") GTC 2023主題直播:使用Picasso服務構(gòu)建圖片和視頻生成式模型
GTC 2023主題直播:使用Picasso服務構(gòu)建圖片和視頻生成式模型

Picasso是一項視覺語言模型制作服務,面向希望使用許可內(nèi)容或?qū)S袃?nèi)容
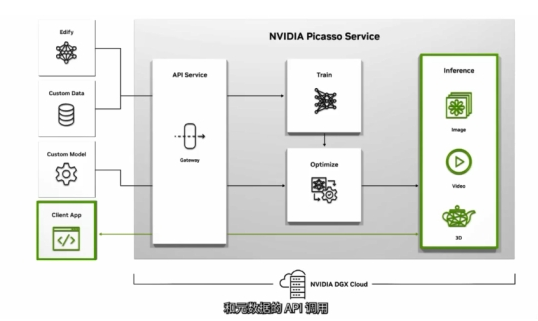
可將生成的素材導入編輯工具或NVIDIA Omniverse,以構(gòu)建逼真的虛擬世界,您可以簡化構(gòu)建自定義生成式AI應用所需的。
我們很高興Getty Images將使用Picasso服務構(gòu)建Edify圖片和Edify視頻生成式模型。
這些模型以其豐富的內(nèi)容庫為基礎(chǔ)進行訓練,其中包含大量以負責任授權(quán)的方式獲得許可的專業(yè)圖像和視頻素材。Shutterstock將幫助簡化用于創(chuàng)意制作、數(shù)字孿生和虛擬協(xié)作的3D素材的創(chuàng)建過程
我很高興地宣布,我們與Adobe之間的長期合作將迎來重要擴展。針對圖像、視頻3D和動畫制作進行優(yōu)化。
GTC 2023主題直播地址:https://t.elecfans.com/live/2302.html
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5594瀏覽量
109743 -
gtc
+關(guān)注
關(guān)注
0文章
74瀏覽量
4766
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
商湯科技日日新Seko系列模型與寒武紀成功適配
12月15日,商湯科技基于在生成式AI與多模態(tài)交互領(lǐng)域的技術(shù)積累,正式發(fā)布Seko2.0——行業(yè)首個多劇集生成智能體。該智能體在多劇集視頻生成的一致性方面展現(xiàn)出顯著優(yōu)勢,其背后依托的是
openDACS 2025 開源EDA與芯片賽項 賽題七:基于大模型的生成式原理圖設(shè)計
智能生成。
4. 賽題內(nèi)容
4.1賽題描述
本賽題要求參賽隊伍構(gòu)建合理規(guī)模的知識庫,運用提示詞工程,構(gòu)建一個完整的生成式原理圖設(shè)計系統(tǒng)。 參
發(fā)表于 11-13 11:49
OpenAI Sora 2模型上線微軟Azure AI Foundry國際版
我們非常激動地宣布,OpenAI 的新一代多模態(tài)視頻生成模型 Sora 2 現(xiàn)已在 Azure AI Foundry(國際版)上線,進入公共預覽階段。

全球首個動漫專屬AI視頻生成平臺Animon,國內(nèi)版"萌動AI"正式發(fā)布
Animon國內(nèi)版——"萌動AI"首秀:AI動漫創(chuàng)作進入全民時代 北京2025年9月25日?/美通社/ -- CreateAI(OTC:TSPH)今日宣布,其打造的全球首個專注于動漫的AI視頻生成
思必馳一鳴智能客服大模型通過生成式人工智能服務備案
近日,江蘇網(wǎng)信發(fā)布新一批生成式人工智能服務備案信息,其中,由思必馳控股子公司馳必準自主研發(fā)的一鳴智能客服大模型通過《生成
中車斫輪大模型通過國家生成式人工智能服務備案
9月14日,國家互聯(lián)網(wǎng)信息辦公室發(fā)布最新公告,“中車斫輪”大模型通過“生成式人工智能服務”備案,標志著其在數(shù)據(jù)安全治理、模型機制透明度、內(nèi)容
華盛昌DeepSense深度感測大模型通過生成式人工智能服務備案
近日,深圳市華盛昌科技實業(yè)股份有限公司(以下簡稱“華盛昌”)的“DeepSense深度感測大模型”在歷經(jīng)屬地網(wǎng)信辦初審、中央網(wǎng)信辦終審及六大部委意見征詢后,通過廣東省生成式人工智能服務
【Sipeed MaixCAM Pro開發(fā)板試用體驗】基于MaixCAM-Pro的AI生成圖像鑒別系統(tǒng)
1. 項目概述
本項目旨在開發(fā)并部署一個高精度的深度學習模型,用于自動鑒別一張圖片是由AI生成(如Stable Diffusion, DALL-E, Midjourney等工具生成)還
發(fā)表于 08-21 13:59
Copilot操作指南(一):使用圖片生成原理圖符號、PCB封裝
“ ?上周推出支持圖片生成模型的華秋發(fā)行版之后,得到了很多小伙伴的肯定。但看到更多的回復是:為什么我的 Copilot 無法生成符號?只有普通的文本回復?今天就為大家詳細講解下
百度重磅發(fā)布!全球首創(chuàng)中文音視頻模型
電子發(fā)燒友網(wǎng)綜合報道 2025年7月2日,百度在北京正式發(fā)布全球首個中文音視頻一體化生成模型——MuseSteamer,標志著其正式進軍圖生視頻領(lǐng)域。這款
一種基于擴散模型的視頻生成框架RoboTransfer
在機器人操作領(lǐng)域,模仿學習是推動具身智能發(fā)展的關(guān)鍵路徑,但高度依賴大規(guī)模、高質(zhì)量的真實演示數(shù)據(jù),面臨高昂采集成本與效率瓶頸。仿真器雖提供了低成本數(shù)據(jù)生成方案,但顯著的“模擬到現(xiàn)實”(Sim2Real)鴻溝,制約了仿真數(shù)據(jù)訓練策略的泛化能力與落地應用。

4K、多模態(tài)、長視頻:AI視頻生成的下一個戰(zhàn)場,誰在領(lǐng)跑?
電子發(fā)燒友網(wǎng)報道(文/李彎彎) 6月11日,豆包App上線視頻生成模型豆包Seedance 1.0 pro。這是字節(jié)跳動最新視頻模型,支持文字與圖片
NVIDIA GTC 2025精華一文讀完 黃仁勛在GTC上的主題演講
來自 NVIDIA 年度最大活動 GTC 的精華新聞,內(nèi)容涵蓋最新服務和硬件、技術(shù)演示以及 AI 的未來發(fā)展趨勢。 GTC 2025 將揭示 AI 的最新發(fā)展趨勢。這里不僅有最新技術(shù),還匯聚了推動




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論