 使用NVIDIA A30 GPU加速AI推理工作負載
使用NVIDIA A30 GPU加速AI推理工作負載

NVIDIA A30 GPU 基于最新的 NVIDIA Ampere 體系結構,可加速各種工作負載,如大規模人工智能推理、企業培訓和數據中心主流服務器的 HPC 應用程序。 A30 PCIe 卡將第三代 Tensor 內核與大容量 HBM2 內存( 24 GB )和快速 GPU 內存帶寬( 933 GB / s )組合在一個低功耗外殼中(最大 165 W )。
A30 支持廣泛的數學精度:
雙精度( FP64 )
單精度( FP32 )
半精度( FP16 )
腦浮 16 ( BF16 )
整數( INT8 )
它還支持 Tensor Float 32 ( TF32 )和 Tensor Core FP64 等創新技術,提供了一個單一的加速器來加速每個工作負載。
圖 1 顯示了 TF32 ,其范圍為 FP32 ,精度為 FP16 。 TF32 是 PyTorch 、 TensorFlow 和 MXNet 中的默認選項,因此在上一代 NVIDIA Volta 架構中實現加速不需要更改代碼。
A30 的另一個重要特點是多實例 GPU ( MIG )能力。 MIG 可以最大限度地提高從大到小工作負載的 GPU 利用率,并確保服務質量( QoS )。單個 A30 最多可以被劃分為四個 MIG 實例,以同時運行四個應用程序,每個應用程序都與自己的流式多處理器( SMs )、內存、二級緩存、 DRAM 帶寬和解碼器完全隔離。有關更多信息,請參閱 支持的 MIG 配置文件 。
對于互連, A30 支持 PCIe Gen4 ( 64 GB / s )和高速第三代 NVLink (最大 200 GB / s )。每個 A30 都可以支持一個 NVLink 橋接器與一個相鄰的 A30 卡連接。只要服務器中存在一對相鄰的 A30 卡,這對卡就應該通過跨越兩個 PCIe 插槽的 NVLink 橋接器連接,以獲得最佳橋接性能和平衡的橋接拓撲。
性能和平衡的橋接拓撲。
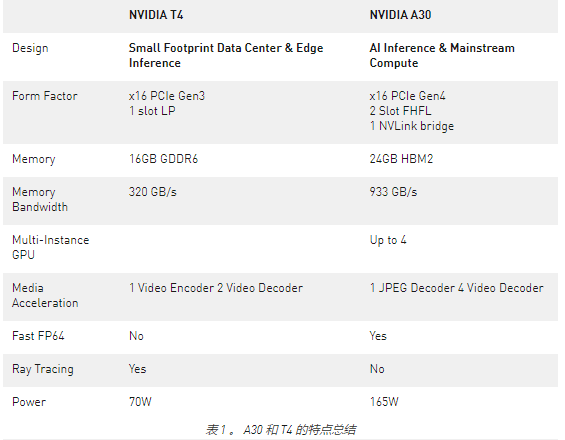
除了表 1 中總結的硬件優勢外, A30 可以實現比 T4 GPU 更高的每美元性能。 A30 還支持端到端軟件堆棧解決方案:
圖書館
GPU 加速了 PyTorch 、 TensorFlow 和 MXNet 等深度學習框架
優化的深度學習模型
可從 NGC 和[2000]以上的容器中獲得
性能分析
為了分析 A30 相對于 T4 和 CPU 的性能改進,我們使用以下數據集對 MLPerf 推斷 v1.1 。 中的六個模型進行了基準測試:
ResNet-50v1 。 5 ( ImageNet )
SSD 大尺寸 ResNet-34 ( COCO )
3D Unet (布拉茨 2019 )
DLRM ( 1TB 點擊日志,離線場景)
BERT (第 1.1 版,第 384 小節)
RNN-T (圖書館語言)
MLPerf 基準測試套件 涵蓋了廣泛的推理用例,從圖像分類和對象檢測到推薦,以及自然語言處理( NLP )。
圖 2 顯示了 A30 與 T4 和 BERT 在人工智能推理工作負載上的性能比較結果。對于 CPU 推斷, A30 比 CPU 快約 300 倍。
與T4相比,A30在使用這六種機型進行推理時提供了大約3-4倍的性能加速比。性能加速是由于30個較大的內存大小。這使得模型的批量更大,內存帶寬更快(幾乎是3倍T4),可以在更短的時間內將數據發送到計算核心。
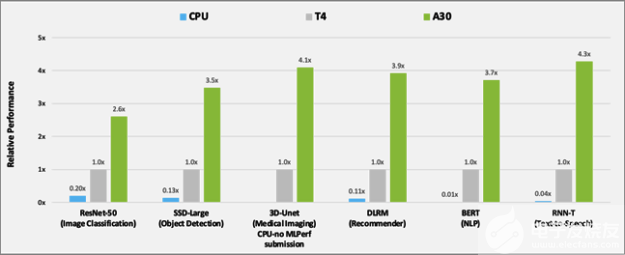
圖 2 使用 MLPerf 比較 A30 與 T4 和 CPU 的性能。
CPU:8380H (不在 3D Unet 上提交)
除了人工智能推理之外, A30 還可以快速預訓練人工智能模型,例如 BERT 大型 TF32 ,以及使用 FP64 張量核加速 HPC 應用。帶有 TF32 的 A30 Tensor Cores 的性能比 T4 高出 10 倍,無需對代碼進行任何更改。它們還提供了自動混合精度的額外 2 倍提升,使吞吐量增加了 20 倍。
硬件解碼器
在構建視頻分析或視頻處理管道時,必須考慮以下幾個操作:
計算模型或預處理步驟的需求。 這取決于 Tensor 內核、 GPU DRAM 和其他硬件組件,它們可以加速模型或幀預處理內核。
傳輸前的視頻流編碼。 這樣做是為了最小化網絡上所需的帶寬。為了加快這一工作量,請使用 NVIDIA 硬件解碼器。
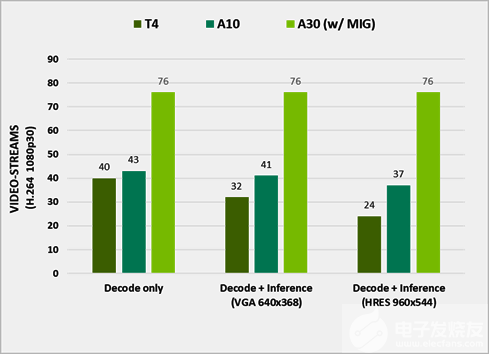
圖 3 在不同 GPU 上處理的流的數量
使用 DeepStream 5.1 測試性能。它代表了 e2e 在視頻捕獲和解碼、預處理、批處理、推理和后處理方面的性能。已關閉輸出渲染以獲得最佳性能,運行 ResNet10 、 ResNet18 和 ResNet50 網絡以推斷 H.264 1080p30 視頻流。
A30 旨在通過提供四個視頻解碼器、一個 JPEG 解碼器和一個光流解碼器來加速智能視頻分析( IVA )。
要使用這些解碼器和計算資源來分析視頻,請使用 NVIDIA DeepStream SDK ,它為基于人工智能的多傳感器處理、視頻、音頻和圖像理解提供了一個完整的流分析工具包。有關更多信息,請參閱 TAO 工具包與 DeepStream 的集成 或者 使用 NVIDIA DeepStream 構建實時編校應用程序,第 1 部分:培訓 。
接下來呢?
A30 代表了數據中心最強大的端到端人工智能和 HPC 平臺,使研究人員、工程師和數據科學家能夠交付真實世界的結果,并將解決方案大規模部署到生產中。有關更多信息,請參閱 NVIDIA A30 Tensor Core GPU 數據表 和 NVIDIA A30 GPU 加速器產品簡介 。
關于作者
Maggie Zhang 是 NVIDIA 的深度學習工程師,致力于深度學習框架和應用程序。她在澳大利亞新南威爾士大學獲得計算機科學和工程博士學位,在那里她從事 GPU / CPU 異構計算和編譯器優化。
Tanay Varshney 是 NVIDIA 的一名深入學習的技術營銷工程師,負責廣泛的 DL 軟件產品。他擁有紐約大學計算機科學碩士學位,專注于計算機視覺、數據可視化和城市分析的橫斷面。
Davide Onofrio 是 NVIDIA 的高級深度學習軟件技術營銷工程師。他在 NVIDIA 專注于深度學習技術開發人員關注內容的開發和演示。戴維德在生物特征識別、虛擬現實和汽車行業擔任計算機視覺和機器學習工程師已有多年經驗。他的教育背景包括米蘭理工學院的信號處理博士學位。Ivan Belyavtsev 是一名圖形開發工程師,主要致力于開發人員支持和優化基于虛擬引擎的游戲。他還是 Innopolis 大學游戲開發領域的計算機圖形學導師。
Shar Narasimhan 是 AI 的高級產品營銷經理,專門從事 NVIDIA 的 Tesla 數據中心團隊的深度學習培訓和 OEM 業務。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5594瀏覽量
109756 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265420 -
深度學習
+關注
關注
73文章
5599瀏覽量
124400
發布評論請先 登錄
NVIDIA DGX SuperPOD為Rubin平臺橫向擴展提供藍圖
NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

通過NVIDIA Jetson AGX Thor實現7倍生成式AI性能
BPI-AIM7 RK3588 AI與 Nvidia Jetson Nano 生態系統兼容的低功耗 AI 模塊
通過NVIDIA RTX PRO服務器加速企業工作負載

NVIDIA虛擬GPU 18.0版本的亮點
使用NVIDIA RTX PRO Blackwell系列GPU加速AI開發
英偉達GTC2025亮點:Oracle與NVIDIA合作助力企業加速代理式AI推理

英偉達GTC2025亮點:NVIDIA與行業領先存儲企業共同推出面向AI時代的新型企業基礎設施
英偉達GTC25亮點:NVIDIA Blackwell Ultra 開啟 AI 推理新時代
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
Oracle 與 NVIDIA 合作助力企業加速代理式 AI 推理

NVIDIA 與行業領先的存儲企業共同推出面向 AI 時代的新型企業基礎設施

NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺




 工商網監
工商網監
評論