") NVIDIA CUDA C ++編譯器的新特性
NVIDIA CUDA C ++編譯器的新特性

CUDA 11 . 5 C ++編譯器解決了不斷增長的客戶請求。具體來說,如何減少 CUDA 應(yīng)用程序構(gòu)建時間。除了消除未使用的內(nèi)核外, NVRTC 和 PTX 并發(fā)編譯有助于解決這個關(guān)鍵問題 CUDA C ++應(yīng)用程序開發(fā)的關(guān)注點。
CUDA 11 . 5 NVCC 編譯器現(xiàn)在添加了對 Clang 12 . 0 作為主機編譯器的支持。我們還提供了 128 位整數(shù)支持的有限預(yù)覽版本,這在高保真計算中變得至關(guān)重要。
CUDA C ++編譯器工具鏈上的技術(shù)演練補充了編程指南(需要鏈接),并提供了在 CUDA 11 . 5 工具包版本中引入的新特性的廣泛概述。
并發(fā)編譯
NVRTC 編譯過程分為三個主要階段:
Parser -> NVVM optimizer -> PTX Compiler
其中一些階段不是線程安全的,因此 NVRTC 以前會使用全局鎖序列化來自多個用戶線程的并發(fā)編譯請求。
在 CUDA 11 . 5 中,對 NVRTC 實現(xiàn)進行了增強,以提供部分并發(fā)編譯支持。這是通過移除全局鎖和使用每階段鎖來實現(xiàn)的,這會導(dǎo)致不同的線程并發(fā)執(zhí)行編譯管道的不同階段。
圖 1 顯示了 CUDA 11 . 5 之前的 NVRTC 如何序列化來自四個線程的同時編譯請求。
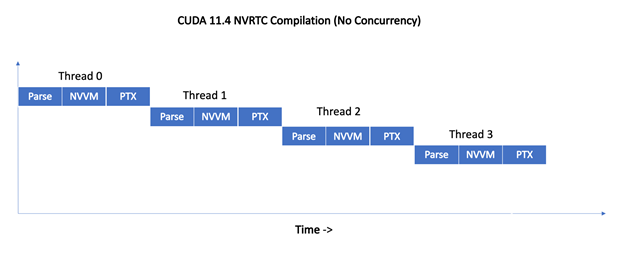
圖 1 。序列化編譯
對于 11 . 5 , NVRTC 不會序列化編譯請求。相反,來自不同線程的編譯請求是管道化的,從而使編譯管道的不同階段能夠同時進行。
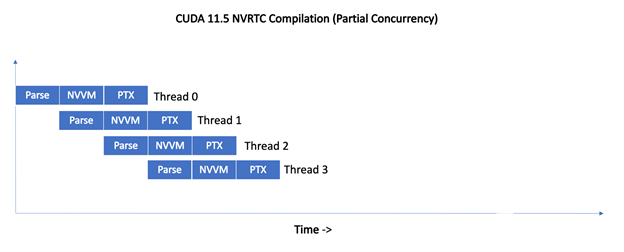
圖 2 。并發(fā)編譯
圖 3 中的圖表顯示了編譯一組 100 個相同的示例 NVRTC 程序的總編譯時間,這些程序按可用線程數(shù)進行劃分。
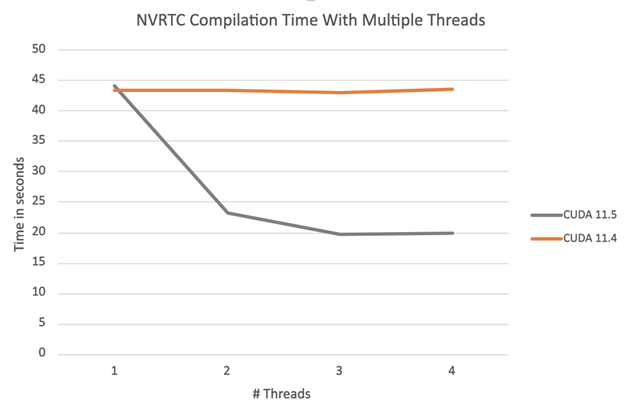
圖 3 。 CUDA 11 . 4 和 11 . 5 的編譯時間比較
正如所料,對于 CUDA 11 . 4 NVRTC ,總編譯時間不會隨著線程數(shù)的增加而改變,而編譯是使用全局 NVRTC 鎖序列化的。使用 CUDA 11 . 5 NVRTC ,總編譯時間會隨著線程數(shù)的增加而減少。我們將繼續(xù)使單個 stage 線程更安全,這將為本例實現(xiàn)近乎線性的加速。
PTX 并發(fā)編譯
沿著 JIT 編譯路徑進行 PTX 編譯,以及使用 PTX 靜態(tài)庫進行多個內(nèi)部階段。這些階段以前的實現(xiàn)不能保證從多個線程進行并發(fā)編譯。相反, PTX 編譯器使用全局鎖來序列化并發(fā)編譯。
在 CUDA 11 . 5 和 R495 驅(qū)動程序中, PTX 編譯器實現(xiàn)現(xiàn)在使用更細粒度的本地鎖,而不是全局鎖。這允許并發(fā)執(zhí)行多個編譯請求,并顯著縮短了編譯時間。
下圖顯示了編譯 104 個相同的示例程序所需的總編譯時間,這些程序在給定數(shù)量的線程上拆分到cuLinkAddData使用CU_JIT_INPUT_PTX作為CUjitInputType。
正如 R470 CUDA 驅(qū)動程序所預(yù)期的那樣,總編譯時間不會隨著線程數(shù)的增加而改變,因為編譯是用全局鎖序列化的。使用 R495 CUDA 驅(qū)動程序,總編譯時間隨著線程數(shù)的增加而減少。
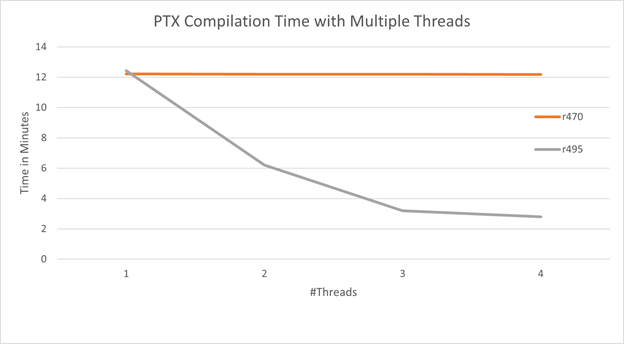
圖 4 。 CUDA 11 . 4 和 11 . 5 的 PTX 并發(fā)編譯比較
消除未使用的內(nèi)核
單獨編譯模式允許 CUDA 內(nèi)核函數(shù)和設(shè)備函數(shù)作為 CUDA 設(shè)備代碼庫發(fā)布,并使用設(shè)備鏈接器 NVLink 針對任何用戶應(yīng)用程序進行鏈接。然后在運行時在 GPU 上加載并執(zhí)行生成的設(shè)備程序。
在 CUDA 11 . 5 之前, NVLink 無法確定從鏈接設(shè)備程序中刪除未使用的內(nèi)核是否安全,因為這些內(nèi)核函數(shù)可以從主機代碼中引用。
考慮一個定義四個內(nèi)核函數(shù)的庫:
//library.cu
__global__ void AAA() { /* code */ }
__global__ void BBB() { /* code */ }
__global__ void CCC() { /* code */ }
__global__ void DDD() { /* code */ }
該庫的構(gòu)建和發(fā)布:
$nvcc -rdc=true library.cu -lib -o testlib.a
用戶代碼引用庫中的單個內(nèi)核:
//user.cu
extern __global__ void AAA();
int main() { AAA<<<1,1>>>(); }
代碼鏈接為:
$nvcc -rdc=true user.cu testlib.a -o user
以 CUDA 11 . 4 為例,鏈接設(shè)備程序?qū)兴膫€內(nèi)核體,即使鏈接設(shè)備程序中只使用一個內(nèi)核(“ AAA ”)。對于鏈接到較大庫的應(yīng)用程序來說,這可能是一個負擔。
增加的二進制大小和應(yīng)用程序加載時間并不是冗余設(shè)備代碼的唯一問題。當使用設(shè)備鏈接時間優(yōu)化(DLTO –修復(fù)鏈接)時,在優(yōu)化之前未刪除的未使用內(nèi)核可能會導(dǎo)致更長的構(gòu)建時間,并可能阻礙代碼優(yōu)化。
使用 CUDA 11 . 5 , CUDA 編譯器將跟蹤主機代碼中對內(nèi)核的引用,并將此信息傳播到設(shè)備鏈接器( NVLink )。 NVLink 然后從鏈接的設(shè)備程序中刪除未使用的內(nèi)核。對于前面的示例,未使用的內(nèi)核 BBB 、 CCC 和 DDD 將從鏈接設(shè)備程序中刪除。
在 CUDA 11 . 5 中,默認情況下禁用此優(yōu)化,但可以通過將-Xnvlink -use-host-info選項添加到 NVCC 命令行來啟用:
$nvcc -rdc=true user.cu testlib.a -o user -Xnvlink -use-host-info
在隨后的 CUDA 工具包版本中,默認情況下將啟用優(yōu)化,并提供一個退出標志。
這里有一些警告。在 CUDA 11 . 5 中,編譯器對內(nèi)核引用的分析在以下情況下是保守的。編譯器可以考慮一些未從宿主代碼實際引用的內(nèi)核,如:
- 如果模板實例化是從主機代碼引用的,則該模板的所有實例都被視為是從主機代碼引用的。
template
__global__ void foo() { }
__device__ void doit() { foo<<<1,1>>>(); }
int main() {
// compiler will mark all instances of foo template as referenced
// from host code, including "foo", which is only actually
// referenced from device code
foo<<<1,1>>>();
}
-
__global__ or __device__函數(shù)體之外的任何引用都被視為主機代碼引用。
__global__ void foo() { }
__device__ auto *ptr = foo; // foo is considered as referenced
// from host code.
- 當對函數(shù)的引用為template-dependent時,具有該名稱的所有內(nèi)核都被視為主機引用。
__global__ void foo(int) { }
namespace N1 {
template
__global__ void foo(T) { }
}
template
void doit() {
// the reference to 'foo' is template dependent, so
// both ::foo and all instances of ::N1::foo are
// considered as referenced from host code.
foo<<<1,1>>>(T{});
}
另一個警告是,當設(shè)備鏈接步驟推遲到主機應(yīng)用程序啟動( JIT 鏈接)時,而不是在構(gòu)建時,將不會刪除未使用的內(nèi)核。
// With nonvirtual architecture (sm_80), NVLink is invoked
// at build time, and kernel pruning will occur.
$nvcc -Xnvlink -use-host-info -rdc=true foo.cu bar.cu -o foo -arch sm_80
// With virtual architecture (compute_80), NVLink is not invoked
// at build time, but only during host application startup.
// kernel pruning will not occur.
$nvcc -Xnvlink -use-host-info -rdc=true foo.cu bar.cu -o foo -arch compute_80
今后的工作
在 CUDA 11 . 5 中, NVLink 在設(shè)備鏈接時間優(yōu)化( DLTO – FIXME link )期間尚未使用有關(guān)未使用內(nèi)核的信息。我們的目標是使 NVLink 能夠使用此信息刪除未使用的內(nèi)核,減少優(yōu)化器時間,并通過減少代碼膨脹來提高生成的代碼質(zhì)量。
有限的 128 位整數(shù)支持
11 . 5 CUDA C ++編譯器支持主機編譯器支持 128 位整數(shù)的平臺的 128 位整數(shù)數(shù)據(jù)類型。基本的算術(shù)、邏輯和位運算將在 128 位整數(shù)上工作。未來版本計劃支持?CUDA 固有類型和?CUDA 數(shù)學(xué)函數(shù)的 128 位整數(shù)變體。
類似地,對 128 位整數(shù)的調(diào)試支持以及與開發(fā)人員工具的集成將在后續(xù)版本中提供。目前,我們正在開發(fā)者論壇上尋求您對此預(yù)覽功能的早期反饋。
NVRTC 靜態(tài)庫
CUDA 11 . 5 提供了 NVRTC 庫的靜態(tài)版本。一些應(yīng)用程序可能更喜歡鏈接靜態(tài) NVRTC 庫,以保證部署期間的穩(wěn)定性能和功能。靜態(tài)庫用戶還希望靜態(tài)鏈接 NVRTC 內(nèi)置庫和 PTX 編譯器庫的靜態(tài)版本。有關(guān)鏈接靜態(tài) NVRTC 庫的更多信息,請參閱NVRTC 用戶指南。
__builtin_assume
CUDA 11 . 5 改進了__builtin_assume應(yīng)用于__isShared(pointer)等地址空間謂詞函數(shù)的結(jié)果時加載和存儲的代碼生成。有關(guān)其他支持的功能,請參閱地址空間謂詞函數(shù)。
如果沒有地址空間說明符,編譯器將生成通用加載和存儲指令,這需要一些額外的指令來計算特定的內(nèi)存段,然后再執(zhí)行實際的內(nèi)存操作。使用__builtin_assume(expr)提示編譯器使用泛型指針的地址空間,這可能會提高代碼的性能。
Correct Usage:
bool b = __isShared(ptr);
__builtin_assume(b); // OK: Proof that ptr is a pointer to shared memory
Incorrect Usage:
These hints are ignored unless the boolean expression is stored in a separate variable:
__builtin_assume(__isShared(ptr)); // IGNORED
與其他__builtin_assume一樣,如果表達式不為 TRUE ,則行為未定義。如果您有興趣了解__builtin_assume的更多信息,請參閱?CUDA 11 . 2 編譯器文章。
Pragma 診斷控制
在 CUDA 11 . 5 中, NVCC CUDA 編譯器前端增加了對大量雜注的支持,這些雜注提供了對診斷消息的更多控制。
您可以使用以下雜注來控制特定錯誤號的編譯器診斷:
#pragma nv_diag_suppress // suppress the specified diagnostic
// message
#pragma nv_diag_warning // make the specified diagnostic a warning
#pragma nv_diag_error // make the specified diagnostic an error
#pragma nv_diag_default // restore the specified diagnostic level
// to default
#pragma nv_diag_once // only report the specified diagnostic once
Uses of these pragmas have the following form:
#pragma nv_diag_xxx error_number, error_number …
要了解如何使用這些帶有更詳細警告的雜注,請參閱?CUDA 內(nèi)部編程指南。以下示例將取消foo的 Clara 選項上的“declared but never referenced”警告:
#pragma nv_diag_suppress 177
void foo()
{
int xxx=0;
}
雜注nv_diagnostic推送和nv_diagnostic彈出可用于保存和恢復(fù)當前診斷pragma狀態(tài):
#pragma nv_diagnostic push
#pragma nv_diag_suppress 177
void foo()
{
int xxx=0;
}
#pragma nv_diagnostic pop
void bar()
{
int xxx=0;
}
這些雜注都不會對主機編譯器產(chǎn)生任何影響。
不推薦使用注意:不帶nv_前綴的診斷雜注已不推薦使用。例如,#pragma diag_suppress支持將從所有未來版本中刪除。使用這些診斷標記將引發(fā)如下警告消息:
pragma "diag_suppress" is deprecated, use "nv_diag_suppress" instead
宏__NVCC_DIAG_PRAGMA_SUPPORT__有助于過渡到使用新宏:
#ifdef __NVCC_DIAG_PRAGMA_SUPPORT__
#pragma nv_diag_suppress 177
#else
#pragma diag_suppress 177
#endif
新選項 -arch = all | all major
在 CUDA 11 . 5 版本之前,如果您想為所有受支持的體系結(jié)構(gòu)生成代碼,必須在--generate-code選項中列出所有目標。如果添加了較新的版本,或舊版本失效,則必須相應(yīng)地更改--generate-code選項。現(xiàn)在,新選項-arch=all|all-major提供了一種更簡單、更高效的方法。
如果指定了-arch=all, NVCC 將為所有受支持的體系結(jié)構(gòu)(sm_*)嵌入編譯后的代碼映像,并為最高的主要虛擬體系結(jié)構(gòu)嵌入 PTX 程序。
如果指定了-arch=all-major, NVCC 將為所有受支持的主要版本(sm_*0)嵌入編譯后的代碼映像,從最早受支持的sm_x體系結(jié)構(gòu)(此版本為sm_35)開始,并為最高的主要虛擬體系結(jié)構(gòu)嵌入 PTX 程序。
例如,簡單的-arch=all選項相當于此版本的以下一長串選項:
-gencode arch=compute_35,"code=sm_35"
-gencode arch=compute_37,"code=sm_37"
-gencode arch=compute_50,"code=sm_50"
-gencode arch=compute_52,"code=sm_52"
-gencode arch=compute_53,"code=sm_53"
-gencode arch=compute_60,"code=sm_60"
-gencode arch=compute_61,"code=sm_61"
-gencode arch=compute_62,"code=sm_62"
-gencode arch=compute_70,"code=sm_70"
-gencode arch=compute_72,"code=sm_72"
-gencode arch=compute_75,"code=sm_75"
-gencode arch=compute_80,"code=sm_80"
-gencode arch=compute_86,"code=sm_86"
-gencode arch=compute_87,"code=sm_87"
-gencode arch=compute_80,"code=compute_80"
簡單的-arch=all-major選項相當于此版本的以下一長串選項:
-gencode arch=compute_35,"code=sm_35"
-gencode arch=compute_50,"code=sm_50"
-gencode arch=compute_60,"code=sm_60"
-gencode arch=compute_70,"code=sm_70"
-gencode arch=compute_80,"code=sm_80"
-gencode arch=compute_80,"code=compute_80"
有關(guān)所有受支持的虛擬體系結(jié)構(gòu),請參閱虛擬體系結(jié)構(gòu)功能列表。有關(guān)所有受支持的真實體系結(jié)構(gòu),請參閱?GPU 功能列表。
確定性代碼生成
在以前的 CUDA 工具包中,設(shè)備代碼中內(nèi)部鏈接變量或函數(shù)的名稱在每次 nvcc 調(diào)用時都會更改,即使源代碼沒有更改。某些軟件管理和構(gòu)建系統(tǒng)檢查生成的程序位是否已更改。先前的 nvcc 編譯器行為導(dǎo)致此類系統(tǒng)觸發(fā),并錯誤地假設(shè)源程序中存在語義更改;例如,可能觸發(fā)冗余的依賴生成。
在 CUDA 11 . 5 中, NVCC 編譯器行為已更改為確定性。例如,考慮這個測試用例:
//--
static __device__ void foo() { }
auto __device__ fptr = foo;
int main() { }
//--
在 CUDA 11 . 4 中,兩次編譯同一程序會在 PTX 中生成稍微不同的名稱:
//--
$cuda-11.4/bin/nvcc -std=c++14 -rdc=true -ptx test.cu -o test1.ptx
$cuda-11.4/bin/nvcc -std=c++14 -rdc=true -ptx test.cu -o test2.ptx
$diff -w test1.ptx test2.ptx
13c13
< .func _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv
---
> .func _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv
16c16
< .visible .global .align 8 .u64 fptr = _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv;
---
> .visible .global .align 8 .u64 fptr = _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv;
18c18
< .func _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv()
---
> .func _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv()
$
//--
使用 CUDA 11 . 5 ,兩次編譯同一程序會生成相同的 PTX :
//--
$nvcc -std=c++14 -rdc=true -ptx test.cu -o test1.ptx
$nvcc -std=c++14 -rdc=true -ptx test.cu -o test2.ptx
$diff -w test1.ptx test2.ptx
$
//--
結(jié)論
通過閱讀在 CUDA 11 . 5 工具包中展示新功能文章,了解更多關(guān)于 CUDA 11 . 5 工具包的信息。
關(guān)于作者
Arthy Sundaram 是 CUDA 平臺的技術(shù)產(chǎn)品經(jīng)理。她擁有哥倫比亞大學(xué)計算機科學(xué)碩士學(xué)位。她感興趣的領(lǐng)域是操作系統(tǒng)、編譯器和計算機體系結(jié)構(gòu)。
Jaydeep Marathe 是 NVIDIA 的高級編譯工程師。他擁有北卡羅來納州立大學(xué)計算機科學(xué)碩士和博士學(xué)位。
Hari Sandanagobalane 是 NVIDIA 的高級編譯工程師。他擁有新加坡國立大學(xué)計算機科學(xué)碩士學(xué)位。
Mike Murphy 是 NVIDIA 的高級編譯工程師。
Xiaohua Zhang 是 NVIDIA 的高級編譯工程師。他擁有清華大學(xué)計算機科學(xué)碩士學(xué)位。
Girish Bharambe 是 NVIDIA 的高級編譯經(jīng)理。他擁有印度浦那大學(xué)計算機工程學(xué)士學(xué)位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5592瀏覽量
109721 -
代碼
+關(guān)注
關(guān)注
30文章
4967瀏覽量
73960
發(fā)布評論請先 登錄
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

C編譯器錯誤與解決方法
NVIDIA CUDA Tile的創(chuàng)新之處、工作原理以及使用方法

在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA CUDA 13.1版本的新增功能與改進
開源鴻蒙技術(shù)大會2025丨編譯器與編程語言分論壇:語言驅(qū)動系統(tǒng)創(chuàng)新,編譯賦能生態(tài)繁榮

rtsmart開啟C++特性支持后,工具鏈編譯內(nèi)核不通過怎么解決?
GCC編譯器,怎么才能實現(xiàn)c文件中未被調(diào)用的函數(shù),不會被編譯呢?
進迭時空同構(gòu)融合RISC-V AI CPU的Triton算子編譯器實踐




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論