 AMD處理器和加速器全面助力人工智能 (AI) 訓練與高性能計算
AMD處理器和加速器全面助力人工智能 (AI) 訓練與高性能計算

根據世界經濟論壇2022年《全球風險報告》顯示,“氣候行動失敗”是未來5-10年內全球最主要的長期風險之一。這不僅是未來的挑戰,而且相關問題已經顯現。作為微處理器設計廠商,在技術飛速發展的今天,我們有責任保護地球,也有機會幫助大家節約能源和減少溫室氣體排放。
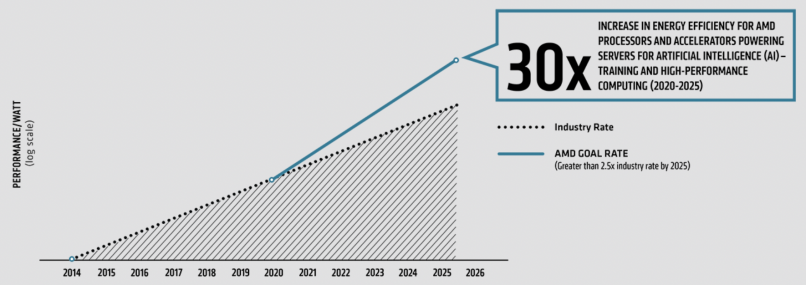
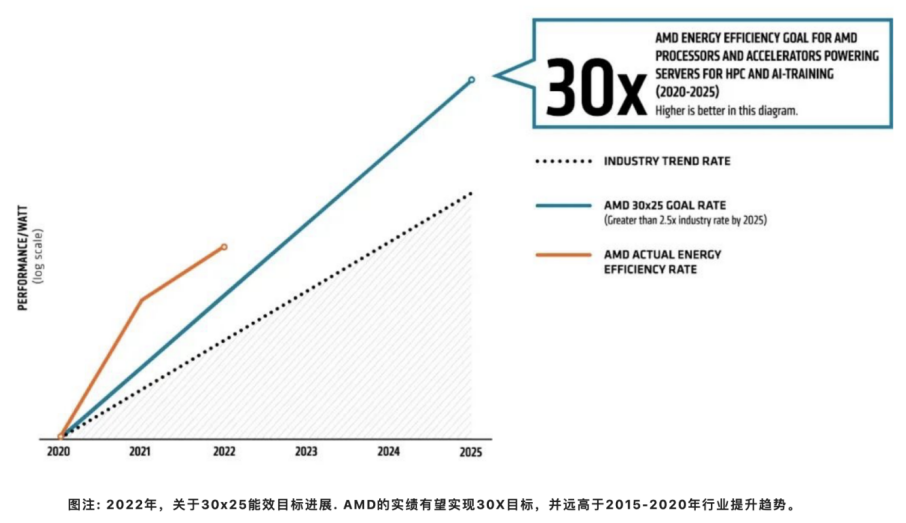
AMD面向未來繪制了更加宏偉的藍圖,在25x20能效計劃實施的基礎上,制定了一項新的能效目標——30x25目標。從2020年到2025年,將AMD 處理器和加速器的能效提高 30 倍,全面助力人工智能 (AI) 訓練與高性能計算。我們的目標相當于到 2025 年將計算的能耗減少97%。如果全球所有的人工智能和高性能計算服務器節點都能實現相似的提升,相對于行業基準趨勢,從2021年到2025 年,最多可節省510億千瓦時的電力,相當于62 億美元的節電量和 6 億棵生長 10 年的樹木的碳減排量。
AMD EPYC(霄龍)處理器和AMD Instinct 加速器
AMD EPYC(霄龍) 7003系列產品是性能出類拔萃的x86服務器處理器,其不僅能帶來出色的性能,而且能夠充分降低數據中心運營對環境的影響,進一步降低能源成本,同時推動實現公司的可持續發展目標。
經過全新設計的AMD Instinct 加速器,可以輕松應對高性能計算和人工智能工作負載,無論是單服務器解決方案,還是世界先進的超級計算機,AMD Instinct 系列加速器可為各種規模的數據中心帶來卓越性能。全新的AMD Instinct 加速器采用創新性 AMD CDNA 2 架構、AMD Infinity Fabric 技術以及先進的封裝技術,助力百億億級計算系統加速探索發現,讓科學家能夠輕松應對各種緊迫的挑戰。
基于AMD EPYC(霄龍)CPU和AMD Instinct加速器,AMD可以為AI訓練和HPC應用程序中那些世界上增長最快的計算需求而服務。這些應用程序可用于:
-氣候預測、基因組學和藥物發現等方面的科學研究
我們相信通過架構創新,可以為這些及其他加速計算節點的應用程序優化能源。
接近2022年中期,AMD正朝著實現30x25的目標前進,僅通過使用基于一顆第三代AMD EPYC CPU和四個AMD Instinct MI250x GPU的加速節點,便可以在2020年的基準水平之上提高6.79倍能效。我們的進度報告采用的測量方法2經過著名的計算能效研究專家Jonathan Koomey博士的驗證。
保護地球人人有責,AMD將持續通過提高產品能效,助力可持續發展的低碳經濟加速轉型,實現節約能源和減少溫室氣體排放的目標,對全社會產生積極的作用。
1、該情景基于全球所有人工智能和高性能計算服務器節點實現 AMD 30 倍目標的提升,相對于 2020 年的基線趨勢,從 2021 年到 2025 年,累計節省高達 514 億千瓦時的電力。假設每千瓦時 0.12 美分 x 514 億千瓦時 = 620 萬美元。CO2e 排放量(公噸)以及植樹當量的估算值來自 2021 年 12 月 1 日將節電量輸入美國 EPA 溫室氣體計算器后得出的結果。https://www.epa.gov/energy/greenhouse-gas-equivalencies-calculator
2、 AMD 在四加速器 CPU 主機配置中對用于人工智能訓練和高性能計算的高性能 AMD CPU 和 GPU 加速器進行計算節點效能功耗比測量。
- 高性能計算工作負載的性能基于具有 4k 矩陣大小的 Linpack DGEMM kernel FLOPS。人工智能訓練的性能基于在 4k 矩陣上運行的低精度訓練浮點數學 GEMM kernel,例如 FP16 或 BF16 FLOPS。
-功耗基于一個典型的加速計算節點(包括 CPU 主機 + 內存以及 4 個 GPU 加速器)的熱設計功耗 (TDP)。
為了使該目標與全球能源使用量密切相關,AMD 與 Koomey Analytics 合作評估可用的研究和數據,其中包括 GPU 高性能計算 (HPC) 和機器學習 (ML) 等特定領域數據中心能源使用效率 (PUE)。AMD CPU 和 GPU 節點功耗包含特定領域使用(活動與空閑)百分比,并乘以 PUE 來確定實際總能耗,從而能夠計算出效能功耗比。
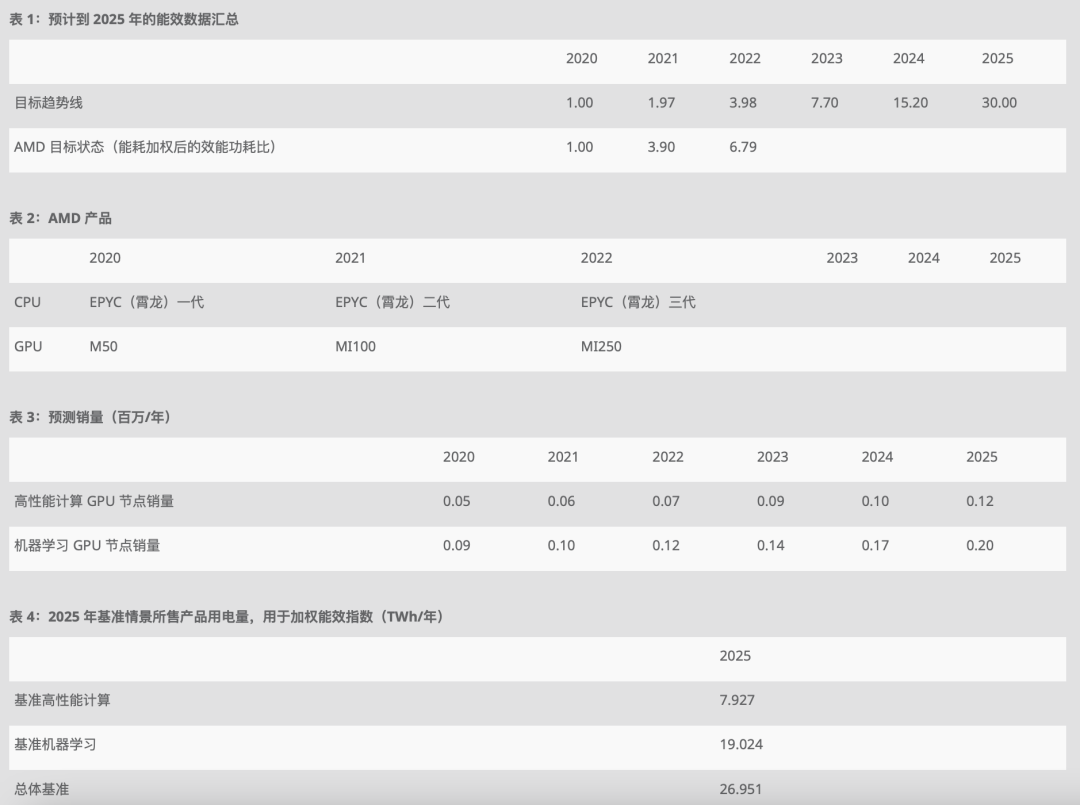
能耗基準采用 2015-2020 年數據中觀察到的行業單位作業能耗提升率,并根據這一變化率推測至 2025 年。AMD 目標趨勢線(表 1)顯示到 2025 年實現能效提升 30 倍目標所需的指數級提升。AMD 實際發布產品(表 2)是表 1 AMD 目標能效提升的來源。
2020 年到 2025 年各領域單位作業能耗提升值是由全球預計銷量加權得出(根據 IDC - Q1 2021 TrackerHyperion- Q4 2020 Tracker,Hyperion 高性能計算市場分析,2021 年 4 月)。將這些銷量換算到機器學習訓練和高性能計算市場,會得出如下表 3 所示的節點量。然后將這些節點量乘以 2025 年各計算領域的典型能源消耗 (TEC)(表 4),得出一個有意義的全球實際能源使用提升的總體指標。
原文標題:AMD EPYC(霄龍) 處理器和AMD Instinct 加速器為高能效添能助力
文章出處:【微信公眾號:AMD中國】歡迎添加關注!文章轉載請注明出處。
審核編輯:劉清
-
加速器
+關注
關注
2文章
839瀏覽量
40105 -
AMD處理器
+關注
關注
2文章
60瀏覽量
14025 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265372
原文標題:AMD EPYC(霄龍) 處理器和AMD Instinct 加速器為高能效添能助力
文章出處:【微信號:AMD中國,微信公眾號:AMD中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AMD銳龍AI嵌入式P100系列處理器產品簡介

奇異摩爾參編人工智能加速器互聯芯粒技術要求團體標準發布
一文了解Mojo編程語言
邊緣計算中的AI加速器類型與應用

【今晚7點半】正點原子 x STM32:智能加速邊緣AI應用開發!今晚正點原子B站直播間等你
瑞薩電子RZ/V系列微處理器助力邊緣AI開發

關于人工智能處理器的11個誤解
AMD嵌入式處理器為您的應用添能助力
芯原可擴展的高性能GPGPU-AI計算IP賦能汽車與邊緣服務器AI解決方案
TPU處理器的特性和工作原理
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
支持實時物體識別的視覺人工智能微處理器RZ/V2MA數據手冊
嵌入式AI加速器DRP-AI 詳細介紹
AI MPU# 瑞薩RZ/V2H 四核視覺 ,采用 DRP-AI3 加速器和高性能實時處理器



 工商網監
工商網監
評論