") 探索AIGC未來:CPU源碼優(yōu)化、多GPU編程與中國算力瓶頸與發(fā)展
探索AIGC未來:CPU源碼優(yōu)化、多GPU編程與中國算力瓶頸與發(fā)展

★人工智能;大數(shù)據(jù)技術(shù);AIGC;Turbo;DALL·E 3;多模態(tài)大模型;MLLM;LLM;Agent;Llama2;國產(chǎn)GPU芯片;GPU;CPU;高性能計算機;邊緣計算;大模型顯存占用;5G;深度學(xué)習(xí);A100;H100;A800;H800;L40s;Intel;英偉達;算力
近年來,AIGC的技術(shù)取得了長足的進步,其中最為重要的技術(shù)之一是基于源代碼的CPU調(diào)優(yōu),可以有效地提高人工智能模型的訓(xùn)練速度和效率,從而加快了人工智能的應(yīng)用進程。同時,多GPU編程技術(shù)也在不斷發(fā)展,大大提高人工智能模型的計算能力,更好地滿足實際應(yīng)用的需求。
本文將分析AIGC的最新進展,深入探討以上話題,以及中國算力產(chǎn)業(yè)的瓶頸和趨勢。
AIGC發(fā)展現(xiàn)狀
AIGC產(chǎn)業(yè)在上半年經(jīng)歷“百模大戰(zhàn)”和“百花齊放”的階段后,現(xiàn)在正站在從“玩具”到“工具”的關(guān)鍵時期。大模型市場格局發(fā)生深刻變化,行業(yè)關(guān)注焦點也轉(zhuǎn)向人工智能發(fā)展的“終極命題”——應(yīng)用與商業(yè)化落地。AIGC研發(fā)范式的變革從根本上提高數(shù)據(jù)生產(chǎn)效率,降低使用者和開發(fā)者的門檻。
為提升模型的能力和效用,行業(yè)共同關(guān)注放大模型能力的有效途徑,如微調(diào)、提示工程、搜索增強生成、AI Agent等技術(shù)手段。同時,開源模型迅速發(fā)展,產(chǎn)品向終端延伸,結(jié)合更多AI應(yīng)用技術(shù),推動應(yīng)用場景多元化。然而,由于政策面向C端設(shè)置準(zhǔn)入門檻,標(biāo)準(zhǔn)體系覆蓋多個行業(yè),強調(diào)數(shù)據(jù)、算法、模型和安全因素的重要性,因此“百模大戰(zhàn)”回歸理性,行業(yè)格局邁入整合階段。
2023 Q3國內(nèi)AIGC行業(yè)發(fā)生融資事件35起,涉及公司33家,投資機構(gòu)51家。融資金額39.61億人民幣,種子輪~天使輪21家(占比63.64%)。通用大模型(6起)和工具平臺(6起)兩個細分賽道相對活躍。在應(yīng)用層中,元宇宙/數(shù)字人(5起)和營銷(5起)是融資事件最頻繁的細分領(lǐng)域。有1家國內(nèi)AIGC企業(yè)完成上市——第四范式(決策類人工智能公司)。2023年Q3國內(nèi)AIGC行業(yè)發(fā)生1起并購事件——美團收購光年之外,融資額20.65億元。
一、技術(shù)迭代
1、多模態(tài)大模型DALL·E 3帶來產(chǎn)業(yè)沖擊
多模態(tài)大語言模型(MLLM)是一種將文本、圖像、音頻和視頻等多模態(tài)信息結(jié)合訓(xùn)練的模型,相比大語言模型(LLM)更符合人類感知世界的方式。通過多模態(tài)輸入的支持,用戶可以更靈活的方式與智能助手進行交互,并利用強大的大模型作為大腦來執(zhí)行多模態(tài)任務(wù)。
DALL·E 3能夠更好地捕捉語義描述的細微差異,實現(xiàn)提示詞的完美遵循,并高效避免混淆詳細請求中的元素,在畫面呈現(xiàn)方面取得明顯進步。同時,文生圖模型與ChatGPT的結(jié)合,極大地減少了提示工程的約束。

2、長文本技術(shù)增強產(chǎn)品用戶體驗
LLM中的“上下文長度”是指大語言模型在生成預(yù)測時考慮的輸入文本長度。更長的文本建模能力使模型能夠觀察到更長的上下文,避免重要信息的丟失。大模型的應(yīng)用效果取決于兩個核心指標(biāo):模型參數(shù)量和上下文長度。其中,上下文長度決定大模型的“內(nèi)存”能力,長文本可以提供更多上下文和細節(jié)信息來輔助模型判斷語義,減少歧義,提高歸納和推理的準(zhǔn)確性。
目前,國內(nèi)外對于文本長度的探索還沒有達到“臨界點”,長文本在未來的Agent和AI原生應(yīng)用中仍然扮演著重要角色。Agent需要依靠歷史信息進行規(guī)劃和決策,而AI原生應(yīng)用需要依靠上下文來保持連貫、個性化的用戶體驗。這也是為什么像月之暗面、OpenAI等大模型公司關(guān)注長文本技術(shù)的原因。
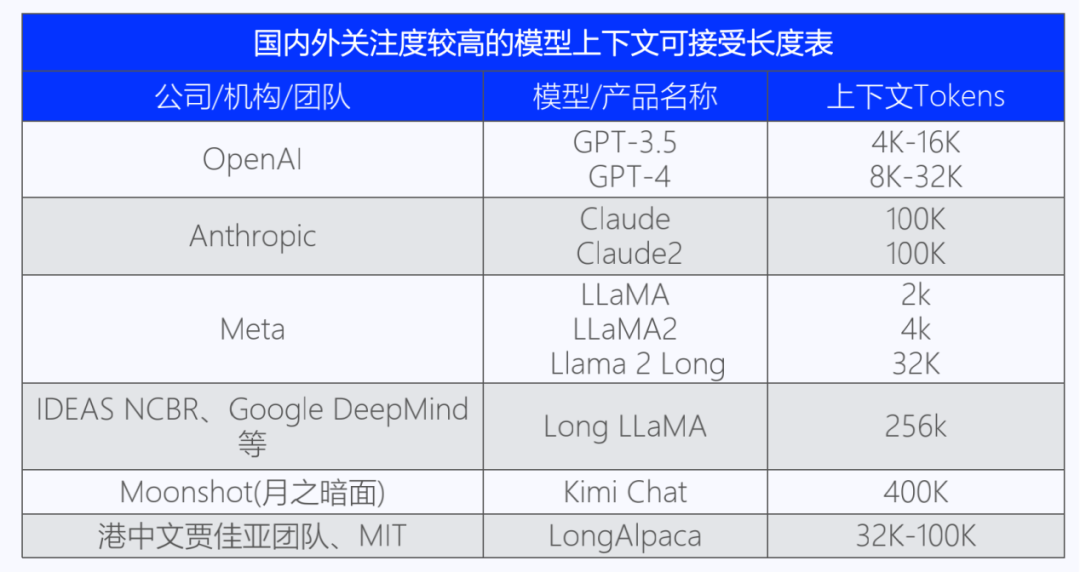
3、Llama2掀起大模型市場新格局
Llama是Meta發(fā)布的一款使用公開數(shù)據(jù)集訓(xùn)練的大型語言模型,因其與開源協(xié)議的兼容性和可復(fù)現(xiàn)性而受到AI社區(qū)歡迎。但受限于開源協(xié)議,LLaMA僅限學(xué)術(shù)研究使用,不能用于商業(yè)用途。
相比Llama 1,Llama 2預(yù)訓(xùn)練語料庫增加40%,達到2萬億Tokens。9月,Llama2的token已達32,768個,并采用分組查詢注意力機制,對文本語義的理解更深入。在MMLU和GSM8K測試中,Llama 2 70B的性能接近GPT-3.5。
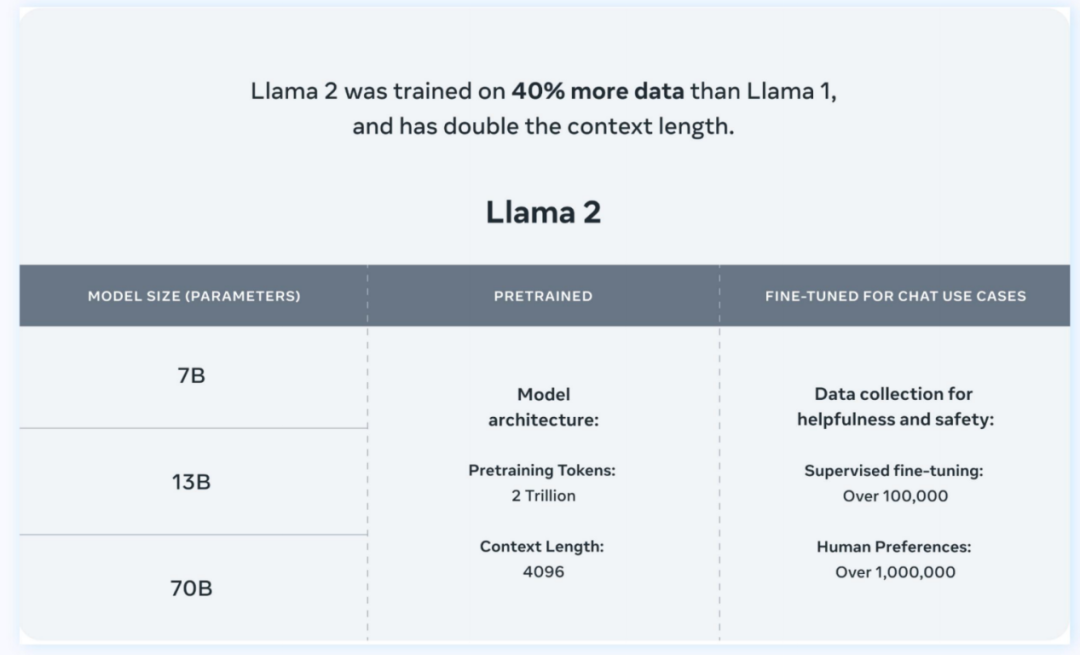
4、AI Agent深入挖掘大模型潛力
Agent是指具有自主性、反應(yīng)性、社會性、預(yù)動性、慎思性和認知性等智能特征的軟件或硬件實體,等于大模型+記憶+主動規(guī)劃+工具。AI Agent能夠理解、規(guī)劃、執(zhí)行和自我調(diào)整,解決更復(fù)雜的問題。與LLM相比,AI Agent能夠獨立思考并調(diào)用工具逐步完成目標(biāo),區(qū)別于RPA的是其能夠處理未知環(huán)境信息。
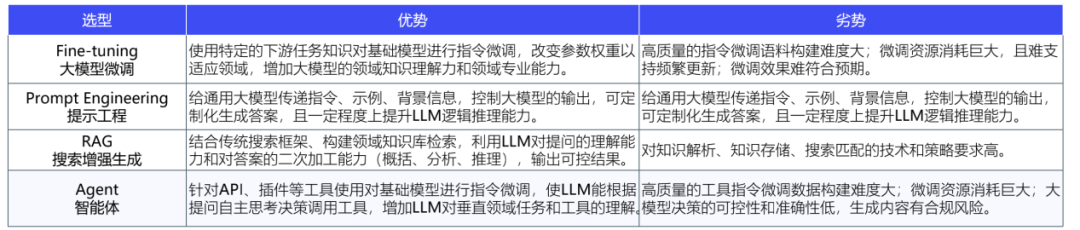
AI Agent與其他技術(shù)選型方案發(fā)展及優(yōu)劣勢比較
二、技術(shù)趨勢
1、擁抱開源精神,國產(chǎn)模型的崛起已成燎原之勢
在國家的大力支持和頭部廠商的推動下,國產(chǎn)模型已成為大語言模型陣營中的重要力量。盡管起步較晚,且面臨國外高端GPU芯片的圍堵,但國產(chǎn)模型的崛起之勢已成燎原。基礎(chǔ)的互聯(lián)網(wǎng)大廠積極推動開源生態(tài)體系的構(gòu)建。
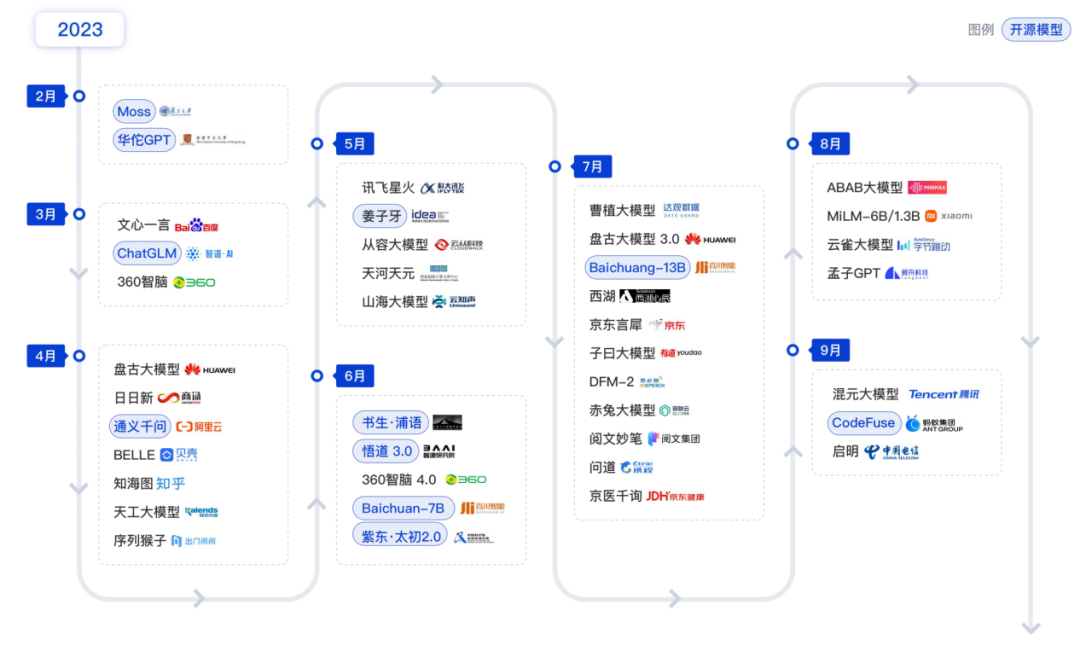
國內(nèi)AI大模型發(fā)展進程 (截至2023年Q3)
2、大模型產(chǎn)品向終端延伸,推動應(yīng)用場景多元化發(fā)展
大模型開源、多模態(tài)和Agent等技術(shù)將帶來全新、個性化、人性化的交互體驗。未來,大模型將部署在手機、PC、汽車、人形機器人等終端,解決云端AI在成本、能耗、性能、隱私、安全和個性化等方面的問題,并拓寬自動駕駛、智慧教育、智慧家居等場景的多元化應(yīng)用。然而,如何在端側(cè)實現(xiàn)輕量部署和軟硬件深度融合仍是難點問題。

企業(yè)私有化部署大模型綜合成本持續(xù)降低
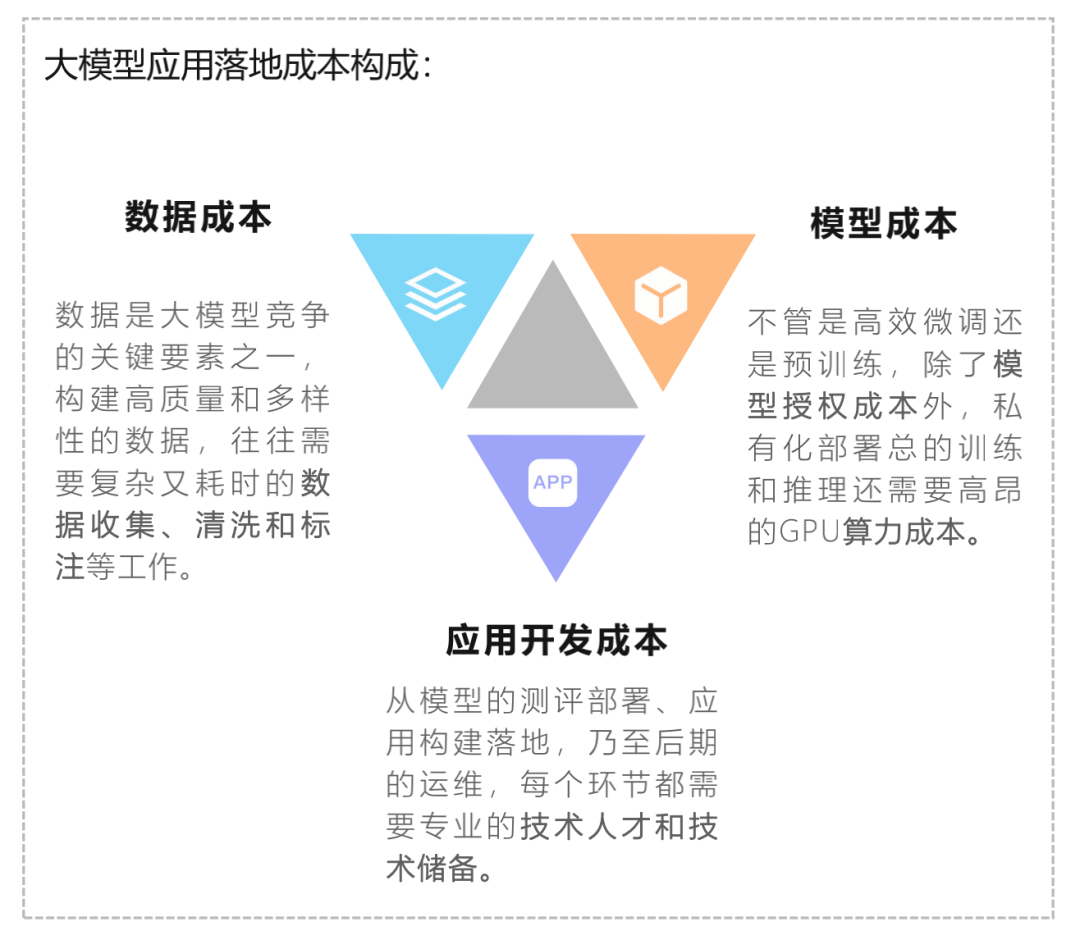
大模型應(yīng)用落地成本包括數(shù)據(jù)、模型和應(yīng)用開發(fā)成本。模型成本包括授權(quán)成本和算力成本。隨著Llama2推動國內(nèi)模型的商用免費化,MaaS逐漸被市場接受,授權(quán)成本過高的壁壘正在消失。通過QLoRA微調(diào)和GPTQ量化,中小企業(yè)也可以使用千億級模型,算力成本大幅降低。企業(yè)私有化部署綜合成本持續(xù)降低,有利于大模型對B端市場的滲透。
三、如何確定大模型顯存占用?
在部署大模型時,顯存占用是個關(guān)鍵問題。大模型因其巨大規(guī)模,要么因顯存溢出而無法運行,要么因模型過大導(dǎo)致推理速度慢。優(yōu)化大模型的推理與優(yōu)化小模型CNN的推理有所不同。下面將主要探討如何計算大模型的顯存占用。
以流行的LLama2大模型為例,主要有7B、13B、70B三個版本。B(Billion)是十億,M(Million)是百萬,所以LLama2這類大模型可稱為十億、百億級大模型。
對于深度學(xué)習(xí)模型,精度通常有float32、float16、int8、int4等。后面的int8、int4等低精度主要用于推理加速。比如,一個float32會占用4個字節(jié)32個比特,往后就減半,如int8是1字節(jié)占用8比特,int4的占用空間會更加小。參數(shù)量和模型精度可以用來計算模型的顯存占用。以LLama2-13B為例:
對于float32精度:13 * 10^9 * 4 / 1024^3 約等于 48.42G
對于float16精度:13 * 10^9 * 2 / 1024^3 約等于 24.21G
以此類推,計算LLama2-7B的顯存占用。
對于float32精度:7 * 10^9 * 4 / 1024^3 約等于 26.08G;
對于float16精度顯存減半:約等于 13G;
對于int8精度再減半:約等于6.5G;
對于int4精度再減半:約等于3.2G。
可見低比特量化在大模型部署顯存管理中的重要性。上述推理顯存占用只適用于模型前向推理,不適用于模型訓(xùn)練。訓(xùn)練過程中還會受梯度、優(yōu)化器參數(shù)、bs等因素影響。一般經(jīng)驗來說,訓(xùn)練時的顯存占用會是推理時的好多倍,甚至十幾倍。上述推理顯存占用是理論值,實際肯定會更多一些,因此需要預(yù)留一些余量。例如,實測LLama2-13B時,理論值約為48.21G,但實際需要大約52G的顯存。當(dāng)然,這種方法也適用于CNN模型的前向推理顯存占用計算。
基于源代碼的CPU調(diào)優(yōu)
對于高性能應(yīng)用,如云服務(wù)、科學(xué)計算和3A游戲等,硬件基礎(chǔ)至關(guān)重要。忽視硬件因素可能導(dǎo)致性能瓶頸。標(biāo)準(zhǔn)算法和數(shù)據(jù)結(jié)構(gòu)在某些場景下可能無法提供最佳性能。
一、CPU前端優(yōu)化
隨著“扁平化”數(shù)據(jù)結(jié)構(gòu)的普及,鏈表逐漸被淘汰。傳統(tǒng)鏈表每個節(jié)點動態(tài)分配內(nèi)存,導(dǎo)致內(nèi)存訪問延遲和碎片化。這使得遍歷鏈表比遍歷數(shù)組更耗時。有些數(shù)據(jù)結(jié)構(gòu)(如二叉樹)有類似鏈表的天然結(jié)構(gòu),使用指針追蹤實現(xiàn)可能更高效。另外,更高效的數(shù)據(jù)結(jié)構(gòu)版本如boost::flat_map 和 boost::flat_set也存在。
特定問題的最優(yōu)算法在特定場景中可能不是最好的選擇。例如,二分搜索在排序數(shù)組中查找元素很高效,但分支預(yù)測錯誤可能導(dǎo)致其在大規(guī)模數(shù)據(jù)中表現(xiàn)不佳。因此,在處理小規(guī)模整型數(shù)組時,線性搜索可能更有效。總之,針對高性能應(yīng)用,需要深入理解硬件和算法性能,并靈活選擇和優(yōu)化合適的算法和數(shù)據(jù)結(jié)構(gòu)以適應(yīng)不同場景。
“數(shù)據(jù)驅(qū)動”優(yōu)化是一種重要的調(diào)優(yōu)技術(shù),基于對程序處理數(shù)據(jù)的深入理解。專注于數(shù)據(jù)的分布和在程序中的轉(zhuǎn)化方式。其中一個典型的例子是將數(shù)組結(jié)構(gòu)體(SOA)轉(zhuǎn)換為結(jié)構(gòu)體數(shù)組(AOS)。選擇哪種布局取決于代碼訪問數(shù)據(jù)的方式。如果程序遍歷數(shù)據(jù)結(jié)構(gòu)并僅訪問字段b,則SOA更有效,這主要是由于所有內(nèi)存訪問都是按順序執(zhí)行;如果程序遍歷數(shù)據(jù)結(jié)構(gòu)并對對象的所有字段(即a、b和c)進行大量操作,則AOS更佳,因為所有成員都可能保存在相同的緩存行中,減少緩存行讀取,提高內(nèi)存帶寬利用率。要進行此類優(yōu)化,需要了解程序?qū)⑻幚砟男?shù)據(jù)和數(shù)據(jù)的分布情況,并相應(yīng)地修改程序。

另一個重要的數(shù)據(jù)驅(qū)動優(yōu)化方法是“小尺寸優(yōu)化”,旨在為容器預(yù)先分配固定量的內(nèi)存,以避免動態(tài)內(nèi)存分配。該方法在LLVM基礎(chǔ)設(shè)施中廣泛應(yīng)用,并可顯著提升性能(如對于SmallVector,boost::static_vector也是基于相同概念實現(xiàn))。現(xiàn)代CPU是非常復(fù)雜的設(shè)備,幾乎不可能預(yù)測某段代碼的運行方式。CPU指令的執(zhí)行受制于眾多因素,包括許多變化的組件。
1、機器碼布局
機器碼布局指編譯器將源代碼轉(zhuǎn)化為串行的字節(jié)列。由于編譯器會影響到二進制文件的性能,因此在將源代碼翻譯為機器碼時,會考慮到指令在內(nèi)存中的放置偏移位置。
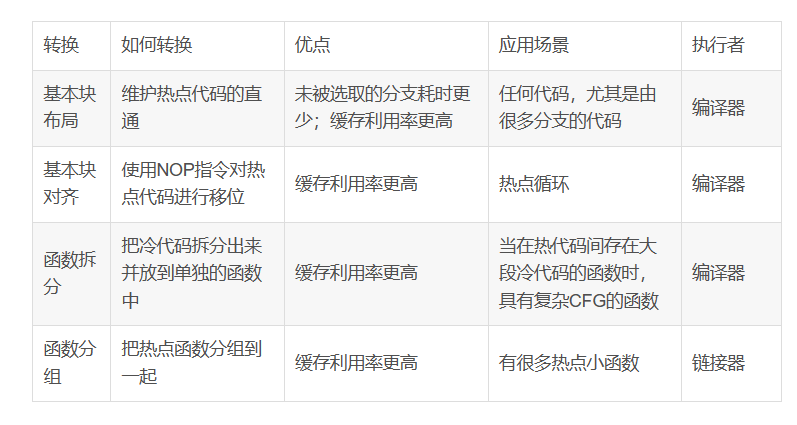
2、基本塊
基本塊是指具有單個入口和出口的指令序列,可以有多個前驅(qū)和后繼,但在基本塊中間沒有任何指令可以跳出基本塊。這種結(jié)構(gòu)確保了基本塊中的每條代碼只會被執(zhí)行一次,從而大大減少控制流圖分析和轉(zhuǎn)換的問題。
3、基本塊布局
// hot path
if (cond)
coldFunc();
// hot path again
如果條件cond通常為真,那么選擇默認布局,因為另一個布局會導(dǎo)致兩次而不是一次跳轉(zhuǎn)。coldFunc是錯誤處理函數(shù),不太可能經(jīng)常執(zhí)行,因此選擇保持熱點代碼間的直通,并將選取分支轉(zhuǎn)化為未被選取分支。選擇這種布局的原因如下:
1)CPU每個時鐘可以執(zhí)行2個未被選擇的分支,但每2個時鐘周期才能執(zhí)行一個被選取的分支,因此未被選取的分支比被選取時耗時更少。
2)所有熱點代碼都是連續(xù)的,沒有緩存行碎片化問題,因此可以更充分利用指令和微操作緩存。
3)每個被選取的跳轉(zhuǎn)指令都意味著跳轉(zhuǎn)之后的字節(jié)都是無效的,因此被選取的分支對于讀取單元來說也更耗時。
4、基本塊對齊
性能因指令在內(nèi)存中的偏移而變化。若循環(huán)跨越多條緩存行,CPU前端可能會出現(xiàn)性能問題。因此,可以使用nop指令將循環(huán)提前,使其整個循環(huán)位于一條緩存行中。
LLVM使用-mllvm-align-all-blocks對齊基本塊,但可能造成性能劣化。插入nop指令會增加程序開銷,尤其在關(guān)鍵路徑上。盡管nop指令不需要執(zhí)行,但仍需從內(nèi)存中讀取、解碼和執(zhí)行,消耗前端數(shù)據(jù)結(jié)構(gòu)和記賬緩沖區(qū)空間。
為精確控制對齊,可使用ALIGN匯編指令。開發(fā)人員先生成匯編列表,然后插入ALIGN指令以滿足特定實驗場景的需求。
5、函數(shù)拆分
函數(shù)拆分是為了優(yōu)化在熱點路徑具有復(fù)雜CFG和大量冷代碼的函數(shù)。通過將冷代碼移動到單獨的函數(shù)中,可以避免在運行時加載不必要的代碼,從而改善內(nèi)存占用情況。
在優(yōu)化后的代碼中,將原來的函數(shù)拆分為兩個函數(shù),一個包含熱點代碼,另一個包含冷代碼。通過將冷代碼移動到單獨的函數(shù)中,可以避免在運行時加載不必要的代碼,從而改善內(nèi)存占用情況。同時,使用__attribute__((noinline))禁止內(nèi)聯(lián)冷函數(shù),以避免冷函數(shù)被內(nèi)聯(lián)到熱點代碼中,從而影響性能。
通過將熱點代碼和冷代碼分離,可以更好地利用CPU前端數(shù)據(jù)結(jié)構(gòu)(指令緩存和DSB),提高CPU的利用率。同時,將新函數(shù)放在.text段之外,可以避免在運行時加載不必要的代碼,從而改善內(nèi)存占用情況。
6、函數(shù)分組
熱點函數(shù)可以聚集在一起,以提高CPU前端緩存的利用率,降低緩存行的讀取需求。鏈接器負責(zé)規(guī)劃程序中所有函數(shù)的排列布局,LLD鏈接器通過--symbol-ordering-file優(yōu)化函數(shù)布局。HFSort工具能根據(jù)剖析數(shù)據(jù)自動生成分區(qū)排序文件。
7、基于剖析文件的編譯優(yōu)化
大多數(shù)編譯器具備一組轉(zhuǎn)換功能,可根據(jù)剖析數(shù)據(jù)來調(diào)整算法,這被稱為PGO(Profile-Directed Optimization)。剖析數(shù)據(jù)生成有兩種方式:代碼插樁和基于采樣的剖析。
1)利用LLVM編譯器通過-fprofile-instr-generate參數(shù)生成插樁代碼,再使用-fprofile-inst-use參數(shù)利用剖析數(shù)據(jù)重新編譯程序,生成PGO調(diào)優(yōu)的二進制文件。
2)基于采樣生成編譯器所需的剖析數(shù)據(jù),然后通過AutoFDO工具將linux perf生成的采樣數(shù)據(jù)轉(zhuǎn)換為GCC和LLVM編譯器可理解的形式。但編譯器會假設(shè)所有負載表現(xiàn)相同。
8、對ITLB的優(yōu)化
內(nèi)存中的虛地址到物理地址轉(zhuǎn)換是前端優(yōu)化的關(guān)鍵領(lǐng)域之一。通過將性能關(guān)鍵代碼映射到大頁上,可以減輕ITLB(指令翻譯緩沖)的壓力。這需要重新鏈接二進制文件,確保代碼段在適當(dāng)?shù)捻撨吔鐚R。除使用大頁,還可以采用其他技術(shù)來優(yōu)化指令緩存性能,如重新排列函數(shù)以使熱點函數(shù)更集中,使用LTO(鏈接時間優(yōu)化)/IPO(內(nèi)聯(lián)函數(shù)優(yōu)化)來減小熱點區(qū)域的大小,使用PGO(基于剖析的編譯優(yōu)化)并避免過度內(nèi)聯(lián)。
二、CPU后端優(yōu)化
在計算機處理過程中,前端完成取指和譯碼后,如果后端資源不足無法處理新的微操作,會導(dǎo)致前端無法繼續(xù)交付微操作。例如,當(dāng)數(shù)據(jù)緩存未命中或除法單元過載時,后端無法高效處理指令,從而造成前端停滯。
1、存儲bound
當(dāng)應(yīng)用程序進行大量內(nèi)存訪問并花費較長時間等待內(nèi)存訪問完成時,被視為存儲bound。這意味著需要優(yōu)化存儲訪問情況,減少存儲訪問次數(shù)或升級存儲子系統(tǒng)。
在TMA中,存儲bound會統(tǒng)計CPU流水線由于按需加載或存儲指令而阻塞的部分槽位。解決此類性能問題的第一步是定位導(dǎo)致高“存儲bound”指標(biāo)的訪存操作,并識別具體的訪存操作。然后開始進行調(diào)優(yōu)。
1)緩存友好的數(shù)據(jù)類型
關(guān)于緩存友好算法和數(shù)據(jù)結(jié)構(gòu)是性能關(guān)鍵要素之一,重點在于時間和空間局部性原則,目標(biāo)是從緩存中高效地讀取所需的數(shù)據(jù)。
按順序訪問數(shù)據(jù)
利用緩存空間局部性的最佳方法是順序訪問內(nèi)存。標(biāo)準(zhǔn)實現(xiàn)二分搜索不會利用空間局部性,而解決這個問題的方法之一是Eytzinger布局存儲數(shù)組元素。其思想是維護一個隱式二叉搜索樹,并使用類似廣度優(yōu)先搜索的布局將二叉搜索樹打包到一個數(shù)組中。
使用適當(dāng)容器
幾乎所有語言都提供各種現(xiàn)成的容器,理解它們底層存儲機制和性能影響至關(guān)重要。在處理數(shù)據(jù)時,需要根據(jù)代碼的具體情況來選擇合適的數(shù)據(jù)存儲方式。
打包數(shù)據(jù)
提高內(nèi)存層次利用率的一種方式是使數(shù)據(jù)更加緊湊。打包數(shù)據(jù)的一個經(jīng)典例子就是使用位存儲,可以極大地減少來回傳輸?shù)膬?nèi)存數(shù)量,同時節(jié)省緩存空間。然而,由于b和a與c共享一個機器字,編譯器需要執(zhí)行移位操作。在額外計算的開銷比低效內(nèi)存轉(zhuǎn)移開銷低的情況下,打包數(shù)據(jù)是值得的。
對于結(jié)構(gòu)體或類中的字段布局,程序員可以通過重新排列來減少內(nèi)存的使用,同時避免由編譯器添加結(jié)構(gòu)體填充。例如,如果有一個結(jié)構(gòu)體包含一個布爾值和一個整數(shù),最好將整數(shù)放在前面,因為這樣可以使用整數(shù)的位來存儲布爾值,從而節(jié)省內(nèi)存。
對齊與填充
當(dāng)變量存儲在能被其大小整除的內(nèi)存地址時,訪問效率最高。對齊可能導(dǎo)致未使用的字節(jié)形成空位,降低內(nèi)存帶寬利用率。為避免邊緣情況如緩存爭用和偽共享,需要填充數(shù)據(jù)結(jié)構(gòu)成員。例如,兩個線程訪問同一結(jié)構(gòu)體的不同字段時,緩存一致性問題可能導(dǎo)致程序運行速度明顯降低。通過填充方法,可確保結(jié)構(gòu)體的不同字段位于不同的緩存行。當(dāng)使用malloc進行動態(tài)分配時,要確保返回的內(nèi)存地址滿足平臺目標(biāo)的最小對齊要求。最重要的是,對于SIMD代碼,當(dāng)使用編譯器向量化內(nèi)建函數(shù)時,地址通常要被16、32或64整除。
動態(tài)內(nèi)存分配
malloc的替代方案往往更快、更可擴展,更能有效地處理內(nèi)存碎片問題。動態(tài)內(nèi)存分配的一個挑戰(zhàn)在于,多個線程可能同時嘗試申請內(nèi)存,導(dǎo)致效率降低。
為解決此問題,可以使用自定義分配器加速內(nèi)存分配。這類分配器的優(yōu)勢在于開銷較低,因為避免了每次內(nèi)存分配都進行系統(tǒng)調(diào)用。同時,也具有高度靈活性,允許開發(fā)者根據(jù)操作系統(tǒng)的內(nèi)存區(qū)域來實現(xiàn)自己的分配策略。一種策略是維護兩個不同的分配器,各自負責(zé)熱數(shù)據(jù)和冷數(shù)據(jù)的分配。將熱數(shù)據(jù)放在一起可以共享高速緩存行,從而提高內(nèi)存帶寬利用率和空間局部性。同時,這種策略還可以提高TLB利用率,因為熱數(shù)據(jù)占用的內(nèi)存頁更少。此外,自定義內(nèi)存分配器還可以利用線程本地存儲來實現(xiàn)每個線程的獨立分配,從而消除線程間的同步問題。
針對存儲器層次調(diào)優(yōu)代碼
某些應(yīng)用程序的性能取決于特定層緩存的大小,最著名的例子是使用循環(huán)分塊來改進矩陣乘法。
2)顯式內(nèi)存預(yù)取
當(dāng)arr數(shù)組規(guī)模較大時,硬件預(yù)取可能無法識別訪存模式并提前獲取所需數(shù)據(jù)。為在計算j與arrp[j]請求之間的時間窗口內(nèi)手動添加預(yù)取指令,可使用__builtin_prefetch,如下所示:
for (int i = 0; i < N; ++i) {
int j = calNextIndex();
__builtin_prefetch(arr + j, 0, 1);
// ...
doSomeExtensiveComputation();
// ...
x = arr[j];
}
為使預(yù)取有效,需提前插入預(yù)取指示,確保用于計算的值在計算時已加載到緩存中,同時避免過早插入預(yù)取提示以避免污染緩存。
顯式內(nèi)存預(yù)取不可移植,一個平臺上的性能提升無法保證在另一個平臺上也有相同效果。此外,顯式預(yù)取指令會增加代碼大小并增加CPU前端的壓力。
3)針對DTLB優(yōu)化
TLB分為ITLB和DTLB在L1,統(tǒng)一TLB在L2。L1 ITLB未命中時延很小,通常被亂序執(zhí)行隱藏。統(tǒng)一TLB未命中會調(diào)用頁遍歷器,可能導(dǎo)致性能損失。
Linux默認頁面大小為4KB,增大頁大小可減少TLB條目和未命中次數(shù)。Intel 64和AMD 64支持2MB和1GB巨型頁。使用大頁的TLB更緊湊,遍歷內(nèi)核頁表的代價減少。
在Linux系統(tǒng)中,應(yīng)用程序使用大頁的方法有顯式大頁和透明大頁。使用libhugetlbfs庫可動態(tài)分配大頁內(nèi)存。開發(fā)者可以通過以下方式控制對大頁的訪問:帶MAP_HUGETLB參數(shù)使用mmap;掛載hugetlbfs文件系統(tǒng)中的文件使用mmap;對SHM_HUGETLB參數(shù)使用shmget。
2、計算bound
主要有兩種性能瓶頸:硬件計算資源短缺和軟件指令依賴關(guān)系。前者指執(zhí)行單元過載或執(zhí)行端口爭用,發(fā)生在負載頻繁執(zhí)行大量繁重指令時;后者指程序數(shù)據(jù)流或指令流中的依賴關(guān)系限制了性能。下面討論函數(shù)內(nèi)聯(lián)、向量化和循環(huán)優(yōu)化等常見優(yōu)化手段,旨在減少執(zhí)行指令總量,提高性能。
1)函數(shù)內(nèi)聯(lián)
內(nèi)聯(lián)函數(shù)不僅可以消除函數(shù)調(diào)用的開銷,還可以擴展編譯器分析的范圍,進行更多優(yōu)化。但內(nèi)聯(lián)也可能增加編譯后文件的大小和編譯時間。編譯器通常基于成本模型來決定是否內(nèi)聯(lián)函數(shù),例如LLVM會考慮計算成本和調(diào)用次數(shù)。一般而言,小函數(shù)、單一調(diào)用點的函數(shù)更可能被內(nèi)聯(lián),而大型函數(shù)和遞歸函數(shù)通常不會被內(nèi)聯(lián)。通過指針調(diào)用的函數(shù)可以用內(nèi)聯(lián)來代替直接調(diào)用。開發(fā)者可以使用特殊提示(如C++ 11的gnu::always_inline)來強制內(nèi)聯(lián)函數(shù)。另一種方法是剖析數(shù)據(jù)來識別潛在的內(nèi)聯(lián)對象,特別是分析函數(shù)的參數(shù)傳遞和返回頻率。
2)循環(huán)優(yōu)化
循環(huán)是程序中執(zhí)行最頻繁的代碼段,因此大部分執(zhí)行時間都在循環(huán)中消耗。循環(huán)的性能受到內(nèi)存延遲、內(nèi)存帶寬或計算能力的限制。屋頂線模型是一個很好的基于硬件理論最大值的評估不同循環(huán)的方法,TMA分析是另一種處理這種瓶頸的方法。
低層優(yōu)化
通過將循環(huán)中永遠不會改變的表達式移到循環(huán)外,進行循環(huán)不變量外提,有助于提高算術(shù)強度性能。循環(huán)展開可以增加指令級并行,同時減少循環(huán)開銷,但不建議開發(fā)者手動展開任何循環(huán),因為編譯器非常擅長并以最佳方式展開循環(huán)。借助亂序執(zhí)行,處理器具有“內(nèi)嵌的展開器”。循環(huán)強度折疊使用開銷更小的指令代替開銷高的指令,應(yīng)用于所有循環(huán)變量的表達式和數(shù)組索引,編譯器通過分析變量的值在循環(huán)迭代中的演變方式來實現(xiàn)。此外,如果循環(huán)內(nèi)部有不變的判斷條件,將其移到循環(huán)外,即進行循環(huán)判斷外提,也有助于提高性能。
高層優(yōu)化
此類優(yōu)化策略會深度改變循環(huán)結(jié)構(gòu),并可能影響多個嵌套循環(huán)的整體性能。其根本目的是提升內(nèi)存訪問效率,解決內(nèi)存帶寬和時延的瓶頸問題。為實現(xiàn)這個目標(biāo),可以采用以下幾種策略:通過交換嵌套循環(huán)的順序,使得對多維數(shù)組元素的內(nèi)存訪問更加有序,從而消除帶寬和時延的限制;將多維循環(huán)的執(zhí)行范圍合理拆分為多個循環(huán)塊,使得每塊數(shù)據(jù)的訪問能夠與CPU緩存的大小相適配,從而優(yōu)化跨步幅訪存的內(nèi)存帶寬和時延;對于可以合并的情況,將多個獨立的循環(huán)合并在一起,以減少循環(huán)開銷,同時改善內(nèi)存訪問的時間局部性。
但需要注意的是,循環(huán)合并并不總是能提高性能,有時候?qū)⒀h(huán)拆分為多條路徑、預(yù)過濾數(shù)據(jù)、對數(shù)據(jù)進行排序和重組等可能更有效。拆分循環(huán)有助于解決在大循環(huán)中發(fā)生的緩存高度爭用問題,還可以減少寄存器壓力,并且可以借助編譯器對小循環(huán)進行進一步的單獨優(yōu)化。
3)發(fā)現(xiàn)循環(huán)優(yōu)化的機會
編譯優(yōu)化報告顯示轉(zhuǎn)換失敗,需要查看由應(yīng)用程序剖析文件生成的匯編代碼的熱點部分。優(yōu)化的策略應(yīng)從簡單的方案開始嘗試,然后開發(fā)者需明確循環(huán)中的瓶頸,并基于硬件理論最大值評估性能。可以使用屋頂線模型來確定需要分析的瓶頸點,然后嘗試各種變換。
4)使用循環(huán)優(yōu)化框架
多面體框架可用于檢查循環(huán)轉(zhuǎn)換的合法性并自動轉(zhuǎn)換循環(huán)。Polly是基于LLVM的高層循環(huán)和數(shù)據(jù)局部性優(yōu)化器及優(yōu)化基礎(chǔ)設(shè)施,采用基于整數(shù)多面體的抽象數(shù)學(xué)表示來分析和優(yōu)化程序的內(nèi)存訪問模式。要啟用Polly,需要用戶通過顯式的編譯器選項(-mllvm -polly)來啟用,因為LLVM基礎(chǔ)設(shè)施的標(biāo)準(zhǔn)流水線并未默認啟用Polly。
3、向量化
使用SIMD指令可以顯著提高未向量化代碼的運行速度。性能分析的重點之一是確保關(guān)鍵代碼能夠被編譯器正確向量化。如果編譯器無法生成所需的匯編指令,可以使用編譯器內(nèi)建函數(shù)重寫代碼片段。使用編譯器內(nèi)建函數(shù)的代碼與內(nèi)聯(lián)后的匯編代碼類似,可讀性較差。通常可以通過使用編譯注解等方式來指導(dǎo)編譯器進行自動向量化。編譯器可以進行三種向量化操作:內(nèi)循環(huán)自動向量化、外循環(huán)向量化和超字向量化。
1)編譯器自動向量化
編譯器自動向量化受到多種因素阻礙,包括編程語言的固有語義和處理器向量操作的限制。這些因素導(dǎo)致編譯器難以有效地將循環(huán)轉(zhuǎn)換為向量化的代碼。然而,通過合法性檢查、收益檢查和轉(zhuǎn)換三個階段,可以逐步優(yōu)化代碼并提高程序的運行速度。在合法性檢查階段,評估循環(huán)向量化是否滿足一系列條件,以確保生成的代碼正確且有效。在收益檢查階段,比較不同的向量化因子并選擇最優(yōu)的方案,同時考慮代碼的執(zhí)行成本和效率。最后,在轉(zhuǎn)換階段,將通過插入向量化的保護代碼來啟用向量化執(zhí)行,并優(yōu)化代碼以提高運行速度。
2)探索向量化的機會
分析程序中的熱點循環(huán),檢查編譯器已進行哪些優(yōu)化,最簡單方法是查看編譯器向量化標(biāo)記。當(dāng)循環(huán)無法向量化時,編譯器會給出失敗原因。另一種方法是檢查程序的匯編輸出,分析剖析工具的輸出更好。雖然查看匯編費時,但該技能回報高,因為可從匯編代碼中發(fā)現(xiàn)次優(yōu)代碼、缺乏向量化、次優(yōu)向量化因子、執(zhí)行不必要計算等。
向量化標(biāo)記能清晰解釋問題及編譯器不能向量化代碼的原因。gcc 10.2可輸出優(yōu)化報告(使用參數(shù)-fopt-info啟用)。開發(fā)者應(yīng)意識到向量化代碼的隱藏成本,尤其是AVX512可能導(dǎo)致大幅降頻。對于循環(huán)次數(shù)小的循環(huán),強制向量化程序使用小向量化因子或計數(shù)展開以減少循環(huán)處理的元素數(shù)量。
多GPU編程
CUDA提供多GPU編程的功能,包括在一個或多個進程中管理多設(shè)備,使用統(tǒng)一的虛擬尋址直接訪問其他設(shè)備內(nèi)存,GPUDirect,以及使用流和異步函數(shù)實現(xiàn)的多設(shè)備計算通信重疊。
一、從一個GPU到多GPU
在處理大規(guī)模數(shù)據(jù)集時,使用多GPU是提高計算效率和吞吐量的有效方式。多GPU系統(tǒng)通過不同的連接方式,如通過PCIe總線或在集群中的網(wǎng)絡(luò)交換機連接,來實現(xiàn)高效的GPU間通信。在多GPU應(yīng)用程序中,工作負載的分配和數(shù)據(jù)交換模式是關(guān)鍵因素。最基本的模式是各問題分區(qū)在獨立GPU上運行,而更復(fù)雜的模式則需要考慮數(shù)據(jù)如何在設(shè)備間進行最優(yōu)移動以避免數(shù)據(jù)復(fù)制到主機再復(fù)制到另一GPU。
1、在多GPU上執(zhí)行
CUDA的cudaGetDeviceCount函數(shù)可確定系統(tǒng)內(nèi)可用的CUDA設(shè)備數(shù)量。在利用CUDA與多GPU協(xié)作的應(yīng)用程序中,必須顯式指定目標(biāo)GPU。使用cudaSetDevice(int id)函數(shù)可設(shè)置當(dāng)前設(shè)備,該函數(shù)將具有特定ID的設(shè)備設(shè)置為當(dāng)前設(shè)備,與其他設(shè)備無同步,因此開銷較低。
如果在首個CUDA API調(diào)用前未顯示調(diào)用cudaSetDevice函數(shù),則當(dāng)前設(shè)備將自動設(shè)置為設(shè)備0。選定當(dāng)前設(shè)備后,所有CUDA運算將應(yīng)用于此設(shè)備,包括:從主線程分配的設(shè)備內(nèi)存、由CUDA運行時函數(shù)分配的主機內(nèi)存、由主機線程創(chuàng)建的流或事件以及由主機線程啟動的內(nèi)核。
多GPU適用于以下場景:單節(jié)點的單線程、單節(jié)點的多線程、單節(jié)點的多進程以及多節(jié)點的多進程。以下代碼展示如何在主機線程中執(zhí)行內(nèi)核和內(nèi)存拷貝:
for (int i = 0; i < ngpus; i++) { ?
cudaSetDevice(i);
kernel<<>>(...);
cudaMemcpyAsync();
}
由于循環(huán)中的內(nèi)核啟動和數(shù)據(jù)傳輸是異步的,因此在每次操作后,控制將快速返回至主機線程。
2、點對點通信
在計算能力2.0或以上的設(shè)備上,64位應(yīng)用程序執(zhí)行的內(nèi)核可以直接訪問連接到同一PCIe根節(jié)點的GPU全局內(nèi)存,但需使用CUDA點對點API進行設(shè)備間直接通信,該功能需要CUDA4.0或更高版本。點對點訪問和傳輸是CUDA P2P API支持的兩種模式,但當(dāng)GPU連接到不同PCIe根節(jié)點時,將不允許直接點對點訪問,此時可使用CUDA P2P API進行點對點傳輸,但數(shù)據(jù)傳輸會通過主機內(nèi)存進行。
1)啟用點對點訪問
點對點訪問允許GPU直接引用連接到同一PCIe根節(jié)點的其他GPU設(shè)備內(nèi)存上的數(shù)據(jù)。使用cudaDeviceCanAccessPeer檢查設(shè)備是否支持P2P,設(shè)備能直接訪問對等設(shè)備全局內(nèi)存則返回1,否則返回0。在兩個設(shè)備間,必須使用cudaDeviceEnablePeerAccess顯式啟用點對點內(nèi)存訪問,該函數(shù)允許當(dāng)前設(shè)備到peerDevice的點對點訪問,授權(quán)的訪問是單向的。點對點訪問保持啟用狀態(tài),直到被cudaDeviceDisablePeerAccess顯式禁用。32位應(yīng)用程序不支持點對點訪問。
2)點對點內(nèi)存復(fù)制
在兩個設(shè)備之間啟用對等訪問后,可以使用cudaMemcpyPeerAsync函數(shù)異步復(fù)制設(shè)備上的數(shù)據(jù)。該函數(shù)將數(shù)據(jù)從源設(shè)備srcDev傳輸?shù)侥繕?biāo)設(shè)備dstDev。如果srcDev和dstDev連接在同一PCIe根節(jié)點上,數(shù)據(jù)傳輸將沿著PCIe的最短路徑執(zhí)行,無需通過主機內(nèi)存中轉(zhuǎn)。
3、多GPU間同步
多GPU應(yīng)用程序中,流和事件與單一設(shè)備關(guān)聯(lián),典型工作流程包括:選擇GPU集、為每個設(shè)備創(chuàng)建流和事件、分配設(shè)備資源、通過流啟動任務(wù)、查詢和等待任務(wù)完成并清空資源。只有與流關(guān)聯(lián)的設(shè)備才能啟動內(nèi)核和記錄事件。內(nèi)存拷貝可在任何流中進行,與設(shè)備和當(dāng)前狀態(tài)無關(guān)。即使流或事件與當(dāng)前設(shè)備不相關(guān),也可以查詢或同步它們。
二、多GPU間細分計算
1、在多設(shè)備上分配內(nèi)存
在分配多個設(shè)備任務(wù)之前,首先需要確定系統(tǒng)中的可用GPU數(shù)量。通過cudaGetDeviceCount獲取GPU數(shù)量并打印。
接下來,為每個設(shè)備聲明所需的內(nèi)存和流。使用cudaSetDevice為每個設(shè)備分配內(nèi)存和流。
對于每個設(shè)備,分配一定大小的主機內(nèi)存和設(shè)備內(nèi)存,并創(chuàng)建流。為了在設(shè)備和主機之間進行異步數(shù)據(jù)傳輸,還需要分配鎖頁內(nèi)存。
最后,使用循環(huán)為每個設(shè)備執(zhí)行以下操作:
1)設(shè)置當(dāng)前設(shè)備
2)分配設(shè)備內(nèi)存:cudaMalloc
3)分配主機內(nèi)存:cudaMallocHost
4)創(chuàng)建流:cudaStreamCreate
這樣,就為每個設(shè)備分配了內(nèi)存和流,準(zhǔn)備好進行任務(wù)分配和數(shù)據(jù)傳輸。
2、單主機線程分配工作
// 在設(shè)備間分配操作之前,為每個設(shè)備初始化主機數(shù)組的狀態(tài)
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i);
initial(h_A[i], iSize);
initial(h_B[i], iSize);
}
// 在多個設(shè)備間分配數(shù)據(jù)和計算
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i);
cudaMemcpyAsync(d_A[i], h_A[i], iBytes, cudaMemcpyHostToDevice, streams[i]);
cudaMemcpyAsync(d_B[i], h_B[i], iBytes, cudaMemcpyHostToDevice, streams[i]);
iKernel<<>>(d_A[i], d_B[i], d_C[i], iSize);
cudaMemcpyAsync(gpuRef[i], d_C[i], iBytes, cudaMemcpyDeviceToHost, stream[i]);
}
cudaDeviceSynchronize();
這個循環(huán)遍歷多個GPU,為設(shè)備異步地復(fù)制輸入數(shù)組。然后在想要的流中操作iSize個數(shù)據(jù)元素以便啟動內(nèi)核。最后,設(shè)備發(fā)出異步拷貝命令,把結(jié)果從內(nèi)核返回到主機。因為所有的元素都是異步的,所以控制會立即返回到主機線程。
三、多個GPU上的點對點通信
下面將測試兩個GPU之間的單向內(nèi)存復(fù)制;兩個GPU之間的雙向內(nèi)存和內(nèi)核中對等設(shè)備內(nèi)存的訪問3種情況;
1、實現(xiàn)點對點訪問
首先,必須對所有設(shè)備啟用雙向點對點訪問,代碼如下;
// 啟動雙向點對點訪問權(quán)限
inline void enableP2P(int ngpus)
{
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i)
for (int j = 0; j < ngpus; j++)
{
if (i == j)
continue;
int peer_access_available = 0;
cudaDeviceCanAccessPeer(&peer_access_available, i, j);
if (peer_access_avilable)
{
cudaDeviceEnablePeerAccess(j, i);
printf(" > GP%d enbled direct access to GPU%dn", i, j);
}
else
printf("(%d, %d)n", i, j);
}
}
}
函數(shù)enbleP2P遍歷所有設(shè)備對(i,j),如果支持點對點訪問,則使用cudaDeviceEnablePeerAccess函數(shù)啟用雙向點對點訪問。
2、點對點內(nèi)存復(fù)制
不能啟用點對點訪問的最有可能的原因是它們沒有連接到同一個PCIe根節(jié)點上。如果兩個GPU之間不支持點對點訪問,那么這兩個設(shè)備之間的點對點內(nèi)存復(fù)制將通過主機內(nèi)存中轉(zhuǎn),從而降低了性能。
啟用點對點訪問后,下面的代碼在兩個設(shè)備間執(zhí)行ping-pong同步內(nèi)存復(fù)制,次數(shù)為100次。
// ping-pong undirectional gmem copy
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpy(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpy(d_src[0], drc[1], iBytes, cudaMemcpyDeviceToHost);
}
請注意,在內(nèi)存復(fù)制之前沒有指定設(shè)備,因為跨設(shè)備的內(nèi)存復(fù)制不需要顯式地設(shè)定當(dāng)前設(shè)備。如果在內(nèi)存復(fù)制前指定了設(shè)備,也不會影響它的行為。
如需衡量設(shè)備之間數(shù)據(jù)傳輸?shù)男阅埽枰褑雍屯V故录涗浽谕辉O(shè)備上,并將ping-pong內(nèi)存復(fù)制包含在內(nèi)。然后,用cudaEventElapsedTime計算兩個事件之間消耗的時間。
// ping-pong undirectional gmem copy
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpy(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpy(d_src[0], drc[1], iBytes, cudaMemcpyDeviceToHost);
}
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
...
}
cudaSetDevice(0);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsed_time_ms;
cudaEventElapsedTime(&elapsed_time_ms, start, stop);
elapsed_time_ms /= 100;
printf("Ping-pong unidirectional cudaMemcpy: tt %8.2f ms", elapsed_time_ms);
printf("performance: %8.2f GB/sn", (float)iBytes / (elapsed_time_ms * 1e6f));
因為PCIe總線支持任何兩個端點之間的全雙工通道,所以也可以使用異步復(fù)制函數(shù)來進行雙向的且點對點的內(nèi)存復(fù)制。
// bidirectional asynchronous gmem copy
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpyAsync(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpyAsync(d_rcv[0], drcv[1], iBytes, cudaMemcpyDeviceToHost);
}
注意,由于PCIe總線是一次兩個方向上使用的,所以獲得的帶寬增加了一倍。
中國算力產(chǎn)業(yè)發(fā)展及瓶頸
一、市場規(guī)模:服務(wù)器作為算力載體,受益云計算需求提升
1、產(chǎn)業(yè)鏈:下游各領(lǐng)域算力需求帶動服務(wù)器產(chǎn)業(yè)發(fā)展
服務(wù)器產(chǎn)業(yè)鏈上游主要是電子材料及零部件/配套。中游為各類服務(wù)器產(chǎn)品,包括云服務(wù)器、智能服務(wù)器、邊緣服務(wù)器、儲存服務(wù)器。下游需求主體為數(shù)據(jù)中心服務(wù)商、互聯(lián)網(wǎng)企業(yè)、政府部門、金融機構(gòu)、電信運營商等。
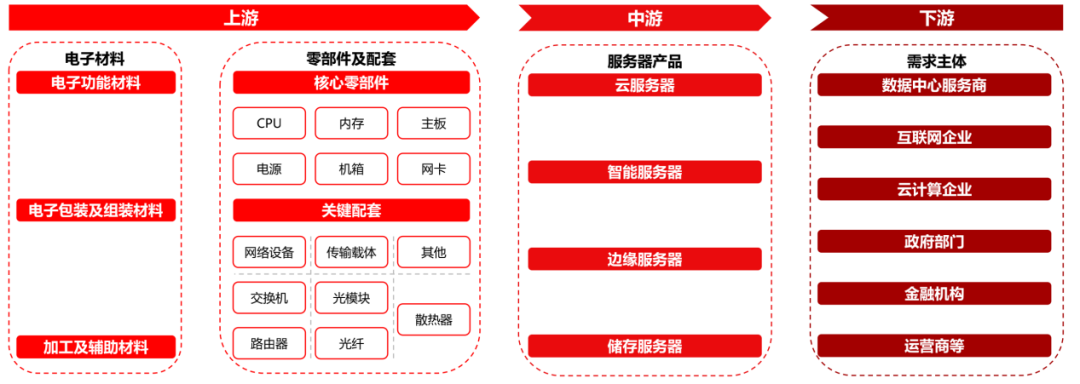
服務(wù)器產(chǎn)業(yè)鏈全景圖
2、云計算:算力應(yīng)用互聯(lián)網(wǎng)需求最大,其次為政府、服務(wù)等
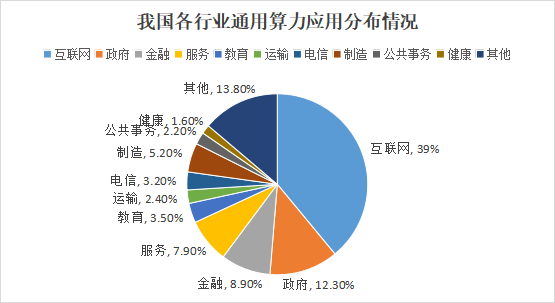
在通用算力領(lǐng)域,互聯(lián)網(wǎng)行業(yè)依然是算力需求最大的行業(yè),占據(jù)了通用算力的39%。電信行業(yè)加大了對算力基礎(chǔ)設(shè)施的投入,算力份額首次超過政府行業(yè),位列第二。而政府、服務(wù)、金融、制造、教育、運輸?shù)刃袠I(yè)位列三到八位。
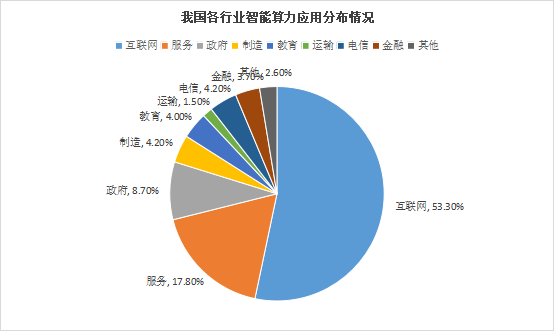
在智能算力領(lǐng)域,互聯(lián)網(wǎng)行業(yè)對數(shù)據(jù)處理和模型訓(xùn)練的需求持續(xù)增長,成為智能算力需求最大的行業(yè),占據(jù)了智能算力的53%。服務(wù)行業(yè)正在快速從傳統(tǒng)模式轉(zhuǎn)向新興智慧模式,其算力份額占比位列第二。而政府、電信、制造、教育、金融、運輸?shù)刃袠I(yè)分列第三到八位。
2、云計算:中國市場增速快于全球,預(yù)計2025年突破萬億元
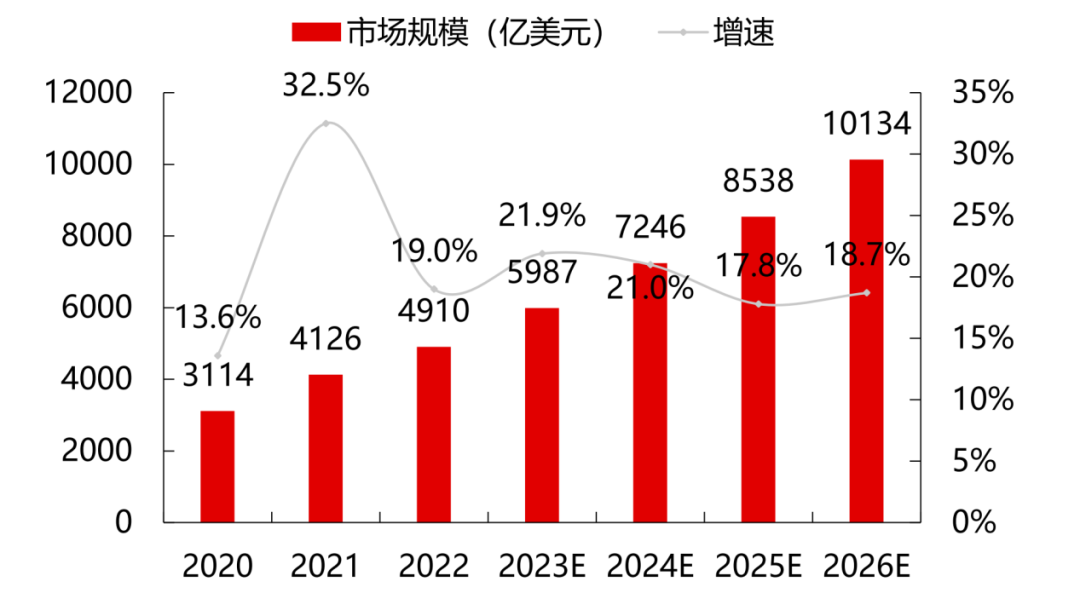
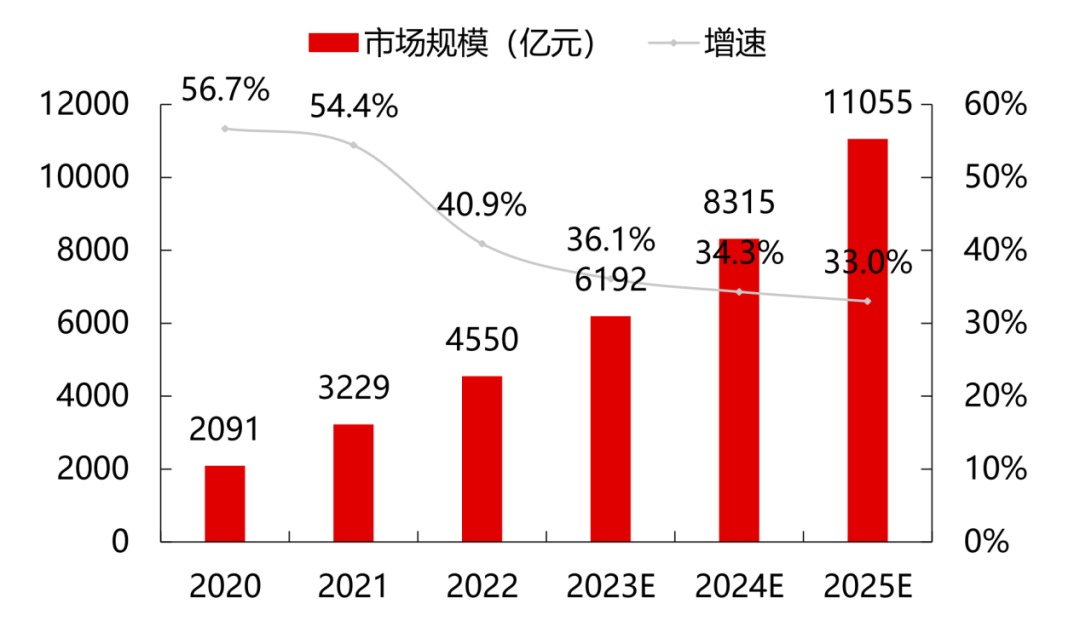
根據(jù)Gartner數(shù)據(jù),2022年全球云計算市場規(guī)模達到4910億美元,同比增長19%,但較2021年同比下降13.5%。而根據(jù)中國信息通信研究院的統(tǒng)計,2022年中國云計算市場規(guī)模達到4550億元,同比增長40.91%。
全球云計算市場規(guī)模及增速
云計算仍然是新技術(shù)融合和業(yè)態(tài)發(fā)展的重要推動力。預(yù)計在大模型和算力需求的刺激下,市場將繼續(xù)保持穩(wěn)定增長,到2026年全球云計算市場將突破萬億美元。相比全球19%的增速,中國云計算市場仍處于快速發(fā)展階段,在大經(jīng)濟頹勢下仍保持較高的抗風(fēng)險能力,預(yù)計到2025年我國云計算整體市場規(guī)模將突破萬億元。
中國云計算市場規(guī)模及增速
3、服務(wù)器:銷售端頭部集中,采購端以科技巨頭為主
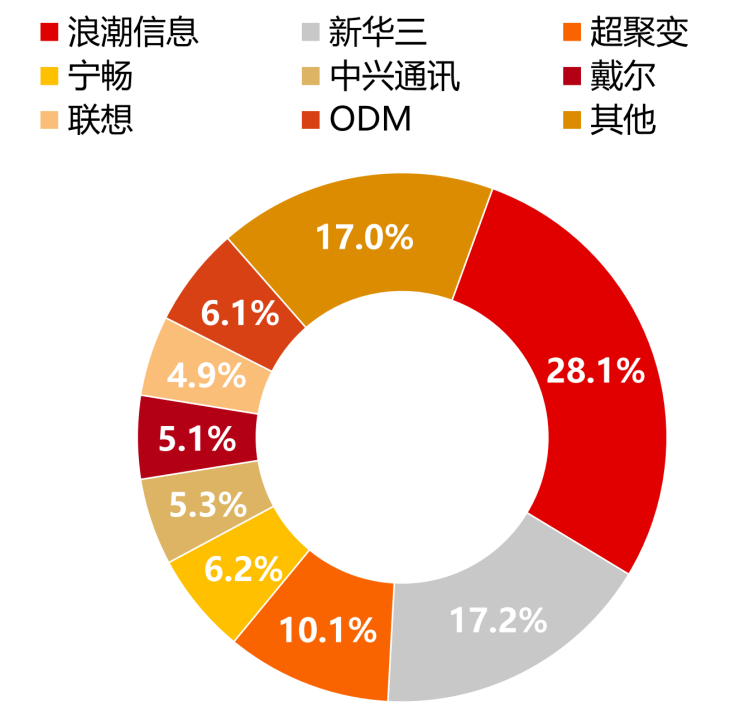
根據(jù)IDC之前公布的數(shù)據(jù),2022年中國服務(wù)器市場的主要供應(yīng)商包括浪潮信息、新華三、超聚變、寧暢和中興通訊。
2022年中國服務(wù)器市份額情況
國內(nèi)AI服務(wù)器行業(yè)采用CPU+加速芯片的架構(gòu)形式,在進行模型訓(xùn)練和推斷時具有效率優(yōu)勢。浪潮信息在國內(nèi)市場份額較高,其次為新華三、寧暢、安擎等。
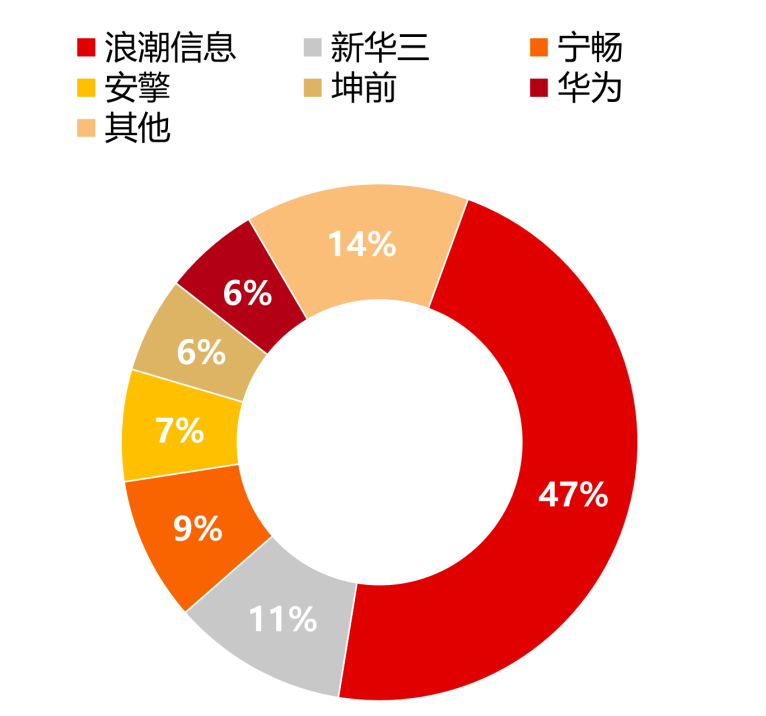
2022年中國AI服務(wù)器市份額情況
隨著云計算、移動互聯(lián)網(wǎng)、物聯(lián)網(wǎng)、大數(shù)據(jù)、人工智能等技術(shù)的興起,互聯(lián)網(wǎng)巨頭逐漸取代政府和銀行等部門成為服務(wù)器的主要采購方。在2012年之前,服務(wù)器的下游客戶主要是政府、銀行等金融機構(gòu)、電信和其他大型企業(yè)。然而,現(xiàn)在服務(wù)器的下游客戶主要以科技巨頭為主,如海外亞馬遜、微軟、谷歌以及國內(nèi)阿里、騰訊等為代表的云計算巨頭逐步成為服務(wù)器市場的主要采購客戶。
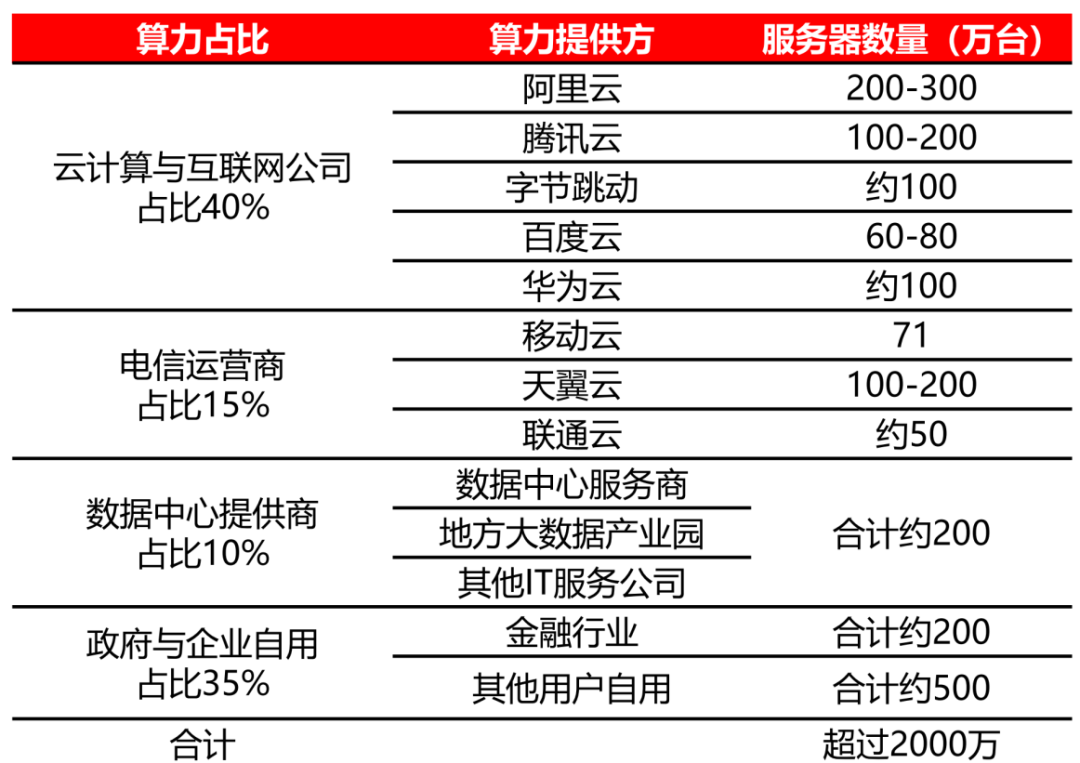
2022年中國主要云廠商服務(wù)器規(guī)模
根據(jù)IDC的預(yù)測數(shù)據(jù),2023年全球服務(wù)器市場規(guī)模同比幾乎持平,而2024年及以后服務(wù)器市場將保持8-11%的增速,預(yù)計到2027年市場規(guī)模將達到1780億美元。
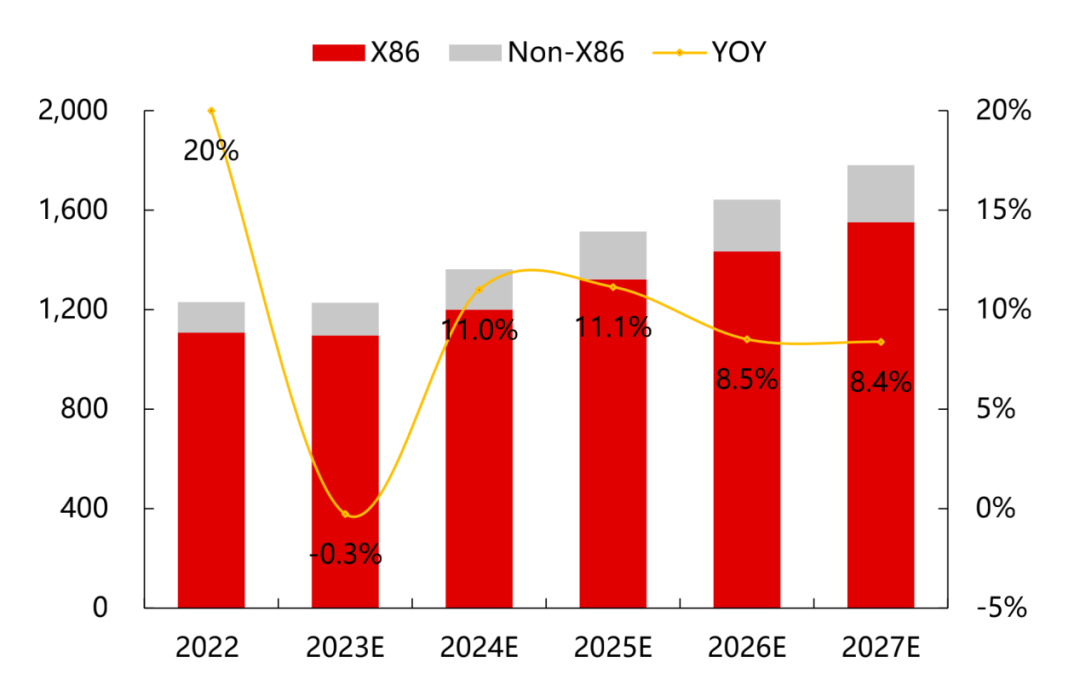
2022-2027E全球服務(wù)器市場規(guī)模(億美元)
2022年中國服務(wù)器市場規(guī)模約為273.4億美元,同比增長9%,增速有所放緩。根據(jù)華經(jīng)產(chǎn)業(yè)研究院的數(shù)據(jù),2023年市場規(guī)模將達到308億美元,增速為13%。隨著東數(shù)西算項目的推進、海量數(shù)據(jù)運算和存儲需求的快速增長等因素的影響,中國服務(wù)器整體的采購需求將進一步增加。IDC預(yù)測,到2027年中國AI服務(wù)器市場規(guī)模將達到164億美元。
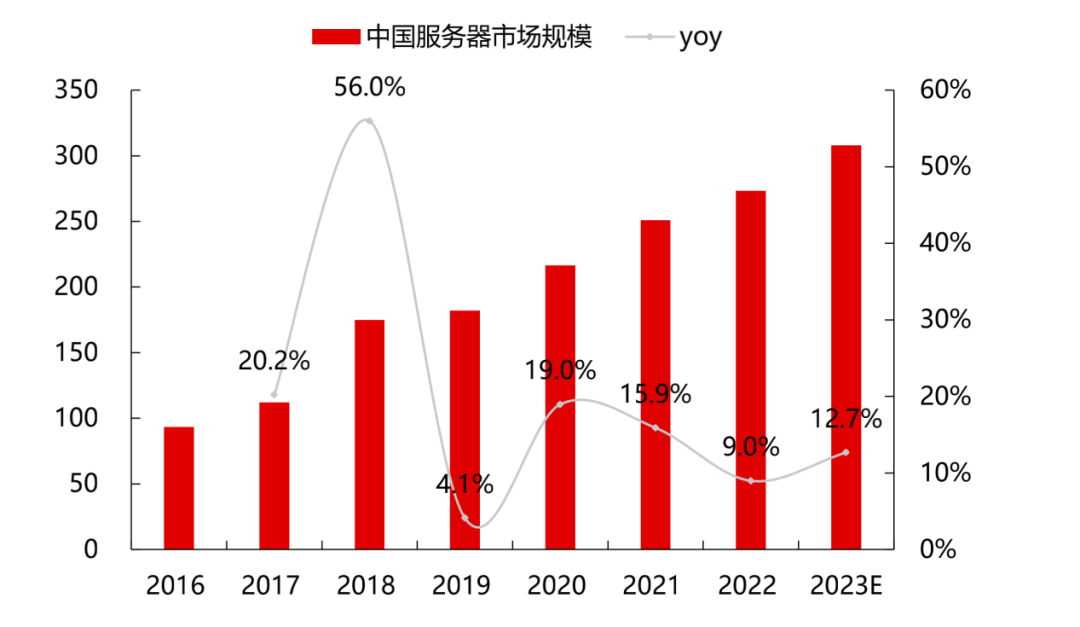
2016-2023E中國服務(wù)器市場規(guī)模(億美元)
二、底層關(guān)鍵: CPU是服務(wù)器的大腦,國產(chǎn)替代空間廣闊
1、作用關(guān)鍵:CPU是服務(wù)器的大腦,GPU并行計算能力很強
CPU是服務(wù)器的控制中心,負責(zé)完成布局謀略、發(fā)號施令、控制行動等任務(wù),其結(jié)構(gòu)包括運算器、控制單元、寄存器、高速緩存器和通訊的總線。GPU由于圖形渲染、數(shù)值分析、AI推理等底層邏輯需要將繁重的數(shù)學(xué)任務(wù)拆解,利用GPU多流處理器機制,將大量運算拆解為小運算,并行處理。CPU和GPU是兩種不同的處理器,CPU是程序控制、順序執(zhí)行的通用處理器,而GPU是用于特定領(lǐng)域分析的專用處理器,受CPU控制。在許多終端設(shè)備中,CPU和GPU通常集成在一個芯片中,同時具備CPU或GPU處理能力。
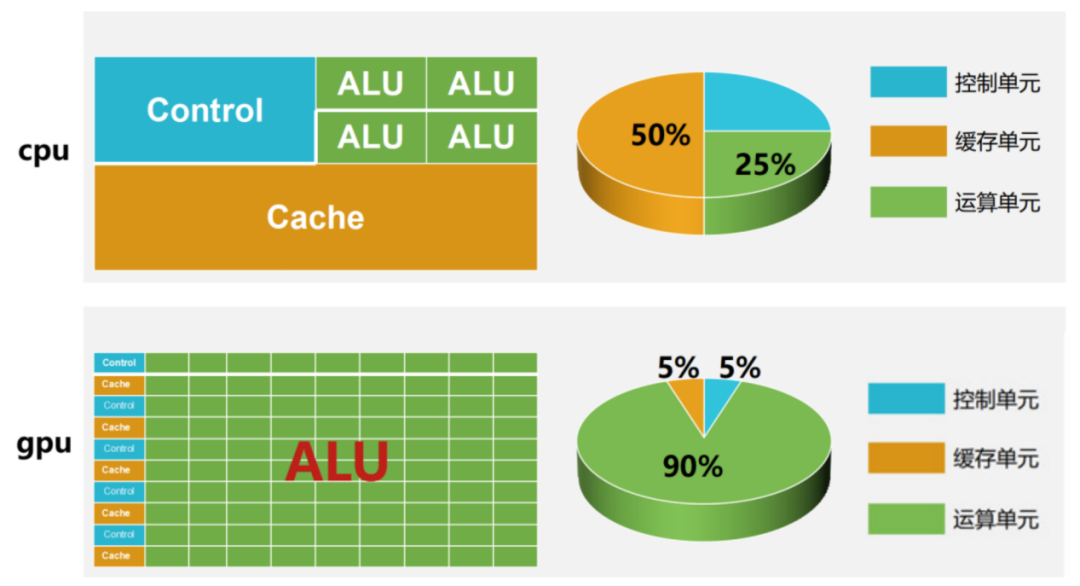
GPU投入更多晶體管進行數(shù)據(jù)處理,并行運算能力強
2、價值關(guān)鍵:CPU、GPU占據(jù)各類服務(wù)器的硬件成本高
服務(wù)器的硬件成本構(gòu)成上,CPU及芯片組、內(nèi)存和外部存儲是主要部分:在普通服務(wù)器中,CPU及芯片組約占32%,內(nèi)存約占27%,外部存儲約占18%,其他硬件約占23%。而在AI服務(wù)器上,GPU的成本占比則遠高于其他部分,可能接近整體成本的70%。從普通服務(wù)器升級到AI訓(xùn)練服務(wù)器時,其他單臺服務(wù)器價值量增量較大的部件包括內(nèi)存、SSD、PCB、電源等,都有數(shù)倍的提升。
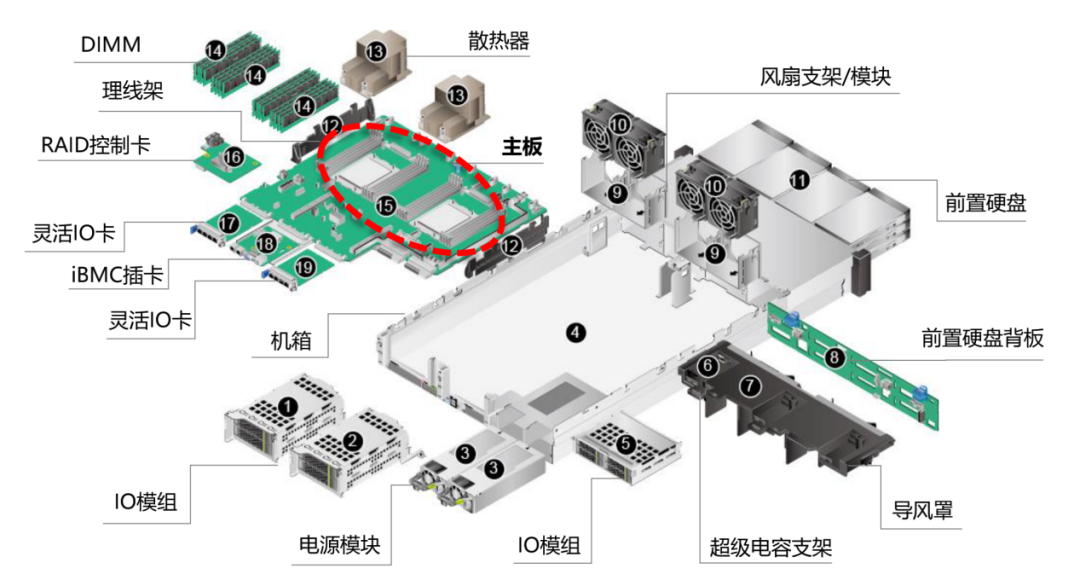
服務(wù)器內(nèi)部拆解示意圖
3、處理器:CPU主導(dǎo)地位,GPU增長迅猛
根據(jù)Yole Intelligence的報告,預(yù)計到2028年處理器市場的收入將達到2420億美元,復(fù)合年增長率為8%。CPU市場的主導(dǎo)地位將得到鞏固,2028年市場規(guī)模將達到970億美元,復(fù)合年增長率為6.9%。GPU市場也將實現(xiàn)顯著增長,2028年市場規(guī)模將達到550億美元,復(fù)合年增長率為16.5%。在處理器市場上,英特爾、AMD、英偉達等巨頭以及紫光展銳主導(dǎo)著市場。在國內(nèi)外服務(wù)器所使用的處理器方面,英特爾、AMD、英偉達、龍芯、兆芯、鯤鵬、海光、飛騰、申威、昇騰等占主導(dǎo)地位。
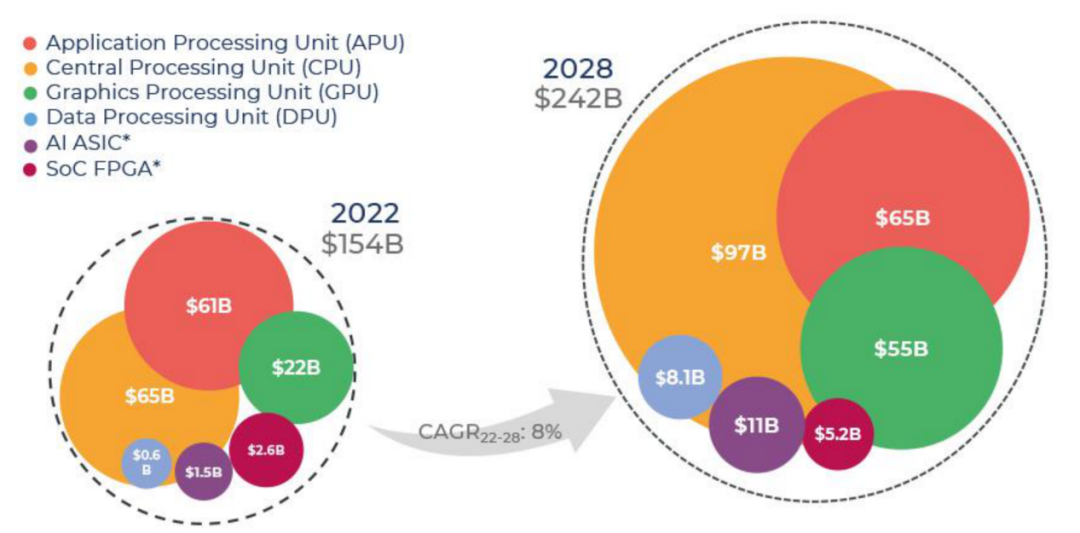
2022-2028年按處理器類型劃分的處理器收入預(yù)測
4、我國在美國多輪制裁下不斷進行科技攻堅
自2019年5月至2020年9月,美國政府對華為實施多輪制裁,導(dǎo)致華為5G手機芯片供應(yīng)被切斷,華為手機銷量大幅下滑。此后,美國針對我國半導(dǎo)體領(lǐng)域的限制不斷升級。然而,華為最新旗艦機型采用了7nm工藝的麒麟9000s芯片,標(biāo)志著中國在芯片設(shè)計和制造領(lǐng)域的里程碑。
2023年10月17日,美國商務(wù)部工業(yè)和安全局公布了新的尖端芯片出口管制規(guī)則,共計近500頁,全面限制美國芯片巨頭如英偉達、英特爾等生產(chǎn)的“特供版”芯片出口到中國及40余個國家。此外,還更新了半導(dǎo)體設(shè)備和技術(shù)相關(guān)的“長臂管轄”,擴大荷蘭***企業(yè)ASML不可對華出口機型范圍,并限制波及中國之外20余個國家。同時,將壁仞科技、摩爾線程等13個中國實體加入美國管制清單,限制中國企業(yè)通過代工廠生產(chǎn)先進芯片。

10月17日美國商務(wù)部工業(yè)和安全局公布管制新規(guī)
三、算力的瓶頸在哪里,機會就會在哪里
算力是現(xiàn)代計算機技術(shù)的核心,其瓶頸主要存在于數(shù)據(jù)傳輸和存儲方面。目前,計算機普遍采用馮諾依曼架構(gòu),數(shù)據(jù)存儲和數(shù)據(jù)計算分開,算力容易被卡在數(shù)據(jù)傳輸,而非真正的計算。算力分為四層,每一層都需要解決如何讓數(shù)據(jù)連接更快的問題。
1、GPU內(nèi)部
GPU內(nèi)部的計算單元與顯存之間的數(shù)據(jù)傳輸是性能提升的瓶頸,同時多個GPU間的協(xié)同計算也受到數(shù)據(jù)傳輸速度的限制。傳統(tǒng)GPU通常采用GDDR內(nèi)存,這種內(nèi)存是平面封裝,導(dǎo)致數(shù)據(jù)傳輸速度跟不上GPU的計算速度。為解決這一問題,升級后的方案采用HBM內(nèi)存技術(shù)。HBM內(nèi)存是垂直封裝,能夠提供更大的帶寬,從而將數(shù)據(jù)更快地傳輸?shù)紾PU的計算單元中。例如,HBM2的帶寬高達256GB/s,比傳統(tǒng)的GDDR內(nèi)存快十倍以上。
2、AI服務(wù)器
每臺AI服務(wù)器都由多個GPU組成(4個、8個甚至更多),GPU需要進行協(xié)同計算。然而,它們之間的數(shù)據(jù)傳輸速度成為性能的瓶頸。在這方面,英偉達GPU連接技術(shù)最為先進,使用的是其NVLink協(xié)議,每秒傳輸速度高達50GB。華為也擁有自己的HCCS協(xié)議,帶寬表現(xiàn)不錯,每秒30GB,與英偉達沒有量級的差異。然而,其他傳統(tǒng)的服務(wù)器只采用PCIe 5標(biāo)準(zhǔn)接口,每通道傳輸速度只有4GB,不到英偉達的十分之一。因此,為提高數(shù)據(jù)傳輸速度并解決該瓶頸問題,需要采用更先進的技術(shù)和協(xié)議。
3、數(shù)據(jù)中心
數(shù)據(jù)中心由上百甚至上千臺AI服務(wù)器組成計算集群,服務(wù)器之間需要快速的數(shù)據(jù)連接。英偉達采用專用的InfiniBand網(wǎng)絡(luò),而其他廠商則使用ROC高速以太網(wǎng)網(wǎng)絡(luò)。盡管這兩種網(wǎng)絡(luò)在物理層都使用光纖連接,但都離不開光模塊。無論是數(shù)據(jù)發(fā)送還是接收,無論是服務(wù)器端還是交換機端,都需要光模塊。今年,光模塊的技術(shù)從400G升級到800G,因為國內(nèi)廠商在光模塊制造領(lǐng)域的占比很高,因此這一塊的業(yè)績能夠真正實現(xiàn),導(dǎo)致光模塊技術(shù)在算力領(lǐng)域被炒作得最多。
4、數(shù)據(jù)網(wǎng)絡(luò)
不同地點和城市的數(shù)據(jù)中心可以組成一個龐大的算力網(wǎng)絡(luò),通過調(diào)度和統(tǒng)籌,終端用戶輕松地使用最快且最便宜的算力資源。目前,算力網(wǎng)絡(luò)的發(fā)展趨勢是采用云-邊-端的架構(gòu),旨在解決數(shù)據(jù)傳輸?shù)膯栴}。其中,邊緣計算是最為熱門的技術(shù)之一。邊緣計算并不僅僅是指手機和智能車輛,而是指在傳統(tǒng)的云計算中心之外,更靠近終端地方增加一層直接計算能力,以節(jié)省數(shù)據(jù)傳輸?shù)某杀竞蜁r間。因此,未來的大趨勢是云的AI算力、邊緣的AI算力和用戶端的AI算力相互結(jié)合,共同推動人工智能技術(shù)的發(fā)展。
藍海大腦深度學(xué)習(xí)大數(shù)據(jù)平臺
藍海大腦深度學(xué)習(xí)大數(shù)據(jù)平臺是面向多源空間數(shù)據(jù)的處理平臺,集成存儲、計算和數(shù)據(jù)處理軟件,具有高效、易操作、低成本、多層次擴展和快速部署等顯著優(yōu)勢,在測繪、農(nóng)業(yè)、林業(yè)、水利、環(huán)保等領(lǐng)域大大提升圖像處理能力,保護投資,高效應(yīng)對大數(shù)據(jù)挑戰(zhàn),加速業(yè)務(wù)突破和轉(zhuǎn)型。
一、主要技術(shù)指標(biāo)
可 靠 性:平均故障間隔時間MTBF≥15000 h
工作溫度:5~40 ℃
工作濕度:35 %~80 %
存儲溫度:-40~55 ℃
存儲濕度:20 %~90 %
聲 噪:≤35dB

二、特點及優(yōu)勢:
基于統(tǒng)一的整體架構(gòu),采用先進成熟可靠的技術(shù)與軟硬件平臺,保證基礎(chǔ)數(shù)據(jù)平臺易擴展、易升級、易操作、易維護等特性。基于業(yè)界熱門,且領(lǐng)先的 Spark 技術(shù),極速提高平臺的整體計算性能。
支持基礎(chǔ)數(shù)據(jù)模型、應(yīng)用分析模型、前端應(yīng)用的擴展性;支持在統(tǒng)一系統(tǒng)架構(gòu)中服務(wù)器、存儲、I/O 設(shè)備等的可擴展性。
制定并實施基礎(chǔ)數(shù)據(jù)平臺高可用性方案、運行管理監(jiān)控制度、運行維護制度、故障處理預(yù)案等,保證系統(tǒng)在多用戶、多節(jié)點等復(fù)雜環(huán)境下的可靠性。
高效性:在規(guī)定時間內(nèi)完成數(shù)據(jù)寫入操作,并將數(shù)據(jù)寫入對數(shù)據(jù)分析的影響降到最低;提升實現(xiàn)規(guī)劃要求的數(shù)據(jù)查詢和統(tǒng)計分析速度。
數(shù)據(jù)質(zhì)量貫穿基礎(chǔ)數(shù)據(jù)平臺系統(tǒng)建設(shè)的每個環(huán)節(jié),基礎(chǔ)數(shù)據(jù)平臺系統(tǒng)通過合理的數(shù)據(jù)質(zhì)量管理解決方案保證數(shù)據(jù)質(zhì)量。
按國家標(biāo)準(zhǔn)、行業(yè)標(biāo)準(zhǔn)、安全規(guī)范等實現(xiàn)數(shù)據(jù)安全管理。
統(tǒng)一的管理平臺,對系統(tǒng)進行相應(yīng)的性能管理和日志監(jiān)控。
人機接口靈活多樣的展現(xiàn)方式,最終用戶只需進行適當(dāng)?shù)呐嘤?xùn)就可以方便地使用新的分析工具,減少 IT 人員的工作量,加強集群監(jiān)管的時效性。
具有超強影像處理能力,每天(24小時)可處理多達500景對(全色和多光譜)高分一號影像數(shù)據(jù)。
廣泛適用于基礎(chǔ)測繪、農(nóng)業(yè)、林業(yè)、水利、環(huán)保等領(lǐng)域,適合常規(guī)模式下產(chǎn)品生產(chǎn)和應(yīng)急模式下快速影像圖生成。
針對大數(shù)據(jù)原始技術(shù)存在的問題,藍海大腦大數(shù)據(jù)平臺從企業(yè)應(yīng)用角度出發(fā),對 Apache Hadoop 進行了系列技術(shù)開發(fā),形成了適應(yīng)企業(yè)級應(yīng)用的一站式大數(shù)據(jù)平臺,從而滿足各類企業(yè)的要求:
超大數(shù)據(jù)的分布式存儲、流數(shù)據(jù)實時計算要求
滿足大數(shù)據(jù)的高并發(fā)、低延遲查詢請求
分布式應(yīng)用系統(tǒng)異常故障時,業(yè)務(wù)切換
系統(tǒng)線性擴展時,無需增加開發(fā)工作,實現(xiàn)無成本擴展
三、常用配置推薦
1、CPU:
- Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
- Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
- AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
- AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
- Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Gold 6240R 24C/48T,2.4GHz,35.75MB,DDR4 2933,Turbo,HT,165W.1TB
- Intel Xeon Gold 6258R 28C/56T,2.7GHz,38.55MB,DDR4 2933,Turbo,HT,205W.1TB
- Intel Xeon W-3265 24C/48T 2.7GHz 33MB 205W DDR4 2933 1TB
- Intel Xeon Platinum 8280 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W 1TB
- Intel Xeon Platinum 9242 48C/96T 3.8GHz 71.5MB L2,DDR4 3200,HT 350W 1TB
- Intel Xeon Platinum 9282 56C/112T 3.8GHz 71.5MB L2,DDR4 3200,HT 400W 1TB
2、GPU:
- NVIDIA A100, NVIDIA GV100
- NVIDIA L40S GPU 48GB
- NVIDIA NVLink-A100-SXM640GB
- NVIDIA HGX A800 80GB
- NVIDIA Tesla H800 80GB HBM2
- NVIDIA A800-80GB-400Wx8-NvlinkSW
- NVIDIA RTX 3090, NVIDIA RTX 3090TI
- NVIDIA RTX 8000, NVIDIA RTX A6000
- NVIDIA Quadro P2000,NVIDIA Quadro P2200
審核編輯 黃宇
-
cpu
+關(guān)注
關(guān)注
68文章
11277瀏覽量
224956 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135433 -
源碼
+關(guān)注
關(guān)注
8文章
685瀏覽量
31317 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
9063瀏覽量
143743 -
AIGC
+關(guān)注
關(guān)注
1文章
391瀏覽量
3224
發(fā)布評論請先 登錄
五年完成從0到1,國產(chǎn)TPU的算力突圍
GPU 利用率<30%?這款開源智算云平臺讓算力不浪費 1%

從CPU、GPU到NPU,美格智能持續(xù)優(yōu)化異構(gòu)算力計算效能

奇異摩爾受邀出席2025多樣性算力產(chǎn)業(yè)發(fā)展大會

【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的未來:提升算力還是智力
昆侖芯科技亮相2025中國算力大會
華為聯(lián)合中國移動研究院發(fā)布“算力路由AI推理及視聯(lián)網(wǎng)應(yīng)用樣板”
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗】+NVlink技術(shù)從應(yīng)用到原理
RISC-V架構(gòu)下AI融合算力及其軟件棧實踐

AIGC算力基礎(chǔ)設(shè)施技術(shù)架構(gòu)與行業(yè)實踐
搭建算力中心,從了解的GPU 特性開始

維諦技術(shù)(Vertiv)發(fā)布兆瓦級UPS新品,破局高密AI算力負載供電挑戰(zhàn)

DeepSeek推動AI算力需求:800G光模塊的關(guān)鍵作用
AI 算力報告來了!2025中國AI算力市場將達 259 億美元




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論