 使用多個推理芯片需要仔細規劃
使用多個推理芯片需要仔細規劃

過去兩年,推理芯片業務異常忙碌。有一段時間,似乎每隔一周就有另一家公司推出一種新的更好的解決方案。盡管所有這些創新都很棒,但問題是大多數公司不知道如何利用各種解決方案,因為他們無法判斷哪一個比另一個表現更好。由于在這個新市場中沒有一套既定的基準,他們要么必須快速掌握推理芯片的速度,要么必須相信各個供應商提供的性能數據。
大多數供應商都提供了某種類型的性能數據,通常是任何讓它們看起來不錯的基準。一些供應商談論 TOPS 和 TOPS/Watt 時沒有指定型號、批量大小或工藝/電壓/溫度條件。其他人使用了 ResNet-50 基準,這是一個比大多數人需要的簡單得多的模型,因此它在評估推理選項方面的價值值得懷疑。
從早期開始,我們已經走了很長一段路。公司已經慢慢發現,在衡量推理芯片的性能時真正重要的是 1) 高 MAC 利用率,2) 低功耗和 3) 你需要保持一切都很小。
我們知道如何衡量——下一步是什么?
既然我們對如何衡量一個推理芯片相對于另一個的性能有了相當好的了解,公司現在正在詢問在同一設計中同時使用多個推理芯片的優點(或缺點)是什么。簡單的答案是,使用多個推理芯片,當推理芯片設計正確時,可以實現性能的線性增長。當我們考慮使用多個推理芯片時,高速公路的類比并不遙遠。公司想要單車道高速公路還是四車道高速公路的性能?
顯然,每家公司都想要一條四向高速公路,所以現在的問題變成了“我們如何在不造成交通和瓶頸的情況下交付這條四車道的高速公路?” 答案取決于選擇正確的推理芯片。為了解釋,讓我們看一個神經網絡模型。
神經網絡被分解成層。ResNet-50 等層有 50 層,YOLOv3 有超過 100 層,每一層都接受前一層的激活。因此,在第 N 層中,它的輸出是進入第 N+1 層的激活。它等待該層進入,計算完成,輸出是進入第 n+2 層的激活。這會持續到層的長度,直到你最終得到結果。請記住,此示例的初始輸入是圖像或模型正在處理的任何數據集。
當多個芯片發揮作用時
現實情況是,如果您的芯片具有一定的性能水平,總會有客戶想要兩倍或四倍的性能。如果你分析神經網絡模型,在某些情況下是可以實現的。您只需要查看如何在兩個芯片或四個芯片之間拆分模型。
多年來,這一直是并行處理的一個問題,因為很難弄清楚如何對您正在執行的任何處理進行分區并確保它們全部相加,而不是在性能方面被減去。
與并行處理和通用計算不同,推理芯片的好處是客戶通常會提前知道他們是否要使用兩個芯片,這樣編譯器就不必在運行時弄清楚——它是在編譯時完成的。使用神經網絡模型,一切都是完全可預測的,因此我們可以分析并準確確定如何拆分模型,以及它是否能在兩個芯片上運行良好。
為了確保模型可以在兩個或更多芯片上運行,重要的是逐層查看激活大小和 MAC 數量。通常發生的情況是,最大的激活發生在最早的層中。這意味著隨著層數的增加,激活大小會慢慢下降。
查看 MAC 的數量以及每個周期中完成的 MAC 數量也很重要。在大多數模型中,每個循環中完成的 MAC 數量通常與激活大小相關。這很重要,因為如果您有兩個芯片并且想要以最大頻率運行,則需要為每個芯片分配相同的工作負載。如果一個芯片完成模型的大部分工作,而另一個芯片只完成模型的一小部分,那么您將受到第一個芯片的吞吐量的限制。
如何在兩個芯片之間拆分模型也很重要。您需要查看 MAC 的數量,因為這決定了工作負載的分布。您還必須查看芯片之間傳遞的內容。在某些時候,您需要在您傳遞的激活盡可能小的地方對模型進行切片,以便所需的通信帶寬量和傳輸延遲最小。如果在激活非常大的點對模型進行切片,激活的傳輸可能會成為限制雙芯片解決方案性能的瓶頸。
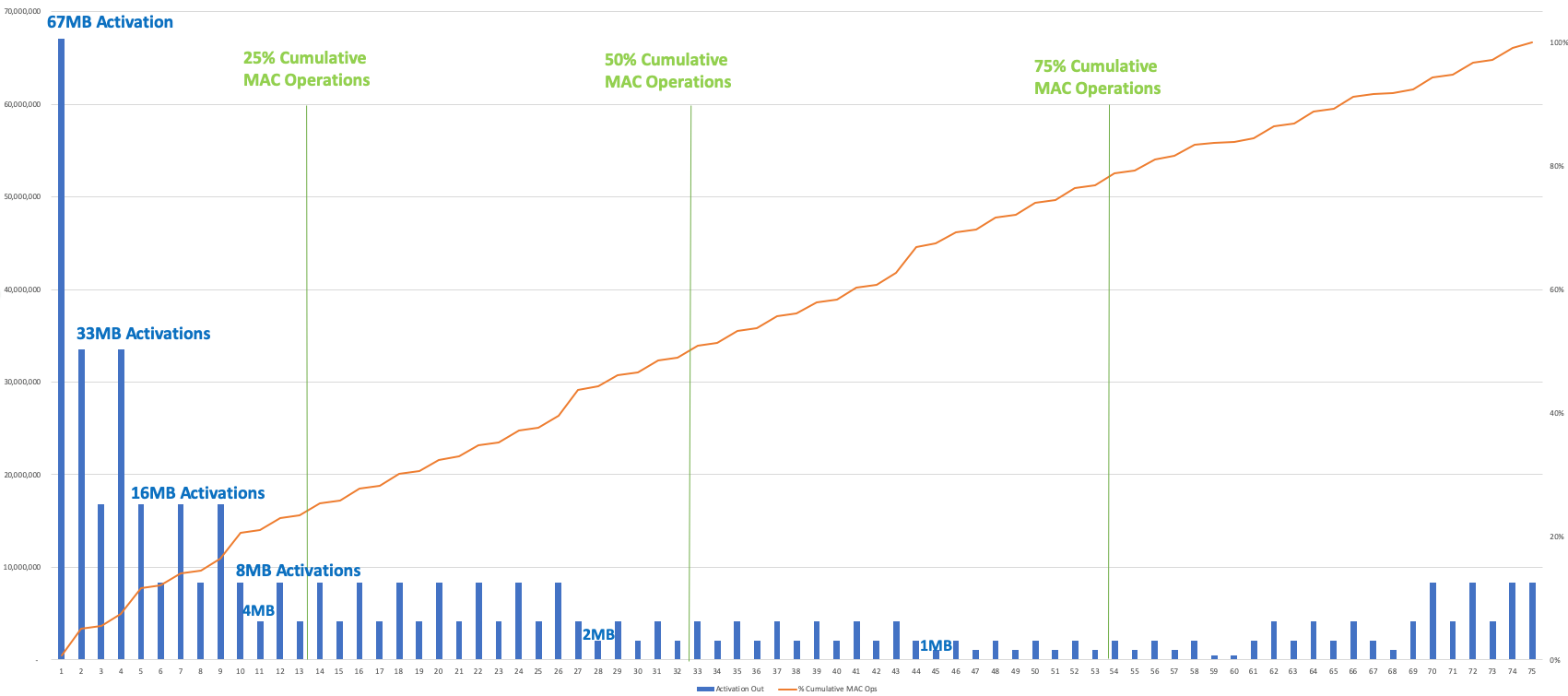
下圖顯示了 YOLOv3、Winograd、2 百萬像素圖像的激活輸出大小和累積的 Mac 操作逐層(繪制了卷積層)。為了平衡兩個芯片之間的工作負載,該模型將減少大約 50% 的累積 MAC 操作——此時從一個芯片傳遞到另一個芯片的激活為 1MB 或 2MB。要在 4 個籌碼之間進行拆分,削減率約為 25%、50% 和 75%;請注意,激活大小在開始時最大,因此 25% 的切點有 4 或 8MB 的激活要通過。
單擊此處查看大圖
YOLOv3/Winograd/2Mpixel 圖像的激活輸出大小(藍條)和逐層累積 MAC 操作(紅線),顯示工作負載如何在多個芯片之間分配(圖片:Flex Logix)
性能工具
幸運的是,現在可以使用性能工具來確保高吞吐量。事實上,模擬單個芯片性能的同一工具可以推廣到模擬兩個芯片的性能。雖然任何給定層的性能完全相同,但問題是數據傳輸如何影響性能。建模工具需要考慮這一點,因為如果所需的帶寬不夠,該帶寬將限制吞吐量。
如果您正在做四個芯片,您將需要更大的帶寬,因為模型第一季度的激活往往大于模型后期的激活。因此,您投資的通信資源量將允許您使用流水線連接的大量芯片,但這將是所有芯片都必須承擔的間接成本,即使它們是獨立芯片。
結論
使用多個推理芯片可以顯著提高性能,但前提是如上所述正確設計神經網絡。如果我們回顧一下高速公路的類比,有很多機會通過使用錯誤的芯片和錯誤的神經網絡模型來建立交通。如果你從正確的芯片開始,你就走在了正確的軌道上。請記住,最重要的是吞吐量,而不是 TOPS 或 Res-Net50 基準。然后,一旦您選擇了正確的推理芯片,您就可以設計一個同樣強大的神經網絡模型,為您的應用需求提供最大的性能。
— Geoff Tate 是 Flex Logix 的首席執行官
、審核編輯 黃昊宇
-
芯片
+關注
關注
463文章
54024瀏覽量
466354 -
Mac
+關注
關注
0文章
1128瀏覽量
55348
發布評論請先 登錄
堪稱史上最強推理芯片!英偉達發布 Rubin CPX,實現50倍ROI

把大模型“刻進”芯片,AI芯片推理速度17000 tokens/秒

AI推理芯片需求爆發,OpenAI欲尋求新合作伙伴
曦望發布新一代推理GPU芯片,單位Token推理成本降低90%
今日看點:消息稱 AMD、高通考慮導入 SOCAMM 內存;曦望發布新一代推理GPU芯片啟望S3
LLM推理模型是如何推理的?

歐洲之光!5nm,3200 TFLOPS AI推理芯片即將量產

使用NVIDIA Grove簡化Kubernetes上的復雜AI推理
AI推理芯片賽道猛將,200億市值AI芯片企業赴港IPO
大模型推理顯存和計算量估計方法研究
PTR54L15藍牙模組的引腳規劃——電源域
邏輯推理AI智能體的實際應用
谷歌新一代 TPU 芯片 Ironwood:助力大規模思考與推理的 AI 模型新引擎?
詳解 LLM 推理模型的現狀

新品 | Module LLM Kit,離線大語言模型推理模塊套裝




 工商網監
工商網監
評論