 總結過去三年,MIT發布AI加速器綜述論文
總結過去三年,MIT發布AI加速器綜述論文

過去幾年,關于人工智能和機器學習加速器的發展進行到哪一階段了?來自 MIT 的研究者通過一篇綜述性文章總結了過去三年關于 AI 加速器和處理器的調查。
過去這一年,無論是初創公司還是成熟大廠,預告、發布和部署人工智能(AI)和機器學習(ML)加速器的步伐很緩慢。但這并非不合理,對于許多發布加速器報告的公司來說,他們花三到四年的時間研究、分析、設計、驗證和對加速器設計的權衡,并構建對加速器進行編程的技術堆棧。對于那些已發布升級版本加速器的公司來說,雖然他們報告的開發周期更短,但至少還是要兩三年。這些加速器的重點仍然是加速深層神經網絡(DNN)模型,應用場景從極低功耗嵌入式語音識別和圖像分類到數據中心大模型訓練,典型的市場和應用領域的競爭仍在繼續,這是工業公司和技術公司從現代傳統計算向機器學習解決方案轉變的重要部分。
人工智能生態系統將邊緣計算、傳統高性能計算(HPC)和高性能數據分析(HPDA)的組件結合在一起,這些組件必須協同工作,才能有效地給決策者、一線人員和分析師賦能。圖 1 展示了這種端到端 AI 解決方案及其組件的架構概覽。
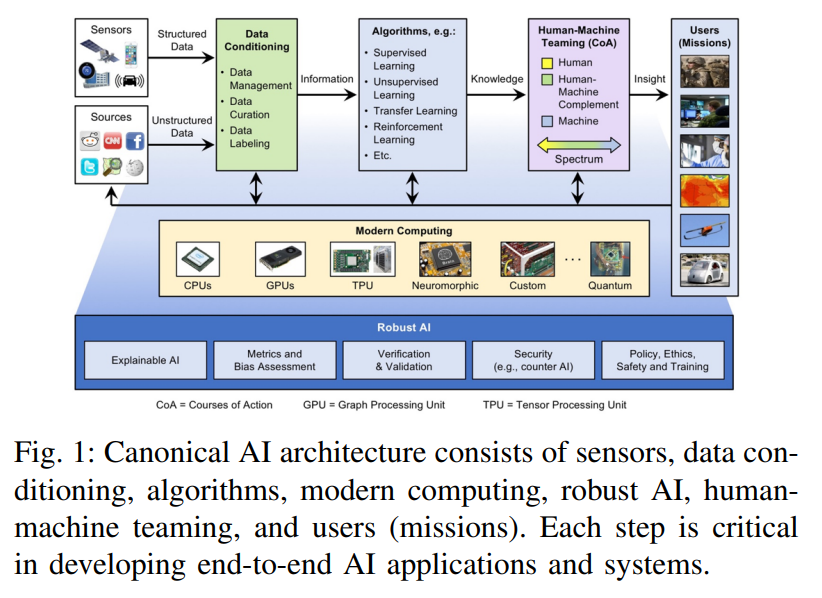
原始數據首先需要進行數據規整,在該步驟中數據被融合、聚合、結構化、累積并轉換為信息。數據規整步驟生成的信息作為神經網絡等有監督或無監督算法的輸入,這些算法可提取模式、填充缺失數據或查找數據集之間的相似性、進行預測,從而將輸入信息轉換為可操作的知識。這些可操作的知識將會傳遞給人類,用于人機協作階段的決策過程。人機協作階段為用戶提供有用且重要的洞察,將知識轉化為可操作的智能或洞察力。
支撐這個系統的是現代計算系統。摩爾定律的趨勢已經結束,但同時還有許多相關的定律和趨勢被提出來,如 Denard 定律(功率密度)、時鐘頻率、核心數、每時鐘周期的指令和每焦耳的指令(Koomey 定律)。從最早出現在汽車應用、機器人和智能手機中的片上系統(SoC)趨勢來看,通過開發和集成常用內核、方法或功能的加速器,其創新仍在不斷進步。這些加速器在性能和功能靈活性之間存在不同的平衡,包括深度學習處理器和加速器的創新爆發。通過閱讀大量相關論文,本文探討了這些技術的相對優勢,因為它們對于將人工智能應用于對大小、重量和功率等有極大要求的嵌入式系統和數據中心時特別重要。
本文是對 IEEE-HPEC 過去三年論文的一次更新。與過去幾年一樣,本文繼續關注深度神經網絡(DNN)和卷積神經網絡(CNN)的加速器和處理器,它們的計算量極大。本文主要針對加速器和處理器在推理方面的發展,因為很多 AI/ML 邊緣應用極度依賴推理。本文針對加速器支持的所有數字精度類型,但對于大多數加速器來說,它們的最佳推理性能是 int8 或 fp16/bf16(IEEE 16 位浮點或 Google 的 16 位 brain float)。

論文鏈接:https://arxiv.org/pdf/2210.04055.pdf
目前,已經有很多探討 AI 加速器的論文。如本系列調查的第一篇論文就有探討某些 AI 模型的 FPGA 的峰值性能,之前的調查都深入覆蓋了 FPGA,因此不再包含在本次調查中。這項持續調查工作和文章旨在收集一份全面的 AI 加速器列表,包括它們的計算能力、能效以及在嵌入式和數據中心應用中使用加速器的計算效率。與此同時文章主要比較了用于政府和工業傳感器和數據處理應用的神經網絡加速器。前幾年論文中包含的一些加速器和處理器已被排除在今年的調查之外,之所以放棄它們,是因為它們可能已經被同一家公司的新加速器替代、不再維護或者與主題不再相關。
處理器調查
人工智能的許多最新進展部分原因要歸功于硬件性能的提升,這使得需要巨大算力的機器學習算法,尤其是 DNN 等網絡能夠實現。本文的這次調查從公開可用的材料中收集各類信息,包括各種研究論文、技術期刊、公司發布的基準等。雖然還有其他方法獲取公司和初創公司(包括那些處于沉默期的公司)的信息,但本文在本次調查時忽略了這些信息,這些數據將在公開后納入該調查。該公共數據的關鍵指標如下圖所示,其反映了最新的處理器峰值性能與功耗的關系能力(截至 2022 年 7 月)。
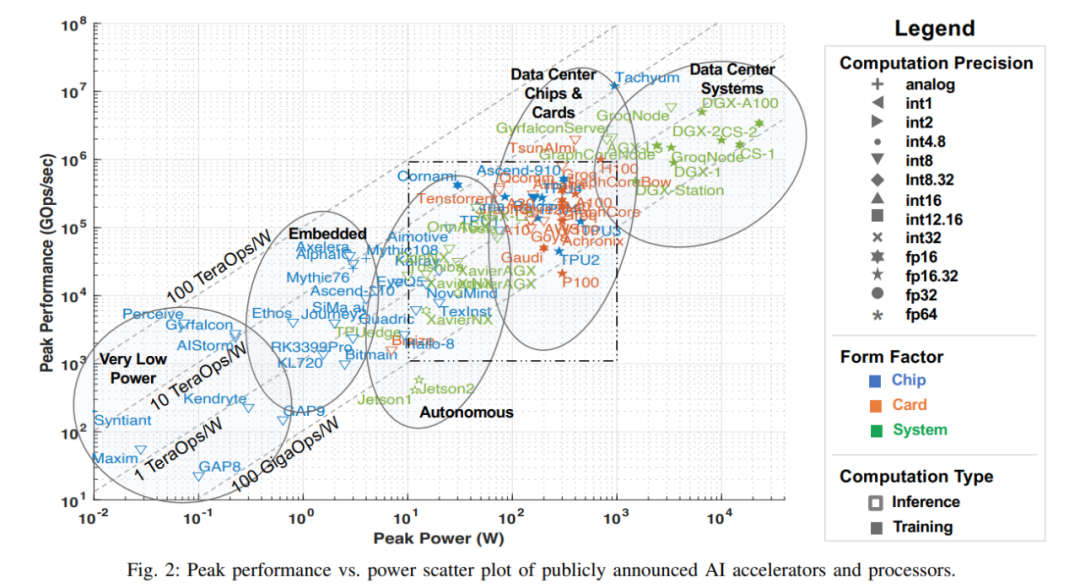
注意:圖 2 中虛線方框與下圖 3 是對應的,圖 3 是把虛線框放大后的圖。
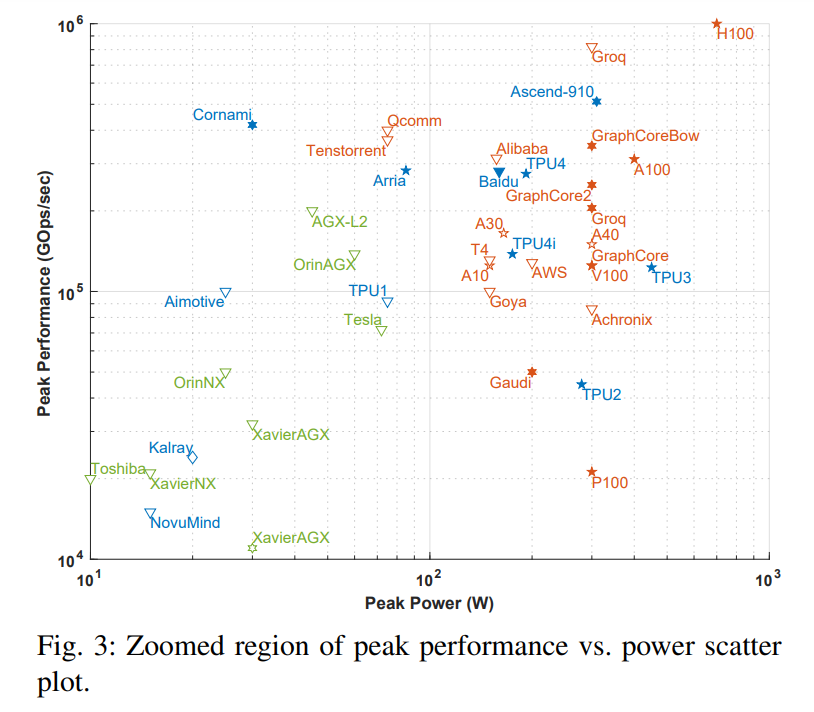
圖中 x 軸表示峰值功率,y 軸表示每秒峰值千兆操作數(GOps/s),均為對數尺度。處理能力的計算精度用不同幾何形狀表示,計算精度范圍從 int1 到 int32、從 fp16 到 fp64。顯示的精度有兩種類型,左邊代表乘法運算的精度,右邊代表累加 / 加運算的精度(如 fp16.32 表示 fp16 乘法和 fp32 累加 / 加)。使用顏色和形狀區分不同類型系統和峰值功率。藍色表示單芯片;橙色表示卡;綠色表示整體系統(單節點桌面和服務器系統)。此次調查僅限于單主板、單內存系統。圖中空心幾何圖形是僅進行推理加速器的最高性能,而實心幾何圖形代表執行訓練和推理的加速器的性能。
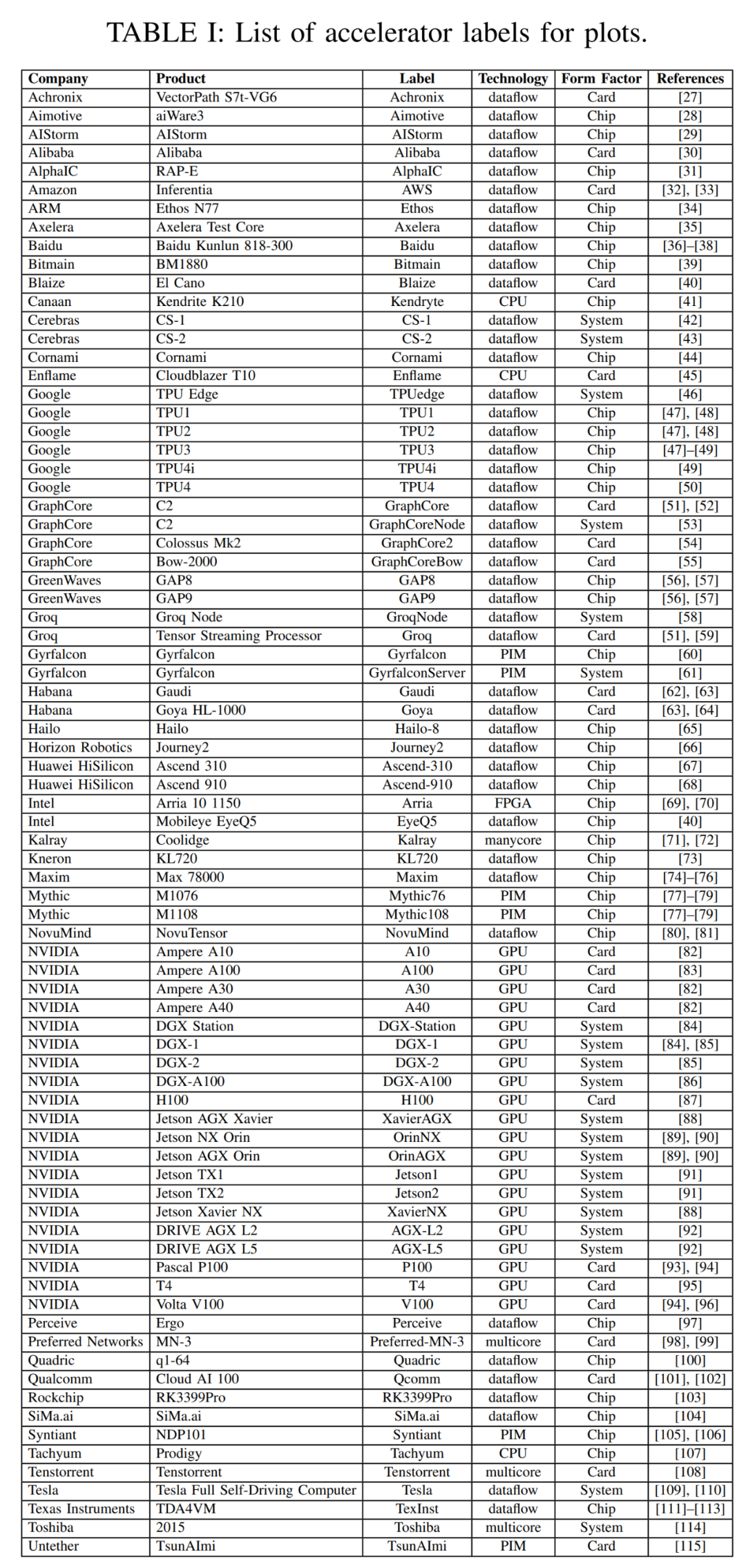
本次調查中本文以過去三年調查數據的散點圖開篇。下表 1 中本文總結了加速器、卡和整體系統的一些重要元數據,包括圖 2 中每個點的標簽,許多要點都是從去年的調查中提出來的。表 1 中大多數列和條目都是準確清楚的。但有兩個技術條目可能不是:Dataflow 和 PIM。Dataflow 型處理器是為神經網絡推理和訓練定制的處理器。由于神經網絡訓練和推理計算完全確定地構建,因此它們適合 dataflow 處理,其中計算、內存訪問和 ALU 間通信被顯式 / 靜態編程或者布局布線到計算硬件。內存處理器(PIM)加速器將處理元素與內存技術集成在一起。在這些 PIM 加速器中,有一些基于模擬計算技術的加速器,該技術使用就地模擬乘法加法功能增強閃存電路。可以參考 Mythic 和 Gyrfalcon 加速器的相關資料,了解關于此創新技術的更多詳細信息。
本文根據加速器的預期應用對其進行合理分類,圖 1 用橢圓標識了五類加速器,根據性能和功耗做對應:功耗非常低,傳感器非常小的語音處理;嵌入式攝像機、小型無人機和機器人;駕駛輔助系統、自動駕駛和自動機器人;數據中心的芯片和卡;數據中心系統。
大多數加速器的性能、功能等指標都沒有改變,可以參閱過去兩年的論文以了解相關信息。下面的是沒有被過去的文章所收錄的加速器。
荷蘭嵌入式系統初創公司 Acelera 聲稱他們生產的嵌入式測試芯片具有數字和模擬設計能力,而這種測試芯片是為了測試數字設計能力的范圍。他們希望在未來的工作中增加模擬(也可能是閃存)設計要素。
Maxim Integrated 發布了一款名為 MAX78000 用于超低功耗應用的系統芯片(SoC)。其包括 ARM CPU 內核、RISC-V CPU 內核和 AI 加速器。ARM 核心用于快速原型設計和代碼重用,而 RISC-V 核心用于實現優化,以實現最低的功耗。AI 加速器有 64 個并行處理器,支持 1 位、2 位、4 位和 8 位整數運算。SoC 的最大工作功率為 30mW,適用于低延遲、電池供電的應用。
Tachyum 最近發布名為 Prodigy 一體式處理器,Prodigy 每個核心都集成 CPU 和 GPU 的功能,它是為 HPC 和機器學習應用程序設計的,該芯片有 128 個高性能統一內核,運行頻率為 5.7GHz。
NVIDIA 于 2022 年 3 月發布了名為 Hopper(H100)的下一代 GPU。Hopper 集成更多的 Symmetric Multiprocessor(SIMD 和 Tensor 核),50% 的內存帶寬,SXM 夾層卡實例的功率為 700W。(PCIe 卡功率為 450W)
過去幾年 NVIDIA 發布了一系列系統平臺,用于部署在汽車、機器人和其他嵌入式應用程序 Ampere 架構的 GPU。對于汽車應用,DRIVE AGX 平臺增加了兩個新系統:DRIVE AGX L2 可在 45W 功率范圍內實現 2 級自動駕駛,DRIVE AGX L5 可在 800W 功率范圍內能實現 5 級自動駕駛。Jetson AGX Orin 和 Jetson NX Orin 也使用 Ampere 架構 GPU,用于機器人、工廠自動化等,它們最大峰值功率為 60W 和 25W。
Graphcore 發布其第二代加速器芯片 CG200,它部署在 PCIe 卡上,峰值功率約為 300W。去年,Graphcore 還推出 Bow 加速器,這是與臺積電合作設計的首款晶圓對晶圓處理器。加速器本身與上面提到的 CG200 相同,但它與第二塊晶片配合使用,從而大大改善了整個 CG200 芯片的功率和時鐘分布。這意味著性能提高了 40% 以及 16% 每瓦特的性能提升。
2021 年 6 月,谷歌宣布了其第四代純推理 TPU4i 加速器的詳細信息。將近一年后,谷歌分享了其第 4 代訓練加速器 TPUv4 的詳細信息。雖然官宣的細節很少,但他們分享了峰值功率和相關性能數值。與以前的 TPU 各種版本一樣,TPU4 可通過 Google Compute Cloud 獲得并用于內部操作。
接下來是對沒有出現在圖 2 中的加速器的介紹,其中每個版本都發布一些基準測試結果,但有的缺少峰值性能,有的沒有公布峰值功率,具體如下。
SambaNova 去年發布了一些可重構 AI 加速器技術的基準測試結果,今年也發布了多項相關技術并與阿貢國家實驗室合作發表了應用論文,不過 SambaNova 沒有提供任何細節,只能從公開的資料估算其解決方案的峰值性能或功耗。
今年 5 月,英特爾 Habana 實驗室宣布推出第二代 Goya 推理加速器和 Gaudi 訓練加速器,分別命名為 Greco 和 Gaudi2。兩者性能都比之前版本表現好幾倍。Greco 是 75w 的單寬 PCIe 卡,而 Gaudi2 還是 650w 的雙寬 PCIe 卡(可能在 PCIe 5.0 插槽上)。Habana 發布了 Gaudi2 與 Nvidia A100 GPU 的一些基準比較,但沒有披露這兩款加速器的峰值性能數據。
Esperanto 已經生產了一些 Demo 芯片,供三星和其他合作伙伴評估。該芯片是一個 1000 核 RISC-V 處理器,每個核都有一個 AI 張量加速器。Esperanto 已經發布了部分性能指標,但它們沒有披露峰值功率或峰值性能。
在特斯拉 AI Day 中,特斯拉介紹了他們定制的 Dojo 加速器以及系統的一些細節。他們的芯片具有 22.6 TF FP32 性能的峰值,但沒有公布每個芯片的峰值功耗,也許這些細節會在以后公布。
去年 Centaur Technology 推出一款帶有集成 AI 加速器的 x86 CPU,其擁有 4096 字節寬的 SIMD 單元,性能很有競爭力。但 Centaur 的母公司 VIA Technologies 將位于美國的處理器工程團隊賣給了 Intel,似乎已經結束了 CNS 處理器的開發。
一些觀察以及趨勢
圖 2 中有幾個觀察值得一提,具體內容如下。
Int8 仍然是嵌入式、自主和數據中心推理應用程序的默認數字精度。這種精度對于使用有理數的大多數 AI/ML 應用程序來說是足夠的。同時一些加速器使用 fp16 或 bf16。模型訓練使用整數表示。
在極低功耗的芯片中,除了用于機器學習的加速器之外,還沒發現其他額外功能。在極低功耗芯片和嵌入式類別中,發布片上系統(SoC)解決方案是很常見的,通常包括低功耗 CPU 內核、音頻和視頻模數轉換器(ADC)、加密引擎、網絡接口等。SoC 的這些附加功能不會改變峰值性能指標,但它們確實會對芯片報告的峰值功率產生直接影響,所以在比較它們時這一點很重要。
嵌入式部分的變化不大,就是說計算性能和峰值功率足以滿足該領域的應用需求。
過去幾年,包括德州儀器在內的幾家公司已經發布了 AI 加速器。而 NVIDIA 也發布了一些性能更好的汽車和機器人應用系統,如前所述。在數據中心中,為了突破 PCIe v4 300W 的功率限制,PCIe v5 規格備受期待。
最后,高端訓練系統不僅發布了令人印象深刻的性能數據,而且這些公司還發布了高度可擴展的互聯技術,將數千張卡連接在一起。這對于像 Cerebras、GraphCore、Groq、Tesla Dojo 和 SambaNova 這樣的數據流加速器尤其重要,這些加速器通過顯式 / 靜態編程或布局布線到計算硬件上的。這樣一來它使這些加速器能夠適應像 transformer 這種超大模型。
審核編輯 :李倩
-
加速器
+關注
關注
2文章
839瀏覽量
40097 -
MIT
+關注
關注
3文章
254瀏覽量
24996 -
機器學習
+關注
關注
66文章
8553瀏覽量
136931
原文標題:總結過去三年,MIT發布AI加速器綜述論文
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
安路科技2025年度總結
使用NORDIC AI的好處
奇異摩爾參編人工智能加速器互聯芯粒技術要求團體標準發布
邊緣計算中的AI加速器類型與應用

亞馬遜云科技第三期創業加速器圓滿收官 助力初創釋放Agentic AI潛力 加速全球化進程
創客總部加入MathWorks加速器計劃
Andes晶心科技推出新一代深度學習加速器
【免費送書】AI芯片,從過去走向未來:《AI芯片:前沿技術與創新未來》

【書籍評測活動NO.64】AI芯片,從過去走向未來:《AI芯片:科技探索與AGI愿景》
粒子加速器?——?科技前沿的核心裝置

直擊Computex2025:英特爾重磅發布新一代GPU,圖形和AI性能躍升3.4倍

英特爾發布全新GPU,AI和工作站迎來新選擇
第三期 “亞馬遜云科技創業加速器” 正式啟動
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
嵌入式AI加速器DRP-AI 詳細介紹



 工商網監
工商網監
評論