 存內計算對“存”的選擇
存內計算對“存”的選擇

電子發燒友網報道(文/周凱揚)無論是前段時間爆火的繪圖模型Stable Diffusion,還是大規模語言模型ChatGPT,AI無疑已經成了新時代的自動化工具,哪怕是在某些與認知相關的任務上,也能通過深度學習實現高于人類的精度。
但正因我們提過多次的算力問題,對于大型AI訓練的計算要求已經在每兩個月翻倍了,別說可持續能源供應了,就連硬件的可持續都有些陷入停滯了。其實以目前各種模型的迭代速度來看,更高的運算效率才是重中之重,畢竟這些模型并不需要每兩個月就推陳出新。
深度學習還有哪些環節可以提升效率
我們先從深度學習運算來看哪些算數運算占比最高,根據IBM給出的統計數據,無論是語音識別的RNN、語言模型DNN和視覺模型CNN,矩陣向量乘法都占據了運算總數的70%到90%,所以打造一個矩陣矢量乘法加速器,是多數AI加速器的思路。
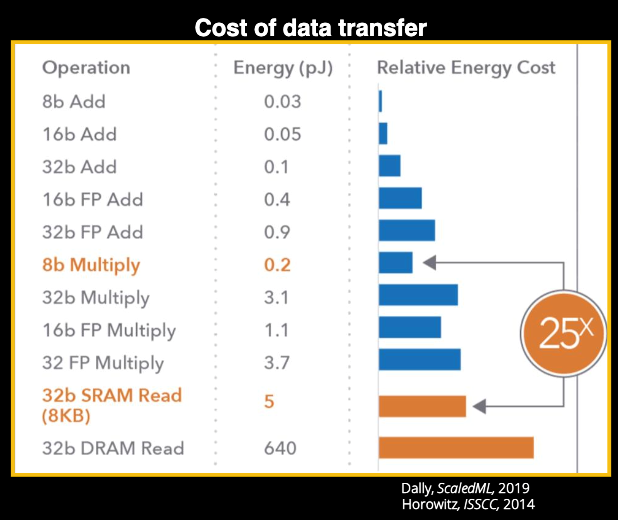
數據傳輸和運算的功耗對比 / ISSCC
要考慮效率,我們就不能不談到功耗的問題,如果只顧算力而不考慮功耗,任由龐大規模的GPU等硬件消耗能量不顧碳排放的話,也不符合全球當下的節能減排趨勢。而在深度學習中,各種精度的加法乘法都會消耗能量,但這些運算消耗的能量與傳統馮諾依曼結構中數據移動消耗的能量相比,就顯得微不足道了,尤其是從DRAM中讀寫高精度數值時,能耗差距甚至可以達到數十倍以上。
這還只是在數據中心場景中,如果我們放到邊緣來看,如今的移動設備需要語音識別、圖像識別之類的各種深度學習應用。所以提升這類設備的效率,才有可能在功耗和內存都有所限制的嵌入式應用中普及深度學習。
存內計算的存儲選擇
為了減少數據移動消耗的能量,提高MVM的計算性能,存內計算成了一個不錯的選擇。存內計算(IMC)是一項創新的計算方式,將特定的計算任務放到存儲設備中,并使用模擬或混合信號的計算技術。相較馮諾依曼結構或近存計算來說,最大程度地減少了數據移動。
而早期利用IMC進行神經網絡推理的測試結果證明,在軟硬件結合的情況下,可以得到優秀的精度結果,而DAC、ADC、功能激活之類的數字操作則是通過片外的軟件或硬件來實現的。自那之后,各種使用SRAM、NOR Flash、RRAM、PCM和MRAM的單核或多核存內計算芯片紛紛面世。
在對于正確存儲類型的選擇上,存內計算必須面臨取舍的問題,比如性能、密度、寫入時間、寫入功耗、穩定性以及制造工藝上。性能自然就是直接影響到我們說的TOPS算力以及效率,目前SRAM優勢較大,密度則決定了裸片大小,同時也影響到了成本。
而在邊緣場景下,環境一致性往往不比數據中心,所以如果不能保證穩定性的話,就會影響到存內計算進行深度學習的精度。最后的制造工藝不僅決定了這類存內計算芯片能否量產,是否存在供應鏈危機或成本問題,也決定了它有沒有繼續推進的空間,比如目前工藝較為先進的主要是PCM和SRAM,最高分別已經到了14nm和12nm。
在2021年的VLSI技術大會上,IBM發表了一篇文章,講述了他們以14nm CMOS工藝打造的一個64核PCM模擬存內計算芯片,HERMES。該芯片采用了后端集成的多層相變化內存,由256個線性化的CCO ADC組成,可以在1GHz的工作頻率之上進行精確的片上矩陣矢量乘法運算。在深度學習的運算測試中,HERMES獲得了10.5 TOPS/W的運算效率以及1.59TOPS/mm2的性能密度。
而荷蘭初創企業Axelera AI則選了數字SRAM這一路線,他們在去年12月成功流片第一代IMC芯片Thetis Core。Thetis Core的面積不到9mm2,卻可以在INT8精度下提供39.3TOPS的算力和14.1 TOPS/W的性能,甚至還可以超頻到48.16TOPS。但不少存內計算芯片提到性能表現時,往往都是指滿載的情況,正因如此,Thetis Core在低利用率下的效率表現才顯得無比亮眼。哪怕從100%利用率降低至25%的,該芯片也能展現13TOPS/W的效率,降幅只有7%左右。
小結
除了“存”以外,存內計算在“算”上的選擇也不盡相同,比如進行模擬或數字MAC運算等等。從斯坦福大學教授Boris Murmann提出的觀點來看,在低精度下模擬運算要比數字運算更高效,但一旦精度拔高,比如8位以后,模擬計算的功耗就會成倍增加了。考慮到落地應用較少,未來的存內計算會更傾向于哪種形式仍有待觀察,但從存儲廠商、存算一體芯片廠商的動向來看,這或許是存儲市場迎來又一輪爆發的絕佳機遇。
但正因我們提過多次的算力問題,對于大型AI訓練的計算要求已經在每兩個月翻倍了,別說可持續能源供應了,就連硬件的可持續都有些陷入停滯了。其實以目前各種模型的迭代速度來看,更高的運算效率才是重中之重,畢竟這些模型并不需要每兩個月就推陳出新。
深度學習還有哪些環節可以提升效率
我們先從深度學習運算來看哪些算數運算占比最高,根據IBM給出的統計數據,無論是語音識別的RNN、語言模型DNN和視覺模型CNN,矩陣向量乘法都占據了運算總數的70%到90%,所以打造一個矩陣矢量乘法加速器,是多數AI加速器的思路。
數據傳輸和運算的功耗對比 / ISSCC
要考慮效率,我們就不能不談到功耗的問題,如果只顧算力而不考慮功耗,任由龐大規模的GPU等硬件消耗能量不顧碳排放的話,也不符合全球當下的節能減排趨勢。而在深度學習中,各種精度的加法乘法都會消耗能量,但這些運算消耗的能量與傳統馮諾依曼結構中數據移動消耗的能量相比,就顯得微不足道了,尤其是從DRAM中讀寫高精度數值時,能耗差距甚至可以達到數十倍以上。
這還只是在數據中心場景中,如果我們放到邊緣來看,如今的移動設備需要語音識別、圖像識別之類的各種深度學習應用。所以提升這類設備的效率,才有可能在功耗和內存都有所限制的嵌入式應用中普及深度學習。
存內計算的存儲選擇
為了減少數據移動消耗的能量,提高MVM的計算性能,存內計算成了一個不錯的選擇。存內計算(IMC)是一項創新的計算方式,將特定的計算任務放到存儲設備中,并使用模擬或混合信號的計算技術。相較馮諾依曼結構或近存計算來說,最大程度地減少了數據移動。
而早期利用IMC進行神經網絡推理的測試結果證明,在軟硬件結合的情況下,可以得到優秀的精度結果,而DAC、ADC、功能激活之類的數字操作則是通過片外的軟件或硬件來實現的。自那之后,各種使用SRAM、NOR Flash、RRAM、PCM和MRAM的單核或多核存內計算芯片紛紛面世。
在對于正確存儲類型的選擇上,存內計算必須面臨取舍的問題,比如性能、密度、寫入時間、寫入功耗、穩定性以及制造工藝上。性能自然就是直接影響到我們說的TOPS算力以及效率,目前SRAM優勢較大,密度則決定了裸片大小,同時也影響到了成本。
而在邊緣場景下,環境一致性往往不比數據中心,所以如果不能保證穩定性的話,就會影響到存內計算進行深度學習的精度。最后的制造工藝不僅決定了這類存內計算芯片能否量產,是否存在供應鏈危機或成本問題,也決定了它有沒有繼續推進的空間,比如目前工藝較為先進的主要是PCM和SRAM,最高分別已經到了14nm和12nm。
在2021年的VLSI技術大會上,IBM發表了一篇文章,講述了他們以14nm CMOS工藝打造的一個64核PCM模擬存內計算芯片,HERMES。該芯片采用了后端集成的多層相變化內存,由256個線性化的CCO ADC組成,可以在1GHz的工作頻率之上進行精確的片上矩陣矢量乘法運算。在深度學習的運算測試中,HERMES獲得了10.5 TOPS/W的運算效率以及1.59TOPS/mm2的性能密度。

而荷蘭初創企業Axelera AI則選了數字SRAM這一路線,他們在去年12月成功流片第一代IMC芯片Thetis Core。Thetis Core的面積不到9mm2,卻可以在INT8精度下提供39.3TOPS的算力和14.1 TOPS/W的性能,甚至還可以超頻到48.16TOPS。但不少存內計算芯片提到性能表現時,往往都是指滿載的情況,正因如此,Thetis Core在低利用率下的效率表現才顯得無比亮眼。哪怕從100%利用率降低至25%的,該芯片也能展現13TOPS/W的效率,降幅只有7%左右。
小結
除了“存”以外,存內計算在“算”上的選擇也不盡相同,比如進行模擬或數字MAC運算等等。從斯坦福大學教授Boris Murmann提出的觀點來看,在低精度下模擬運算要比數字運算更高效,但一旦精度拔高,比如8位以后,模擬計算的功耗就會成倍增加了。考慮到落地應用較少,未來的存內計算會更傾向于哪種形式仍有待觀察,但從存儲廠商、存算一體芯片廠商的動向來看,這或許是存儲市場迎來又一輪爆發的絕佳機遇。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
存內計算
+關注
關注
0文章
35瀏覽量
1661
發布評論請先 登錄
相關推薦
熱點推薦
ISSCC 2026重磅:清華+華為+字節聯合發布存內計算芯片,重塑推薦系統能效邊界
Recommendation System Acceleration》(HYDAR:面向高效推薦系統加速的混合存內計算框架),首次提出基于 28nm 工藝的混合存

存內計算芯片,熱度大增
。自動駕駛汽車需要實時響應,避免數據傳輸延遲。醫療和工業應用通常依賴于無法與第三方共享的敏感數據。盡管邊緣人工智能應用速度更快、更安全,但它們的計算

知存科技榮獲2025半導體市場創新表現獎
8月26日,第22屆深圳國際電子展(elexcon2025)現場正式揭曉聚焦行業技術突破與價值創造的“2025半導體市場創新表現獎” ,知存科技憑借WTM系列存算一體芯片的核心技術創新,成功斬獲
芯動科技與知存科技達成深度合作
隨著3D堆疊方案憑借低功耗、高帶寬特性,有望成為下一代移動端高端熱門技術。芯動科技瞄準3DIC市場,與全球領先的存算一體芯片企業知存科技達成深度合作,正式量產面向Face2Face鍵合(F2F)系列高速接口IP解決方案。
一文看懂“存算一體”
今天這篇文章,我們來聊一個最近幾年很火的概念——存算一體。為什么會提出“存算一體”?存算一體,英文叫ComputeInMemory,簡稱CIM。顧名思義,就是將存儲和計算放在一起。大家
Texas Instruments TMAG5213霍爾效應鎖存器數據手冊
Texas Instruments TMAG5213霍爾效應鎖存器是斬波穩定霍爾效應傳感器,在整個溫度范圍內具有出色的靈敏度穩定性。這些鎖存器具有30kHz磁采樣頻率、35μs上電時間以及多種靈敏度
知存科技邀您相約第二十一屆全國容錯計算學術會議
7月18日至20日,由中國計算機學會主辦的第二十一屆全國容錯計算學術會議(CCF CFTC 2025)將在杭州舉行。作為國內容錯計算領域一年一度的盛會,此次會議匯聚了來自學術界和產業界的眾多精英,知
緩解高性能存算一體芯片IR-drop問題的軟硬件協同設計
在高性能計算與AI芯片領域,基于SRAM的存算一體(Processing-In-Memory, PIM)架構因兼具計算密度、能效和精度優勢成為主流方案。隨著存算一體芯片性能的持續攀升,
“算存平衡”有多重要?
。而決定這種配合效率的關鍵指標,正是我們今天要聊的“算存比”。什么是算存比?算存比=計算能力(如每秒浮點運算次數)÷存儲容量(如GB/TB),但更核心的是
一文讀懂Allegro先進磁性開關和鎖存器
Allegro 擁有豐富的霍爾效應和隧道磁阻(TMR)開關及鎖存器產品,可廣泛應用于汽車、工業和消費電子等領域。本應用筆記旨在提供分步選型流程,協助設計師為具體應用場景選擇適配的 Allegro
得一微定義“AI存力芯片”,讓每比特數據創造更多智能
在AI技術重塑全球產業格局的進程中,計算范式正經歷從運算器為中心到存儲器為中心的范式躍遷。這一變革重新定義了“先進存力”的邊界。 得一微電子首次創造性地提出“AI存力芯片”的技術概念。未來 AI
第二屆知存科技杯華東高校存內計算創新應用大賽正式啟動
在數字化浪潮席卷各行業的當下,數據量呈爆炸式增長,算力需求也水漲船高。存內計算架構作為創新解決方案,備受產學研各界關注。為推動存內
知存科技入選杭州AI“18羅漢”企業
,聚焦人工智能領域的新生代,代表人工智能產業的未來,從而全面展現杭州AI生態。知存科技憑借其在存內計算芯片領域的卓越表現入選杭州 AI“18 羅漢”,彰顯在人工智能基礎層的強勁實力與領
知存科技產學研融合戰略再啟新篇
知存科技產學研融合戰略再啟新篇。近日,清華大學-知存科技“多模態智能感存算融合系統”產學研深度融合專項啟動會暨指導委員會第一次會議在清華大學順利召開。
得一微:AI存力芯片,重構計算范式
。 ? 在近日舉行的MemoryS 2025上,得一微電子(YEESTOR)展示了其“IP設計-芯片設計-算法驅動-存力創新”的全鏈條技術實力。公司首席市場官羅挺接受電子發燒友采訪時表示,得一微在業界首次提出“AI存力芯片”的概念,通過積極布局產品,創造性地采用“AI




 工商網監
工商網監
評論