 CUDA-NDT的定義與使用實例
CUDA-NDT的定義與使用實例

隨著自主機器的發展,我們可以在生活中經常看到自主機器的應用。有傳統應用的倉庫工廠 AMR、機械臂、銀行酒店里面的服務機器人、家庭機器人、無人物流車、自主礦卡等等。不同的自主機器,軟件架構的方案也不一樣,但核心的模塊定位、導航、感知、控制等都是相通的。
定位模塊是自主機器最核心的模塊之一,定位又包括全局定位和局部定位,對于自主機器,其精度需要達到厘米級別。
本文我們將討論全局定位,即確定自主機器在全局下的位置。傳統的低速自主機器,類似于 AMR 等,其采用的定位方式通常以 SLAM(Simultaneous Localization and Mapping)的方法進行同時建圖和定位,但是該方法實現代價高、難度大,并不適用于室外自主機器——類似于無人物流車、園區接駁車等的實時高精度定位需求。這些室外自主機器行駛速度快、距離遠、環境復雜,使得 SLAM 的精度下降,同時遠距離的行駛將導致實時構建的地圖偏移過大。因此,如果在已有高精度的全局地圖的情況下進行自主機器的定位,將極大的簡化該問題。
因此,將問題分為獨立的兩部分:建圖 Mapping 和定位 Matching。NDT 是一種點云配準算法,可同時用于點云的建圖和定位。
CUDA-NDT
正態分布變換算法(NormalDistributions Transform, NDT)同 ICP 算法的功能一致,即,用于計算兩幀點云數據之間的坐標變換矩陣,從而能夠使不同的坐標下的點云數據合并到同一個坐標系統中。不同的是 NDT 算法對初值不敏感,且不需要進行對應點的特征計算,所以速度較快。NDT 算法使用應用于 3D 點統計模型的標準優化技術來確定兩個點云之間最可能的配準。
NDT 算法和 ICP 算法可以結合使用,以提高配準精度和速度。首先,NDT 算法可用于粗配準,得到轉換參數;然后使用 ICP 算法結合參數進行精細配準。為了改進 NDT 算法在 NVIDIA Jetson 上的性能,我們推薦使用基于 CUDA 加速的 CUDA-NDT。
使用CUDA-NDT
以下是 CUDA-NDT 的使用實例。我們需要初始化相關的類對象,設置相關的參數,并調用接口函數。
cudaNDT ndtTest(nPCountM, nQCountM, stream);ndtTest.setInputSource(source);ndtTest.setInputTarget(target);ndtTest.setResolution(resolution);ndtTest.setMaximumIterations(nr_iterations);ndtTest.setTransformationEpsilon(epsilon);ndtTest.setStepSize(step_size);ndtTest.ndt(cloud_source, nPCount,cloud_target, nQCount, guess,transformation_matrix,stream);
CUDA-NDT 計算的輸出是 transformation_matrix,代表的含義如下:
-
源點云 (P)* transformation_matrix = 目標坐標系的點云 (Q)
因為激光類型的輸出點云的數量為固定值,所以 CUDA-NDT 在輸出化的時候,要求輸入兩幀點云的最大數量,從而分配計算資源。
class cudaNDT{public:/*nPCountM and nQCountM are the maximum of count for input cloudsThey are used to pre-allocate memory.*/cudaNDT(int nPCountM, int nQCountM, cudaStream_t stream = 0);~cudaNDT(void);void setInputSource (void *source);void setInpuTarget (void *target);void setResolution (float resolution);void setMaximumIterations (int nr_iterations);void setTransformationEpsilon (double epsilon);void setStepSize (double step_size);/*cloud_target = transformation_matrix * cloud_sourceWhen the Epsilon of transformation_matrix is less than threshold,the function will return transformation_matrix.Input:cloud_source, cloud_target: data pointer for points cloudnPCount: the points number of cloud_sourcenQCount: the points number of cloud_targetguess: initial guess of transformation_matrixstream: CUDA streamOutput:transformation_matrix: rigid transformation matrix*/void ndt(float *cloud_source, int nPCount,float *cloud_target, int nQCount,float *guess, void *transformation_matrix,cudaStream_t stream = 0);void *m_handle = NULL;};
經過 CUDA 加速的 NDT 速度對比微加速版本提升了 4 倍左右,請參考下表的性能對比,經過 NDT 匹配的點云效果對比請參考圖 1 和圖 2。
|
|
CUDA-NDT |
PCL-NDT |
|
count of pointscloud |
7000 |
7000 |
|
cost time(ms) |
34.7789 |
136.858 |
|
fitness_score |
0.538 |
0.540 |
CUDA-NDT 與 PCL-NDT 的性能對比
開始使用CUDA-NDT
我們希望通過本文介紹使用 CUDA-NDT 從而獲得更好的點云注冊性能。
因為 NDT 在 NVIDIA Jetson 上無法使用 CUDA 進行點云的加速處理,所以我們開發了基于 CUDA 的 CUDA-NDT。
復制鏈接,獲得相關庫和實例代碼。
https://github.com/NVIDIA-AI-IOT/cuda-pcl/tree/main/cuda-ndt
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
5594瀏覽量
109778 -
NDT
+關注
關注
0文章
27瀏覽量
15252 -
CUDA
+關注
關注
0文章
127瀏覽量
14476
原文標題:基于CUDA加速的自主機器SLAM技術——CUDA-NDT
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
RV生態又一里程碑:英偉達官宣CUDA將兼容RISC-V架構!
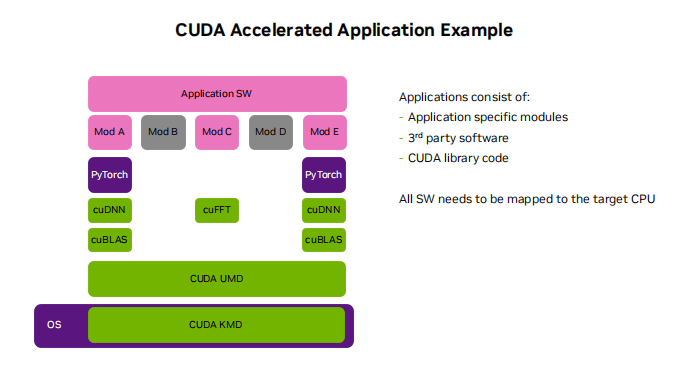
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

NVIDIA CUDA Tile的創新之處、工作原理以及使用方法

在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA CUDA 13.1版本的新增功能與改進
如何在e203 SOC中添加自定義外設
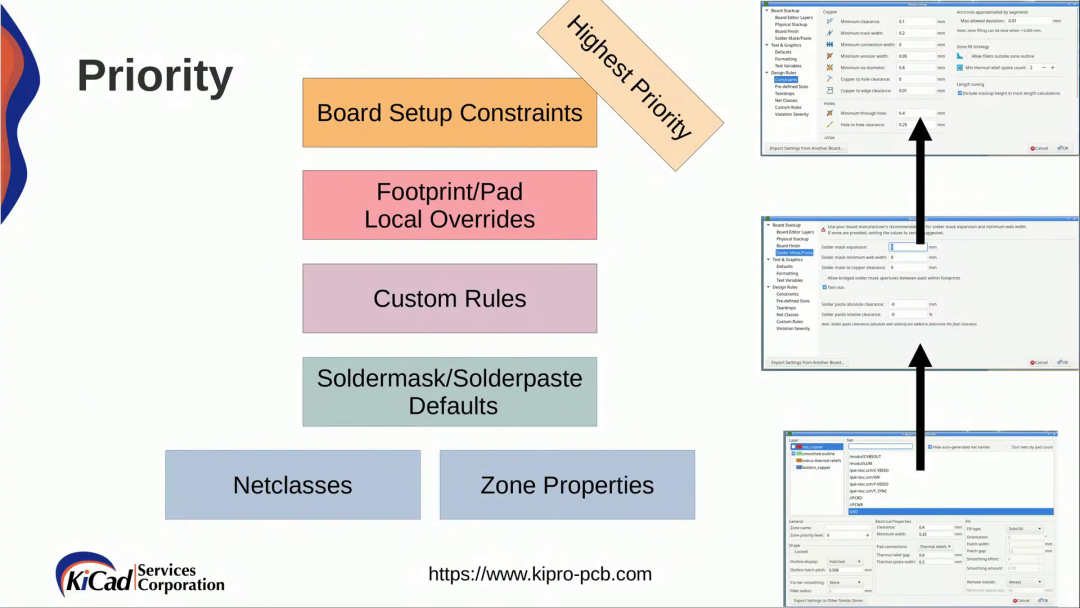
KiCad 中的自定義規則(KiCon 演講)



 工商網監
工商網監
評論