 在AI浪潮的推動下,AMD再用Chiplet技術交出階段性答卷!
在AI浪潮的推動下,AMD再用Chiplet技術交出階段性答卷!

眾所周知,隨著最近生成式AI浪潮的席卷全球,NVIDIA無論影響力還是股價都已一息千里;
但可能令黃仁勛也想不到的是:僅僅在就在本月初,在NVIDIA推出被稱作“巨型GPU”的GH200超級芯片后,作為表外甥女的AMD總裁蘇姿豐也放出了其“終極武器”——MI300X。
6月14日凌晨一點,AMD舉行了最新直播活動,這一次,蘇媽帶來多款重磅產品:

圖片來自:AMD
蘇姿豐率先公布了Instinct MI300A,她稱之為全球首個為AI和HPC(高性能計算)打造的APU加速器,擁有多達13顆小芯片,總共包含1460億個晶體管;
該加速器采用CDNA 3 GPU架構和24個Zen 4 CPU內核,配置128GB的HBM3內存,相比前代MI250,MI300的性能提高八倍,效率提高五倍。
而全場發布會的重頭戲,則是一款全新的純GPU產品 ——“Instinct MI300X”;

圖片來自:AMD
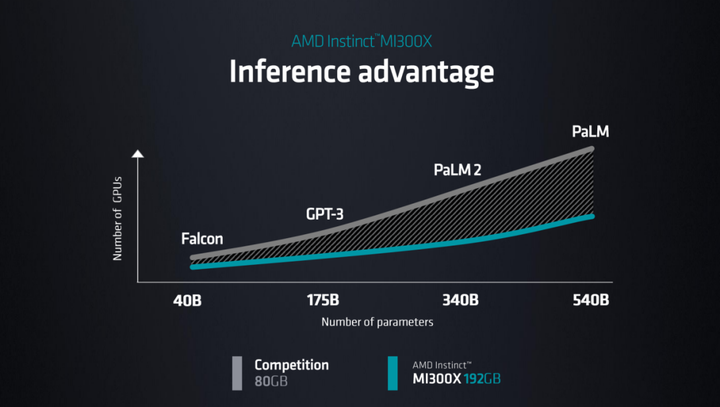
據蘇姿豐介紹:Instinct MI300X內存達到了192GB,內存帶寬為5.2TB/s,Infinity Fabric帶寬為896GB/s,晶體管達到嘆為觀止的1530億個。
這與NVIDIAH100芯片相比,MI300X提供的HBM密度最高是前者的2.4倍,HBM帶寬最高則是1.6倍。這意味著,AMD的芯片可以運行比NVIDIA芯片更大的模型;蘇姿豐強調,生成式AI模型可能不再需要數目那么龐大的GPU,由此可為用戶節省成本。
當然,我們這里所說的二者的關系問題,并不是道聽途說而來:
這兩人不僅都出生在臺南,且還有親戚關系,蘇姿豐的外公與黃仁勛的母親是兄妹;相當于,蘇姿豐是黃仁勛的外甥女,換言之,黃仁勛是蘇姿豐的表舅
更有意思的是,黃仁勛職業生涯早期還曾在AMD工作過,他也曾提起自己很喜歡當時的工作。
回到正題,或許你和我一樣,在本場發布會之前都認為:
蘇姿豐和她的AMD技術團隊是否可以生產出足夠強大的芯片,以打破NVIDIA對GPU市場幾乎壟斷的地位呢?
答案就在本次發布會蘇姿豐的驚人話語中:“隨著模型尺寸變得越來越大,你需要多個 GPU 來運行最新的大型語言模型;且,隨著 AMD 芯片上內存增加,開發者將不需要那么多 GPU。”

圖片來自:AMD
其理由是:AMD 的 Instinct MI300 系列以及NVIDIA的 H100 / H800 系列 GPU 都在采用臺積電先進的后端 3D 封裝方法 CoWoS,導致臺積電 CoWoS 產能短缺將持續存在;臺積電目前有能力每月處理大約 8000 片 CoWoS 晶圓,其中NVIDIA和 AMD 合計占了大約 70% 到 80%。
尤其,用于CoWoS和其他先進封裝技術的封裝設備需要專門的生產工具,它們的交貨時間在3到6個月之間;這意味著臺積電迅速擴大其CoWoS產能的能力是有限的。
特別值得一提的是:這張集成了1530億晶體管的怪獸芯片也是AMD Chiplet技術生態的集大成者:
AMD本次發布的MI300A被蘇姿豐稱作“面向 AI 和高性能計算的全球首款 APU 加速器”,將多個 CPU、GPU 和高帶寬內存封在一起,在 13 個 Chiplets 上擁有1460 億顆晶體管。
AMD Instinct MI 300X和AMD Instinct MI 300A不同點在于,AMD Instinct MI 300X并沒有集成CPU內核,而是采用了8 個 GPU Chiplet(基于CDNA 3架構)和另外 4 個 IO 內存Chiplet的設計,這讓其集成的晶體管數量達到了驚人的1530億。
與此同時,Chiplet技術在AI芯片中具有提高芯片集成度、降低生成本、提高性能、降低性能和提高芯片可能依賴等技術作用;隨著技術的不斷進步和應用場景的不斷擴大,Chiplet技術在AI芯片中的應用前景將會更加廣泛。
圖片來自:AMD
尤其,作為一款對標NVIDIA H100的產品,AMD Instinct MI 300X的HMB密度是前者的2.4倍,帶寬則為前者的1.6倍;這讓AMD的這顆產品在當前的AI時代競爭力大增。
同時,基于帶寬高達896GB/s的AMD Infinity架構,AMD可以將八個 M1300X 加速器組合在一個系統中,這樣就能為開發帶來更強大的計算能力,為 AI 推理和訓練提供不一樣的解決方案。
綜上所述,毋庸置疑,這是一場攸關未來的半導體競賽;全球數據中心 GPU 和 CPU 的頭部企業NVIDIA和Intel均在強調其加速 AI 的實力。
但,作為這兩條賽道“萬年老二”的 AMD,也在競相滿足對 AI 計算日益增長的需求,并通過推出適應最新需求的數據中心 GPU 來挑戰NVIDIA在新興市場的主導地位。
-
amd
+關注
關注
25文章
5684瀏覽量
139971 -
AI
+關注
關注
91文章
39793瀏覽量
301412 -
chiplet
+關注
關注
6文章
495瀏覽量
13603
原文標題:在AI浪潮的推動下,AMD再用Chiplet技術交出階段性答卷!
文章出處:【微信號:奇普樂芯片技術,微信公眾號:奇普樂芯片技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何突破AI存儲墻?深度解析ONFI 6.0高速接口與Chiplet解耦架構
聯想出席中足聯全棧AI總指揮中心階段性成果匯報會
躍昉科技受邀出席第四屆HiPi Chiplet論壇

安森美Roy Chia:AI浪潮推動半導體技術創新

ADI:AI浪潮下的技術創新與新興市場機遇

景嘉微:自研邊端側AI SoC芯片CH37系列取得階段性進展

眾達科技以“自主可控”生態,在國產嵌入式領域交出超200款產品、100+專利的硬核答卷
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+內容總覽
AI 芯片浪潮下,職場晉升新契機?

星漢大模型2.0:AI大模型浪潮奔涌 大華股份呈交“智能答卷”

DeepSeek推動AI算力需求:800G光模塊的關鍵作用
Chiplet:芯片良率與可靠性的新保障!




 工商網監
工商網監
評論