 通過NVIDIA RTX PRO服務器加速企業工作負載
通過NVIDIA RTX PRO服務器加速企業工作負載

從大語言模型(LLM)到代理式 AI 推理和物理 AI ,隨著 AI 工作負載的復雜性和規模不斷增加,人們對更快、擴展性更高的計算基礎設施的需求空前強烈。滿足這些需求就要從基礎開始重新思考系統架構。
NVIDIA 正在通過NVIDIA ConnectX-8 SuperNIC升級平臺架構。NVIDIA ConnectX-8 SuperNIC 是業內首款在單個設備中集成PCIe6.0 交換機和超高速網絡的 SuperNIC。ConnectX-8 專為現代 AI 基礎架構設計,可提供更高的吞吐量,同時簡化系統設計,并提高能效和成本效益。
為 PCIe6.0 連接的時代做好準備
在基于 PCIe 連接的平臺中,尤其是配備 8 個或更多 GPU 的平臺,PCIe 交換機對于最大化 GPU 間通信帶寬和實現可擴展的 GPU 拓撲至關重要。現有設計依賴于獨立的 PCIe 交換機,這通常會增加設計復雜性,并可能會限制性能和效率。
ConnectX-8 通過內置的 PCIe6.0 交換機提供 48 通道的 PCIe6.0 連接解決了這一問題。將 GPU 到 GPU 和 GPU 到 NIC 通信整合到單一高性能設備中,消除了對獨立 PCIe 交換機的需求,減少了元器件數量并簡化了主板設計,為 AI 基礎設施打造了更具成本效益、可擴展的架構。
此外,憑借原生 PCIe6.0 支持,ConnectX-8 可滿足新一代 GPU、CPU 和 IO 加速器日益增長的 IO 需求。它使系統架構師能夠設計出向前兼容的平臺,能夠充分享用領先的高吞吐 PCIe6.0 設備的帶寬。
通過 NVIDIA RTX PRO 服務器加速企業工作負載
ConnectX-8 SuperNIC 現已全面投產。 在 COMPUTEX 2025 上,ConnectX-8 被發布用于全球各系統合作伙伴的 NVIDIA RTX PRO 服務器中。
圖 1 比較了兩種服務器架構:采用獨立 PCIe 交換機的傳統設計,以及采用 NVIDIA ConnectX-8 SuperNIC 集成 PCIe6.0 交換機的 NVIDIA RTX PRO 服務器的 優化配置。
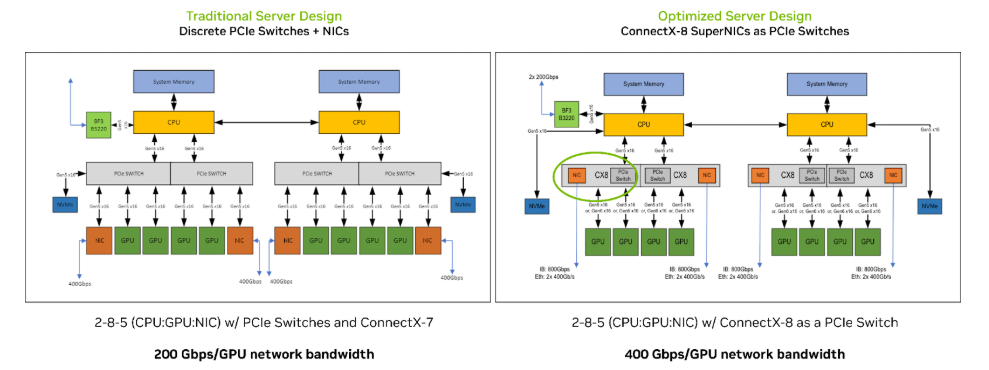
圖 1:傳統(左)和與采用 ConnectX-8 SuperNIC 優化(右)服務器設計的比較
在傳統設計中,服務器布局包括 2 個 CPU、8 個 GPU 和 5 個 NIC(包括 4 個 NVIDIA ConnectX-7 NIC 和 1 個 NVIDIA BlueField-3 DPU)。這種配置還需要兩到四個獨立的 PCIe 交換機來實現 GPU 到 GPU 和 GPU 到 NIC 的連接,從而增加復雜性和組件數量。
在優化過的設計中,用 ConnectX-8 SuperNIC 替換掉了專用 PCIe 交換機,將 PCIe6.0 交換和 800 Gb/s 網絡集成在了單一網卡設備中。
它使每個 GPU 的網絡帶寬翻倍,有助于消除 IO 瓶頸,并加快 GPU、NIC 和存儲之間的數據移動速度。因此,此 NVIDIA RTX PRO 服務器平臺可提供高達 2 倍的 NCCL all-to-all 性能,加速在多 GPU 和多節點工作負載中至關重要的集合通信,并提高 AI 工廠的可擴展性。
在圖 1 的基礎上,圖 2 讓我們更深入地了解經過優化設計的服務器架構如何改善三種主要 GPU 通信路徑之間的連接:
GPU 到 GPU 通信跨越兩個 CPU 插座:在傳統設計中,此路徑可能會遇到主機 CPU 和內部插座瓶頸問題,根據 CPU 之間鏈路的利用率不同,可能被限制在 25 GB/s 或更低的速度。相比之下,基于 ConnectX-8 的優化設計可為集群內的所有 GPU 間通信提供高達 每個GPU 50 GB/s 的 IO 帶寬,因為 NCCL 直接通過網絡轉發所有流量。
GPU 到 NIC 通信:在 2:1 的 GPU 到 NIC 配置下,經過優化的架構為每個 GPU 提供 50 GB/s 的帶寬,無論 GPU 或主機系統是 PCIe5.0 或 PCIe6.0。
GPU 到 GPU 通信通過同一 PCIe 交換機:相較 PCIe5.0,配備 PCIe6.0 的系統可將帶寬提高一倍,從而顯著加速同一 PCIe 交換機上的點對點 GPU 傳輸。
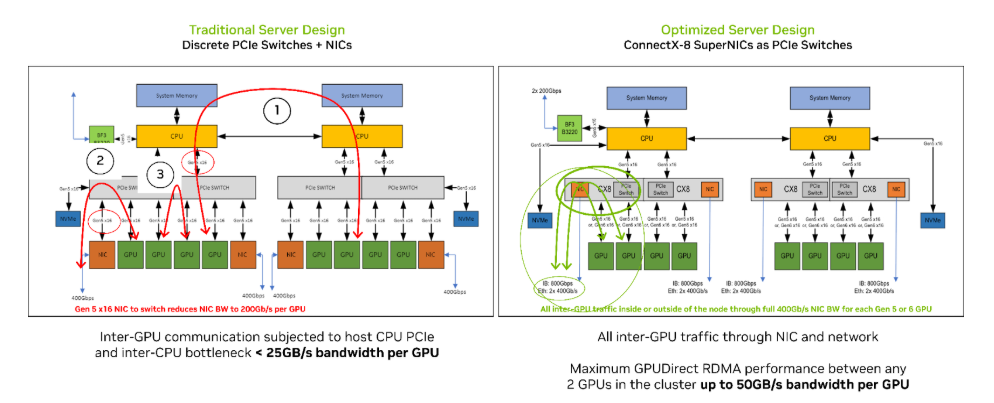
圖 2:傳統(左)和與采用 ConnectX-8 SuperNIC 的優化(右)服務器設計的比較,強調了三種關鍵的 GPU 通信路徑
通過將 PCIe 交換直接集成到 SuperNIC 中,ConnectX-8 還簡化了主板設計、改善了氣流并增強了可維護性。這將打造一個更緊湊、更節能、更經濟高效的平臺。在 NVIDIA 參考設計的支持下,這項創新可幫助系統廠商更快地擴展其系統,并提高性能及降低 TCO。
基于 PCIe 總線的 AI 基礎架構的未來
NVIDIA ConnectX-8 正在重新定義基于 PCIe 總線的系統的可能性。通過將 PCIe6.0 交換機和高性能 SuperNIC 集成到單一集成設備中,ConnectX-8 可簡化服務器設計,減少組件數量,并解鎖現代 AI 工作負載所需的高帶寬通信路徑。從而打造更簡單、更節能的平臺,同時降低總體擁有成本(TCO)并實現出色的性能可擴展性。
此外,ConnectX-8 SuperNIC 還可在基于多 GPU 的平臺中實現增強的機密計算能力。
在 COMPUTEX 2025 上,領先的數據中心合作伙伴展示了由內置 NVIDIA ConnectX-8 SuperNIC 的 NVIDIA RTX PRO 服務器所加速的先進 AI 平臺架構。
-
NVIDIA
+關注
關注
14文章
5678瀏覽量
110060 -
總線
+關注
關注
10文章
3050瀏覽量
91817 -
AI
+關注
關注
91文章
40737瀏覽量
302385 -
PCIe
+關注
關注
16文章
1470瀏覽量
88850
原文標題:NVIDIA ConnectX-8 SuperNIC 通過 PCIe6.0 總線升級 AI 平臺架構
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA RTX PRO 2000 Blackwell GPU性能測試

基于NVIDIA GPU的加速服務 為AI、機器學習和AI工作負載提速
nVidia許可服務器存在問題
RTX刀片服務器實現云渲染密度、效率及可擴展性的飛躍
NVIDIA虛擬工作站新版本可支持RTX服務器
NVIDIA公布通過NVIDIA認證系統測試的全球首批加速服務器 企業 AI 使用量倍增
NVIDIA Grace超級芯片為HPC及AI工作負載提速

使用NVIDIA Triton推理服務器來加速AI預測
NVIDIA Blackwell RTX PRO 提供工作站和服務器兩種規格,助力設計師、開發者、數據科學家和創作人員構建代理式

NVIDIA加速的Apache Spark助力企業節省大量成本

NVIDIA RTX PRO 4500 Blackwell GPU測試分析

NVIDIA RTX PRO 4000 Blackwell GPU性能測試

NVIDIA RTX PRO 5000 Blackwell GPU的深度評測




 工商網監
工商網監
評論