 AutoML技術提高NVIDIA GPU和RAPIDS速度
AutoML技術提高NVIDIA GPU和RAPIDS速度

為了獲得最先進的機器學習( ML )解決方案,數據科學家通常建立復雜的 ML 模型。然而, 這些技術的計算成本很高,直到最近還需要廣泛的背景知識、經驗和人力。
最近,在 GTC21 , AWS 高級數據科學家 尼克·埃里克森 給出了一個 session 分享如何結合 AutoGluon , RAPIDS 和 NVIDIA GPU 計算簡化實現最先進的 ML 精度,同時提高性能和降低成本。 這篇文章概述了尼克會議的一些要點:
AutoML 是什么? AutoGluon 有什么不同?
在 Kaggle 預測比賽中, AutoGluon 如何在僅僅三行代碼的情況下就超過 99% 的人類數據科學團隊, 不需要專家知識?
AutoGluon 與 RAPIDS 的集成如何使訓練速度提高 40 倍,推理速度提高 10 倍?
什么是AutoGluon?
AutoGluon 是一個開放源代碼的 AutoML 庫,它支持易于使用和易于擴展的 AutoML ,重點放在自動堆棧合并、深度學習和跨文本、圖像和表格數據的真實應用程序上。面向 ML 初學者和專家, AutoGluon 使您能夠:
用幾行代碼為您的原始數據快速構建深度學習和經典 ML 解決方案的原型。
在沒有專家知識的情況下自動使用最先進的技術(如適用)。
利用自動超參數調整、模型選擇/裝配、架構搜索和數據處理。
輕松改進/調整您的定制模型和數據管道,或為您的用例定制 AutoGluon 。
本文主要關注 AutoGluon Tabular ,這是一個 AutoGluon API ,它只需要幾行 Python 就可以在未處理的表格數據集(如 CSV 文件)上訓練高度精確的機器學習模型。 為了理解 AutoGluon Tabular 是如何做到這一點的,我們將首先解釋一些概念。
什么是監督機器學習?
有監督機器學習 將一組帶標簽的訓練實例作為輸入,并構建一個模型,該模型旨在基于我們知道的關于該實例的其他信息(稱為實例的特征)正確預測每個訓練實例的標簽。這樣做的目的是建立一個精確的模型,可以自動用未知的標簽標記未來的數據。
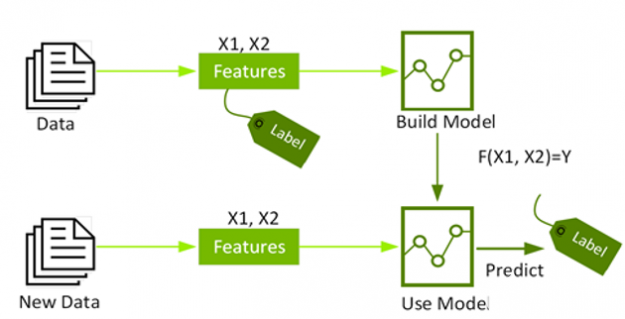
圖 1 :有監督機器學習使用標記數據建立模型,對未標記數據進行預測。
在表格數據集中,列表示變量的度量(又稱特征),行表示單個數據點。 例如,下表顯示了一個包含三列的小數據集:“有工作”、“擁有房子”和“收入”。在本例中,“ income ”是標簽(有時稱為預測的目標變量),其他列是用于嘗試預測收入的特征。

表 1 :收入數據集
有監督機器學習是一個迭代的、探索性的過程,它涉及到數據準備、特征工程、驗證拆分、缺失值處理、訓練、測試、超參數調整、集成和評估 ML 模型,然后才能將模型用于生產中進行預測。
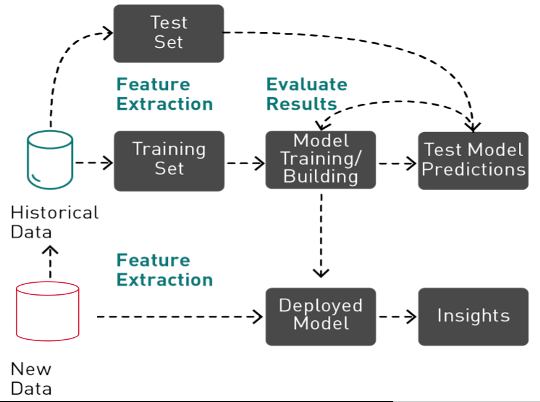
圖 2 :機器學習是一個迭代過程,包括特征提取、訓練和評估,然后才能部署模型進行預測。
什么是 AutoML
歷史上,實現最先進的 ML 性能需要廣泛的背景知識、經驗和人力。根據自動化的工具和級別, AutoML 使用不同的算法技術來嘗試為 ml 管道找到最佳的特性、超參數、算法和/或算法組合。通過 automating 耗時的 ML 管道,從業者和企業可以應用機器學習更快更容易地解決業務問題。
AutoML 分三步進行, AutoGluon 表格
自動膠合板 可用于自動構建最先進的模型,該模型使用兩個函數 fit () 和 predict () 根據同一行中的其他列預測特定列的值,如下所示。
from autogluon.tabular import TabularPredictor, TabularDataset
# load dataset
train_data = TabularDataset(DATASET_PATH)
# fit the model
predictor = TabularPredictor(label=LABEL_COLUMN_NAME).fit(train_data)
# make predictions on new data
prediction = predictor.predict(new_data)
函數的作用是:研究數據集,執行數據預處理,擬合多個模型,并將它們結合起來生成一個高精度的模型。有關要嘗試的更完整的示例,請參見 關于預測表中列的 AutoGluon 快速入門教程。
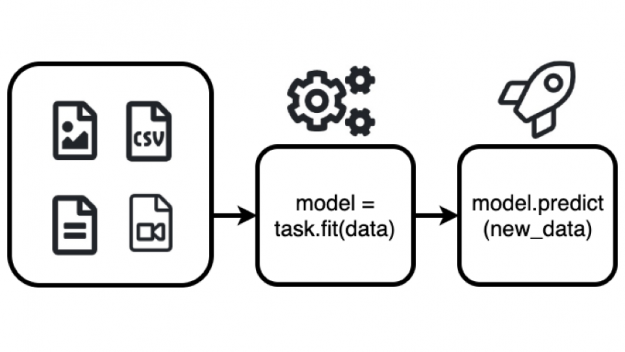
圖 3 : AutoGluon fit ()函數自動構建一個 ML 模型,該模型可用于基于 predict ()函數同一行中的其他列來預測特定列的值。
用這個簡單的代碼, AutoGluon 擊敗了其他 AutoML 框架和許多頂尖的數據科學家。 廣泛的評估 通過對 Kaggle 和 OpenML AutoML 基準測試的 50 個分類和回歸任務進行測試,發現 AutoGluon 比 TPOT 、 H2O 、 AutoWEKA 、 AutoSklearn 和 Google AutoML 表更快、更健壯、更準確。同樣在兩個受歡迎的 Kaggle 比賽中, AutoGluon 在僅僅 4 小時的原始數據訓練后就擊敗了 99% 的數據科學家。
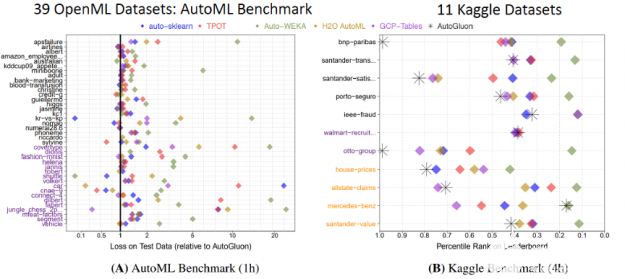
圖 4 : AutoGluon 的性能超過了其他 AutoML 框架和許多頂尖的 Kaggle 數據科學家。
自粘膠有什么不同?
大多數 AutoML 框架致力于將算法選擇和超參數優化( CASH )結合起來,提供從各種可能性中尋找最佳模型及其超參數的策略。然而,現金有一些缺點:
它需要許多重復的模型訓練,而且大多數模型都被丟棄了,而沒有對最終結果做出貢獻。
超參數調優做得越多,驗證數據擬合過度的風險就越高。
超參數調整在加密時不太有用。
相比之下, AutoGluon Tabular 依靠專家數據科學家使用的方法來贏得競爭:將多個模型集合起來,并將它們堆疊在多個層中,從而優于其他框架。
Ensembling 是如何工作的?
集成學習方法結合多種機器學習( ML )算法來獲得更好的模型。為了更好地理解這一點,讓我們看看隨機森林,它是決策樹的集合。
決策樹通過評估 if-then-else 和真/假特征問題樹,并估計評估做出正確決策的概率所需的最小問題數,創建預測目標標簽的模型。決策樹可用于分類以預測類別,或用于回歸以預測連續數值。例如,下面的決策樹(基于上表)嘗試使用特征“ has job ”和“ owns house ”的兩個決策節點來預測標簽“ income ”。
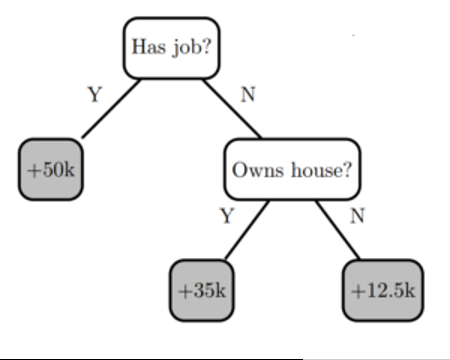
圖 5 :一個簡單的決策樹模型,有兩個決策節點和三片葉子。
決策樹的優點是易于解釋,但存在過度擬合和準確性問題。建立一個精確的模型是介于兩者之間的 以及過度擬合——模型預測與訓練數據的行為方式相匹配,并且被廣泛化,足以對看不見的數據進行準確預測。
決策樹試圖找到最佳分割來對數據進行子集劃分,這會導致嚴重的分割。 例如,給定下面左邊的數據集,我們想預測一個點的顏色,點越亮,值就越高。如右圖所示,決策樹會將數據分割成多個塊。 下一步,我們將研究如何使用 ensembling 改進決策樹。
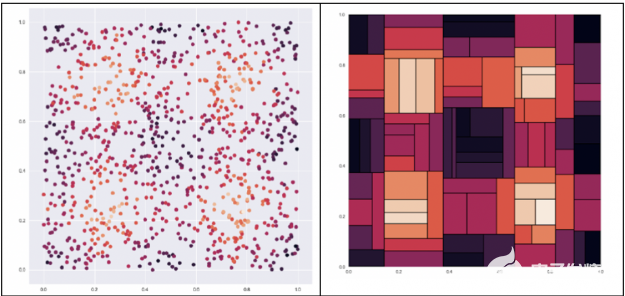
圖 6 :左邊的示例數據集,目標是預測點的顏色,點越亮,值越高。此數據集的決策樹 右邊是將數據分割成粗糙的塊。
Ensembling 是一種通過組合預測和改進泛化來提高模型精度的行之有效的方法。 隨機森林 是一種流行的分類和回歸集成學習方法。 Random forest 使用一種稱為 bagging ( bootstrap aggregating )的技術,從數據集和特征的隨機 bootstrap 樣本并行地構建完整的決策樹。 通過對所有樹的輸出進行聚合來進行預測,減少了方差,提高了預測精度。最終的預測是所有決策樹預測的多數類或均值回歸。 隨機性對森林的成功至關重要, bagging 確保沒有決策樹是相同的,減少了單個樹的過度擬合問題。
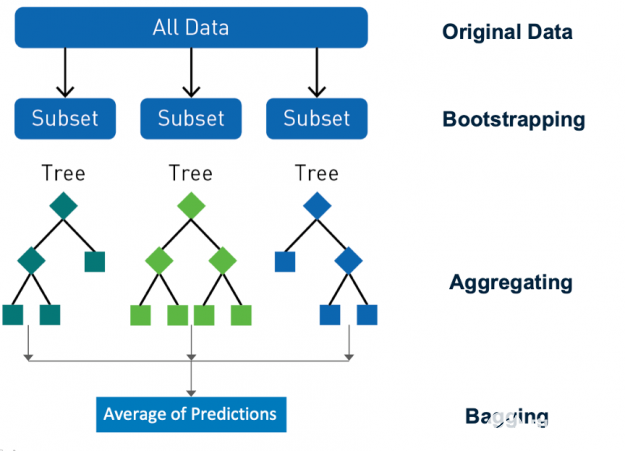
圖 7 : Random forest 使用一種稱為 bagging 的技術從數據集和特性的隨機引導樣本構建決策樹。
為了理解這是如何給出更好的預測,讓我們看一個例子。這里是圖 6 中所示的數據集的四個不同的決策樹,測試數據點的預測顏色不同。我們可以看到,每一種方法都給出了解的近似值,而這種近似值不足以作出精確的預測。
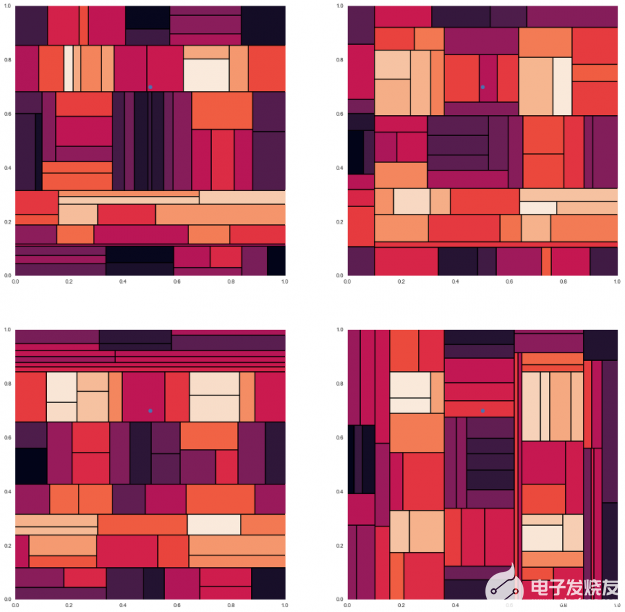
圖 8 : 圖 6 所示的數據集有四個不同的決策樹,一個測試數據點有不同的預測顏色 。
當這四個決策樹被合并并平均在一起時,粗糙的邊界消失了,并且像下面的隨機森林示例一樣被平滑。現在 測試數據點的預測顏色是來自其他樹預測的顏色的混合。
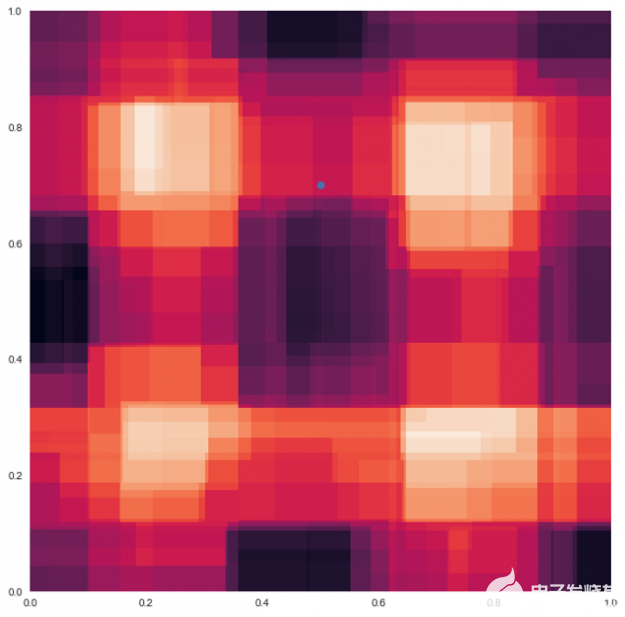
圖 9 :隨機森林 模型 對于 圖 8 中的四個決策樹 。
隨機林中的所有決策樹都是次優的,它們在隨機方向上都是錯誤的。當平均決策樹時,它們錯誤的原因相互抵消,這稱為方差抵消。 結果質量更高,因為它們反映了大多數樹做出的決定。平均值限制了誤差,即使有些樹是錯的,有些樹是對的,所以這組樹一起朝著正確的方向移動。
當許多不相關的決策樹組合在一起時,它們產生的模型具有很高的預測能力,能夠抵抗過度擬合。這些概念是流行的機器學習算法的基礎,例如 隨機森林, XGBoost , Catboost 和 LightGBM 這些都是由自動膠所使用的。
多層疊加
你可以更進一步與 ensembling ,經驗豐富的機器學習實踐者 將 RandomForest 、 CatBoost 、 k 近鄰和其他的輸出結合起來,以進一步提高模型精度。在 ML 競爭社區很難找到一個單一的模型贏得的競爭,每一個獲勝的解決方案都包含了模型的集合。
Stacking 是一種使用“基本”回歸或分類模型集合的聚合預測作為訓練元分類器或回歸“堆棧”模型的特征的技術。
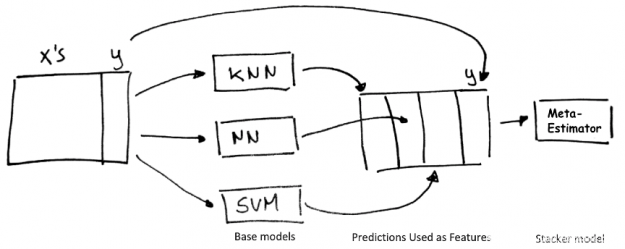
圖 10 :堆疊技術。
多層堆垛機將堆垛機模型輸出的預測結果作為輸入輸入到其他更高層的堆垛機模型中。在許多 Kaggle 比賽中,在多個層次上迭代這個過程是一個獲勝的策略。多層疊加集成功能強大,但很難使用和實現,目前除了 Autogluon 之外,其他任何 AutoML 框架都沒有使用它。
無需專家知識, AutoGluon 自動組裝和訓練一種新形式的多層堆疊,如圖 11 所示,采用 k 折疊裝袋。其工作原理如下:
底座: 第一層有多個基礎模型,這些模型分別經過訓練,并使用 k-fold 集成裝袋(下文討論)。
連接:將基礎層模型預測與輸入特征連接起來,作為下一層的訓練輸入。
堆垛:多個堆垛機模型在 concat 層輸出上進行訓練。與傳統的堆疊策略不同, AutoGluon 重用與 stackers 相同的基本層模型類型(具有相同的超參數值)。 此外,堆垛機模型不僅將前一層模型的預測作為輸入,而且還將原始數據特征本身作為輸入。
加權:最后的堆疊層應用集合選擇以加權的方式聚合堆疊機模型的預測。 在高容量模型堆棧中聚合預測可以提高對過度擬合的恢復能力
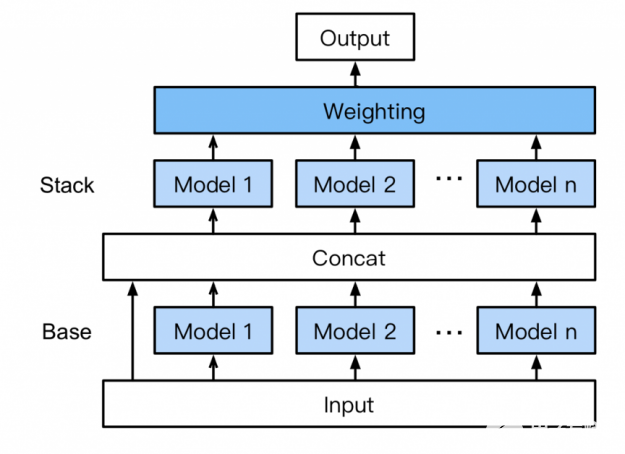
圖 11 : AutoGluon 的多層堆疊集成。
k-fold Ensembling 套袋
AutoGluon 通過將所有可用數據用于訓練和驗證,通過在堆棧的所有層對所有模型進行 k 折集成裝袋來提高堆棧性能。 k-fold ensemble bagging 類似于 k-fold cross validation,這是一種最大化訓練數據集的方法,通常用于超參數調整以確定最佳模型參數。通過 k 折交叉驗證,數據被隨機分成 k 個分區(折疊)。每個折疊一次用作驗證數據集,而其余的 (Out-Of-Fold – OOF) 用于訓練。模型使用 OOF 訓練集進行訓練并使用驗證集進行評估,從而產生 k 個模型精度測量值。 AutoGluon 不是確定最佳模型并丟棄其余模型,而是將所有模型打包并從訓練期間未看到的分區上的每個模型獲得 OOF 預測。這為每個模型創建了 k 折預測,用作下一層的元特征。
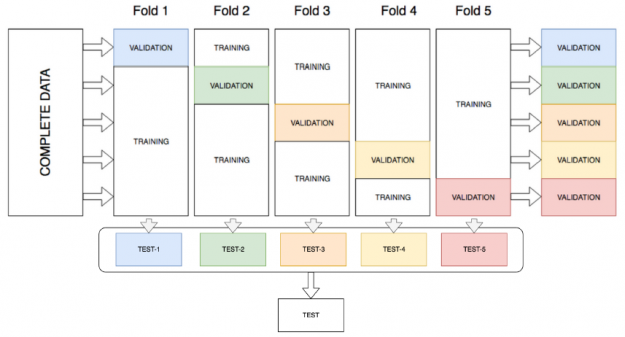
圖 12 : k 折整體裝袋。
為了進一步提高預測精度和減少過度擬合, AutoGluon 表格 在訓練數據的 n 個不同的隨機分區上重復 k 次裝袋過程,平均重復袋子上的所有 OOF 預測。在調用 fit ()函數時,通過估計在指定的時間限制內可以完成多少輪來選擇 n 。
為什么 AutoGluon 需要 GPU 加速
多層堆棧集成提高了精度,然而,這意味著要訓練數百個模型,這比基本的 ML 用例需要更多的計算密集型任務,并且比加權集成要貴 10 到 20 倍。 在過去,復雜性和計算需求使得多層堆棧集成很難在許多生產用例和大型數據集上實現。對于 AutoGluon 和 NVIDIA GPU 計算 ,情況不再如此。
在體系結構上, CPU 由幾個內核組成,這些內核有大量的高速緩存,一次可以處理幾個軟件線程。相反, GPU 由數百個內核組成 可以同時處理數千個線程。 GPU 的性能超過 20 倍 在 ML 工作流程中比 CPU 更快,并徹底改變了深度學習領域。

圖 13 : CPU 由幾個核組成,而 GPU 則由幾百個核組成。
NVIDIA 開發了 RAPIDS ——一個開源的數據分析和機器學習加速平臺,用于在 GPUs 中完全執行端到端的數據科學培訓管道。它依賴于 NVIDIA ? [[ZCK0 號]? 用于低級計算優化的原語,但通過用戶友好的 Python 接口(如 pandas 和 sciketlearnapi )公開了 GPU 并行性和高內存帶寬。
使用 RAPIDS 的 cuML , 流行的機器學習算法,比如隨機森林, XGBoost 和其他許多產品都支持單 GPU 和大型數據中心部署。對于大型數據集,這些基于 GPU 的實現可以加快機器學習模型的訓練速度—通過 在隨機森林的情況下高達 45 倍 ,超過 100x 支持向量機 和 k 近鄰最高可達 600 倍 。這些加速可以將夜間作業轉換為交互式作業,允許探索更大的數據集,并且可以在以前訓練單個模型所需的時間內嘗試幾十種模型變體。
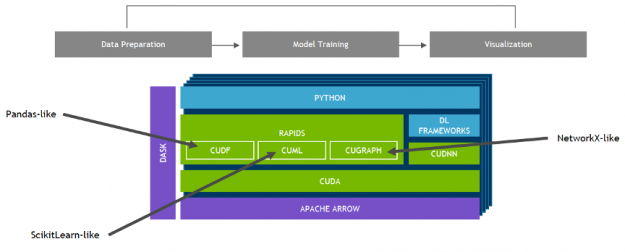
圖 14 :帶有 GPU 和 RAPIDS 的數據科學管道。
AutoGluon 的 最新版本 通過與 RAPIDS 集成,充分利用了 NVIDIA GPU 計算的潛力。通過這些集成, AutoGluon 能夠在 GPU 上訓練流行的 ml 算法并提高性能, 使更廣泛的受眾能夠訪問高性能的 AutoML 。
AutoGluon + RAPIDS 基準
對于 1 。 15 億行航空公司數據集 用于梯度增壓機 ( GBM ) 基準測試套件 , AutoGluon + RAPIDS 的訓練速度比 cpu 上的 AutoGluon 快 25 倍,準確率為 81 。 92% ,比 XGBoost 基線高 7% 。 GPU 更喜歡更長的培訓時間,因為固定的啟動成本變得不那么重要。
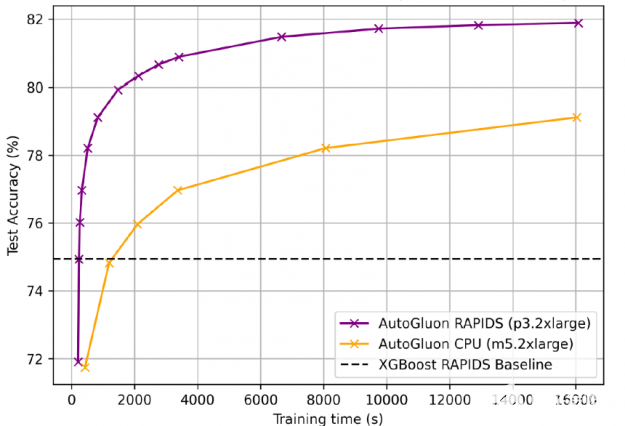
圖 15 : AutoGluon + RAPIDS 比 CPU 上的 AutoGluon 加速訓練 25 倍,準確率為 81 。 92% 。
為了獲得 81 。 92% 的準確率, gpu 上的 AutoGluon + RAPIDS 訓練時間為 4 小時,而 cpu 為 4 。 5 天。
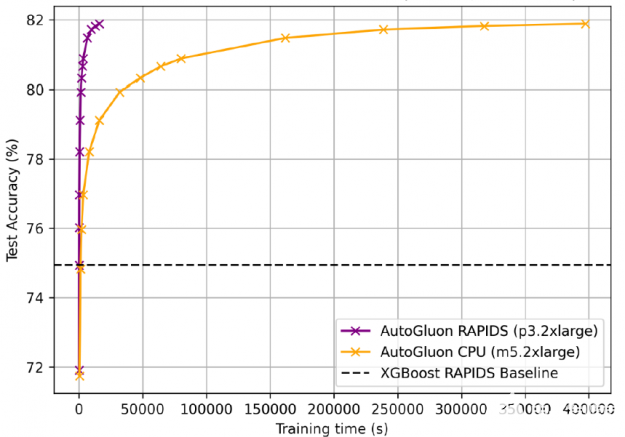
圖 16 : GPU 上的 AutoGluon + RAPIDS 訓練時間為 4 小時,而 CPU 為 4 。 5 天。
GPU 上的 AutoGluon + RAPIDS 不僅速度更快,而且成本更低,? 盡可能多的 CPU 訓練到相同的精度( AWS EC2 定價: p3 。 2XL $ 0 。 9180 /小時, m5 。 2XL $ 0 。 1480 /小時)。
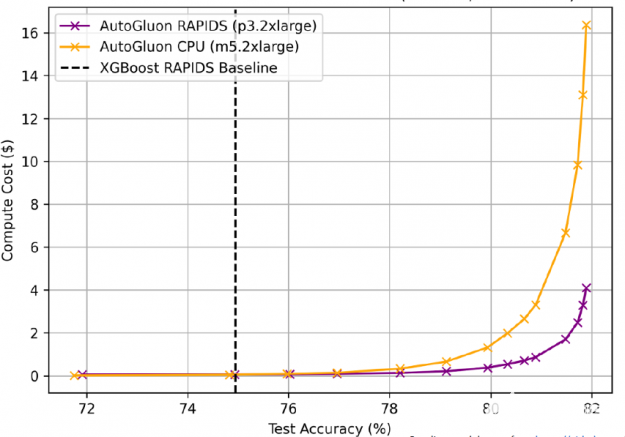
圖 17 : GPU 上的 AutoGluon + RAPIDS 成本更低,? 盡可能多的 CPU 訓練到同樣的精度。
開始吧
要開始使用 AutoGluon 和 RAPIDS :
啟動 帶 p3 。 2XL 的 AWS EC2 實例 GPU
為 CUDA 選擇深度學習 AMI
安裝 RAPIDS
安裝 AutoGluon 表格
試試這個 AutoGluon + RAPIDS Python 筆記本使用來自 Otto 集團產品分類挑戰賽的數據
AutoGluon 網站 為開發人員提供了大量的教程,幫助他們利用機器學習來處理表格、文本和圖像數據(包括分類/回歸等基本任務,以及對象檢測等更高級的任務)。
Conclusion
AutoGluon AutoML 工具箱使培訓和部署尖端技術變得很容易 復雜業務問題的精確機器學習模型。此外, AutoGluon 與 RAPIDS 的集成充分利用了 NVIDIA GPU 計算的潛力,使復雜模型的訓練速度提高了 40 倍,預測速度提高了 10 倍。
關于作者
Nick Becker 是 NVIDIA 的 RAPIDS 團隊的高級軟件工程師和數據科學家,他致力于構建 GPU 加速的數據科學產品。尼克有技術和政府方面的專業背景。在 NVIDIA 之前,他曾在數據科學初創公司 Enigma Technologies 工作。在《謎》之前,他曾在美國中央銀行聯邦儲備理事會( Federal Reserve Board of Governors )進行經濟學研究和預測。
Nick Erickson 是 Amazon 網絡服務人工智能的高級數據科學家。他是開源 AutoML 框架 autoglion 的主要開發人員和合著者。尼克正在尋求推進對人工智能的科學理解,并利用不斷增長的計算能力來創建有利于社會的強大的自適應程序。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5594瀏覽量
109731 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265371 -
機器學習
+關注
關注
66文章
8553瀏覽量
136948
發布評論請先 登錄
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
RSoft GPU加速技術重塑光子元件設計效率革命

NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

NVIDIA RTX PRO 4000 Blackwell GPU性能測試

在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

NVIDIA Isaac Lab多GPU多節點訓練指南
NVIDIA RAPIDS 25.06版本新增多項功能
NVIDIA RTX PRO 4500 Blackwell GPU測試分析

NVIDIA桌面GPU系列擴展新產品
NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄




 工商網監
工商網監
評論