 TPU-MLIR量化敏感層分析,提升模型推理精度
TPU-MLIR量化敏感層分析,提升模型推理精度

背景介紹
TPU-MLIR編譯器可以將機器學習模型轉換成算能芯片上運行的bmodel模型。由于浮點數的計算需要消耗更多的計算資源和存儲空間,實際應用中往往采用量化后的模型(也稱定點模型)進行推理。相比于浮點數模型,量化模型的推理精度會有一定程度的損失。當精度損失較大時,需要搜索模型中對精度影響較大的層,即敏感層,將其改回浮點類型,生成混精度模型進行推理。
以mobilenet-v2網絡為例,使用ILSVRC-2012數據驗證集的5萬張圖片驗證浮點數模型和量化模型(表格中分別記為FLOAT和INT8)的精度,INT8模型的Top1精度降低了3.2%,Top5精度降低了2%。
| Type | Top1 (%) | Top5 (%) |
|---|---|---|
| FLOAT | 70.72 | 89.81 |
| INT8 | 67.53 | 87.84 |
敏感層搜索
TPU-MLIR的敏感層搜索功能會計算網絡模型中的每一層分別由浮點數類型轉成定點數類型后,對網絡模型輸出造成的損失。同時,由于量化threshold值也會影響定點模型的精度,敏感層搜索功能考慮了三種量化方法——KL、MAX和Percentile對精度的影響。KL方法首先統計FLOAT模型tensor絕對值的直方圖(2048個bin),得到參考概率分布P,隨后用INT8類型去模擬表達這個直方圖(128個bin),得到量化概率分布Q,在不同的截取位置計算P和Q的KL散度,最小散度對應的截取位置記為KL方法得到的threshold值。MAX方法是用FLOAT模型tensor絕對值的最大值作為量化threshold。Percentile方法則是通過統計FLOAT模型tensor絕對值的百分位數來確定threshold。
算法流程
敏感層搜索算法的流程圖如下:
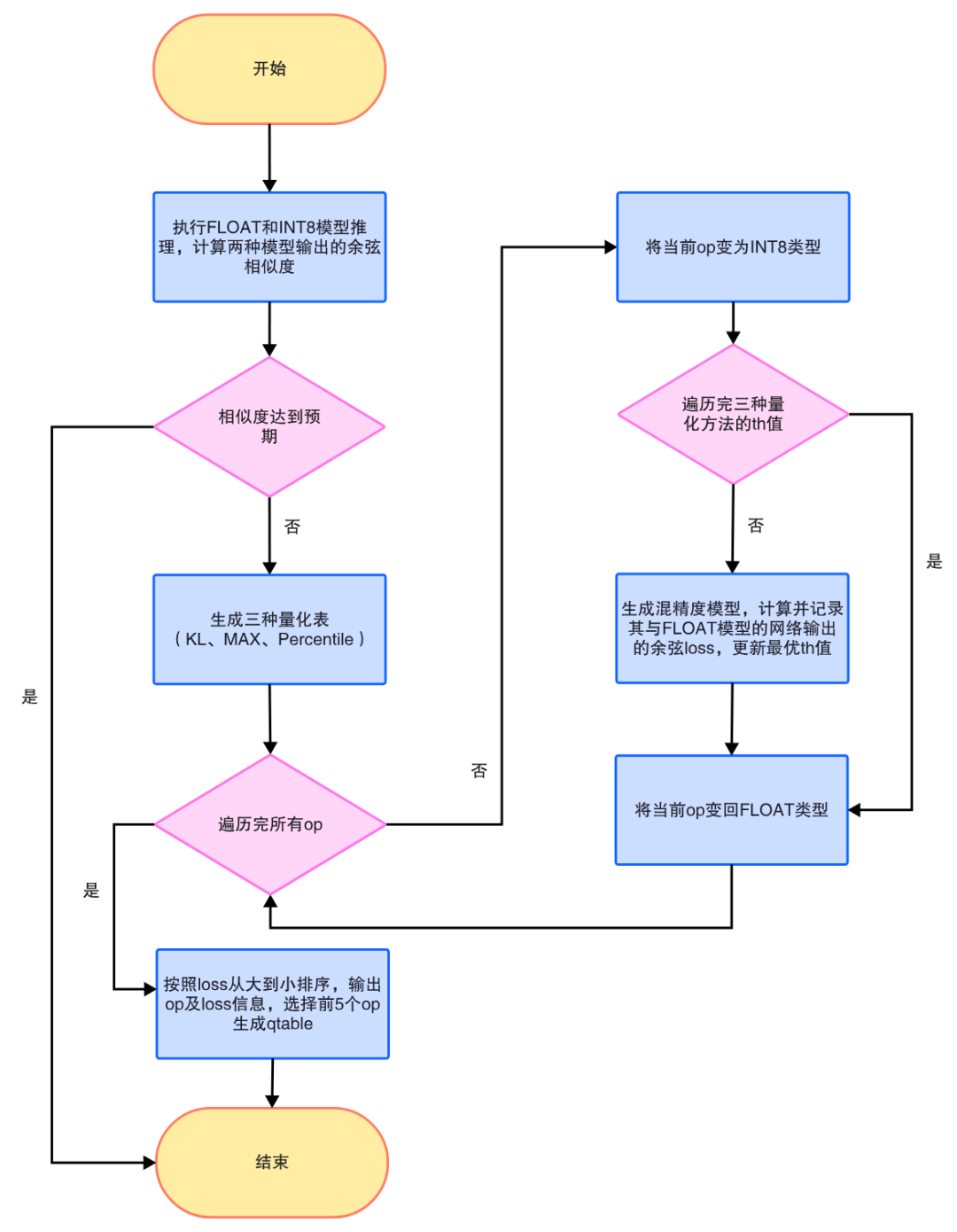 敏感層搜索流程圖
敏感層搜索流程圖
- 在搜索之前需要先判斷FLOAT模型和INT8模型的相似度,用一定數目的圖片(比如30張)進行推理,計算兩種模型輸出結果的余弦相似度的平均值,如果平均值達到預設值,比如0.99,則認為INT8模型與FLOAT模型的相似度較高,不需要進行敏感層搜索。
- 對于該模型,生成三種量化方法對應的量化表。
- 循環每個op及每種量化方法,將該op改為INT8類型,并采用對應量化方法下的threshold,生成混精度模型,計算其與FLOAT模型網絡輸出的loss(1減余弦相似度),記錄最優threshold,即最低loss值對應的threshold,隨后將該op改回FLOAT類型。
- 將所有op按照loss從大到小排序,選擇排名前五的op生成qtable。
在搜索過程中,對于每個op及其每種threshold值下生成的混精度模型與FLOAT模型的loss,以及最終按照loss排序的所有op信息(包括op的名字、類型和loss),均會記錄在log日志中,用戶可以通過查看log日志,手動調整qtable文件。
使用方法
敏感層搜索需要輸入從model_transform步驟得到的mlir文件,run_calibration步驟得到的量化表,推理用的數據集等,使用命令如下:
run_sensitive_layer.pymobilenet.mlir\
--dataset../ILSVRC2012\
--input_num100\
--inference_num30\
--max_float_layers5\
--expected_cos0.99\
--post_processpostprocess.py\
--calibration_tablemobilenet_cali_table\
--chipbm1684\
-omobilenet_qtable
各項參數的含義如下表所示:
| 參數名稱 | 含義 |
|---|---|
| dataset | 用于量化和推理的數據集,推薦使用bad case |
| input_num | 用于量化的圖片數目 |
| inference_num | 用于推理的圖片數目 |
| max_float_layers | qtable中的op數目 |
| expected_cos | INT8模型和FLOAT模型的余弦相似度閾值,達到閾值則不進行敏感層搜索 |
| post_process | 用戶自定義后處理文件路徑,后處理函數需要命名為PostProcess |
| calibration_table | run_calibration步驟得到的量化表 |
| chip | 使用的芯片類型 |
| o | 生成的qtable名稱 |
敏感層搜索程序會生成如下文件:
- 用于生成混精度模型的qtable,每行記錄了需要轉回FLOAT的op及轉換類型,例如:input3.1 F32;
- 經過調優后的新量化表new_cali_table,在原始量化表的基礎上,更新了每個op的threshold值為三種量化方法中最優的threshold;
- 搜索日志SensitiveLayerSearch,記錄整個搜索過程中,每個op在每種量化方法下,混精度模型與FLOAT模型的loss;
注意,在model_deploy步驟生成混精度模型時,需要使用qtable和新量化表。
精度測試結果
仍以前述精度測試采用的mobilenet-v2網絡為例,使用ILSVRC2012數據集中的100張圖片做量化,30張圖片做推理,敏感層搜索總共耗時402秒,占用內存800M,輸出結果信息如下:
the layer input3.1 is 0 sensitive layer, loss is 0.008808857469573828, type is top.Conv
the layer input11.1 is 1 sensitive layer, loss is 0.0016958347875666302, type is top.Conv
the layer input128.1 is 2 sensitive layer, loss is 0.0015641432811860367, type is top.Conv
the layer input130.1 is 3 sensitive layer, loss is 0.0014325751094084183, type is top.Scale
the layer input127.1 is 4 sensitive layer, loss is 0.0011817314259702227, type is top.Add
the layer input13.1 is 5 sensitive layer, loss is 0.001018420214596527, type is top.Scale
the layer 787 is 6 sensitive layer, loss is 0.0008603856180608993, type is top.Scale
the layer input2.1 is 7 sensitive layer, loss is 0.0007558935451825732, type is top.Scale
the layer input119.1 is 8 sensitive layer, loss is 0.000727441637624282, type is top.Add
the layer input0.1 is 9 sensitive layer, loss is 0.0007138056757098887, type is top.Conv
the layer input110.1 is 10 sensitive layer, loss is 0.000662179506136229, type is top.Conv
......
run result:
int8 outputs_cos:0.978847 old
mix model outputs_cos:0.989741
Output mix quantization table to mobilenet_qtable
total time:402.15848112106323
觀察可知,input3.1的loss最大,且值為其他op的至少5倍。嘗試只將input3.1加進qtable,其他層都保持INT8類型不變,生成混精度模型,在ILSVRC2012驗證集上進行推理,精度如下:
| Type | Top1 (%) | Top5 (%) |
|---|---|---|
| FLOAT | 70.72 | 89.81 |
| INT8 | 67.53 | 87.84 |
| MIX(oricali) | 68.19 | 88.33 |
| MIX(newcali) | 69.07 | 88.73 |
上表中,MIX(oricali)代表使用原始量化表的混精度模型,MIX(newcali)代表使用新量化表的混精度模型,可以看出,基于三種量化方法的threshold調優,也對模型的精度起到了正向影響。相比于INT8模型,混精度模型的Top1精度提升1.5%,Top5精度提升約1%。
對比混精度搜索
混精度搜索是TPU-MLIR中的另一個量化調優搜索功能,它的核心思想是先尋找到layer_cos不滿足要求的層,再將該層及其下一層均從INT8轉回FLOAT,生成混精度模型,計算其與FLOAT模型輸出的余弦相似度,如果余弦相似度達到預設值,則停止搜索。注意,混精度搜索只有在op表現較差,即混精度模型與FLOAT模型輸出相似度低于INT8模型與FLOAT模型輸出相似度時,才會將op類型從FLOAT置回INT8,否則不會改變op的精度類型。所以混精度搜索不需要從頭進行推理,耗時較短。這兩種方法的對比如下:
| 對比情況 | 敏感層搜索 | 混精度搜索 |
|---|---|---|
| 核心思想 | 循環所有op,找對網絡輸出影響最大的層 | 以單層layer的相似度為入口,網絡輸出的相似度為停止條件 |
| 考慮多種量化方法 | 只考慮KL方法 | |
| 修改量化表 | 使用原始量化表 | |
| 考慮相鄰兩層 | 只考慮單層 | |
| 考慮layer_cos | 暫未考慮 | |
| 考慮網絡輸出的余弦相似度 | ||
| 手動修改qtable | 使用程序生成的qtable即可 | |
| 支持用戶自定義后處理 | 暫不支持 | |
| 遍歷所有op | 有skip規則,并且達到預設cos后直接停止 | |
| op類型轉換規則 | 從FLOAT變為INT8,算loss | 從INT8變回FLOAT,算cos |
混精度搜索從網絡輸入開始,不斷搜索對網絡輸出相似度有提升的層加入qtable,直到網絡輸出相似度達到預設值后終止搜索。該方法可能會漏掉靠近網絡輸出部分的敏感層,而敏感層搜索方法會遍歷所有op,不會出現這種遺漏,這也是敏感層搜索的優勢之處。在實際應用中,用戶可以先使用速度較快的混精度搜索,如果沒能達到預期效果,再使用敏感層搜索功能進行全局遍歷。
結語
敏感層搜索功能旨在尋找模型量化時對精度影響較大的層,它會遍歷模型中的所有op及三種量化方法,選擇最優的量化threshold,記錄所有op的loss。將搜索到的敏感層設定為浮點數類型,其余層設定為定點數類型,生成混合精度模型,可以提升模型推理的精度。目前的敏感層搜索功能在mobilenet-v2網絡中表現優異,只需要將loss最大的一層置為FLOAT,就可以獲得1.5%的精度提升。與混精度搜索方法相比,敏感層搜索雖然耗時更久,但它考慮了所有op和三種量化方法,不會遺漏靠近網絡輸出部分的敏感層。未來可以考慮從三個方面對敏感層搜索功能進行優化:1) 結合混精度搜索的優點,在搜索時考慮每層及其鄰近層對網絡輸出的綜合影響;2) 在生成qtable時,不是根據用戶設定的數目,選擇loss最大的前N層,而是通過計算,將能讓網絡輸出相似度達到預設值的op均加入qtable;3) 在遍歷op的過程中考慮并行,縮短搜索時間。
-
模型
+關注
關注
1文章
3751瀏覽量
52099 -
機器學習
+關注
關注
66文章
8553瀏覽量
136931 -
TPU
+關注
關注
0文章
170瀏覽量
21654
發布評論請先 登錄
太陽敏感器的高精度補償標定方法

LLM推理模型是如何推理的?

谷歌云發布最強自研TPU,性能比前代提升4倍

什么是AI模型的推理能力
積算科技上線赤兔推理引擎服務,創新解鎖FP8大模型算力
信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
大模型推理顯存和計算量估計方法研究
使用 NPU 插件對量化的 Llama 3.1 8b 模型進行推理時出現“從 __Int64 轉換為無符號 int 的錯誤”,怎么解決?
將Whisper大型v3 fp32模型轉換為較低精度后,推理時間增加,怎么解決?
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規模思考與推理的 AI 模型新引擎?
詳解 LLM 推理模型的現狀




 工商網監
工商網監
評論