的噪聲
為了解決噪聲問題,EmerNeRF 通過位置編碼分解來恢復無噪聲的特征圖。如圖 5 所示,這樣就解鎖了基礎大模型在語義特征上全面、準確的表征能力。
評估 EmerNeRF
正如 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision 中所述,研究人員整理出了一個包含 120 個獨特場景的數據集來評估 EmerNeRF 的性能,這些場景分為 32 個靜態場景、32 個動態場景和 56 個多樣化場景,覆蓋了高速、低光照等具有挑戰性的場景。
然后根據數據集的不同子集,評估每個 NeRF 模型重建場景和合成新視角的能力。
如表 1 所示,據此,EmerNeRF 在場景重建和新視角合成方面的表現始終明顯優于其他方法。
EmerNeRF 的表現還優于專門用于靜態場景的方法,這表明將場景分解為靜態和動態元素的自監督分解既能夠改善靜態重建,還能夠改善動態重建。
總結
自動駕駛仿真只有在能夠準確重建現實世界的情況下才會有效。隨著場景的日益動態化和復雜化,對保真度的要求也越來越高,而且更難實現。
與以前的方法相比,EmerNeRF 能夠更準確地表現和重建動態場景,而且無需人工監督或外部模型。這樣就能大規模地重建和編輯復雜的駕駛數據,解決目前自動駕駛汽車訓練數據集的不平衡問題。
NVIDIA 正迫切希望研究 EmerNeRF 帶來的新功能,如端到端駕駛、自動標注和仿真等。
如要了解更多信息,請訪問 EmerNeRF 項目頁面并閱讀 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision。
了解更多
-
適用于自動駕駛汽車的解決方案
https://www.nvidia.cn/self-driving-cars/
-
EmerNeRF 項目頁面
https://emernerf.github.io/
-
閱讀 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision.
https://arxiv.org/abs/2311.02077
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:使用自監督學習重建動態駕駛場景
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
23文章
4087瀏覽量
99198
原文標題:使用自監督學習重建動態駕駛場景
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
算法工程師需要具備哪些技能?
強化學習會讓自動駕駛模型學習更快嗎?


【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
自動駕駛數據標注是所有信息都要標注嗎?

【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
如何深度學習機器視覺的應用場景
如何選擇適合的智駕仿真工具進行場景生成和測試?
僅使用智能手機在NVIDIA Isaac Sim中重建場景
講講如何閉環自動駕駛仿真場景,從重建到可用?

從“重建”到“可用”:aiSim3DGS方案如何閉環自動駕駛仿真場景?

自動駕駛中常提的“強化學習”是個啥?

生成式 AI 重塑自動駕駛仿真:4D 場景生成技術的突破與實踐

一種適用于動態環境的3DGS-SLAM系統

使用MATLAB進行無監督學習




 工商網監
工商網監
評論