 GPU硬件架構及運行機制(下)
GPU硬件架構及運行機制(下)

4.4 GPU資源機制
本節將闡述GPU的內存訪問、資源管理等機制。
4.4.1 內存架構
部分架構的GPU與CPU類似,也有多級緩存結構:寄存器、L1緩存、L2緩存、GPU顯存、系統顯存。
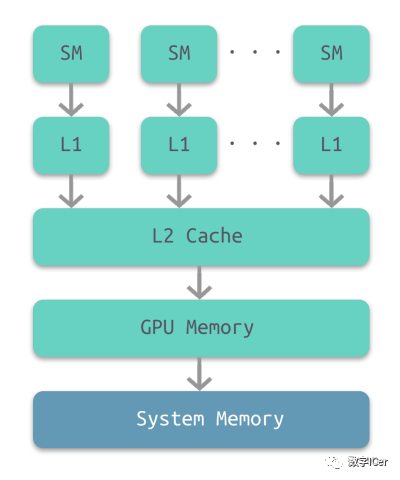
它們的存取速度從寄存器到系統內存依次變慢: 存儲類型 寄存器 共享內存 L1緩存 L2緩存 紋理、常量緩存 全局內存
| 訪問周期 | 1 | 1~32 | 1~32 | 32~64 | 400~600 | 400~600 |
由此可見,shader直接訪問寄存器、L1、L2緩存還是比較快的,但訪問紋理、常量緩存和全局內存非常慢,會造成很高的延遲。 上面的多級緩存結構可被稱為“CPU-Style”,還存在GPU-Style的內存架構:
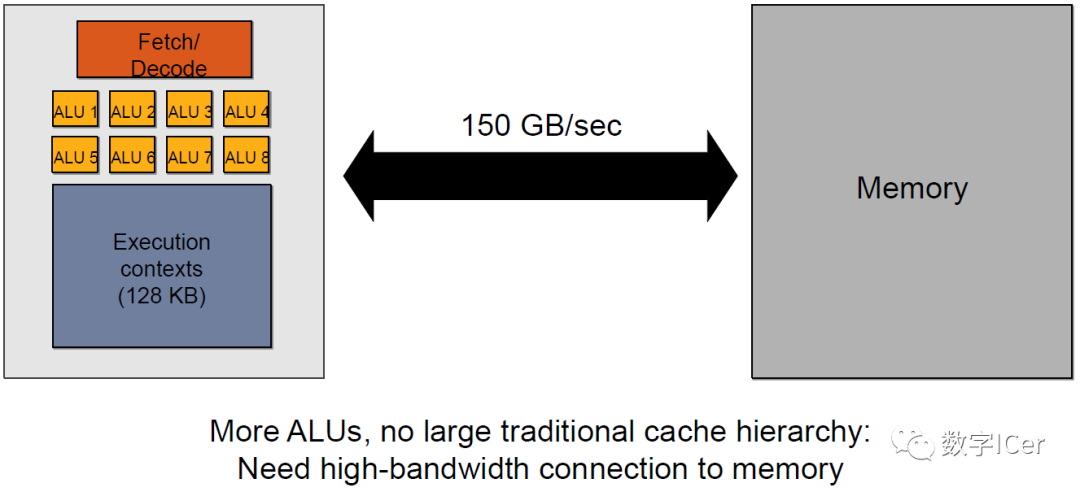
這種架構的特點是ALU多,GPU上下文(Context)多,吞吐量高,依賴高帶寬與系統內存交換數據。
4.4.2 GPU Context和延遲
由于SIMT技術的引入,導致很多同一個SM內的很多Core并不是獨立的,當它們當中有部分Core需要訪問到紋理、常量緩存和全局內存時,就會導致非常大的卡頓(Stall)。 例如下圖中,有4組上下文(Context),它們共用同一組運算單元ALU。
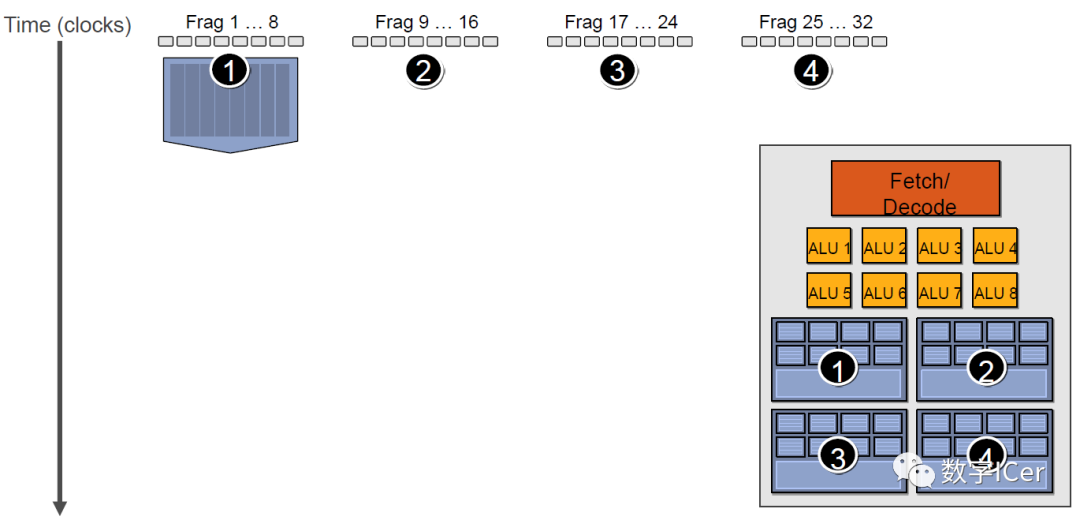
假設第一組Context需要訪問緩存或內存,會導致2~3個周期的延遲,此時調度器會激活第二組Context以利用ALU:
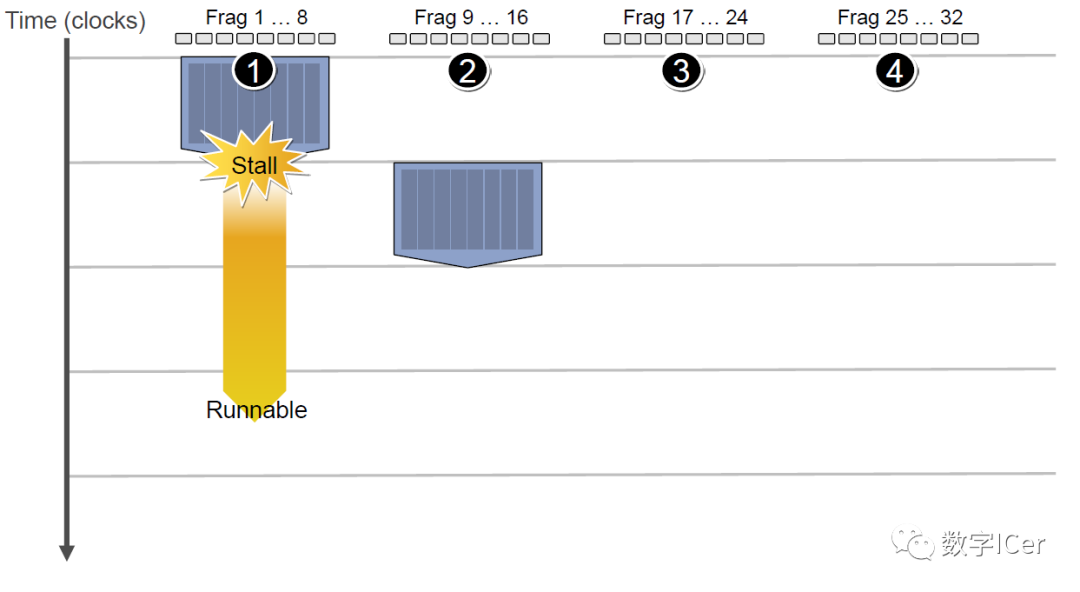
當第二組Context訪問緩存或內存又卡住,會依次激活第三、第四組Context,直到第一組Context恢復運行或所有都被激活:
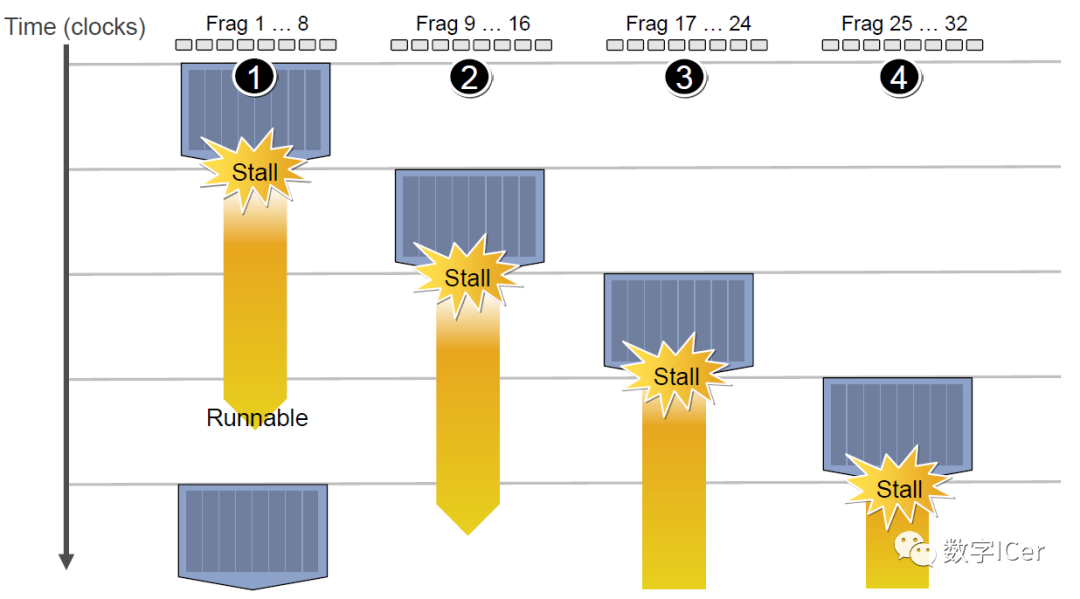
延遲的后果是每組Context的總體執行時間被拉長了:
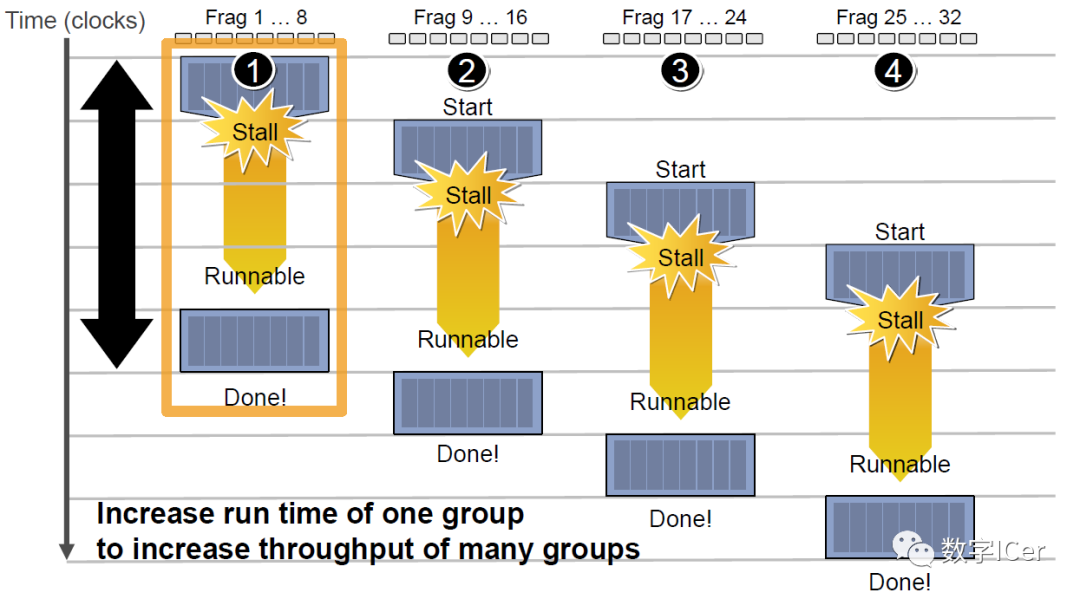
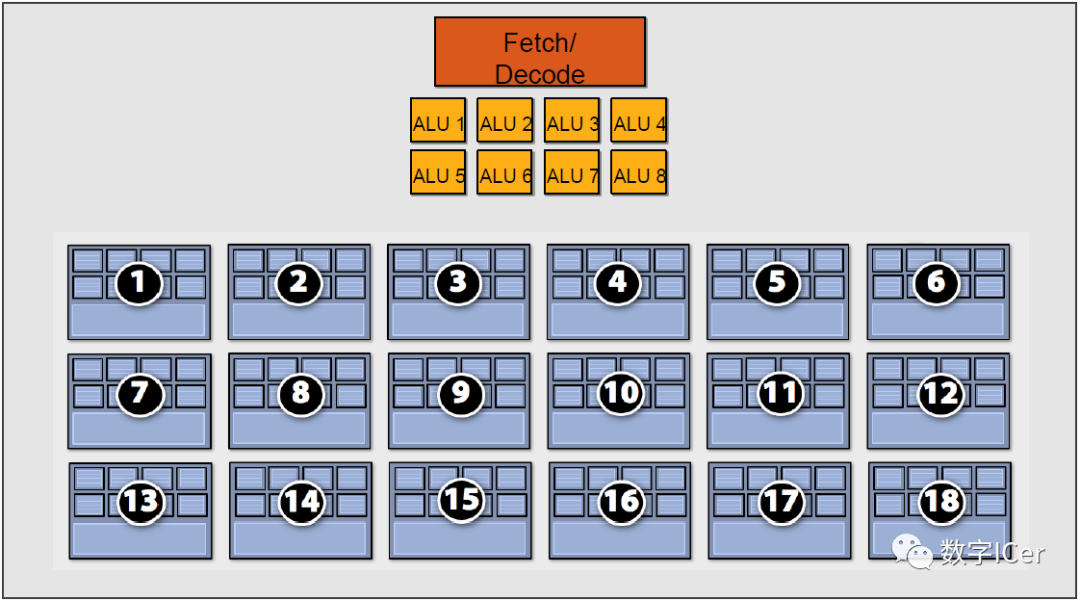
但是,越多Context可用就越可以提升運算單元的吞吐量,比如下圖的18組Context的架構可以最大化地提升吞吐量:
4.4.3 CPU-GPU異構系統
根據CPU和GPU是否共享內存,可分為兩種類型的CPU-GPU架構:
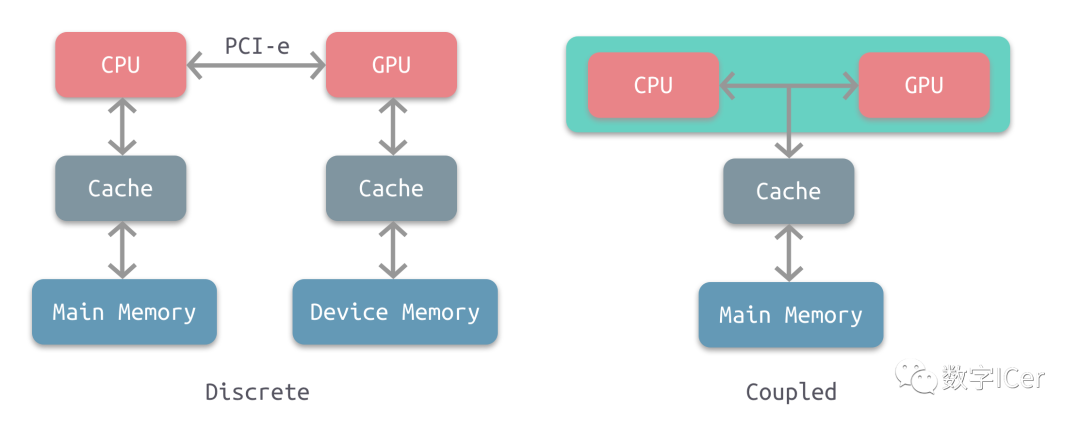
上圖左是分離式架構,CPU和GPU各自有獨立的緩存和內存,它們通過PCI-e等總線通訊。這種結構的缺點在于 PCI-e 相對于兩者具有低帶寬和高延遲,數據的傳輸成了其中的性能瓶頸。目前使用非常廣泛,如PC、智能手機等。 上圖右是耦合式架構,CPU 和 GPU 共享內存和緩存。AMD 的 APU 采用的就是這種結構,目前主要使用在游戲主機中,如 PS4。 在存儲管理方面,分離式結構中 CPU 和 GPU 各自擁有獨立的內存,兩者共享一套虛擬地址空間,必要時會進行內存拷貝。對于耦合式結構,GPU 沒有獨立的內存,與 GPU 共享系統內存,由 MMU 進行存儲管理。
4.4.4 GPU資源管理模型
下圖是分離式架構的資源管理模型:
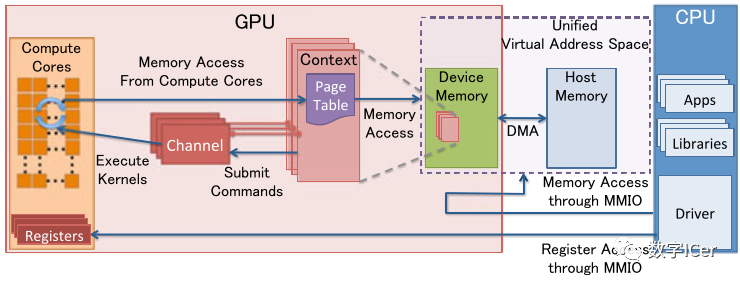
MMIO(Memory Mapped IO)
CPU與GPU的交流就是通過MMIO進行的。CPU 通過 MMIO 訪問 GPU 的寄存器狀態。
DMA傳輸大量的數據就是通過MMIO進行命令控制的。
I/O端口可用于間接訪問MMIO區域,像Nouveau等開源軟件從來不訪問它。
GPU Context
GPU Context代表了GPU計算的狀態。
在GPU中擁有自己的虛擬地址。
GPU 中可以并存多個活躍態下的Context。
GPU Channel
任何命令都是由CPU發出。
命令流(command stream)被提交到硬件單元,也就是GPU Channel。
每個GPU Channel關聯一個context,而一個GPU Context可以有多個GPU channel。
每個GPU Context 包含相關channel的 GPU Channel Descriptors , 每個 Descriptor 都是 GPU 內存中的一個對象。
每個 GPU Channel Descriptor 存儲了 Channel 的設置,其中就包括 Page Table 。
每個 GPU Channel 在GPU內存中分配了唯一的命令緩存,這通過MMIO對CPU可見。
GPU Context Switching 和命令執行都在GPU硬件內部調度。
GPU Page Table
GPU Context在虛擬基地空間由Page Table隔離其它的Context 。
GPU Page Table隔離CPU Page Table,位于GPU內存中。
GPU Page Table的物理地址位于 GPU Channel Descriptor中。
GPU Page Table不僅僅將 GPU虛擬地址轉換成GPU內存的物理地址,也可以轉換成CPU的物理地址。因此,GPU Page Table可以將GPU虛擬地址和CPU內存地址統一到GPU統一虛擬地址空間來。
PCI-e BAR
GPU 設備通過PCI-e總線接入到主機上。Base Address Registers(BARs) 是 MMIO的窗口,在GPU啟動時候配置。
GPU的控制寄存器和內存都映射到了BARs中。
GPU設備內存通過映射的MMIO窗口去配置GPU和訪問GPU內存。
PFIFO Engine
PFIFO是GPU命令提交通過的一個特殊的部件。
PFIFO維護了一些獨立命令隊列,也就是Channel。
此命令隊列是Ring Buffer,有PUT和GET的指針。
所有訪問Channel控制區域的執行指令都被PFIFO 攔截下來。
GPU驅動使用Channel Descriptor來存儲相關的Channel設定。
PFIFO將讀取的命令轉交給PGRAPH Engine。
BO
Buffer Object (BO),內存的一塊(Block),能夠用于存儲紋理(Texture)、渲染目標(Render Target)、著色代碼(shader code)等等。
Nouveau和Gdev經常使用BO。
Nouveau是一個自由及開放源代碼顯卡驅動程序,是為NVidia的顯卡所編寫。 Gdev是一套豐富的開源軟件,用于NVIDIA的GPGPU技術,包括設備驅動程序。
更多詳細可以閱讀論文:Data Transfer Matters for GPU Computing。
4.4.5 CPU-GPU數據流
下圖是分離式架構的CPU-GPU的數據流程圖:
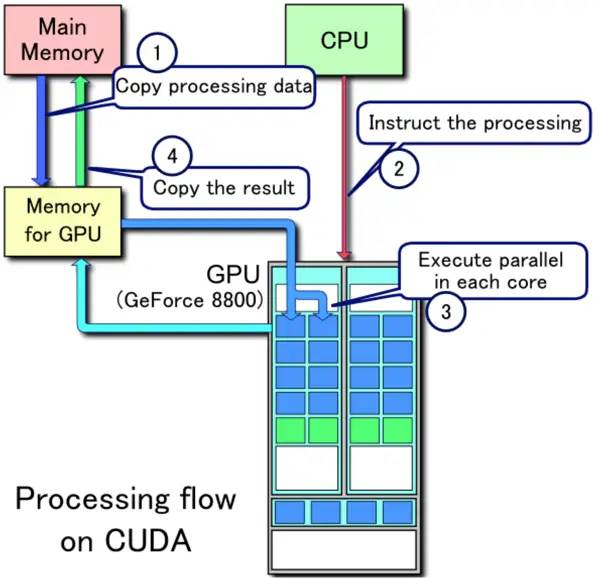
1、將主存的處理數據復制到顯存中。 2、CPU指令驅動GPU。 3、GPU中的每個運算單元并行處理。此步會從顯存存取數據。 4、GPU將顯存結果傳回主存。
4.4.6 顯像機制
水平和垂直同步信號在早期的CRT顯示器,電子槍從上到下逐行掃描,掃描完成后顯示器就呈現一幀畫面。然后電子槍回到初始位置進行下一次掃描。為了同步顯示器的顯示過程和系統的視頻控制器,顯示器會用硬件時鐘產生一系列的定時信號。
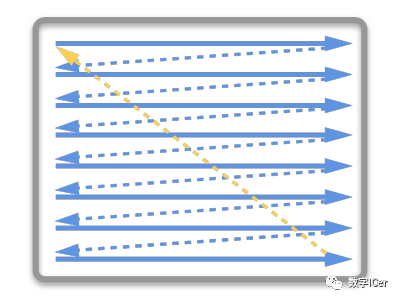
當電子槍換行進行掃描時,顯示器會發出一個水平同步信號(horizonal synchronization),簡稱HSync當一幀畫面繪制完成后,電子槍回復到原位,準備畫下一幀前,顯示器會發出一個垂直同步信號(vertical synchronization),簡稱VSync。 顯示器通常以固定頻率進行刷新,這個刷新率就是 VSync 信號產生的頻率。雖然現在的顯示器基本都是液晶顯示屏了,但其原理基本一致。 CPU將計算好顯示內容提交至 GPU,GPU 渲染完成后將渲染結果存入幀緩沖區,視頻控制器會按照 VSync 信號逐幀讀取幀緩沖區的數據,經過數據轉換后最終由顯示器進行顯示。
雙緩沖在單緩沖下,幀緩沖區的讀取和刷新都都會有比較大的效率問題,經常會出現相互等待的情況,導致幀率下降。 為了解決效率問題,GPU 通常會引入兩個緩沖區,即雙緩沖機制。在這種情況下,GPU 會預先渲染一幀放入一個緩沖區中,用于視頻控制器的讀取。當下一幀渲染完畢后,GPU 會直接把視頻控制器的指針指向第二個緩沖器。
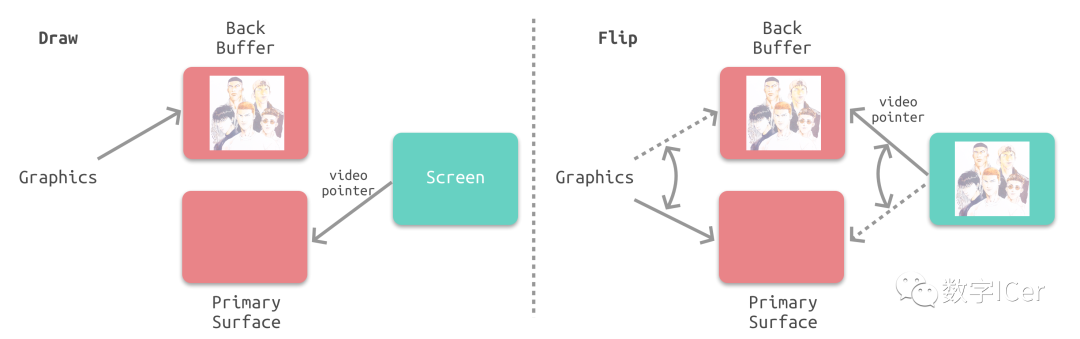
垂直同步雙緩沖雖然能解決效率問題,但會引入一個新的問題。當視頻控制器還未讀取完成時,即屏幕內容剛顯示一半時,GPU 將新的一幀內容提交到幀緩沖區并把兩個緩沖區進行交換后,視頻控制器就會把新的一幀數據的下半段顯示到屏幕上,造成畫面撕裂現象:

為了解決這個問題,GPU 通常有一個機制叫做垂直同步(簡寫也是V-Sync),當開啟垂直同步后,GPU 會等待顯示器的 VSync 信號發出后,才進行新的一幀渲染和緩沖區更新。這樣能解決畫面撕裂現象,也增加了畫面流暢度,但需要消費更多的計算資源,也會帶來部分延遲。
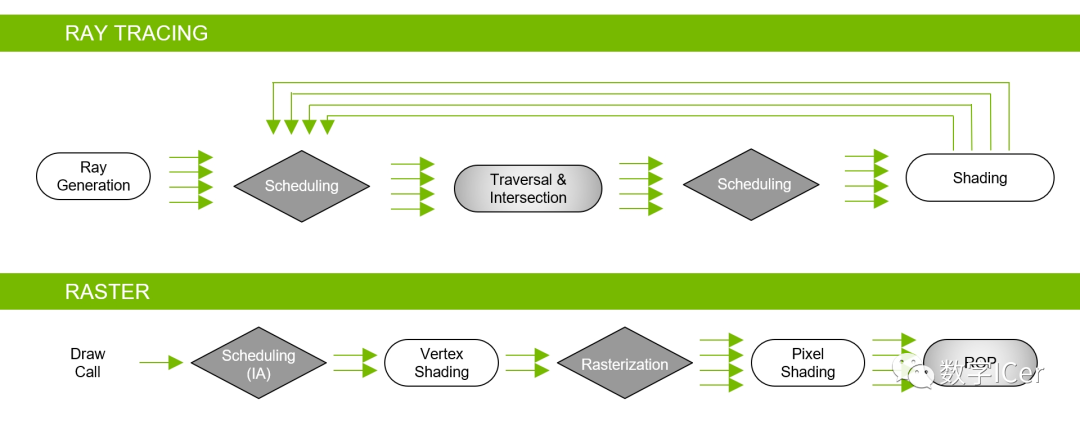
4.5 Shader運行機制
Shader代碼也跟傳統的C++等語言類似,需要將面向人類的高級語言(GLSL、HLSL、CGSL)通過編譯器轉成面向機器的二進制指令,二進制指令可轉譯成匯編代碼,以便技術人員查閱和調試。 由高級語言編譯成匯編指令的過程通常是在離線階段執行,以減輕運行時的消耗。 在執行階段,CPU端將shader二進制指令經由PCI-e推送到GPU端,GPU在執行代碼時,會用Context將指令分成若干Channel推送到各個Core的存儲空間。 對現代GPU而言,可編程的階段越來越多,包含但不限于:頂點著色器(Vertex Shader)、曲面細分控制著色器(Tessellation Control Shader)、幾何著色器(Geometry Shader)、像素/片元著色器(Fragment Shader)、計算著色器(Compute Shader)、...
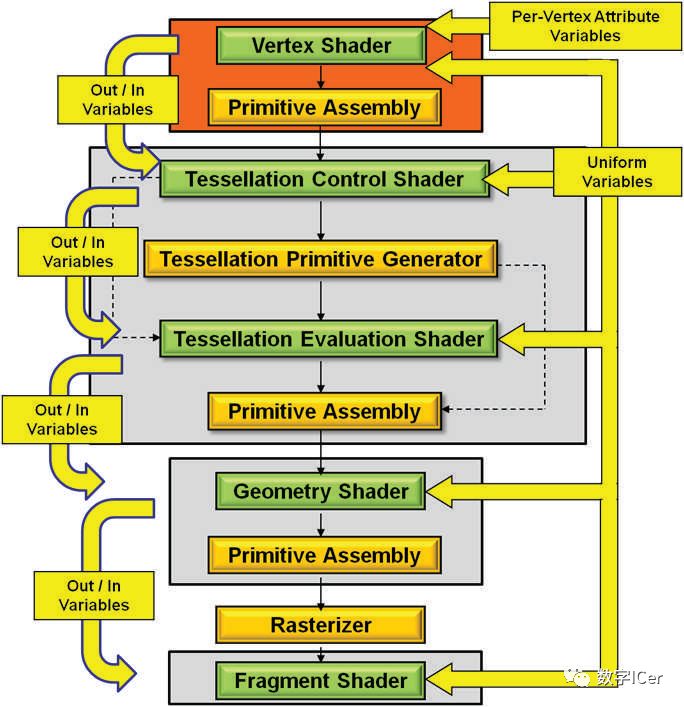
這些著色器形成流水線式的并行化的渲染管線。下面將配合具體的例子說明。 下段是計算漫反射的經典代碼:
sampler mySamp; Texture2D
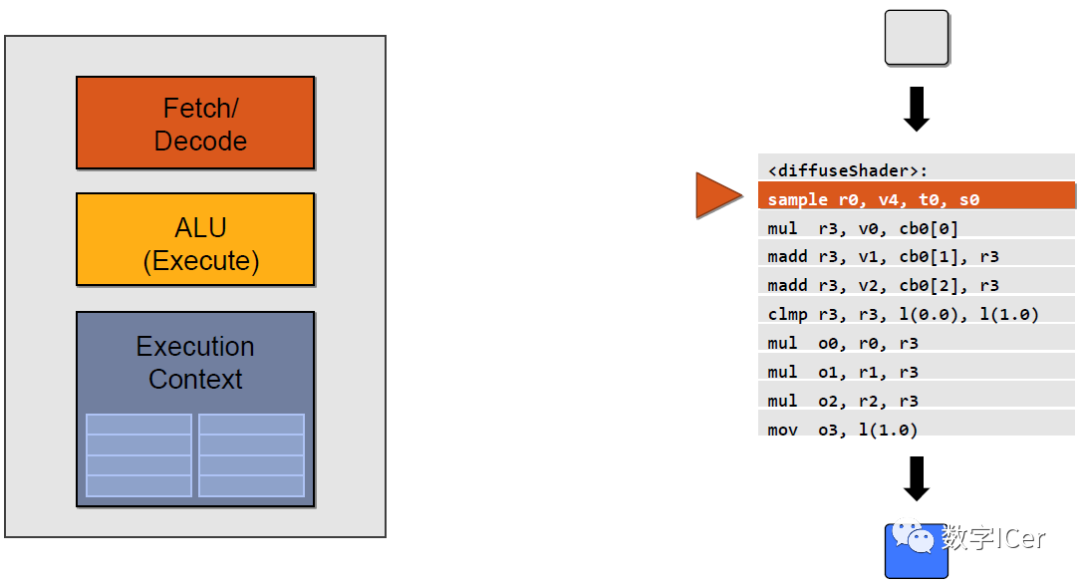
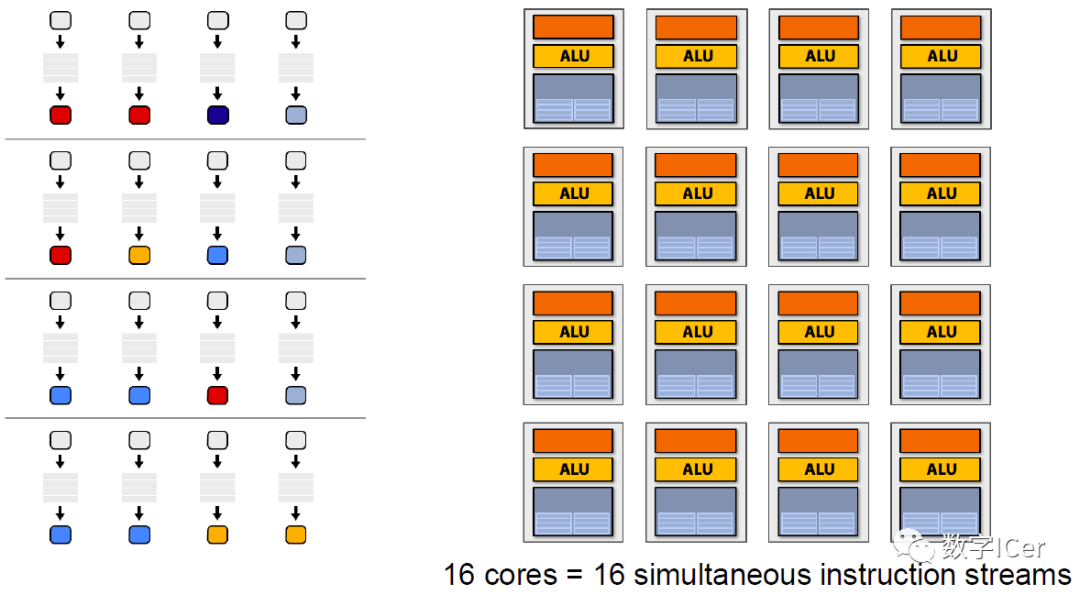
以上示例圖只是單個ALU的執行情況,實際上,GPU有幾十甚至上百個執行單元在同時執行shader指令:
對于SIMT架構的GPU,匯編指令有所不同,變成了SIMT特定指令代碼:
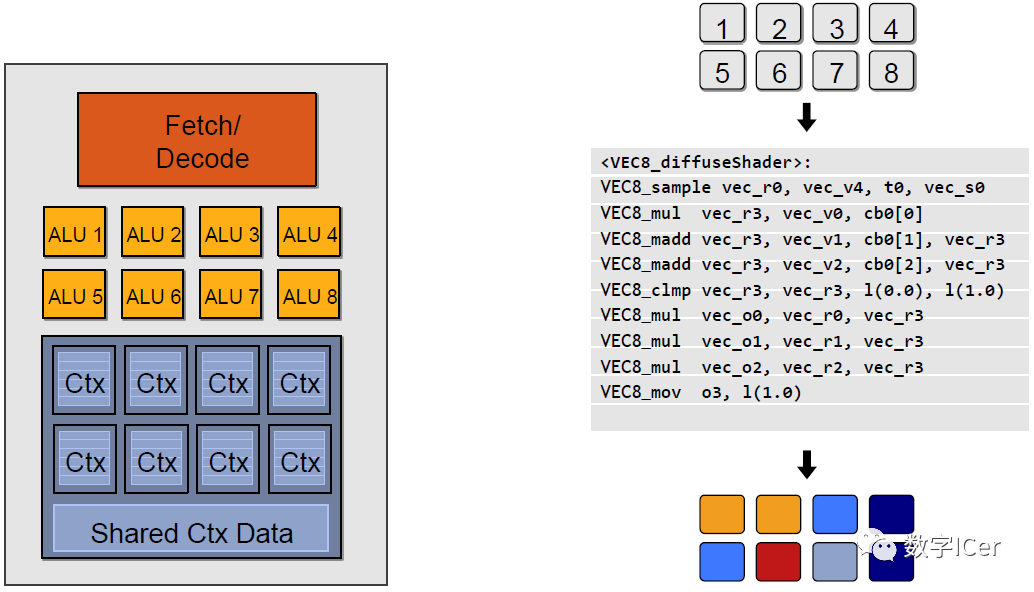
如果有多個Core,就會有更多的ALU同時參與shader計算,每個Core執行的數據是不一樣的,可能是頂點、圖元、像素等任何數據:
4.6 利用擴展例證
NV shader thread group提供了OpenGL的擴展,可以查詢GPU線程、Core、SM、Warp等硬件相關的屬性。如果要開啟次此擴展,需要滿足以下條件:
OpenGL 4.3+;
GLSL 4.3+;
支持OpenGL 4.3+的NV顯卡;
并且此擴展只在NV部分5代著色器內起作用:
This extension interacts with NV_gpu_program5 This extension interacts with NV_compute_program5 This extension interacts with NV_tessellation_program5
下面是具體的字段和代表的意義:
// 開啟擴展 #extension GL_NV_shader_thread_group : require (or enable) WARP_SIZE_NV// 單個線程束的線程數量 WARPS_PER_SM_NV// 單個SM的線程束數量 SM_COUNT_NV// SM數量 uniform uint gl_WarpSizeNV;// 單個線程束的線程數量 uniform uint gl_WarpsPerSMNV;// 單個SM的線程束數量 uniform uint gl_SMCountNV;// SM數量 in uint gl_WarpIDNV;// 當前線程束id in uint gl_SMIDNV;// 當前線程束所在的SM id,取值[0, gl_SMCountNV-1] in uint gl_ThreadInWarpNV;// 當前線程id,取值[0, gl_WarpSizeNV-1] in uint gl_ThreadEqMaskNV;// 是否等于當前線程id的位域掩碼。 in uint gl_ThreadGeMaskNV;// 是否大于等于當前線程id的位域掩碼。 in uint gl_ThreadGtMaskNV;// 是否大于當前線程id的位域掩碼。 in uint gl_ThreadLeMaskNV;// 是否小于等于當前線程id的位域掩碼。 in uint gl_ThreadLtMaskNV;// 是否小于當前線程id的位域掩碼。 in bool gl_HelperThreadNV;// 當前線程是否協助型線程。 上述所說的協助型線程gl_HelperThreadNV是指在處理2x2的像素塊時,那些未被圖元覆蓋的像素著色器線程將被標記為gl_HelperThreadNV = true,它們的結果將被忽略,也不會被存儲,但可輔助一些計算,如導數dFdx和dFdy。為了防止理解有誤,貼出原文:
The variable gl_HelperThreadNV specifies if the current thread is a helper thread. In implementations supporting this extension, fragment shader invocations may be arranged in SIMD thread groups of 2x2 fragments called "quad". When a fragment shader instruction is executed on a quad, it\'s possible that some fragments within the quad will execute the instruction even if they are not covered by the primitive. Those threads are called helper threads. Their outputs will be discarded and they will not execute global store functions, but the intermediate values they compute can still be used by thread group sharing functions or by fragment derivative functions like dFdx and dFdy.
利用以上字段,可以編寫特殊shader代碼轉成顏色信息,以便可視化窺探GPU的工作機制和流程。 利用NV擴展字段,可視化了頂點著色器、像素著色器的SM、Warp id,為我們查探GPU的工作機制和流程提供了途徑。 下面正式進入驗證階段,將以Geforce RTX 2060作為驗證對象,具體信息如下:
操作系統:Windows 10 Pro, 64-bit DirectX 版本:12.0 GPU 處理器:GeForce RTX 2060 驅動程序版本:417.71 Driver Type: Standard Direct3D API 版本:12 Direct3D 功能級別:12_1 CUDA 核心:1920 核心時鐘:1710 MHz 內存數據速率:14.00 Gbps 內存接口:192-位 內存帶寬:336.05 GB/秒 全部可用的圖形內存:22494MB 專用視頻內存:6144 MB GDDR6 系統視頻內存:0MB 共享系統內存:16350MB 視頻 BIOS 版本:90.06.3F.00.73 IRQ:Not used 總線:PCI Express x16 Gen3
首先在應用程序創建包含兩個三角形的頂點數據:
// set up vertex data (and buffer(s)) and configure vertex attributes const float HalfSize = 1.0f; float vertices[] = { -HalfSize, -HalfSize, 0.0f, // left bottom HalfSize, -HalfSize, 0.0f, // right bottom -HalfSize, HalfSize, 0.0f, // top left -HalfSize, HalfSize, 0.0f, // top left HalfSize, -HalfSize, 0.0f, // right bottom HalfSize, HalfSize, 0.0f, // top right }; 渲染采用的頂點著色器非常簡單:#version 430 core layout (location = 0) in vec3 aPos; void main() { gl_Position = vec4(aPos, 1.0f); } 片元著色器也是寥寥數行:#version 430 core out vec4 FragColor; void main() { FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f); } 繪制出來的原始畫面如下: 緊接著,修改片元著色器,加入擴展所需的代碼,并修改顏色計算:#version 430 core #extension GL_NV_shader_thread_group : require uniform uint gl_WarpSizeNV;// 單個線程束的線程數量 uniform uint gl_WarpsPerSMNV;// 單個SM的線程束數量 uniform uint gl_SMCountNV;// SM數量 in uint gl_WarpIDNV;// 當前線程束id in uint gl_SMIDNV;// 當前線程所在的SM id,取值[0, gl_SMCountNV-1] in uint gl_ThreadInWarpNV;// 當前線程id,取值[0, gl_WarpSizeNV-1] out vec4 FragColor; void main() { // SM id float lightness = gl_SMIDNV / gl_SMCountNV; FragColor = vec4(lightness); } 從上面可分析出一些信息:
畫面共有32個亮度色階,也就是Geforce RTX 2060有32個SM。
單個SM每次渲染16x16為單位的像素塊,也就是每個SM有256個Core。
SM之間不是順序分配像素塊,而是無序分配。
不同三角形的接縫處出現斷層,說明同一個像素塊如果分屬不同的三角形,就會分配到不同的SM進行處理。由此推斷,相同面積的區域,如果所屬的三角形越多,就會導致分配給SM的次數越多,消耗的渲染性能也越多。
接著修改片元著色器的顏色計算代碼以顯示Warp id:
// warp id float lightness = gl_WarpIDNV / gl_WarpsPerSMNV; FragColor = vec4(lightness); 由此可得出一些信息或推論:
畫面共有32個亮度色階,也就是每個SM有32個Warp,每個Warp有8個Core。
每個色塊像素是4x8,由于每個Warp有8個Core,由此推斷每個Core單次要處理2x2的最小單元像素塊。
也是無序分配像素塊。
三角形接縫處出現斷層,同SM的推斷一致。
再修改片元著色器的顏色計算代碼以顯示線程id:
// thread id float lightness = gl_ThreadInWarpNV / gl_WarpSizeNV; FragColor = vec4(lightness); 為了方便分析,用Photoshop對中間局部放大10倍,得到以下畫面: 也可以得出一些結論:
相較SM、線程束,線程分布圖比較規律。說明同一個Warp的線程分布是規律的。
三角形接縫處出現紊亂,說明是不同的Warp造成了不同的線程。
畫面有32個色階,說明單個Warp有32個線程。
每個像素獨占一個亮度色階,與周邊相鄰像素都不同,說明每個線程只處理一個像素。
再次說明,以上畫面和結論是基于Geforce RTX 2060,不同型號的GPU可能會不一樣,得到的結果和推論也會有所不同。 更多NV擴展可參見OpenGL官網:NV extensions。
五、總結
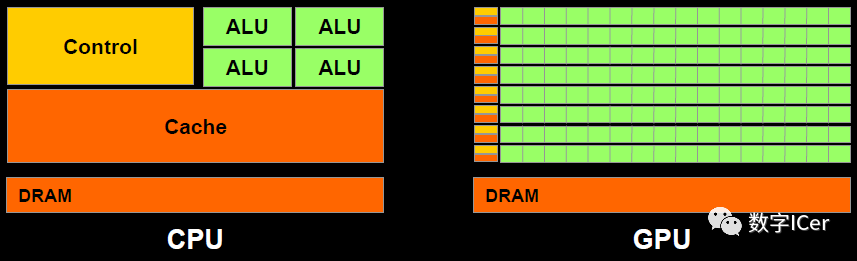
5.1 CPU vs GPU
它們之間的差異(緩存、核心數量、內存、線程數等)可用下圖展示出來:
5.2 渲染優化建議
由上章的分析,可以很容易給出渲染優化建議:
減少CPU和GPU的數據交換:
例如:glGetUniformLocation會從GPU內存查詢狀態,耗費很多時間周期。
避免每幀設置、查詢渲染狀態,可在初始化時緩存狀態。
CPU版的粒子、動畫會每幀修改、提交數據,可移至GPU端。
BVH
Portal
BSP
OSP
合批(Batch)
減少頂點數、三角形數
視錐裁剪
避免每幀提交Buffer數據
減少渲染狀態設置和查詢
啟用GPU Instance
開啟LOD
避免從顯存讀數據
減少過繪制:
粒子數量多且面積小,由于像素塊機制,會加劇過繪制情況
植物、沙石、毛發等也如此
背面裁剪
遮擋裁剪
視口裁剪
剪切矩形(scissor rectangle)
Early-Z
層次Z緩沖(Hierarchical Z-Buffering,HZB)
避免Tex Kill操作
避免Alpha Test
避免Alpha Blend
開啟深度測試
開啟裁剪:
控制物體數量
Shader優化:
避免if、switch分支語句
避免for循環語句,特別是循環次數可變的
減少紋理采樣次數
禁用clip或discard操作
減少復雜數學函數調用
更多優化技巧可閱讀:
移動游戲性能優化通用技法。
GPU Programming Guide。
Real-Time Rendering Resources。
5.3 GPU的未來
從章節[2.2 GPU歷史](#2.2 GPU歷史)可以得出一些結論,也可以推測GPU發展的趨勢:
硬件升級。更多運算單元,更多存儲空間,更高并發,更高帶寬,更低延時。。。
Tile-Based Rendering的集成。基于瓦片的渲染可以一定程度降低帶寬和提升光照計算效率,目前部分移動端及桌面的GPU已經引入這個技術,未來將有望成為常態。
3D內存技術。目前大多數傳統的內存是2D的,3D內存則不同,在物理結構上是3D的,類似立方體結構,集成于芯片內。可獲得幾倍的訪問速度和效能比。

GPU愈加可編程化。GPU天生是并行且相對固定的,未來將會開放越來越多的shader可供編程,而CPU剛好相反,將往并行化發展。也就是說,未來的GPU越來越像CPU,而CPU越來越像GPU。難道它們應驗了古語:合久必分,分久必合么?
實時光照追蹤的普及。基于Turing架構的GPU已經加入大量RT Core、HVB、AI降噪等技術,Hybrid Rendering Pipeline就是此架構的光線追蹤渲染管線,能夠同時結合光柵化器、RT Core、Compute Core執行混合渲染:

Hybrid Rendering Pipeline相當于光線追蹤渲染管線和光柵化渲染管線的合體:
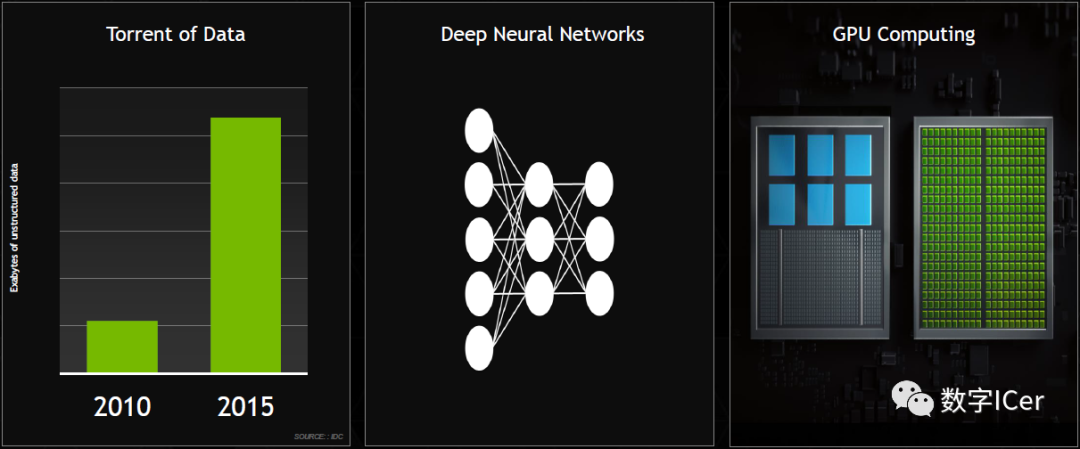
數據并發提升、深度神經網絡、GPU計算單元等普及及提升。
AI降噪和AI抗鋸齒。AI降噪已經在部分RTX系列的光線追蹤版本得到應用,而AI抗鋸齒(Super Res)可用于超高分辨率的視頻圖像抗鋸齒:

基于任務和網格著色器的渲染管線。基于任務和網格著色器的渲染管線(Graphics Pipeline with Task and Mesh Shaders)與傳統的光柵化渲染光線有著很大的差異,它以線程組(Thread Group)、任務著色器(Task shader)和網格著色器(Mesh shader)為基礎,形成一種全新的渲染管線:

關于此技術的更多詳情可閱讀:NVIDIA Turing Architecture Whitepaper。
可變速率著色(Variable Rate Shading)。可變利率著色技術可判斷畫面區域的重要性(或由應用程序指定),然后根據畫面區域的重要性程度采用不同的著色分辨率精度,可以顯著降低功耗,提高著色效率。

5.4 結語
本文系統地講解了GPU的歷史、發展、工作流程,以及部分過程的細化說明和用到的各種技術,我們從中可以看到GPU架構的動機、機制、瓶頸,以及未來的發展。 希望看完本文,大家能很好地回答導言提出的問題:1.3 帶著問題閱讀。如果不能全部回答,也沒關系,回頭看相關章節,總能找到答案。
如果想更深入地了解GPU的設計細節、實現細節,可閱讀GPU廠商定期發布的白皮書和各大高校、機構發布的論文。推薦一個GPU解說視頻:A trip through the Graphics Pipeline 2011: Index,雖然是多年前的視頻,但比較系統、全面地講解了GPU的機制和技術。
作者:0向往0
博客地址:
https://www.cnblogs.com/timlly/p/11471507.html
參考文獻
Real-Time Rendering Resources
Life of a triangle - NVIDIA\'s logical pipeline
NVIDIA Pascal Architecture Whitepaper
NVIDIA Turing Architecture Whitepaper
Pomegranate: A Fully Scalable Graphics Architecture
Performance Optimization Guidelines and the GPU Architecture behind them
A trip through the Graphics Pipeline 2011
Graphic Architecture introduction and analysis
Exploring the GPU Architecture
Introduction to GPU Architecture
An Introduction to Modern GPU Architecture
GPU TECHNOLOGY: PAST, PRESENT, FUTURE
GPU Computing & Architectures
NVIDIA VOLTA
NVIDIA TURING
Graphics processing unit
GPU并行架構及渲染優化
渲染優化-從GPU的結構談起
GPU Architecture and Models
Introduction to and History of GPU Algorithms
GPU Architecture Overview
計算機那些事(8)——圖形圖像渲染原理
GPU Programming Guide GeForce 8 and 9 Series
GPU的工作原理
NVIDIA顯示核心列表
DirectX
高級著色器語言
探究光線追蹤技術及UE4的實現
移動游戲性能優化通用技法
NV shader thread group
實時渲染深入探究
NVIDIA GPU 硬件介紹
Data Transfer Matters for GPU Computing
Slang – A Shader Compilation System
Graphics Shaders - Theory and Practice 2nd Edition
審核編輯 :李倩
-
寄存器
+關注
關注
31文章
5608瀏覽量
129968 -
gpu
+關注
關注
28文章
5194瀏覽量
135434 -
硬件架構
+關注
關注
0文章
30瀏覽量
9307
原文標題:GPU硬件架構及運行機制(下)
文章出處:【微信號:IC學習,微信公眾號:IC學習】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
audio核心庫的運行機制與技術要點

操作系統運行機制
FPGA+GPU異構混合部署方案設計
在Python中借助NVIDIA CUDA Tile簡化GPU編程

如何看懂GPU架構?一分鐘帶你了解GPU參數指標

一文了解Arm神經超級采樣 (Arm Neural Super Sampling, Arm NSS) 深入探索架構、訓練和推理
同一水平的 RISC-V 架構的 MCU,和 ARM 架構的 MCU 相比,運行速度如何?

異構計算解決方案(兼容不同硬件架構)
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
Docker運行GPUStack的詳細教程
GPU架構深度解析



 工商網監
工商網監
評論