 輕松學Pytorch之Deeplabv3推理
輕松學Pytorch之Deeplabv3推理

Deeplabv3
Torchvision框架中在語義分割上支持的是Deeplabv3語義分割模型,而且支持不同的backbone替換,這些backbone替換包括MobileNetv3、ResNet50、ResNet101。其中MobileNetv3版本訓練數據集是COCO子集,類別跟Pascal VOC的20個類別保持一致。這里以它為例,演示一下從模型導出ONNX到推理的全過程。ONNX格式導出
首先需要把pytorch的模型導出為onnx格式版本,用下面的腳本就好啦:
model=tv.models.segmentation.deeplabv3_mobilenet_v3_large(pretrained=True)
dummy_input=torch.randn(1,3,320,320)
model.eval()
model(dummy_input)
im=torch.zeros(1,3,320,320).to("cpu")
torch.onnx.export(model,im,
"deeplabv3_mobilenet.onnx",
verbose=False,
opset_version=11,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=['input'],
output_names=['out','aux'],
dynamic_axes={'input':{0:'batch',2:'height',3:'width'}}
)
模型的輸入與輸出結構如下:
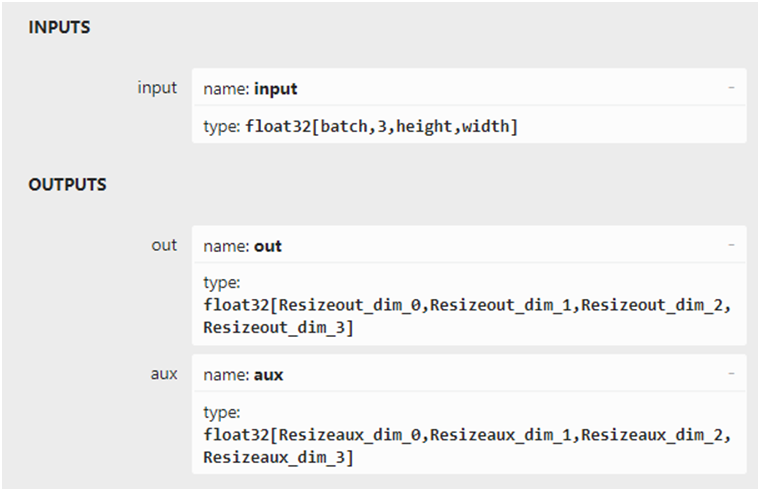
推理測試
模型推理對圖像有個預處理,要求如下:
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
意思是轉換為0~1之間的浮點數,然后減去均值除以方差。
剩下部分的代碼就比較簡單,初始化onnx推理實例,然后完成推理,對結果完成解析,輸出推理結果,完整的代碼如下:
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
])
sess_options=ort.SessionOptions()
#Belowisforoptimizingperformance
sess_options.intra_op_num_threads=24
#sess_options.execution_mode=ort.ExecutionMode.ORT_PARALLEL
sess_options.graph_optimization_level=ort.GraphOptimizationLevel.ORT_ENABLE_ALL
ort_session=ort.InferenceSession("deeplabv3_mobilenet.onnx",providers=['CUDAExecutionProvider'],sess_options=sess_options)
#src=cv.imread("D:/images/messi_player.jpg")
src=cv.imread("D:/images/master.jpg")
image=cv.cvtColor(src,cv.COLOR_BGR2RGB)
blob=transform(image)
c,h,w=blob.shape
input_x=blob.view(1,c,h,w)
defto_numpy(tensor):
returntensor.detach().cpu().numpy()iftensor.requires_gradelsetensor.cpu().numpy()
#computeONNXRuntimeoutputprediction
ort_inputs={ort_session.get_inputs()[0].name:to_numpy(input_x)}
ort_outs=ort_session.run(None,ort_inputs)
t1=ort_outs[0]
t2=ort_outs[1]
labels=np.argmax(np.squeeze(t1,0),axis=0)
print(labels.dtype,labels.shape)
red_map=np.zeros_like(labels).astype(np.uint8)
green_map=np.zeros_like(labels).astype(np.uint8)
blue_map=np.zeros_like(labels).astype(np.uint8)
forlabel_numinrange(0,len(label_color_map)):
index=labels==label_num
red_map[index]=np.array(label_color_map)[label_num,0]
green_map[index]=np.array(label_color_map)[label_num,1]
blue_map[index]=np.array(label_color_map)[label_num,2]
segmentation_map=np.stack([blue_map,green_map,red_map],axis=2)
cv.addWeighted(src,0.8,segmentation_map,0.2,0,src)
cv.imshow("deeplabv3",src)
cv.waitKey(0)
cv.destroyAllWindows()
運行結果如下:
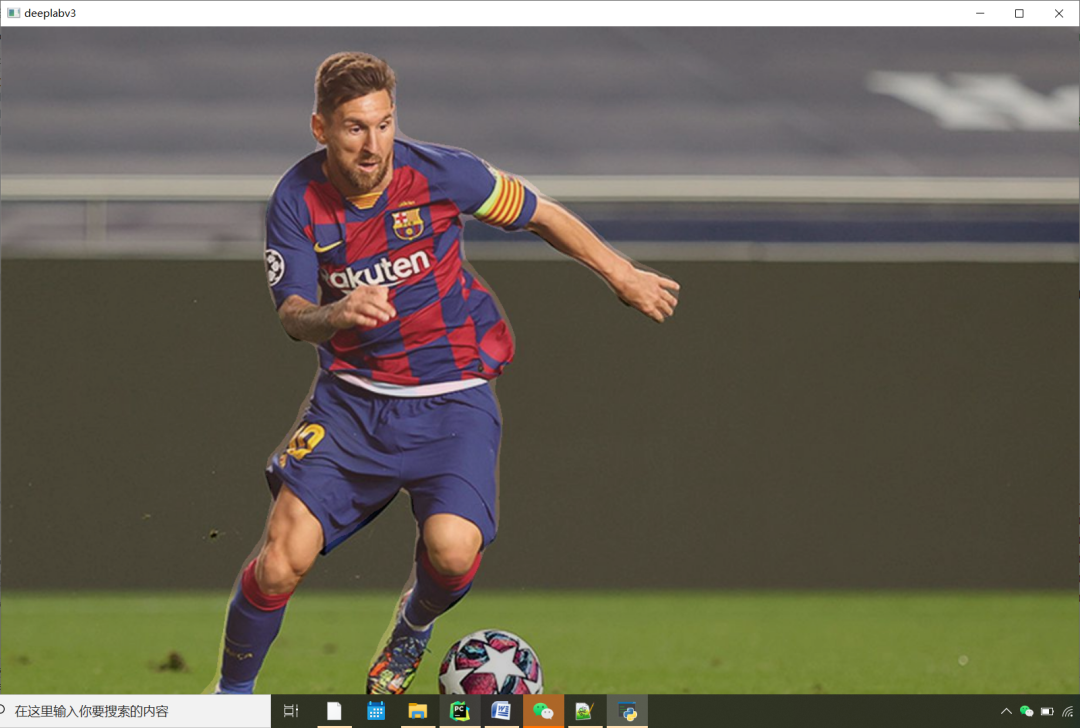
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據集
+關注
關注
4文章
1236瀏覽量
26190 -
pytorch
+關注
關注
2文章
813瀏覽量
14850
原文標題:輕松學Pytorch之Deeplabv3推理
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
AI功能(SC171開發套件V2-FAS)
AI功能(SC171開發套件V2-FAS)
序列
課程名稱
視頻課程時長
視頻課程鏈接
課件鏈接
工程源碼
1
圖像語義分割(deeplabv3)案例----基于SC171開發套件V2-FAS
發表于 02-11 14:33
Pytorch 與 Visionfive2 兼容嗎?
Pytorch 與 Visionfive2 兼容嗎?
$ pip3 install torch torchvision torchaudio --index-url https
發表于 02-06 08:28
商湯開源SenseNova-MARS:突破多模態搜索推理天花板
今日,商湯正式開源多模態自主推理模型 SenseNova-MARS(8B/32B 雙版本),其在多模態搜索與推理的核心基準測試中以 69.74 分超越Gemini-3-Pro(69.06 分
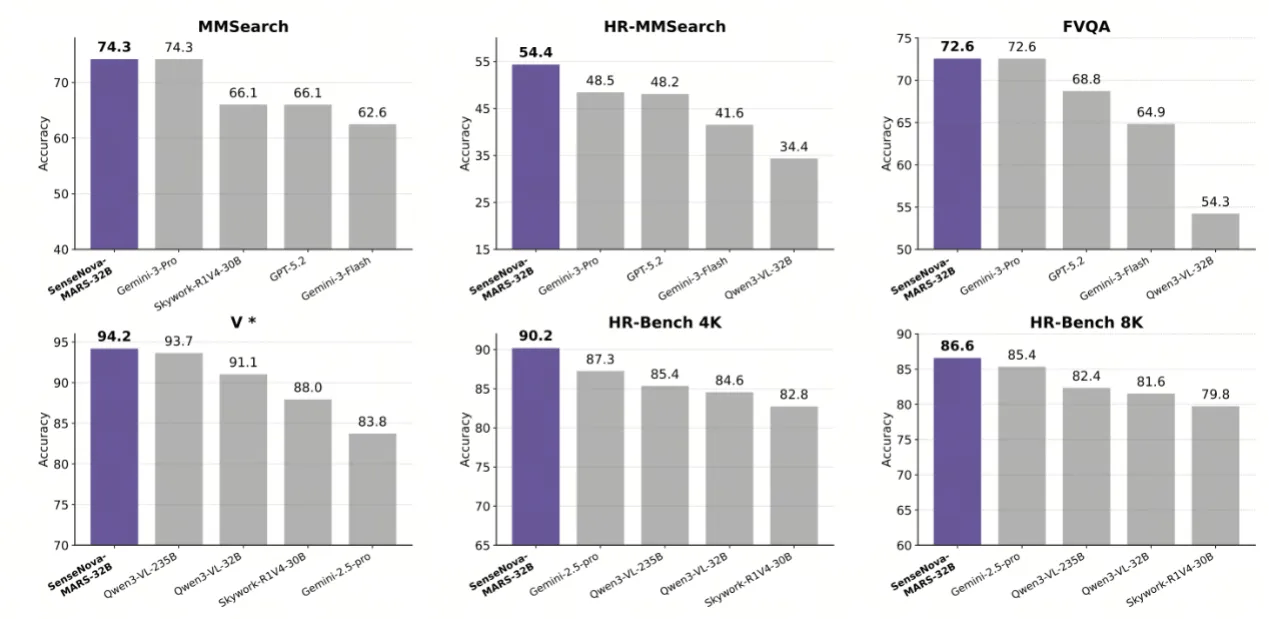
曦望發布新一代推理GPU芯片,單位Token推理成本降低90%
電子發燒友網報道 1月27日,國產GPU廠商曦望(Sunrise)重磅發布新一代推理GPU芯片——啟望S3。這是曦望在近一年累計完成約30億元戰略融資后的首次集中公開亮相。2025年,曦望芯片交付量
今日看點:消息稱 AMD、高通考慮導入 SOCAMM 內存;曦望發布新一代推理GPU芯片啟望S3
曦望發布新一代推理GPU芯片啟望S3 近日,浙江杭州GPU創企曦望(Sunrise)發布新一代推理GPU芯片啟望S3,并推出面向大模型推理的
發表于 01-28 11:09
?384次閱讀
阿里巴巴發布通義千問旗艦推理模型Qwen3-Max-Thinking
今天,我們正式發布千問旗艦推理模型Qwen3-Max-Thinking,創下數項權威評測全球新紀錄。

LLM推理模型是如何推理的?
這篇文章《(How)DoReasoningModelsReason?》對當前大型推理模型(LRM)進行了深刻的剖析,超越了表面的性能宣傳,直指其技術本質和核心局限。以下是基于原文的詳細技術原理、關鍵

AI功能(SC171開發套件V3)2026版
分割(deeplabv3)案例----基于SC171開發套件V3
8分02秒
https://t.elecfans.com/v/28529.html
*附件:文檔:圖像語義分割(deeplabv3
發表于 01-15 11:18

信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
故障)”的自動化推理鏈條。3.預測性防御:智能基線洞察,防患于未然l 基于先進的時序分解算法,為每個關鍵業務終端/鏈路動態構建多維性能基線(吞吐量、時延、丟包率)。l 主動預警潛在風險,如帶寬瓶頸
發表于 07-16 15:29
大模型推理顯存和計算量估計方法研究
隨著人工智能技術的飛速發展,深度學習大模型在各個領域得到了廣泛應用。然而,大模型的推理過程對顯存和計算資源的需求較高,給實際應用帶來了挑戰。為了解決這一問題,本文將探討大模型推理顯存和計算量的估計
發表于 07-03 19:43
將Whisper大型v3 fp32模型轉換為較低精度后,推理時間增加,怎么解決?
將 openai/whisper-large-v3 FP32 模型轉換為 FP16、INT8 和 INT4。
推理所花費的時間比在 FP32 上花費的時間要多
發表于 06-24 06:23
AI功能(SC171開發套件V3)
AI功能(SC171開發套件V3)
序列
課程名稱
視頻課程時長
視頻課程鏈接
課件鏈接
工程源碼
1
圖像語義分割(deeplabv3)案例----基于SC171開發套件V3
7分44秒
發表于 04-16 18:48
有獎直播 | @4/8 輕松部署,強大擴展邊緣運算 AI 新世代
MemryX推出全新MemryXMX3AI推理加速卡,采用PCIeGen3M.2M-Key接口,提供高達20TOPS的強大算力,為工業計算機帶來即插即用的AI部署體驗。結合OrangePi5Plus




 工商網監
工商網監
評論