 如何測量各種工作負載和GPU配置下收縮操作的性能
如何測量各種工作負載和GPU配置下收縮操作的性能

張量收縮是機器學習、計算化學和量子計算中許多重要工作的核心。隨著科學家和工程師們對不斷增長的問題的研究,基礎數據變得越來越大,計算時間也越來越長。
當張量收縮不再適合單個 GPU 時,或者如果在單個 GPU 上花費的時間太長,自然下一步是將收縮分布到多個 GPU 上。我們一直在用這個新功能擴展 cuTENSOR ,并將其作為一個名為 cuTENSORMg (多 GPU )的新庫發布。它在塊循環分布張量上提供單進程多 GPU 功能。
cuTENSORMg 的copy和contraction操作大致分為句柄、張量描述符和描述符。在這篇文章中,我們將解釋句柄和張量描述符,以及復制操作是如何工作的,并演示如何執行張量收縮。然后,我們將展示如何測量各種工作負載和 GPU 配置下收縮操作的性能。
庫把手
庫句柄表示參與計算的設備集。句柄還包含跨調用重用的數據和資源。通過將設備列表傳遞給cutensorMgCreate函數,可以創建庫句柄:
cutensorMgCreate(&handle, numDevices, devices);
cuTENSORMg 中的所有對象都是堆分配的。因此,必須通過匹配的destroy調用釋放它們。為了簡潔起見,我們在這篇文章中沒有展示這些,但是生產代碼應該銷毀它創建的所有對象,以避免泄漏。
cutensorMgDestroy(handle);
所有庫調用都返回cutensorStatus_t類型的錯誤代碼。在生產中,您應該始終檢查錯誤代碼,以便盡早檢測故障或使用問題。為了簡潔起見,我們在本文中省略了這些檢查,但它們包含在相應的示例代碼中。
除了錯誤代碼, cuTENSORMg 還提供與 cuTENSOR 類似的日志記錄功能 。可以通過適當設置CUTENSORMG_LOG_LEVEL環境變量來激活這些日志。例如,CUTENSORMG_LOG_LEVEL=1將為您提供有關返回的錯誤代碼的附加信息。
張量描述符
張量描述符描述了張量在內存中的布局以及在設備中的分布。對于每種模式,有三個核心概念來確定布局:
extent:每個模式的邏輯大小。
blockSize:將extent細分為大小相等的塊,但最后的剩余塊除外。
deviceCount:確定塊在設備上的分布方式。
圖 1 顯示了extent和block size如何細分二維張量。
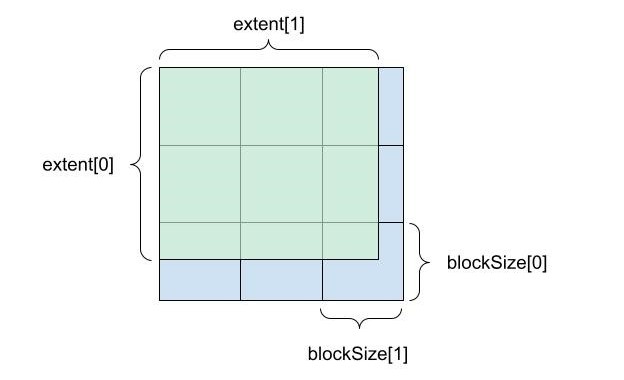
圖 1 帶有范圍和塊的張量數據布局。綠色表示二維張量,藍色表示塊大小導致的塊。
![A 3x3 square showing deviceCount [0] on the Y axis and deviceCount[1] on the X axis.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/03/Introducing-Multi-GPU-Tensor-Contractions-4-625x494_2.jpg)
圖 2 以塊循環方式在設備上分布塊張量;不同的顏色代表不同的設備。
塊以循環方式分布,這意味著連續的塊被分配給不同的設備。圖 2 顯示了塊到設備的逐塊分布,將設備分配到使用另一個數組devices編碼的塊。該陣列是一個密集的柱狀主張量,其范圍與設備計數類似。
![A 4x4 block with Y axis as blockStride[0] and X axis blockStride[1]. This block is comprised of smaller by 4x4 blocks with elementStride[1] as the X axis and and elementStride[0] as the Y axis.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/03/Introducing-Multi-GPU-Tensor-Contractions-2-625x469_2.jpg)
圖 3 使用元素步距和塊步距的設備上數據布局。
最后,設備上的確切數據布局由每種模式的elementStride和blockStride 值決定。它們分別以元素為單位在線性存儲器中確定給定模式下兩個相鄰元素和相鄰塊的位移(圖 3 )。
這些屬性都是使用cutensorMgCreateTensorDescriptor調用設置的:
cutensorMgCreateTensorDescriptor(handle, &desc, numModes, extent, elementStride, blockSize, blockStride, deviceCount, numDevices, devices, type);
可以將NULL傳遞給elementStride、blockSize、blockStride和deviceCount。
如果elementStride是NULL,則使用通用列主布局假定數據布局密集。如果blockSize是NULL,則等于extent。如果blockStride是NULL,則它等于blockSize * elementStride,這將產生交錯塊格式。如果deviceCount為NULL,則所有設備計數都設置為 1 。在這種情況下,張量是分布式的,完全駐留在devices[0]的內存中。
通過將CUTENSOR_MG_DEVICE_HOST作為所屬設備傳遞,可以指定 tensor 位于主機上的固定、托管或定期分配的內存中。
復制操作
copy操作可以更改數據布局,包括將張量重新分配到不同的設備。其參數是源和目標張量描述符(descSrc和descDst),以及源和目標模式列表(modesSrc和modesDst)。這兩個張量在重合模式下的范圍必須匹配,但它們的其他方面可能不同。一個可能位于主機上,另一個跨設備,它們可能具有不同的阻塞和步幅。
與 cuTENSORMg 中的所有操作一樣,它分三步進行:
cutensorMgCopyDescriptor_t:編碼應該執行的操作。
cutensorMgCopyPlan_t:編碼操作的執行方式。
cutensorMgCopy:根據計劃執行操作。
第一步是創建復制描述符:
cutensorMgCreateCopyDescriptor(handle, &desc, descDst, modesDst, descSrc, modesSrc);
有了拷貝描述符,您可以查詢所需的設備端和主機端工作空間的數量。deviceWorkspaceSize陣列的元素數量與手柄中的設備數量相同。i-th 元素是句柄中i-th 設備所需的工作空間量。
cutensorMgCopyGetWorkspace(handle, desc, deviceWorkspaceSize, &hostWorkspaceSize);
確定工作空間大小后,規劃副本。你可以傳遞一個更大的工作空間大小,呼叫可能會利用更多的工作空間,或者你可以嘗試傳遞一個更小的大小。規劃可能能夠適應這一點,否則可能會產生錯誤。
cutensorMgCreateCopyPlan(handle, &plan, desc, deviceWorkspaceSize, hostWorkspaceSize
最后,計劃完成后,執行copy操作。
cutensorMgCopy(handle, plan, ptrDst, ptrSrc, deviceWorkspace, hostWorkspace, streams);
在這個調用中,ptrDst和ptrSrc是指針數組。它們包含對應的張量描述符中每個設備的一個指針。在本例中,ptrDst[0]對應于作為devices[0]傳遞給cutensorMgCreateTensorDescriptor的設備。
另一方面,deviceWorkspace和streams也是數組,其中每個條目對應一個設備。它們是根據庫句柄中設備的順序排序的,例如deviceWorkspace[0]和streams[0]對應于在devices[0]傳遞給cutensorMgCreate的設備。工作空間必須至少與傳遞給cutensorMgCreateCopyPlan的工作空間大小相同。
收縮手術
cuTENSORMg 庫的核心是contraction操作。它目前實現了一個或多個設備上張量的張量收縮,但將來可能支持主機上的張量。作為復習,收縮是以下形式的操作:

其中







與copy操作一樣,它分三個階段進行:
-
cutensorMgCreateContractionDescriptor:對問題進行編碼。 -
cutensorMgCreateContractionPlan:對實現進行編碼。 -
cutensorMgContraction:使用計劃并執行實際收縮。
首先,根據張量描述符、模式列表和所需的計算類型(例如計算期間可能使用的最低精度數據)創建收縮描述符。
cutensorMgCreateContractionDescriptor(handle, &desc, descA, modesA, descB, modesB, descC, modesC, descD, modesD, compute);
由于收縮操作有更多的自由度,您還必須初始化find對象,以便更好地控制給定問題描述符的計劃創建。目前,這個find對象只有一個默認設置:
cutensorMgCreateContractionFind(handle, &find, CUTENSORMG_ALGO_DEFAULT);
然后,您可以按照為copy操作所做的操作來查詢工作空間需求。與該操作相比,您還傳入了find和workspace首選項:
cutensorMgContractionGetWorkspace(handle, desc, find, CUTENSOR_WORKSPACE_RECOMMENDED, deviceWorkspaceSize, &hostWorkspaceSize);
創建一個計劃:
cutensorMgCreateContractionPlan(handle, &plan, desc, find, deviceWorkspaceSize, hostWorkspaceSize);
最后,使用計劃執行收縮:
cutensorMgContraction(handle, plan, alpha, ptrA, ptrB, beta, ptrC, ptrD, deviceWorkspace, hostWorkspace, streams);
在這個調用中, alpha 和 beta 是與BFloat16精度,在這種情況下是single precision。不同數組ptrA、ptrB、ptrC和ptrD中指針的順序對應于它們在描述符devices數組中的順序。deviceWorkspace和streams數組中指針的順序與庫句柄的devices數組中的順序相對應。
表演
你可以在CUDA 庫樣本GitHub 回購。我們將其擴展為兩個參數: GPU 的數量和比例因子。您可以隨意嘗試其他收縮、塊大小和縮放模式。它是以這樣一種方式編寫的,即在保持 K 不變的情況下,將 M 和 N 放大。它實現了形狀的幾乎 GEMM 形狀的張量收縮:

M1和N1按比例放大,這些尺寸中的塊大小保持負載大致平衡。下圖顯示了在 DGX A100 上測量時的比例關系。
關于作者
Markus Hoehnerbach 是 cuTENSOR 和 cuTENSORMg 的高級軟件工程師。他擁有 RWTH 亞琛大學計算機科學博士學位。他感興趣的領域是結構化和非結構化張量的高性能計算及其在機器學習和計算科學中的應用。
審核編輯:郭婷
-
gpu
+關注
關注
28文章
5194瀏覽量
135431 -
機器學習
+關注
關注
66文章
8553瀏覽量
136931
發布評論請先 登錄
用網絡分析儀測量DC-DC轉換器的反饋環路特征

RNF-3000-9/3-X熱縮套管:3:1高收縮比,聚烯烴絕緣防護全解析
NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

如何通過交替式幾何處理實現更優的多核?GPU?擴展

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

【上海晶珩睿莓1開發板試用體驗】4、Coremark性能測試
如何在多顯卡環境下配置OLLAMA實現GPU負載均衡
別讓 GPU 故障拖后腿,捷智算GPU維修室來救場!

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
TMS熱收縮標識套管規格含義
電子負載的功能:CC、CV、CR模式詳解

CyberArk推出業內首款機器身份安全解決方案,為各種環境下的工作負載提供安全保障
NVIDIA虛擬GPU 18.0版本的亮點
?為什么GPU性能效率比峰值性能更關鍵



 工商網監
工商網監
評論