 AI應用的絕佳組合:NPU+DSP!
AI應用的絕佳組合:NPU+DSP!

如今,人工智能應用正在滲透入大眾生活的方方面面,自動駕駛技術的行人檢測、數碼相機的圖像質量增強、AI美顏、語音識別……這些人工智能應用的背后離不開硬件的支持。雖然神經網絡處理器(NPU)在性能、效率和算法靈活性方面已優于可編程的DSP,但這并不意味著 AI 處理中不需要 DSP。恰恰相反,對于許多應用的AI子系統來說,神經網絡處理器(NPU)與矢量DSP是絕佳組合。
哪些應用需要用到DSP?NPU和DSP該如何更好的配置?行業內是否有現成的解決方案可供選擇?本文將針對這些問題一一進行講解。
DSP在AI應用中發揮重要作用
從眾多神經網絡處理需求來看,例如卷積神經網絡 (CNN) 或轉換器,任何可以執行乘法運算并移動大量數據的處理器最終都可以執行這些計算密集型模型。借助先進的量化技術,經過訓練的神經網絡的32位浮點輸出可以在 8 位整數控制器或處理器上運行,而且精度幾乎沒有降低。這意味著可以在 CPU、GPU、DSP 甚至MCU上處理CNN推理,準確度不受影響。
目前在行業內通常用TOPS(每秒萬億次運算)來衡量AI處理器的性能,也稱之為“算力”。TOPS 的計算方式為:一個周期內可以完成的運算次數(一次乘積累加視為兩次運算)x最大頻率。這是很好的首次性能估算,因為大部分計算由對矩陣乘法的需求驅動,而矩陣乘法需要乘積累加運算。
按照這種計算方法,讓我們來看下不同處理器類型的理想TOPS。具有DSP擴展的CPU可以每個時鐘周期執行一次乘積累加 (MAC) 并以 2GHz的速度運行,其運算能力為:2GHz x 2次運算(包括乘積和累加)x 1 MAC/周期 = 4 GOPS 或 0.004 TOPS(1TOPS等于1000 GOPS)。以此類推,矢量DSP的理想TOPS為1.2,高端的NPU將達到255.6 TOPS。如表1中所示,從理想的算力能力上來看,神經處理單元 (NPU) 是獲得最高計算能力的最佳選擇。
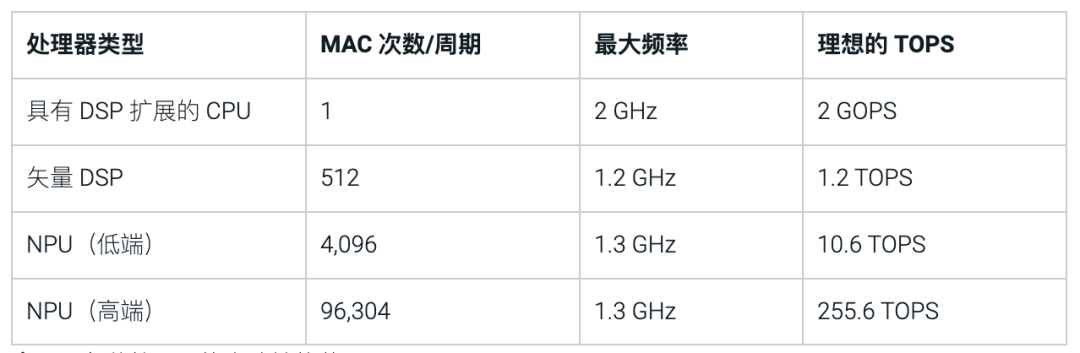
表1 :各種處理器的大致性能范圍
誠然,計算能力固然重要,但一些應用對實時性能的要求也很高。如在汽車應用中,當一輛汽車以 70 英里/小時的速度沖向行人,需要迅速決定是否要剎車。多攝像頭配置、高分辨率、最低延遲,這些因素都對計算效率提出了更高要求,以幫助汽車做出生死攸關的決定。因此,我們需要更謹慎地選擇用于處理AI推理的處理器。
GPU在AI計算中也可以提供高性能,但由于其功耗和面積成本很高,對于實時應用來說難以接受,所以并未在上表中列出。事實上,上表中所列的每種處理器都需要不同級別的功率和面積才能達到所需的運算能力。對于實時應用來說,功耗和面積(與成本和可制造性直接相關)幾乎與性能同樣重要。理論上來說,NPU經過設計和優化,是執行神經網絡算法時性能、功耗和面積效率最高的處理器。
但是,并非每個AI應用都需要NPU提供的最高級別的神經網絡性能。如下圖1所示,不同的AI應用涵蓋從幾GOPS到數千TOPS的各種性能要求。當你的AI應用所需算力小于1 TOPS時,具有DSP擴展的CPU或者矢量DSP是比較理想的選擇;而當算力要求高于1 TOPS時,NPU的 AI 性能效率、功耗效率和面積效率毋庸置疑。

圖 1:AI 應用有各種各樣的性能要求。
NPU 的最佳效率來自每個周期可以完成的大量乘積,以及一些專用于其他神經網絡運算(例如激活函數)的硬件。NPU 面臨的挑戰是如何實現最大硬件加速,從而最大限度地提高神經網絡效率,還要保持一定程度的可編程性。雖然現在全硬件神經網絡ASIC比可編程 NPU更高效,但AI技術發展迅速,AI SoC的生產周期很長,因此保持一定程度的可編程性至關重要。
而且,NPU是專用的神經處理器引擎,只能執行AI計算。如果將矢量DSP和NPU結合使用,利用矢量DSP對NPU進行支持,就可以提供最高性能和額外的可編程性。例如,在自動駕駛汽車中,需要利用NPU來尋找行人、識別街道標志、使用神經網絡進行雷達處理,在這些多應用處理中,系統可利用矢量DSP來為NPU進行額外篩選、雷達或LiDAR處理以及預處理和后處理。
NPU+DSP的三種配置方式
圖2顯示了在 AI 應用中將NPU和矢量DSP結合使用的各種可能性。在圖中所示的三種情況下,高分辨率圖像幀位于DDR內存中,等待在下一幀到達之前得到處理。
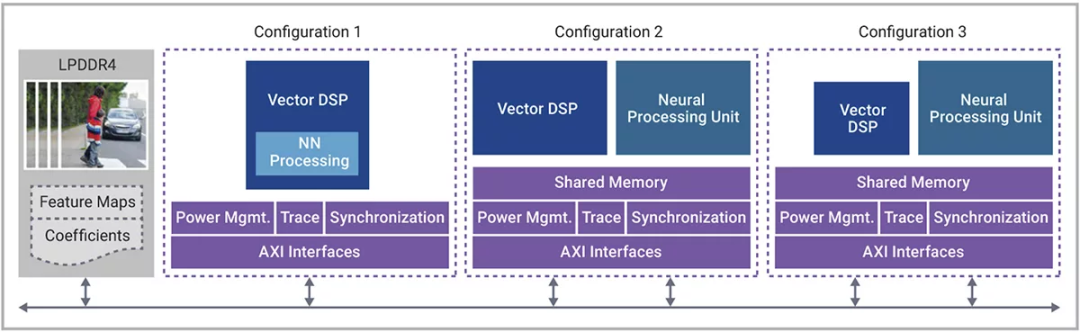
圖 2:矢量DSP和神經網絡性能的不同組合。
在第一種配置中(左側),矢量 DSP本身既可用于DSP處理也可用于一部分AI處理,這屬于運算能力低于 1 TOPS 的用例,這種配置需要大型DSP+小型AI。這種配置的具體示例是為永磁同步電機 (PMSM) 執行無傳感器磁場定向控制 (FOC) 的矢量 DSP。基于 DSP 的電機控制通過 AI 處理實現擴展,AI 處理的作用是執行位置監控,并將相關信息反饋到控制回路。AI 模型的采樣率和計算復雜性使其能夠與矢量DSP的AI功能相適應。
在第二種配置中(中間),AI SoC 需要很高的矢量DSP性能和AI 性能,這種配置是大型 AI+大型 DSP。當矢量DSP處理高度依賴DSP的任務時,需要用NPU為AI密集型任務提供的神經網絡加速作為補充。數碼相機就是這種配置,矢量 DSP 可以對 NPU 執行視覺處理以及預處理和后處理支持,而 NPU 則專用于對高分辨率圖像進行 CNN 或轉換器處理(對象檢測、語義分割、超分辨率等)。這些用例需要緊密集成的矢量 DSP 和 NPU 解決方案,而且可進行擴展以適應性能目標。
第三個配置是小型 DSP+大型 AI。所有的處理都集中在神經網絡上,雖然這些神經網絡通常可以在 NPU 中執行,但有一些更復雜的神經網絡模型需要矢量 DSP 的支持來執行浮點運算,如Mask-RCNN 的 ROI 池化和 ROI 對齊,或 Deeplab v3 使用的非整數比例因子。即使 AI SoC 不需要任何額外的 DSP 處理,納入一定程度的矢量 DSP 性能來支持 NPU 還是有好處的,這可以更好地適應未來的發展需求。
新思科技ARC EV7x能夠實現
矢量DSP和NPU緊密耦合
雖然市場上有多種矢量DSP和NPU供選擇,但對于第二種和第三種配置,最好選擇包含緊密集成處理器的 AI 解決方案。一些神經網絡加速器將矢量DSP嵌入到神經網絡解決方案中,這樣限制了矢量DSP用于外部編程。
而新思科技的ARC EV7x 視覺處理器是異構處理器,它將矢量DSP與可選的神經網絡引擎緊密耦合。為了提高客戶的靈活性和可編程性,ARC EV7x系列正在發展成為 ARC VPX 矢量 DSP 系列和 ARC NPX NPU 系列。VPX 和 NPX 是緊密耦合的 AI 解決方案。圖 3 顯示了這兩種處理器的粗略框圖及其互連方式。
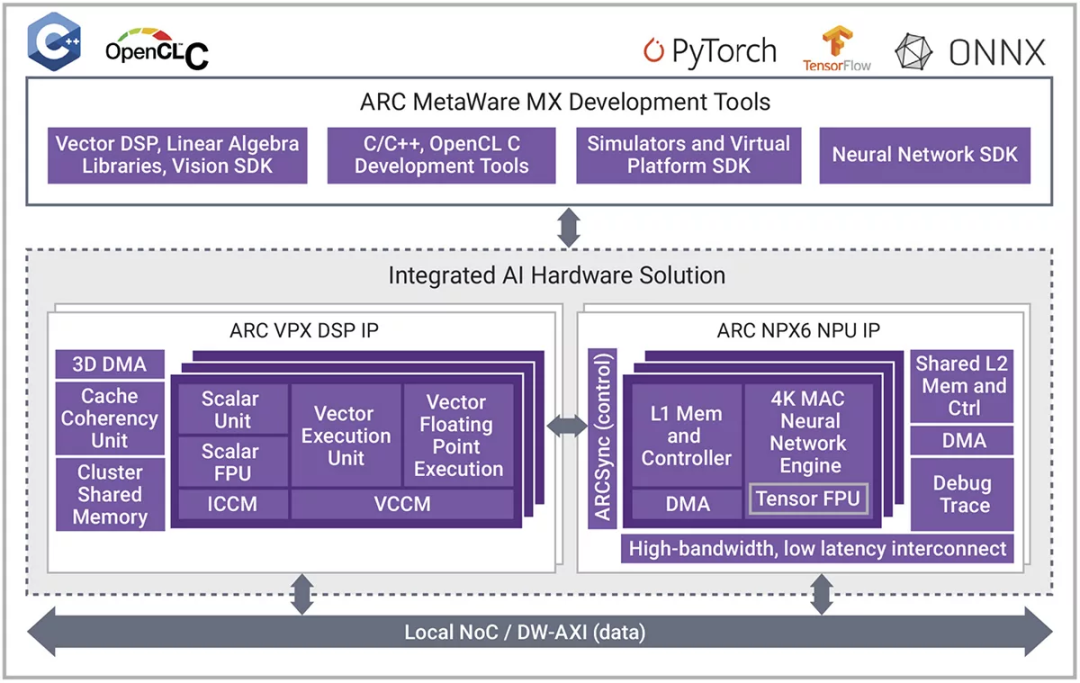
圖 3:新思科技 ARC VPX5 和 ARC NPX6 的緊密耦合型組合
ARC VPX DSP IP在基于超長指令字 (VLIW)/單指令多數據 (SIMD) 架構的并行 DSP 處理方面表現出色,并針對嵌入式工作負載的功耗、性能和面積 (PPA) 要求進行了優化。可將 VPX 系列配置為支持浮點和多種整數格式(包括用于 AI 推理的 INT8 運算)。VPX 系列在 128 位(VPX2、VPX2FS)、256 位(VPX3、VPX3FS)和 512 位(VPX5、VPX5FS)矢量字上運行,因此可提供多種性能,還可以從單核擴展到四核。這樣可以每個周期提供 16 個 INT8 MAC 至 512 個 INT8 MAC(在四核 VPX5 上使用雙 MAC 配置)。
ARC NPX NPU IP專用于 NN 處理,還針對實時應用的 PPA 要求進行了優化。該系列從每個周期 4096 個 MAC 的版本擴展到每個周期 96000 個 MAC 的版本,然后可以擴展到多個實例。NXP6 系列在單個 SoC 上的 AI 性能可從 1 TOPS 擴展到 1000 TOPS。它還針對 CNN 的最新神經網絡模型和新興的轉換器模型類別進行了優化。
如圖 3 所示,VPX 和 NPX 系列緊密集成。ARCsync 是額外的 RTL,可在處理器之間提供中斷控制。數據通過外部 NOC 或 AXI 總線傳遞,這類總線通常已在 SoC 系統中存在。雖然兩個處理器可以完全獨立運行,但 VPX5 能夠根據需要訪問 NPX6 的 L2 內存。
通用軟件開發工具鏈 ARC MetaWare MX 也支持 VPX5 和 NPX6 的緊密集成,該工具鏈支持 NXP 和 VPX 的任意組合。SoC 架構師可以使用這些可擴展處理器系列選擇 DSP 性能和 AI 性能的正確組合,以最大限度地提高性能并減少面積開銷。對于高度依賴 AI 的工作負載,“大型 AI,小型 DSP”配置的經驗法則是,每 8000 或 16000 個 MAC 為 NPX 配備一個 VPX5(具體取決于模型和工作負載)。對于 NPX6-64K 配置,建議至少使用四個 VPX5 內核。
結語
誠然,對于特定任務(例如行人對象檢測),神經網絡處理已經取代了 DSP 處理,但矢量 DSP 的 SIMD 功能與 DSP 支持功能和 AI 支持功能相結合,可使其成為 AI 系統的重要組成部分。隨著嵌入式應用對 AI 處理的需求持續增長,要實現靈活設計,建議的最佳做法是結合使用 NPU 和矢量 DSP,前者用于AI處理,后者用于提供對NPU支持和DSP處理,這樣有助于為快速發展的AI提供具有前瞻性的AI SoC。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107800 -
AI
+關注
關注
91文章
39793瀏覽量
301450 -
自動駕駛
+關注
關注
793文章
14883瀏覽量
179903
原文標題:AI應用的絕佳組合:NPU+DSP!
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【迅為iTOP-Hi3403開發板】一站式啟動Hi3403 NPU開發:從運行例程開始,快速驗證AI效能

使用NORDIC AI的好處
【新品發布】艾為重磅發布端側AI高性能NPU語音芯片,打造智能語音體驗新標桿

瑞芯微SOC智能視覺AI處理器
AI硬件全景解析:CPU、GPU、NPU、TPU的差異化之路,一文看懂!?

安謀科技:端側NPU技術創新,拉動AI算力落地引擎

安謀發布“周易”X3 NPU,破局AI算力,智繪未來藍圖

【RK3568 NPU實戰】別再閑置你的NPU!手把手帶你用迅為資料跑通Android AI檢測Demo,附完整流程與效果

如何利用NPU與模型壓縮技術優化邊緣AI
國產AI芯片真能扛住“算力內卷”?海思昇騰的這波操作藏了多少細節?
工業視覺網關:RK3576賦能多路檢測與邊緣AI
AI體驗躍遷,天璣9500用雙NPU開創端側AI新時代

天璣9500 性能大爆發!NPU AI算力或達100TOPS




 工商網監
工商網監
評論