 介紹第一個結合相對和絕對深度的多模態單目深度估計網絡
介紹第一個結合相對和絕對深度的多模態單目深度估計網絡

背景
單目深度估計分為兩個派系,metric depth estimation(度量深度估計,也稱絕對深度估計)和relative depth estimation(相對深度估計)。
絕對深度估計:估計物體絕對物理單位的深度,即米。預測絕對深度的優點是在計算機視覺和機器人技術的許多下游應用中具有實用價值,如建圖、規劃、導航、物體識別、三維重建和圖像編輯。然而,絕對深度股即泛化能力(室外、室內)極差。因此,目前的絕對深度估計模型通常在特定的數據集上過擬合,而不能很好地推廣到其他數據集。
相對深度估計:估計每個像素與其它像素的相對深度差異,深度無尺度信息,可以各種類型環境中的估計深度。應用場景有限。
導讀
現有的單目深度估計工作,要么關注于泛化性能而忽略尺度,即相對深度估計,要么關注于特定數據集上的最先進的結果,即度量深度(絕對深度)估計。論文提出了第一種結合這兩種形態的方法,從而得到一個在泛化性能良好的同時,保持度量尺度的模型:ZoeD-M12-NK。
具體來說,論文框架包括兩個關鍵組成部分:相對深度估計網絡和絕對深度估計網絡。相對深度估計網絡學習提取相鄰像素之間的深度差異信息,而絕對深度估計網絡則直接預測絕對深度值。
使用這種框架,論文方法能夠將已有數據集的深度信息轉移到新的目標數據集上,從而實現零樣本(Zero-shot)深度估計。在實驗中,論文方法使用了幾個標準數據集進行測試,并證明了所提方法在零樣本深度估計方面比現有SOTA表現更好。
貢獻
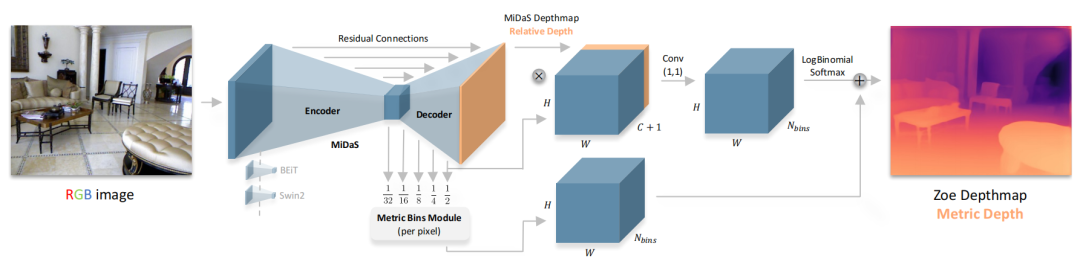
本文中,作者提出了一個兩階段的框架,使用一個通用的編碼-解碼器架構進行相對深度估計的預訓練,在第二階段添加絕對深度估計的輕量級head(metric bins module),并使用絕對深度數據集進行微調。本文的主要貢獻是:
ZoeDepth 是第一個結合了相對深度和絕對深度的方法,在保持度量尺度的同時,實現了卓越的泛化性能。
ZoeDepth 的旗艦模型 ZoeD-M12-NK 在12個數據集上使用相對深度進行預訓練,并在兩個數據集上使用絕對深度進行微調,使其在現有SOTA上有了明顯的提高
ZoeDepth 是第一個可以在多個數據集(NYU Depth v2 和 KITTI)上聯合訓練而性能不明顯下降的模型,在室內和室外域的8個未見過的數據集上實現了前所未有的零樣本泛化性能
ZoeDepth 彌補了相對深度估計和絕對深度估計之間的差距,并且可以通過在更多的數據集上定義更細化的域和,并在更多的絕對深度數據集微調來進一步改進網絡性能。
方法
論文首先使用一個Encoder-Decoder的backbone進行相對深度預測,然后將提出的metric bins 模塊附加在decoder上得到絕對深度預測頭(head),通過添加一個或多個head(每個數據集一個)來進行絕對深度估計。最后再進行端到端的微調。下面介紹每個head(metric bins mdule)是怎么設計的:
LocalBins review
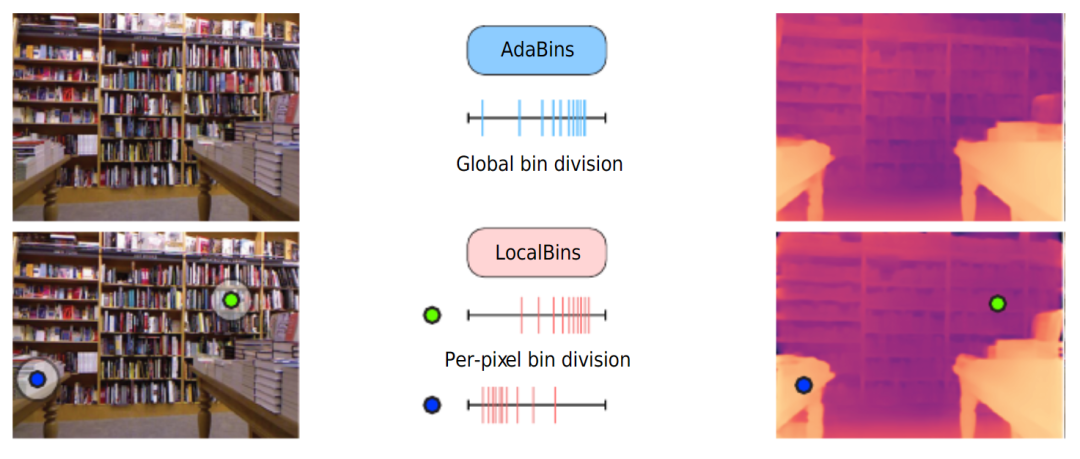
global adaptive bins vs local adaptive bins
不同RGB輸入對應的深度分布會有很大的不同,目前的神經網絡架構主要是在低分辨率的bottleneck獲取全局信息,而不能很好地在高分辨率特征獲取全局特征,深度分布的這種變化使得端到端的深度回歸變得困難。因此,此前的一些方法提出將深度范圍劃分為一定數量的bin,將每個像素分配給每個bin,將深度回歸任務轉換為分類任務。
最終深度估計是bin中心值的線性組合。上圖介紹了兩種劃分bin的方法,AdaBins預測了完整圖像的分布,LocalBins預測了每個像素周圍區域的分布。本文采用了類似于LocalBins的這種方式。
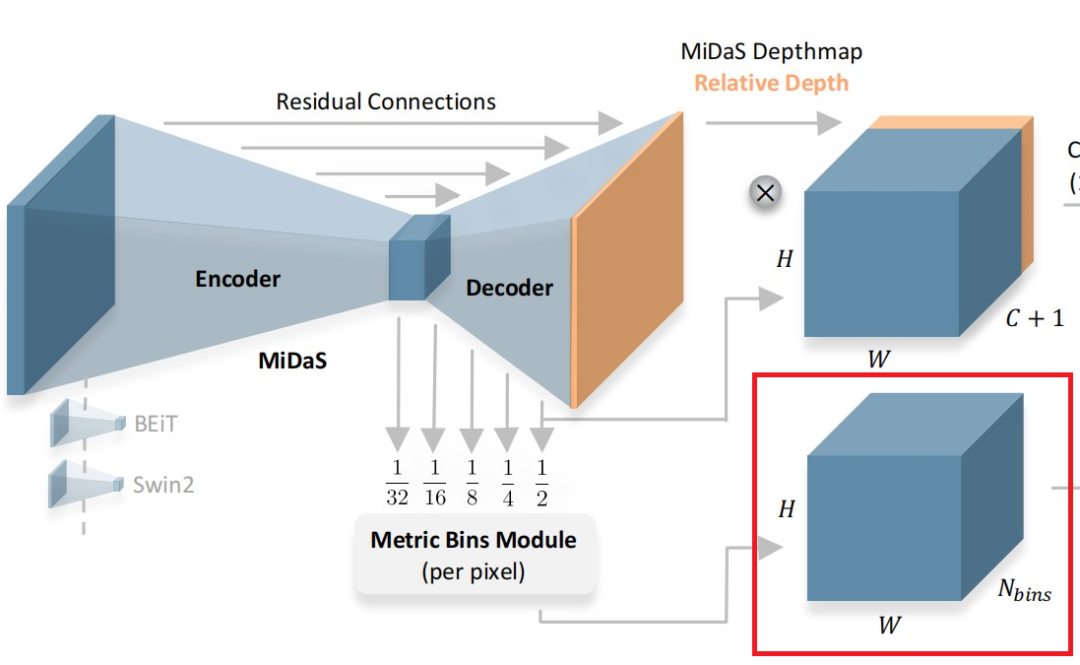
Metric bins
具體來說,LocalBins使用一個標準的encoder-decoder作為基本模型,并附加一個模塊,該模塊將encoder-decoder的多尺度特征作為輸入,預測每個像素深度區間上的個bins中心值(channel)。一個像素的最終深度,由個bin經過softmax得到的概率加權其bin中心值的線性組合得到:
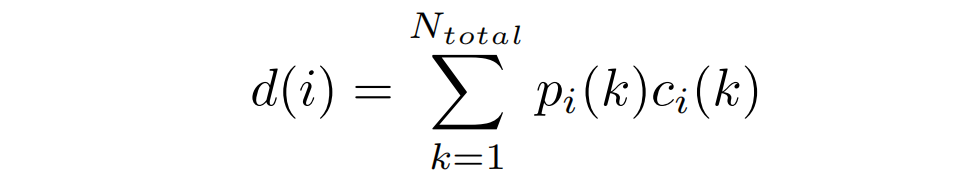
Metric bins module
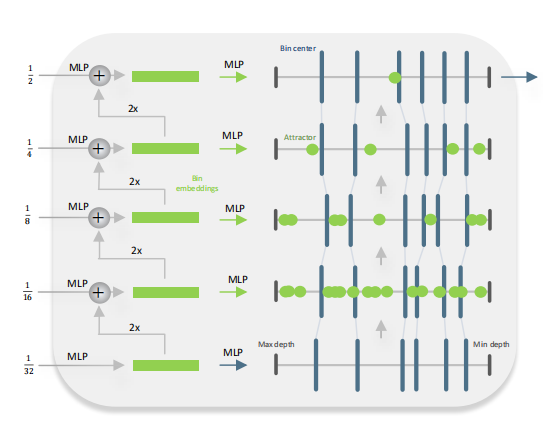
Metric Bins Module
如上圖所示,Metric bins模塊以MiDaS[1](一種有監督的Zero-shot深度估計方法)的解碼器的多尺度(五層)特征作為輸入,預測用于絕對深度估計的深度區間的bins的中心。注意論文在bottleneck層就直接預測每個像素上所有的bins(即channel的維度直接就是)。然后在decoder上使用attractor layers逐步進行細化bin區間。
Attract instead of split
論文通過調整bin,在深度區間上向左或向右移動它們,來實現對bin的多尺度細化。利用多尺度特征,論文預測了深度區間上的一組點用來”吸引“bin的中心。
具體地說,在第1個decoder層,MLP將一個像素處的特征作為輸入,并預測該像素位置的吸引點。調整后的bin中心為,調整如下:
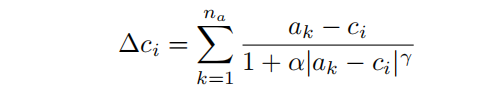
其中,超參數和決定了attractor(吸引子)的強度。論文把這個attractor命名為inverse attractor。此外,論文還實驗了一個指數變量:
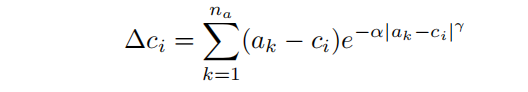
實驗表明,inverse attractor可以導致更好的性能。論文中,深度區間設置了個bin,decoder設置了個attractor。
Log-binomial instead of softmax
為了得到最終的絕對深度預測,每個像素上深度區間內的每個bin通過softmax可以得到其概率,所有的bin的中心進行按照片概率線性組合得到該像素的深度值。
盡管softmax在無序類中運行得很好,但由于深度區間內bin本身是有序的,softmax方法可能導致附近的bin的概率大大不同,因此論文使用具有排序感知的概率預測:
論文使用一個二項式分來預測概率,將相對深度預測與解碼器特征連接起來,并從解碼器特征中預測一個2通道輸出(q - mode和t - temperature),通過以下方法獲得第k個bin中心的概率得分:
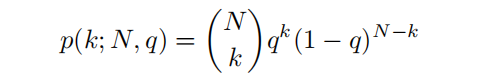
然后再通過:
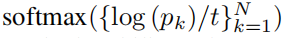
得到最終的概率值。
訓練策略
Metric fine-tuning on multiple datasets
在具有各種場景的混合數據集上訓練一個絕對深度模型是很困難的,論文首先預訓練一個的相對深度估計的backbone,在一定程度上減輕了對多個數據集的微調問題。然后為模型配備多個Metric bins模塊,每個場景類型(室內和室外)對應一個。最后再對完整的模型進行端到端微調。
Routing to metric heads
當模型有多個絕對深度頭時,在推理的時候,算法需要根據輸入數據的類型,通過一個“路由器”來選擇用于特定輸入的絕對深度頭。
論文提供了三種“路由”策略:
Labeled Router(R.1):訓練多個模型,給它們打上場景標簽,推理時根據場景手動選擇模型
Trained Router(R.2):訓練一個MLP分類器,它根據bottleneck預測輸入圖像的場景類型,然后“路由”到相應的head,訓練的時候需要提供場景類型的標簽
Auto Router(R.3):跟第二種類似,但是訓練和推理過程中不提供場景的標簽。
實驗
Comparison to SOTA on NYU Depth V2
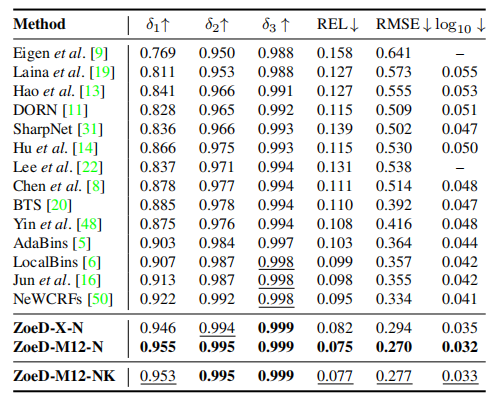
表1 Quantitative comparison on NYU-Depth v2
在沒有任何相對深度預訓練的情況下,論文的模型ZoeD-X-N預測的絕對深度可以比目前的SOTA NeWCRFs提高13.7% (REL = 0.082)。
通過對12個數據集進行相對深度預訓練,然后對NYU Depth v2進行絕對深度微調,論文的模型ZoeD-M12-N可以在ZoeD-X-N上進一步提高8.5%,比SOTA NeWCRFs提高21%(REL = 0.075)。
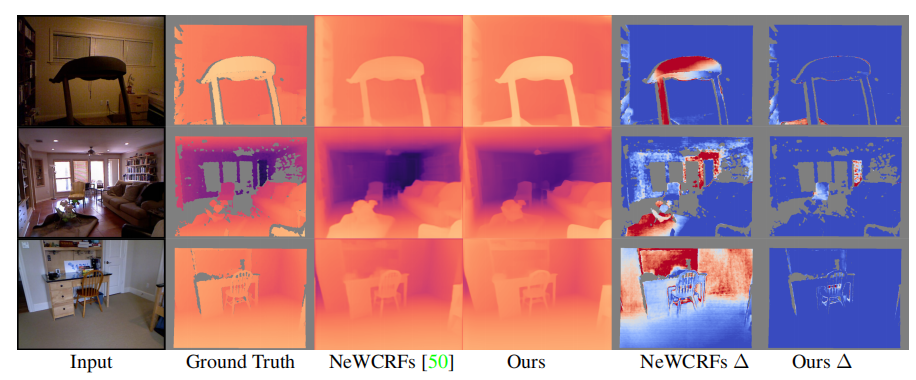
Qualitative comparison on NYU Depth v2
上面的可視化可以看出,論文方法始終以更少的誤差,產生更好的深度預測(藍色表示誤差小)。
Universal Metric SIDE
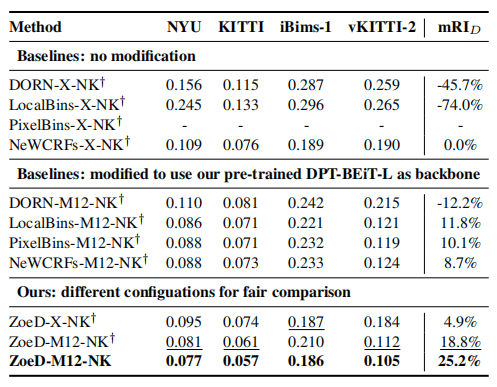
表2 Comparison with existing works when trained on NYU and KITTI
使用跨域數據集(室內NYU和室外KITTI(NK))進行絕對深度訓練的模型通常表現更差,如上表2與表1的對比所示,論文將最近的一些方法在室內和室外數據集上進行聯合訓練,從結果可以看到,這些方法的性能都顯著下降,甚至直接無法收斂。而本文的方法ZoeD-M12-NK**只下降了8%**(REL 0.075 to 0.081),顯著優于SOTA NeWCRFs。
表2中,“”表示使用一個head,可以看到,使用多head的網絡,泛化能力更強,這些結果表明,Metric Bins模塊比現有的工作更好地利用了預訓練,從而改進了跨域的自適應和泛化(Zero-shot性能)。
Zero-shot Generalization
論文將所提模型在8個未訓練的室內和室外數據上進行Zero-shot測試,來評估所提方法的泛化能力。

Zero-shot transfer
Zero-shot transfer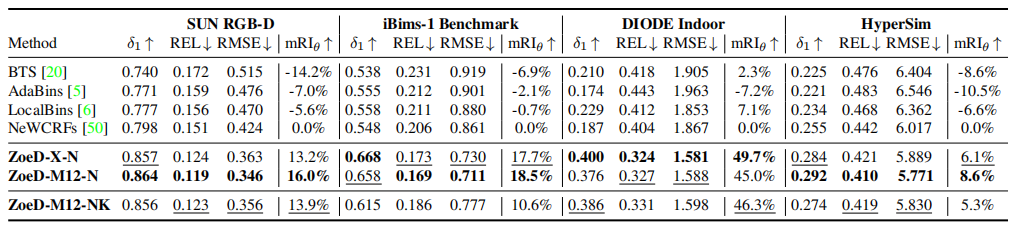
表3 Quantitative results for zero-shot transfer to four unseen indoor datasets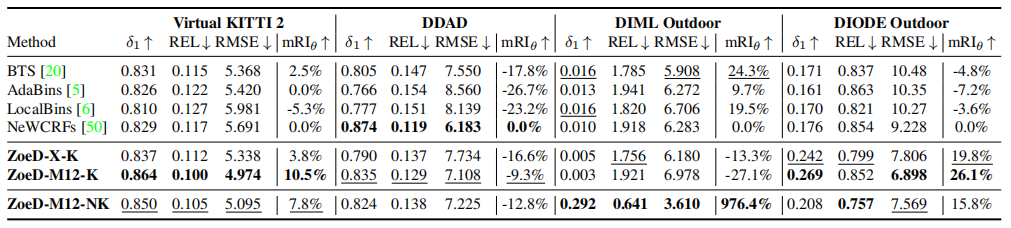
表4 Quantitative results for zero-shot transfer to four unseen outdoor datasets
如表3所示,在室內數據測試中,ZoeD-M12-N能夠取得最好的效果(在12個相對深度數據集上預訓練,只對NYU數據集進行微調),同時在室內NYU數據集和室外KITTI數據集進行微調效果次之,不使用12個相對深度數據集上預訓練最差,但都顯著高于SOTA。如表4和上圖所示,在室外數據測試中,結論類似。甚至在達到了976.4%的提升!,這證明了它前所未有的Zero-shot能力。
消融實驗
Backbones
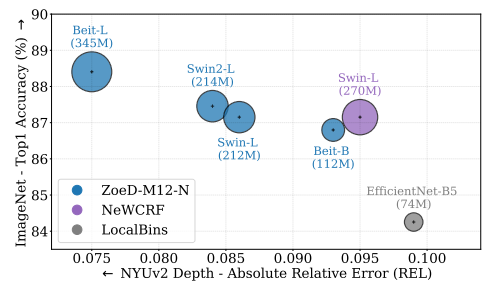
Backbone ablation study
在圖像分類task中的backbone性能與深度估計性能之間有很強的相關性。較大的backbone可以實現較低的絕對相對誤差(REL)。
Metric Bins Module
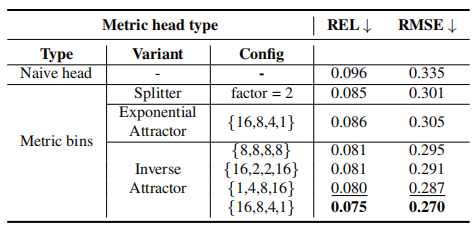
Metric head variants
不同的MLP中的分裂因子(Splitter)和吸引子(Attractor)的數量對結果有影響。
Routers
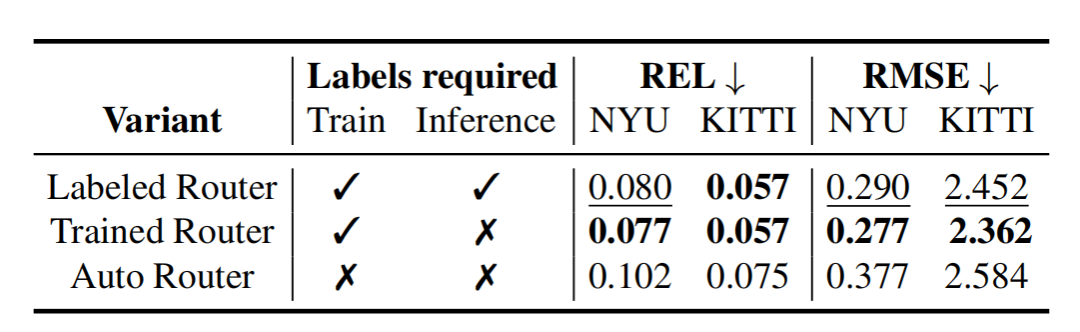
Router variants
Trained Router效果顯著由于另外兩種路由策略。
總結
論文提出了ZoeDepth,第一個結合了相對深度和絕對深度而性能沒有顯著下降的方法,彌補相對和絕對深度估計性能之間的差距,在保持度量尺度的同時,實現了卓越的泛化性能。ZoeDepth是一個兩階段的工作,在第一階段,論文使用相對深度數據集對encoder-decoder架構進行預訓練。在第二階段,論文基于所提的Metric bins 模塊得到domain-specific頭,將其添加到解碼器中,并在一個或多個數據集上對模型進行微調,用于絕對深度預測。
提出的架構顯著地改進了NYU Depth v2的SOTA(高達21%),也顯著提高了zero-transfer的技術水平。論文希望在室內和室外之外定義更細粒度的領域,并在更多的絕對深度數據集上進行微調,可以進一步改善論文的結果。在未來的工作中,論文希望研究ZoeDepth的移動架構版本,例如,設備上的照片編輯,并將該工作擴展到雙目深度估計。
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1218瀏覽量
43393 -
機器人
+關注
關注
213文章
31075瀏覽量
222197 -
RGB
+關注
關注
4文章
831瀏覽量
61940 -
機器人技術
+關注
關注
18文章
194瀏覽量
33245
原文標題:Intel 開源新作 | ZoeDepth: 第一個結合相對和絕對深度的多模態單目深度估計網絡
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中常提的“深度估計”是個啥?

商湯科技日日新V6.5榮獲2025年多模態大模型全國第一

雙目視覺是如何實現深度估計的?
深度解析 | 低抖動高精度EtherCAT多軸控制的實現與實踐案例
自動駕駛中Transformer大模型會取代深度學習嗎?

毫米之間定成敗:PCB背鉆深度設計與生產如何精準把控
研華科技攜手創新奇智推出多模態大模型AI一體機

信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
大模型推理顯存和計算量估計方法研究
汽車多模態交互測試:智能交互的深度驗證





 工商網監
工商網監
評論