") AI、游戲與通用計算,國產(chǎn)GPU的定位
AI、游戲與通用計算,國產(chǎn)GPU的定位

摩爾線程

芯動科技
壁仞科技



原文標(biāo)題:AI、游戲與通用計算,國產(chǎn)GPU的定位
文章出處:【微信公眾號:電子發(fā)燒友網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
電子發(fā)燒友網(wǎng)
+關(guān)注
關(guān)注
1013文章
544瀏覽量
167354
原文標(biāo)題:AI、游戲與通用計算,國產(chǎn)GPU的定位
文章出處:【微信號:elecfans,微信公眾號:電子發(fā)燒友網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
OrangePi RV2 深度技術(shù)評測:RISC-V AI融合架構(gòu)的先行者
x265 視頻編碼 :僅1.2 fps,遠低于主流 ARM 平臺
整體結(jié)論 :通用計算性能相當(dāng)于5 年前入門級 ARM 處理器 (如Cortex-A53),無法勝任重度計算任務(wù)。
2.2 AI 算力
發(fā)表于 03-03 20:19
又一國產(chǎn)GPU企業(yè)上市
GPU企業(yè)、國內(nèi)首家實現(xiàn)“訓(xùn)練+推理”通用GPU雙量產(chǎn)的企業(yè),天數(shù)智芯的上市標(biāo)志著國產(chǎn)高端芯片產(chǎn)業(yè)邁入資本驅(qū)動與技術(shù)突破并行的關(guān)鍵階段。 ? 從技術(shù)深耕到資本進階 ? 天數(shù)智芯成立于2
Banana Pi 基于龍芯2K3000的國產(chǎn)信創(chuàng)工業(yè)計算網(wǎng)關(guān)設(shè)計,采用無風(fēng)扇設(shè)計
2K3000的國產(chǎn)信創(chuàng)工業(yè)計算網(wǎng)關(guān)[]()
設(shè)計原則
設(shè)計基于2K3000處理器的全功能COM-E(Type6)核心板,覆蓋處理器所有資源,避免因需求變化,而必須對核心板進行裁剪及重新設(shè)計的工作量,增強通用
發(fā)表于 12-17 11:06
為啥 AI 計算速度這么驚人?—— 聊聊 GPU、內(nèi)存與并行計算
提到AI,大家常說它“算得快”,其實是指AI能在眨眼間處理海量數(shù)據(jù)。可它為啥有這本事?答案就藏在“GPU+高速內(nèi)存+并行計算”這trio(組合)里。咱們可以把

Imagination中國區(qū)董事長兼亞太區(qū)總裁白農(nóng):通用計算GPU驅(qū)動端側(cè)AI發(fā)展
,通用計算GPU正成為驅(qū)動端側(cè)AI發(fā)展的重要引擎。當(dāng)前,端側(cè)AI算力迎來爆發(fā)式增長,端側(cè)芯片需承載感知數(shù)據(jù)處理、圖像渲染、AI大模型
首款全國產(chǎn)通用GPU芯片發(fā)布 沐曦集成推出曦云C600
沐曦集成電路(南京)有限公司近日正式發(fā)布了首款全國產(chǎn)通用GPU——曦云C600,這標(biāo)志著國產(chǎn)高性能GPU實現(xiàn)歷史性突破。 據(jù)新華日報報道顯示
摩爾線程副總裁王華:AI工廠全棧技術(shù)重構(gòu)算力基建,開啟國產(chǎn) GPU 黃金時代
協(xié)同,重新定義了?AI?基礎(chǔ)設(shè)施的生產(chǎn)力公式 ——AI?工廠生產(chǎn)效率?=?加速計算通用性 × 單芯片有效算力 × 單節(jié)點效率 × 集群效率 × 集群穩(wěn)定性。作為國內(nèi)率先實現(xiàn)單芯片集成?

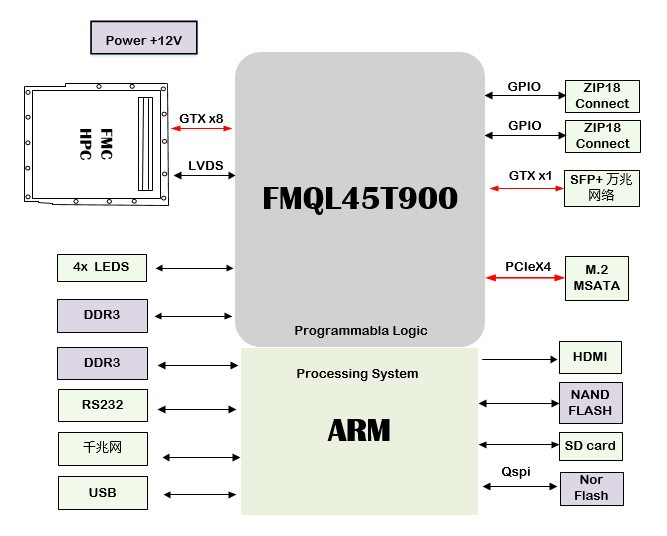
國產(chǎn)化FMC接口通用計算平臺設(shè)計原理圖:2367-基于FMQL45T900 FMC接口通用計算平臺
, 數(shù)字信號處理卡, FMC接口通用計算平臺, FMQL45T900I, 前端信號處理
GPU架構(gòu)深度解析
GPU架構(gòu)深度解析從圖形處理到通用計算的進化之路圖形處理單元(GPU),作為現(xiàn)代計算機中不可或缺的一部分,已經(jīng)從最初的圖形渲染專用處理器,發(fā)展成為強大的并行
Imagination與澎峰科技攜手推動GPU+AI解決方案,共拓計算生態(tài)
的深度融合展開合作。雙方將結(jié)合 Imagination 領(lǐng)先的 GPU IP 技術(shù)與澎峰科技在 AI 模型壓縮與性能優(yōu)化方面的軟硬協(xié)同能力,共同開拓面向 AI 行業(yè)應(yīng)用的計算解決方案
發(fā)表于 05-21 09:40
?1220次閱讀
Imagination與澎峰科技攜手推動GPU+AI解決方案,共拓計算生態(tài)
近日,ImaginationTechnologies與國內(nèi)領(lǐng)先的異構(gòu)計算軟件與智算混合云服務(wù)提供商澎峰科技(PerfXLab)正式簽署合作備忘錄(MoU),圍繞GPU與AI的深度融合展開合作。雙方將
黑芝麻A2000#高階智能駕駛與通用AI計算芯片詳細解析
、產(chǎn)品定位與核心目標(biāo) A2000家族是黑芝麻智能華山系列的最新產(chǎn)品, 定位于高階智能駕駛與通用AI計算 ,目標(biāo)是通過高算力、高能效的芯片設(shè)計

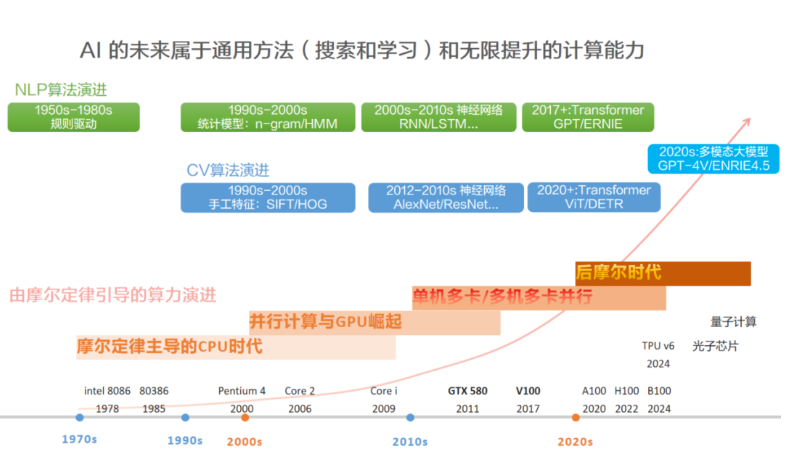
AI演進的核心哲學(xué):使用通用方法,然后Scale Up!
,得到一個AI發(fā)展的重要歷史教訓(xùn):利用計算能力的通用方法最終是最有效的,而且優(yōu)勢明顯”。核心原因是摩爾定律,即單位計算成本持續(xù)指數(shù)級下降。大多數(shù) A
沐曦曦云C500通用計算GPU與百度飛槳完成Ⅱ級兼容性測試
近日,沐曦曦云C500通用計算GPU與百度飛槳已完成Ⅱ級兼容性測試。測試結(jié)果顯示,雙方兼容性表現(xiàn)良好,整體運行穩(wěn)定。這是沐曦加入飛槳“硬件生態(tài)共創(chuàng)計劃”后的階段性成果。
摩爾線程GPU原生FP8計算助力AI訓(xùn)練
并行訓(xùn)練和推理,顯著提升了訓(xùn)練效率與穩(wěn)定性。摩爾線程是國內(nèi)率先原生支持FP8計算精度的國產(chǎn)GPU企業(yè),此次開源不僅為AI訓(xùn)練和推理提供了全新的國產(chǎn)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論