") 微軟正式發(fā)布一個(gè)27億參數(shù)的語言模型—Phi-2
微軟正式發(fā)布一個(gè)27億參數(shù)的語言模型—Phi-2

先后和 OpenAI、Meta 牽手推動(dòng)大模型發(fā)展的微軟,也正在加快自家小模型的迭代。就在今天,微軟正式發(fā)布了一個(gè) 27 億參數(shù)的語言模型——Phi-2。這是一種文本到文本的人工智能程序,具有出色的推理和語言理解能力。
同時(shí),微軟研究院也在官方 X 平臺(tái)上如是說道,“Phi-2 的性能優(yōu)于其他現(xiàn)有的小型語言模型,但它足夠小,可以在筆記本電腦或者移動(dòng)設(shè)備上運(yùn)行”。
Phi-2 的性能真能優(yōu)于大它 25 倍的模型?
對(duì)于Phi-2 的發(fā)布,微軟研究院在官方公告的伊始便直言,Phi-2 的性能可與大它 25 倍的模型相匹配或優(yōu)于。
這也讓人有些尷尬的事,不少網(wǎng)友評(píng)價(jià)道,這豈不是直接把 Google 剛發(fā)的 Gemini 最小型號(hào)的版本給輕松超越了?

那具體情況到底如何?
微軟通過時(shí)下一些如 Big Bench Hard (BBH)、常識(shí)推理(PIQA、WinoGrande、ARC easy 和 Challenge、SIQA)、語言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、 SQuADv2、BoolQ)、數(shù)學(xué)(GSM8k)和編碼(HumanEval)等基準(zhǔn)測(cè)試,將 Phi-2 與 7B 和 13B 參數(shù)的 Mistral 和 Llama-2 進(jìn)行了比較。
最終得出僅擁有 27 億個(gè)參數(shù)的 Phi-2 ,超越了 Mistral 7B 和 Llama-2 7B 以及 13B 模型的性能。值得注意的是,與大它 25 倍的 Llama-2-70B 模型相比,Phi-2 還在多步推理任務(wù)(即編碼和數(shù)學(xué))上實(shí)現(xiàn)了更好的性能。
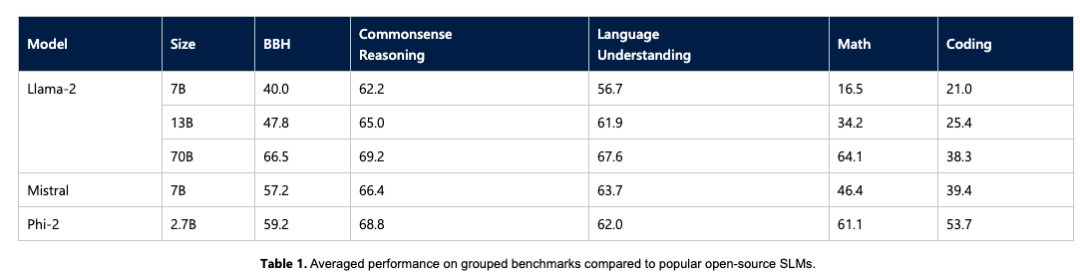
此外,如上文所提及的,微軟研究人員也直接在基準(zhǔn)測(cè)試中放上了其與Google 全新發(fā)布的 Gemini Nano 2 正面PK 的結(jié)果,不出所料,Phi-2盡管尺寸較小,但性能還是把Gemini Nano 2 超了。

除了這些基準(zhǔn)之外,研究人員似是在暗諷 Google 前幾日在Gemini 演示視頻中造假一事,因?yàn)楫?dāng)時(shí) Google 稱其即將推出的最大、最強(qiáng)大的新人工智能模型 Gemini Ultra 能夠解決相當(dāng)復(fù)雜的物理問題,并且甚至糾正學(xué)生的錯(cuò)誤。
事實(shí)證明,盡管 Phi-2 的大小可能只是 Gemini Ultra 的一小部分,但它也能夠正確回答問題并使用相同的提示糾正學(xué)生。

微軟的改進(jìn)
Phi-2 小模型之所以有如此亮眼的成績,微軟研究院在博客中解釋了原因。
一是提升訓(xùn)練數(shù)據(jù)的質(zhì)量。Phi-2 是一個(gè)基于 Transformer 的模型,其目標(biāo)是預(yù)測(cè)下一個(gè)單詞,它在 1.4T 個(gè)詞組上進(jìn)行了訓(xùn)練,這些詞組來自 NLP 和編碼的合成數(shù)據(jù)集和網(wǎng)絡(luò)數(shù)據(jù)集,包括科學(xué)、日常活動(dòng)和心理理論等用于教授模型常識(shí)和推理的內(nèi)容。Phi-2 的訓(xùn)練是在 96 個(gè) A100 GPU 上耗時(shí) 14 天完成的。
其次,微軟使用創(chuàng)新技術(shù)進(jìn)行擴(kuò)展,將其知識(shí)嵌入到 27 億參數(shù) Phi-2 中。
微軟指出,Phi-2 是一個(gè)基礎(chǔ)模型,沒有通過人類反饋強(qiáng)化學(xué)習(xí)(RLHF)進(jìn)行調(diào)整,也沒有經(jīng)過指導(dǎo)性微調(diào)。盡管如此,與經(jīng)過對(duì)齊的現(xiàn)有開源模型相比,微軟觀察到在毒性和偏差方面,Phi-2 有更好的表現(xiàn)。
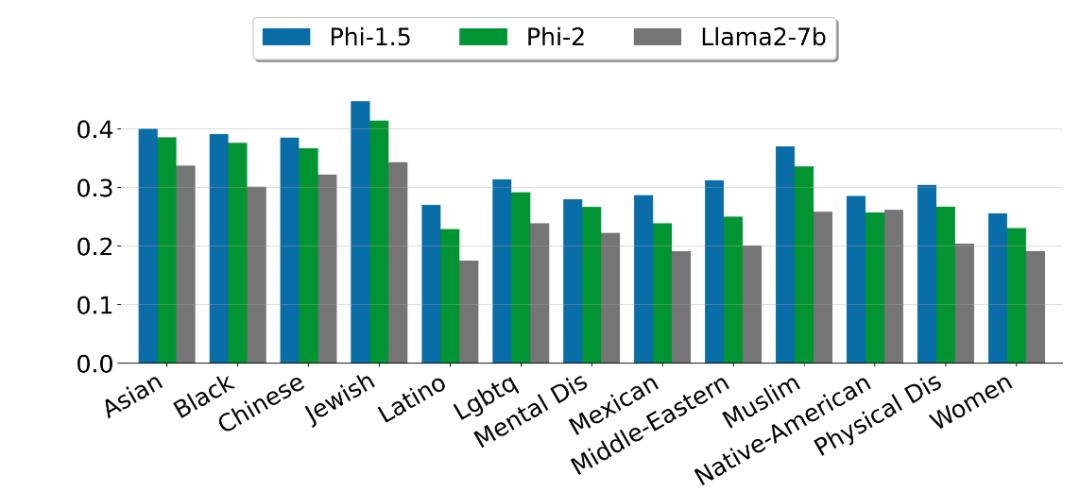
寫在最后
話說 Phi-2 的發(fā)布的確在小模型的性能上實(shí)現(xiàn)了突破,不過也有媒體發(fā)現(xiàn)它還存在很大的局限性。
因?yàn)楦鶕?jù)微軟研究許可證顯示,其規(guī)定了 Phi -2 只能用于“非商業(yè)、非創(chuàng)收、研究目的”,而不是商業(yè)用途。因此,想要在其之上構(gòu)建產(chǎn)品的企業(yè)就不走運(yùn)了。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3953瀏覽量
142660 -
OpenAI
+關(guān)注
關(guān)注
9文章
1245瀏覽量
10078 -
大模型
+關(guān)注
關(guān)注
2文章
3650瀏覽量
5188
原文標(biāo)題:只有 27 億參數(shù),微軟發(fā)布全新 Phi-2 模型!
文章出處:【微信號(hào):AI科技大本營,微信公眾號(hào):AI科技大本營】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

谷歌正式發(fā)布Gemma Scope 2模型
谷歌與耶魯大學(xué)合作發(fā)布最新C2S-Scale 27B模型
米爾RK3576部署端側(cè)多模態(tài)多輪對(duì)話,6TOPS算力驅(qū)動(dòng)30億參數(shù)LLM
3萬字長文!深度解析大語言模型LLM原理

OpenAI發(fā)布2款開源模型
萬億參數(shù)!元腦企智一體機(jī)率先支持Kimi K2大模型
【VisionFive 2單板計(jì)算機(jī)試用體驗(yàn)】3、開源大語言模型部署
日本航空攜手微軟率先將AI應(yīng)用引入客艙管理
Microchip AT27LV256A-90JU 可編程只讀存儲(chǔ)器(OTP EPROM)參數(shù)特性 EDA模型與數(shù)據(jù)手冊(cè)下載
華為助力中國石油發(fā)布3000億參數(shù)昆侖大模型

NVIDIA使用Qwen3系列模型的最佳實(shí)踐

小白學(xué)大模型:從零實(shí)現(xiàn) LLM語言模型
小身板大能量:樹莓派玩轉(zhuǎn) Phi-2、Mistral 和 LLaVA 等AI大模型~

?VLM(視覺語言模型)?詳細(xì)解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論