") YOLOX目標檢測模型的推理部署
YOLOX目標檢測模型的推理部署

YOLOX目標檢測模型
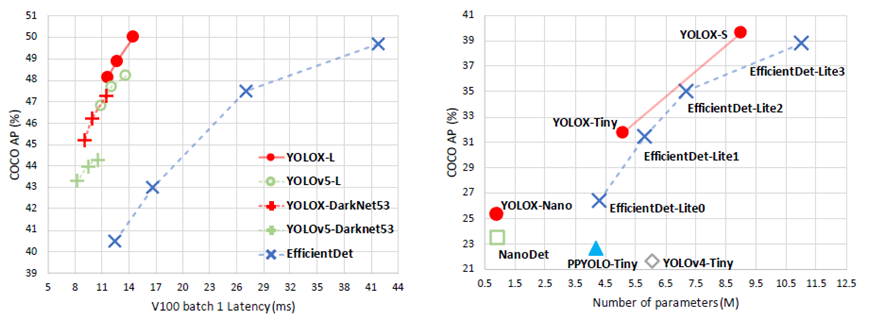
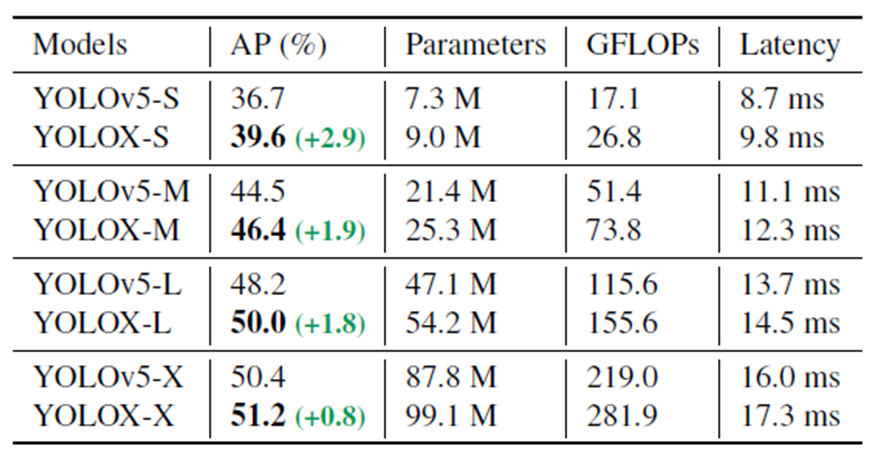
曠視科技開源了內(nèi)部目標檢測模型-YOLOX,性能與速度全面超越YOLOv5早期版本!
https://arxiv.org/pdf/2107.08430.pdfhttps://github.com/Megvii-BaseDetection/YOLOX
ONNX格式模型轉與部署
下載YOLOX的ONNX格式模型(github上可以下載)https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo/ONNXRuntimehttps://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.onnx
下載ONNX格式模型,打開之后如圖:
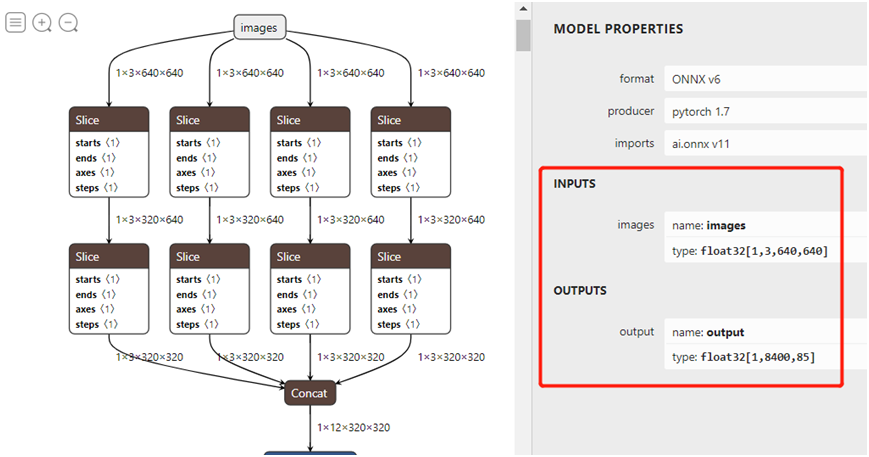
官方說明ONNX格式支持OpenVINO、ONNXRUNTIME、TensorRT三種方式,而且都提供源碼,官方提供的源碼參考如下:輸入格式:1x3x640x640,默認BGR,無需歸一化。輸出格式:1x8400x85
https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo
本人就是參考上述的代碼然后一通猛改,分別封裝成三個類,完成了統(tǒng)一接口,公用了后處理部分的代碼,基于本人筆記本的硬件資源與軟件版本:
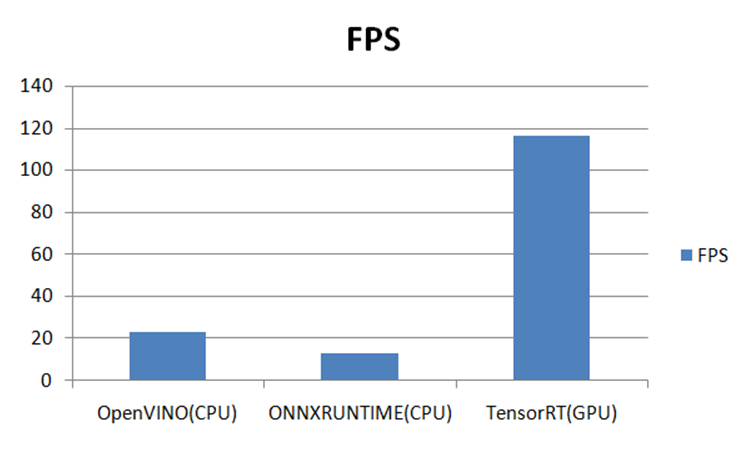
在三個推理平臺上測試結果如下:-GPU 3050Ti-CPU i7 11代-OS:Win10 64位-OpenVINO2021.4-ONNXRUNTIME:1.7-CPU-OpenCV4.5.4-Python3.6.5-YOLOX-TensorRT8.4.x

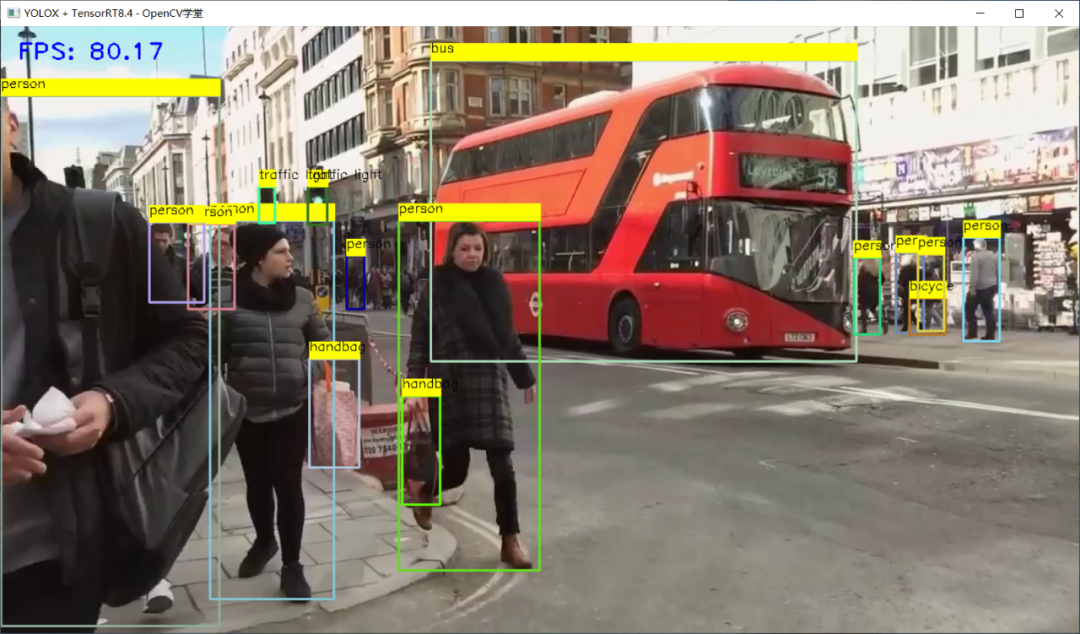
OpenVINO推理

TensorRT推理 - FP32
轉威FP16
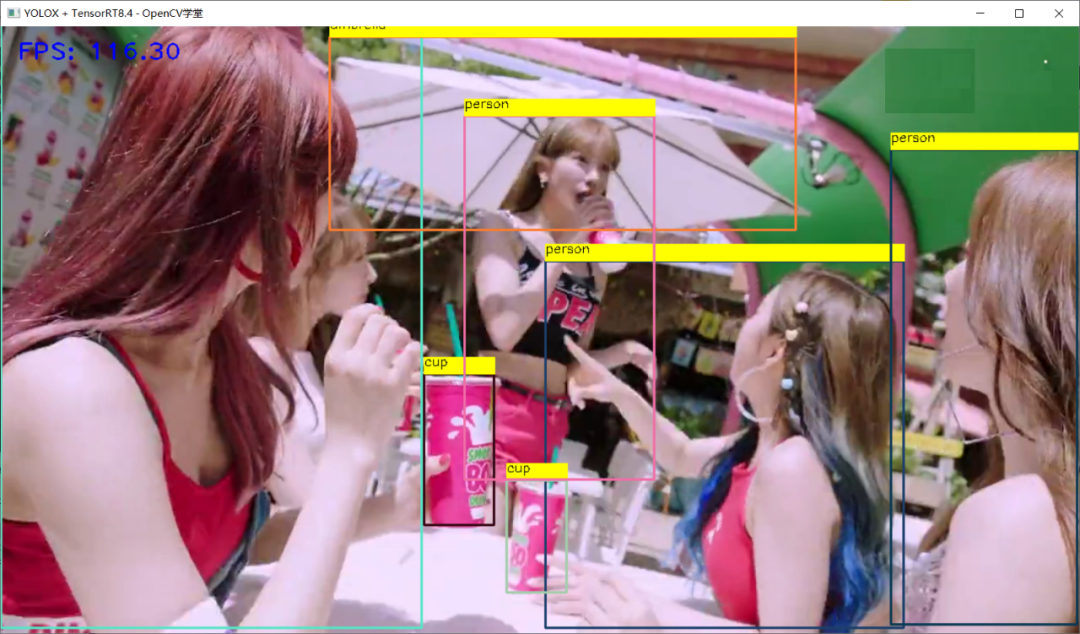
TensorRT推理 - FP16
總結
之前我寫過一篇文章比較了YOLOv5最新版本在OpenVINO、ONNXRUNTIME、OpenCV DNN上的速度比較,現(xiàn)在加上本篇比較了YOLOX在TensorRT、OpenVINO、ONNXRUNTIME上推理部署速度比較,得到的結論就是:能不改代碼,同時支持CPU跟GPU推理是ONNXRUNTIMEOpenCV DNN毫無意外的速度最慢(CPU/GPU)CPU上速度最快的是OpenVINOGPU上速度最快的是TensorRT
原文標題:YOLOX在OpenVINO、ONNXRUNTIME、TensorRT上面推理部署與速度比較
文章出處:【微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
模型
+關注
關注
1文章
3751瀏覽量
52099 -
目標檢測
+關注
關注
0文章
233瀏覽量
16492 -
OpenCV
+關注
關注
33文章
652瀏覽量
44784
原文標題:YOLOX在OpenVINO、ONNXRUNTIME、TensorRT上面推理部署與速度比較
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
熱點推薦
大模型推理服務的彈性部署與GPU調(diào)度方案
7B 模型 FP16 推理需要約 14GB 顯存,70B 模型需要 140GB+,KV Cache 隨并發(fā)數(shù)線性增長,顯存碎片化導致實際利用率不足 60%。
LLM推理模型是如何推理的?
這篇文章《(How)DoReasoningModelsReason?》對當前大型推理模型(LRM)進行了深刻的剖析,超越了表面的性能宣傳,直指其技術本質(zhì)和核心局限。以下是基于原文的詳細技術原理、關鍵

AI端側部署開發(fā)(SC171開發(fā)套件V3)2026版
AI端側部署開發(fā)(SC171開發(fā)套件V3)2026版
序列
課程名稱
視頻課程時長
視頻課程鏈接
課件鏈接
工程源碼
1
Fibo AI Stack模型轉化指南
27分19秒
https
發(fā)表于 01-15 10:31
NVIDIA TensorRT LLM 1.0推理框架正式上線
TensorRT LLM 作為 NVIDIA 為大規(guī)模 LLM 推理打造的推理框架,核心目標是突破 NVIDIA 平臺上的推理性能瓶頸。為實現(xiàn)這一目
廣和通發(fā)布端側目標檢測模型FiboDet
為提升端側設備視覺感知與決策能力,廣和通全自研端側目標檢測模型FiboDet應運而生。該模型基于廣和通在邊緣計算與人工智能領域的深度積累,面向工業(yè)、交通、零售等多個行業(yè)提供高性能、低功
什么是AI模型的推理能力
NVIDIA 的數(shù)據(jù)工廠團隊為 NVIDIA Cosmos Reason 等 AI 模型奠定了基礎,該模型近日在 Hugging Face 的物理推理模型排行榜中位列榜首。
使用aicube進行目標檢測識別數(shù)字項目的時候,在評估環(huán)節(jié)卡住了,怎么解決?
使用aicube進行目標檢測識別數(shù)字項目的時候,前面一切正常
但是在評估環(huán)節(jié)卡住了,一直顯示正在測試,但是完全沒有測試結果,
在部署完模型后在k230上運行也沒有任何識別結果
期
發(fā)表于 08-13 06:45
基于米爾瑞芯微RK3576開發(fā)板部署運行TinyMaix:超輕量級推理框架
本文將介紹基于米爾電子MYD-LR3576開發(fā)平臺部署超輕量級推理框架方案:TinyMaix
摘自優(yōu)秀創(chuàng)作者-短笛君
TinyMaix 是面向單片機的超輕量級的神經(jīng)網(wǎng)絡推理庫,即 TinyML
發(fā)表于 07-25 16:35
如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
TensorRT-LLM 作為 NVIDIA 專為 LLM 推理部署加速優(yōu)化的開源庫,可幫助開發(fā)者快速利用最新 LLM 完成應用原型驗證與產(chǎn)品部署。
大模型推理顯存和計算量估計方法研究
隨著人工智能技術的飛速發(fā)展,深度學習大模型在各個領域得到了廣泛應用。然而,大模型的推理過程對顯存和計算資源的需求較高,給實際應用帶來了挑戰(zhàn)。為了解決這一問題,本文將探討大模型
發(fā)表于 07-03 19:43
基于LockAI視覺識別模塊:C++目標檢測
快速部署高性能的目標檢測應用。
特點:
高性能:優(yōu)化了推理速度,在保持高精度的同時實現(xiàn)了快速響應。
靈活性:支持多種預訓練模型,可以根據(jù)具體
發(fā)表于 06-06 14:43
基于RK3576開發(fā)板的RKLLM大模型部署教程
Runtime則負責加載轉換后的模型,并在Rockchip NPU上進行推理,用戶可以通過自定義回調(diào)函數(shù)實時獲取推理結果。
開發(fā)流程分為模型轉換和板端
labview調(diào)用yolo目標檢測、分割、分類、obb
labview調(diào)用yolo目標檢測、分割、分類、obb、pose深度學習,支持CPU和GPU推理,32/64位labview均可使用。
(yolov5~yolov12)
發(fā)表于 03-31 16:28
【幸狐Omni3576邊緣計算套件試用體驗】RKNN 推理測試與圖像識別
本節(jié)介紹了 RKNN 推理測試的相關流程,包括 rknn_model_zoo 模型部署、編譯及板端測試。
rknn_model_zoo
rknn_model_zoo 是瑞芯微官方提供的 RKNPU 支持
發(fā)表于 03-20 16:14



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論