") 利用NVIDIA CUDA 11 . 2優(yōu)化GPU應(yīng)用性能
利用NVIDIA CUDA 11 . 2優(yōu)化GPU應(yīng)用性能

CUDA 11 . 2 的特點(diǎn)是在 GPU 加速應(yīng)用程序中為設(shè)備代碼提供強(qiáng)大的鏈路時(shí)間優(yōu)化( LTO )功能。 Device LTO 將設(shè)備代碼優(yōu)化的性能優(yōu)勢(只有在 nvcc 整個(gè)程序編譯模式下才可能)帶到了 CUDA 5 . 0 中引入的 nvcc 單獨(dú)編譯模式。
單獨(dú)編譯模式允許 CUDA 設(shè)備內(nèi)核代碼跨多個(gè)源文件,而在整個(gè)程序編譯模式下,程序中的所有 CUDA 設(shè)備內(nèi)核代碼都必須位于單個(gè)源文件中。獨(dú)立編譯模式將源代碼模塊化引入設(shè)備內(nèi)核代碼,因此是提高開發(fā)人員生產(chǎn)率的重要步驟。獨(dú)立的編譯模式使開發(fā)人員能夠更好地設(shè)計(jì)和組織設(shè)備內(nèi)核代碼,并使 GPU 加速許多現(xiàn)有的應(yīng)用程序,而無需進(jìn)行大量的代碼重構(gòu)工作,即可將所有設(shè)備內(nèi)核代碼移動(dòng)到單個(gè)源文件中。它還提高了大型并行應(yīng)用程序開發(fā)的開發(fā)人員的生產(chǎn)效率,只需要重新編譯帶有增量更改的設(shè)備源文件。
CUDA 編譯器優(yōu)化的范圍通常限于正在編譯的每個(gè)源文件。在單獨(dú)的編譯模式下,編譯時(shí)優(yōu)化的范圍可能會(huì)受到限制,因?yàn)榫幾g器無法看到源文件之外引用的任何設(shè)備代碼,因?yàn)榫幾g器無法利用跨越文件邊界的優(yōu)化機(jī)會(huì)。
相比之下,在整個(gè)程序編譯模式下,程序中存在的所有設(shè)備內(nèi)核代碼都位于同一源文件中,消除了任何外部依賴關(guān)系,并允許編譯器執(zhí)行在單獨(dú)編譯模式下不可能執(zhí)行的優(yōu)化。因此,在整個(gè)程序編譯模式下編譯的程序通常比在單獨(dú)編譯模式下編譯的程序性能更好。
使用 CUDA 11 . 0 中預(yù)覽的設(shè)備鏈接時(shí)間優(yōu)化( LTO ),可以獲得單獨(dú)編譯的源代碼模塊化以及設(shè)備代碼整個(gè)程序編譯的運(yùn)行時(shí)性能。雖然編譯器在優(yōu)化單獨(dú)編譯的 CUDA 源文件時(shí)可能無法進(jìn)行全局優(yōu)化的代碼轉(zhuǎn)換,但鏈接器更適合這樣做。
與編譯器相比,鏈接器具有正在構(gòu)建的可執(zhí)行文件的整個(gè)程序視圖,包括來自多個(gè)源文件和庫的源代碼和符號(hào)。可執(zhí)行文件的整個(gè)程序視圖使鏈接器能夠選擇最適合單獨(dú)編譯的程序的性能優(yōu)化。此設(shè)備鏈接時(shí)間優(yōu)化由鏈接器執(zhí)行,是 CUDA 11 . 2 中 nvlink 實(shí)用程序的一個(gè)功能。具有多個(gè)源文件和庫的應(yīng)用程序現(xiàn)在可以通過 GPU 進(jìn)行加速,而不會(huì)影響單獨(dú)編譯模式下的性能。
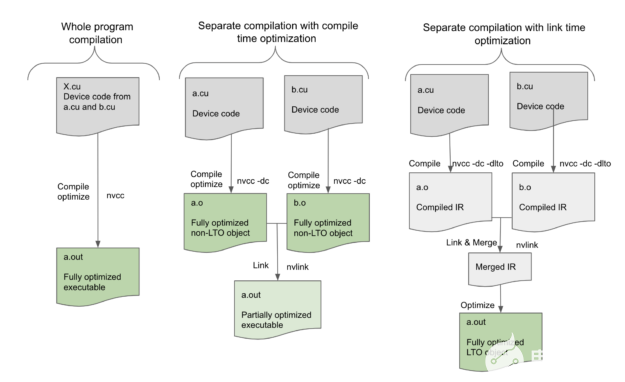
圖 1 。不同編程模式下編譯時(shí)和鏈接時(shí)優(yōu)化過程的比較。
圖 1 ,在 nvcc 全程序編譯模式下,要在單個(gè)源文件 X . cu 中編譯的設(shè)備程序,沒有任何未解析的外部設(shè)備函數(shù)或變量引用,可以在編譯時(shí)由編譯器完全優(yōu)化。然而,在單獨(dú)的編譯模式下,編譯器只能優(yōu)化正在編譯的單個(gè)源文件中的設(shè)備代碼,而最終的可執(zhí)行文件沒有盡可能優(yōu)化,因?yàn)榫幾g器無法執(zhí)行跨源文件的更多優(yōu)化。設(shè)備鏈接時(shí)間優(yōu)化通過將優(yōu)化推遲到鏈接步驟來彌補(bǔ)這一差距。
在設(shè)備 LTO 模式下,我們?yōu)槊總€(gè)翻譯單元存儲(chǔ)代碼的高級(jí)中間形式,然后在鏈接時(shí)合并所有這些中間形式以創(chuàng)建所有設(shè)備代碼的高級(jí)表示。這使鏈接器能夠執(zhí)行高級(jí)優(yōu)化,例如跨文件邊界內(nèi)聯(lián),這不僅消除了調(diào)用約定的開銷,還進(jìn)一步支持對內(nèi)聯(lián)代碼塊本身進(jìn)行其他優(yōu)化。鏈接器還可以利用已完成的偏移量。例如,共享內(nèi)存分配是最終確定的,并且數(shù)據(jù)偏移量僅在鏈路時(shí)間已知,因此設(shè)備鏈路時(shí)間優(yōu)化現(xiàn)在可以使諸如設(shè)備代碼的恒定傳播或折疊之類的低級(jí)優(yōu)化成為可能。即使函數(shù)沒有內(nèi)聯(lián),鏈接器仍然可以看到調(diào)用的兩面,以優(yōu)化調(diào)用約定。因此,可以通過設(shè)備鏈路時(shí)間優(yōu)化來提高為單獨(dú)編譯的程序生成的代碼的質(zhì)量,并且其性能與以整個(gè)程序模式編譯的程序一樣。
為了了解單獨(dú)編譯的局限性以及設(shè)備 LTO 可能帶來的性能提升,讓我們看一個(gè) MonteCarlo 基準(zhǔn)測試中的示例
I 在下面的示例代碼中, MC_Location:: get_domain 不是在另一個(gè)文件中定義的標(biāo)準(zhǔn)編譯模式中內(nèi)聯(lián)的,而是
使用 CUDA 11 . 2 中的設(shè)備鏈路優(yōu)化內(nèi)聯(lián)
__device__ void MCT_Reflect_Particle(MonteCarlo *monteCarlo, MC_Particle &particle){ MC_Location location = particle.Get_Location(); const MC_Domain &domain = location.get_domain(monteCarlo); ... ... /* uses domain */ }
函數(shù) get \ u domain 是另一個(gè)類的一部分,因此在另一個(gè)文件中定義它是有意義的。但是在單獨(dú)的編譯模式下,編譯器在調(diào)用 get \ u domain ()時(shí)將不知道它做什么,甚至不知道它存在于何處,因此編譯器無法內(nèi)聯(lián)該函數(shù),必須隨參數(shù)一起發(fā)出調(diào)用并返回處理,同時(shí)也節(jié)省空間的事情,如回郵地址后,呼吁。這又使得它無法潛在地優(yōu)化使用域值的后續(xù)語句。在設(shè)備 LTO 模式下, get \ u domain ()可以完全內(nèi)聯(lián),編譯器可以執(zhí)行更多優(yōu)化,從而消除調(diào)用約定的代碼,并啟用基于域值的優(yōu)化。
簡而言之,設(shè)備 LTO 將所有性能優(yōu)化都引入到單獨(dú)的編譯模式中,而以前只有在整個(gè)程序編譯模式中才可用。
使用設(shè)備 LTO
要使用設(shè)備 LTO ,請將選項(xiàng) -dlto 添加到編譯和鏈接命令中,如下所示。從這兩個(gè)步驟中跳過 -dlto 選項(xiàng)會(huì)影響結(jié)果。
使用-dlto選項(xiàng)編譯 CUDA 源文件:
nvcc -dc -dlto *.cu
使用-dlto選項(xiàng)鏈接 CUDA 對象文件:
nvcc -dlto *.o
在編譯時(shí)使用 -dlto 選項(xiàng)指示編譯器將正在編譯的設(shè)備代碼的高級(jí)中間表示( NVVM-IR )存儲(chǔ)到 fatbinary 中。在鏈接時(shí)使用 -dlto 選項(xiàng)將指示鏈接器從所有鏈接對象檢索 NVVM IR ,并將它們合并到一個(gè) IR 中并執(zhí)行優(yōu)化在生成的 IR 上生成代碼。設(shè)備 LTO 與任何支持的 SM 架構(gòu)目標(biāo)一起工作。
對現(xiàn)有庫使用設(shè)備 LTO
設(shè)備 LTO 只有在編譯和鏈接步驟都使用 -dlto 時(shí)才能生效。如果 -dlto 在編譯時(shí)使用,而不是在鏈接時(shí)使用,則在鏈接時(shí)每個(gè)對象都被單獨(dú)編譯到 SASS ,然后作為正常鏈接,沒有任何優(yōu)化機(jī)會(huì)。如果 -dlto 在鏈接時(shí)使用,而不是在編譯時(shí)使用,然后鏈接器找不到要執(zhí)行 LTO 的中間表示,并跳過直接鏈接對象的優(yōu)化步驟。
如果包含設(shè)備代碼的所有對象都是用 -dlto 構(gòu)建的,那么 Device LTO 工作得最好。但是,即使只有一些對象使用 -dlto ,它仍然可以使用,如圖 2 所示。

圖 2 :使用非 LTO 庫進(jìn)行單獨(dú)編譯和設(shè)備鏈接時(shí)間優(yōu)化。
在這種情況下,在鏈接時(shí),使用 -dlto 構(gòu)建的對象鏈接在一起形成一個(gè)可重定位對象,然后與其他非 LTO 對象鏈接。這不會(huì)提供最佳性能,但仍然可以通過在 LTO 對象內(nèi)進(jìn)行優(yōu)化來提高性能。此功能允許使用 -dlto ,即使外部庫不是用 -dlto 構(gòu)建的;這只是意味著庫代碼不能從設(shè)備 LTO 中獲益。
每體系結(jié)構(gòu)的細(xì)粒度設(shè)備鏈路優(yōu)化支持
全局 -dlto 選項(xiàng)適用于編譯單個(gè)目標(biāo)體系結(jié)構(gòu)。
使用 -gencode 為多個(gè)體系結(jié)構(gòu)編譯時(shí),請確切指定要存儲(chǔ)到 fat 二進(jìn)制文件中的中間產(chǎn)物。例如,要在可執(zhí)行文件中存儲(chǔ) Volta SASS 和 Ampere PTX ,您當(dāng)前可以使用以下選項(xiàng)進(jìn)行編譯:
nvcc -gencode arch=compute_70,code=sm_70 -gencode arch=compute_80,code=compute_80
使用一個(gè)新的代碼目標(biāo) lto_70 ,您可以獲得細(xì)粒度的控制,以指示哪個(gè)目標(biāo)體系結(jié)構(gòu)應(yīng)該存儲(chǔ) LTO 中介體,而不是 SASS 或 PTX 。例如,要存儲(chǔ) Volta LTO 和 Ampere PTX ,可以使用以下代碼示例進(jìn)行編譯:
nvcc -gencode arch=compute_70,code=lto_70 -gencode arch=compute_80,code=compute_80
績效結(jié)果
設(shè)備 LTO 會(huì)對性能產(chǎn)生什么樣的影響?
gpu 對內(nèi)存流量和寄存器壓力非常敏感。因此,設(shè)備優(yōu)化通常比相應(yīng)的主機(jī)優(yōu)化影響更大。正如預(yù)期的那樣,我們觀察到許多應(yīng)用受益于設(shè)備 LTO 。通常,通過設(shè)備 LTO 的加速比取決于 CUDA 應(yīng)用特性。
圖 3 和圖 4 顯示了一個(gè)內(nèi)部基準(zhǔn)應(yīng)用程序和另一個(gè)實(shí)際應(yīng)用程序的運(yùn)行時(shí)性能和構(gòu)建時(shí)間的比較圖,這兩個(gè)應(yīng)用程序都采用三種編譯模式:
- 全程序編譯
- 不帶設(shè)備 LTO 的單獨(dú)編譯
- 使用設(shè)備 LTO 模式單獨(dú)編譯
我們測試的客戶應(yīng)用程序有一個(gè)占運(yùn)行時(shí) 80% 以上的主計(jì)算內(nèi)核,它調(diào)用了分布在不同翻譯單元或源文件中的數(shù)百個(gè)獨(dú)立設(shè)備函數(shù)。函數(shù)的手動(dòng)內(nèi)聯(lián)是有效的,但如果您希望使用單獨(dú)的編譯來維護(hù)傳統(tǒng)的開發(fā)工作流和庫邊界,則會(huì)很麻煩。在這些情況下,使用設(shè)備 LTO 來實(shí)現(xiàn)潛在的性能優(yōu)勢而不需要額外的開發(fā)工作是非常有吸引力的。

圖 3 :設(shè)備鏈接時(shí)間優(yōu)化的性能加速比優(yōu)于單獨(dú)編譯模式,在某些情況下與整個(gè)程序編譯模式相當(dāng)(越高越好)
如圖 3 所示,帶有設(shè)備 LTO 的基準(zhǔn)測試和客戶應(yīng)用程序的運(yùn)行時(shí)性能接近于整個(gè)程序編譯模式,克服了單獨(dú)編譯模式帶來的限制。請記住,性能的提高在很大程度上取決于應(yīng)用程序本身的構(gòu)建方式。正如我們所觀察到的,在某些情況下,收益微乎其微。使用另一個(gè) CUDA 應(yīng)用程序套件,設(shè)備 LTO 的運(yùn)行時(shí)性能平均提高了 25% 左右。
在這篇文章的后面,我們將介紹更多關(guān)于設(shè)備 LTO 不是特別有用的場景。
除了 GPU 性能之外,設(shè)備 LTO 還有另一個(gè)方面,那就是構(gòu)建時(shí)間。使用設(shè)備 LTO 的總構(gòu)建時(shí)間在很大程度上取決于應(yīng)用程序大小和其他系統(tǒng)因素。在圖 4 中,內(nèi)部基準(zhǔn)構(gòu)建時(shí)間的相對差異與前面三種不同編譯模式的客戶應(yīng)用程序進(jìn)行了比較。內(nèi)部基準(zhǔn)由大約 12000 行代碼組成,而客戶應(yīng)用程序有上萬行代碼。
有些情況下,由于編譯和優(yōu)化這些程序所需的過程較少,因此整個(gè)程序模式的編譯速度可能更快。此外,在全程序模式下,較小的程序有時(shí)可能編譯得更快,因?yàn)樗休^少的編譯命令,因此對宿主編譯器的調(diào)用也較少。但是在全程序模式下的大型程序會(huì)帶來更高的優(yōu)化成本和內(nèi)存使用。在這種情況下,使用單獨(dú)的編譯模式進(jìn)行編譯會(huì)更快。對于圖 4 中的內(nèi)部基準(zhǔn)可以觀察到這一點(diǎn),其中整個(gè)程序模式的編譯時(shí)間快了 17% ,而對于客戶應(yīng)用程序,整個(gè)程序模式的編譯速度慢了 25% 。
有限的優(yōu)化范圍和較小的翻譯單元使單獨(dú)編譯模式下的編譯速度更快。當(dāng)增量更改被隔離到幾個(gè)源文件時(shí),單獨(dú)的編譯模式還減少了總體的增量構(gòu)建時(shí)間。當(dāng)啟用設(shè)備鏈接時(shí)間優(yōu)化時(shí),編譯器優(yōu)化階段將被取消,從而顯著減少編譯時(shí)間,從而進(jìn)一步加快單獨(dú)編譯模式的編譯速度。但是,同時(shí),由于設(shè)備代碼優(yōu)化階段推遲到鏈接器,并且由于鏈接器可以在單獨(dú)編譯模式下執(zhí)行更多優(yōu)化,因此單獨(dú)編譯的程序的鏈接時(shí)間可能隨著設(shè)備鏈接時(shí)間優(yōu)化而更高。在圖 4 中,我們可以觀察到設(shè)備 LTO 構(gòu)建時(shí)間與基準(zhǔn)相比只慢了 7% ,但是與客戶應(yīng)用程序相比,構(gòu)建時(shí)間慢了近 50% 。

圖 4 :構(gòu)建時(shí)間加速可以變化(越高越好)。
在 11 . 2 中,我們還引入了新的 nvcc -threads 選項(xiàng),它在針對多個(gè)體系結(jié)構(gòu)時(shí)支持并行編譯。這有助于減少構(gòu)建時(shí)間。一般來說,這些編譯模式的總(編譯和鏈接)構(gòu)建時(shí)間可能會(huì)因一組不同的因素而有所不同。盡管如此,由于使用設(shè)備 LTO 可以顯著縮短編譯時(shí)間,我們希望啟用設(shè)備鏈接時(shí)間優(yōu)化的單獨(dú)編譯模式的總體構(gòu)建在大多數(shù)典型場景中應(yīng)該是可比的。
設(shè)備 LTO 的限制
設(shè)備 LTO 在跨文件對象內(nèi)聯(lián)設(shè)備功能時(shí)特別強(qiáng)大。但是,在某些應(yīng)用程序中,設(shè)備代碼可能都駐留在源文件中,在這種情況下,設(shè)備 LTO 沒有太大的區(qū)別。
來自函數(shù)指針的間接調(diào)用(如回調(diào))不會(huì)從 LTO 中獲得太多好處,因?yàn)檫@些間接調(diào)用不能內(nèi)聯(lián)。
請注意,設(shè)備 LTO 執(zhí)行激進(jìn)的代碼優(yōu)化,因此它與使用 -G NVCC 命令行選項(xiàng)來啟用設(shè)備代碼的符號(hào)調(diào)試支持不兼容。
對于 CUDA 11 . 2 ,設(shè)備 LTO 只能脫機(jī)編譯。設(shè)備 LTO 中間窗體尚不支持 JIT LTO 。
像 -maxrregcount 或 -use_fast_math 這樣的文件作用域命令與設(shè)備 LTO 不兼容,因?yàn)?LTO 優(yōu)化跨越了文件邊界。如果所有的文件都是用相同的選項(xiàng)編譯的,那么一切都很好,但是如果它們不同,那么設(shè)備 LTO 會(huì)在鏈接時(shí)抱怨。通過在鏈接時(shí)指定 -maxrregcount 或 -use_fast_math ,可以覆蓋設(shè)備 LTO 的這些編譯屬性,然后該值將用于所有 LTO 對象。
盡管使用設(shè)備 LTO 將編譯時(shí)優(yōu)化所花的大部分時(shí)間轉(zhuǎn)移到了鏈接時(shí),但總體構(gòu)建時(shí)間通常在 LTO 構(gòu)建和非 LTO 構(gòu)建之間是相當(dāng)?shù)模驗(yàn)榫幾g時(shí)間顯著縮短。但是,它增加了鏈接時(shí)所需的內(nèi)存量。我們認(rèn)為,設(shè)備 LTO 的好處應(yīng)該抵消最常見情況下的限制。
試用設(shè)備 LTO
如果您希望在不影響性能或設(shè)備源代碼模塊化的情況下,以單獨(dú)的編譯模式構(gòu)建 GPU 加速的應(yīng)用程序,那么設(shè)備 LTO 就適合您了!
使用以單獨(dú)編譯模式編譯的設(shè)備 LTO 程序可以利用跨文件邊界的代碼優(yōu)化的性能優(yōu)勢,從而有助于縮小相對于整個(gè)程序編譯模式的性能差距。
為了評(píng)估和利用設(shè)備 LTO 對 CUDA 應(yīng)用程序的好處, 立即下載 CUDA 11 . 2 工具包 并進(jìn)行試用。另外,請告訴我們您的想法。我們一直在尋找改進(jìn) CUDA 應(yīng)用程序開發(fā)和運(yùn)行時(shí)性能調(diào)優(yōu)體驗(yàn)的方法。
關(guān)于作者
Mike Murphy 是 NVIDIA 的高級(jí)編譯工程師。
Arthy Sundaram 是 CUDA 平臺(tái)的技術(shù)產(chǎn)品經(jīng)理。她擁有哥倫比亞大學(xué)計(jì)算機(jī)科學(xué)碩士學(xué)位。她感興趣的領(lǐng)域是操作系統(tǒng)、編譯器和計(jì)算機(jī)體系結(jié)構(gòu)。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5594瀏覽量
109731 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135450
發(fā)布評(píng)論請先 登錄
借助NVIDIA CUDA Tile IR后端推進(jìn)OpenAI Triton的GPU編程
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

NVIDIA RTX PRO 5000 Blackwell GPU的深度評(píng)測

NVIDIA RTX PRO 4000 Blackwell GPU性能測試

NVIDIA CUDA Tile的創(chuàng)新之處、工作原理以及使用方法

在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA CUDA 13.1版本的新增功能與改進(jìn)
NVIDIA RTX PRO 2000 Blackwell GPU性能測試

NVIDIA桌面GPU系列擴(kuò)展新產(chǎn)品
aicube的n卡gpu索引該如何添加?
NVIDIA Blackwell GPU優(yōu)化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀(jì)錄

鴻蒙5開發(fā)寶藏案例分享---應(yīng)用性能優(yōu)化指南
借助NVIDIA技術(shù)加速半導(dǎo)體芯片制造
解決應(yīng)用性能問題的策略




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論