 TUM&谷歌提出md4all:挑戰性條件下的單目深度估計
TUM&谷歌提出md4all:挑戰性條件下的單目深度估計

前言
大家好, 我叫Stefano Gasperini, 在此宣傳我們的ICCV 2023的工作, 更多詳細信息可查看我們的論文: https://arxiv.org/abs/2308.09711, 和我們的項目網站: https://md4all.github.io.
代碼:https://github.com/md4all/md4all
在CVer微信公眾號后臺回復:md4all,可下載本論文pdf和代碼
首先請大家觀看這樣一個例子:
你能在彩色圖片中看到樹嗎?

我們的單目深度估計網絡在所有條件下都能輸出可靠的深度估計值,即使在黑暗中也是如此!
背景
雖然最先進的單目深度估計方法在理想環境下取得了令人印象深刻的結果,但在具有挑戰性的光照和天氣條件下,如夜間或下雨天,這些方法卻非常不可靠。

在這些情況下, 傳感器自帶的噪聲、無紋理的黑暗區域和反光等不利因素都違反了基于監督和自監督學習方法的訓練假設。自監督方法無法建立學習深度所需的像素的對應關系,而監督方法則可能從傳感器真值中(如上圖中的 LiDAR 與 nuScenes 的數據樣本)中學習到數據瑕疵。
方法
在本文中,我們提出了 md4all 解決了這些安全關鍵問題。md4all 是一個簡單有效的解決方案,在不利和理想條件下都能可靠運行,而且適用于不同類型的監督學習。
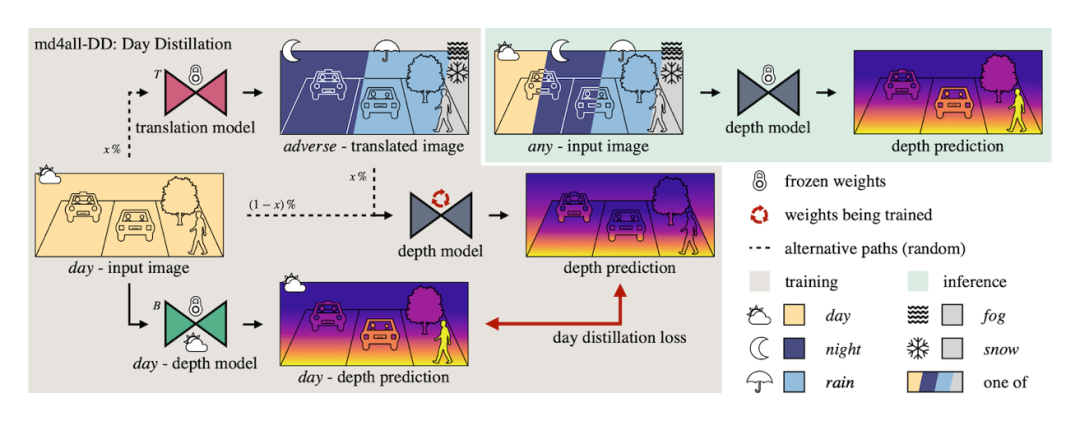
我們利用現有方法在完美設置下的工作能力來實現這一目標。因此,我們提供的有效訓練信號與輸入信號無關。首先,通過圖像轉換,我們生成一組與正常訓練樣本相對應的復雜樣本。然后,我們通過輸入生成的樣本并計算相應原始圖像上的標準損失,引導網絡模型進行自監督學習或完全監督學習。
如上圖所示,我們進一步從預先訓練好的基線模型中提煉知識,該模型只在理想環境下進行推理,同時向深度模型提供理想和不利的混合輸入。
我們的 GitHub 代碼庫中包含所提方法的實現代碼, 歡迎訪問:
https://github.com/md4all/md4all
結果

通過 md4all,我們大大超越了之前的解決方案,在各種條件下都能提供穩健的估計。值得注意的是,所提出的 md4all 只使用了一個單目模型,沒有專門的分支。
上圖顯示了在 nuScenes 數據集的挑戰性環境下的預測結果。由于場景的黑暗程度和噪聲帶來的影響,自監督方法 Monodepth2 無法提取有價值的特征(第一行)。有監督的 AdaBins 會學習到來自傳感器數據的瑕疵,并造成道路上的空洞預測現象(第二行)。在相同的架構上應用,我們的 md4all 提高了在標準和不利條件下的魯棒性。
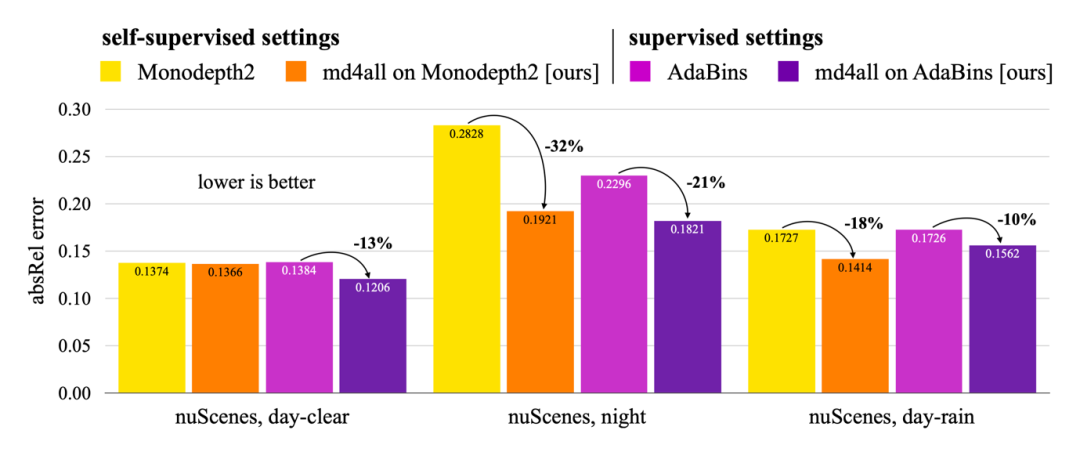
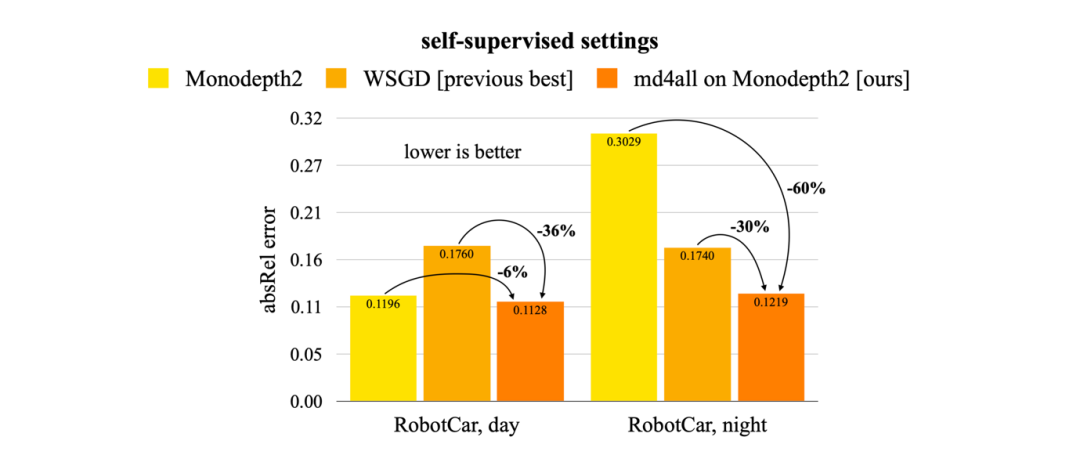
在本文中,我們展示了 md4all 在標準和不利條件下兩種類型的監督下的有效性。通過在 nuScenes 和 Oxford RobotCar 數據集上的大量實驗,md4all 的表現明顯優于之前的作品(如上圖數據所示)。
圖像轉換

我們還顯示了為訓練 md4all 而生成的圖像轉換示例 (如上圖所示)。我們通過向模型提供原始樣本和轉換樣本的混合數據進行數據增強。這樣一個模型就能在不同條件下恢復信息,而無需在推理時進行修改。
在此,我們開源共享所有不利條件下生成的圖像,這些圖像與 nuScenes 和牛津 Robotcar 訓練集中的晴天和陰天樣本相對應。歡迎訪問:
https://forms.gle/31w2TvtTiVNyPb916
這些圖像可用于未來深度估計或其他任務的穩健方法。
-
傳感器
+關注
關注
2577文章
55311瀏覽量
793029 -
谷歌
+關注
關注
27文章
6255瀏覽量
111768 -
模型
+關注
關注
1文章
3789瀏覽量
52214
原文標題:ICCV 2023 | TUM&谷歌提出md4all:挑戰性條件下的單目深度估計
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在芯片內同時捕獲不同觸發條件下的信號
基于單目圖像的深度估計算法,大幅度提升基于單目圖像深度估計的精度

歐拉 Summit 2021 安全&amp;可靠性&amp;運維專場:主流備份技術探討

滿足當今外殼設計具有挑戰性的性能和散熱要求
密集單目SLAM的概率體積融合概述
一種用于自監督單目深度估計的輕量級CNN和Transformer架構
介紹第一個結合相對和絕對深度的多模態單目深度估計網絡
一種利用幾何信息的自監督單目深度估計框架
動態場景下的自監督單目深度估計方案





 工商網監
工商網監
評論