") ACL2021的跨視覺語言模態(tài)論文之跨視覺語言模態(tài)任務(wù)與方法
ACL2021的跨視覺語言模態(tài)論文之跨視覺語言模態(tài)任務(wù)與方法

來自:復(fù)旦DISC
引言
本次分享我們將介紹三篇來自ACL2021的跨視覺語言模態(tài)的論文。這三篇文章分別介紹了如何在圖像描述任務(wù)中生成契合用戶意圖的圖像描述、端對端的視覺語言預(yù)訓(xùn)練模型和如何生成包含更多細節(jié)的圖像描述。
文章概覽
Control Image Captioning Spatially and Temporally
論文地址:https://aclanthology.org/2021.acl-long.157.pdf
該篇文章基于對比學(xué)習(xí)和注意力機制引導(dǎo)提出了LoopCAG模型。LoopCAG可以根據(jù)輸入的鼠標軌跡,生成與鼠標軌跡相匹配的圖像描述,從而增強了圖片描述生成的可控性和可解釋性。
E2E-VLP: End-to-End Vision-Language Pretraining Enhanced by Visual Learning
論文地址:https://arxiv.org/pdf/2106.01804.pdf
這篇文章提出了一個端到端的視覺語言預(yù)訓(xùn)練模型。模型不需要利用預(yù)訓(xùn)練的目標檢測器抽取基于區(qū)域的視覺特征,直接以圖片作為輸入。并且設(shè)計了兩個額外的視覺預(yù)訓(xùn)練任務(wù)幫助模型學(xué)習(xí)細粒度的信息,達到了和兩階段模型相似的效果,并且提高了運算效率。
Enhancing Descriptive Image Captioning with Natural Language Inference
論文地址:https://aclanthology.org/2021.acl-short.36.pdf
這篇文章通過推理圖和PageRank對圖像描述進行描述性打分。再通過參考抽樣和加權(quán)指定獎勵來生成具有更多細節(jié)的圖像描述。模型生成了比一般方法具有更多細節(jié)的圖像描述,這些圖像描述可以包含基線方法生成的圖像描述。
論文細節(jié)
1
動機
圖像描述任務(wù)主要針對圖片上比較突出的物體和物體關(guān)系展開描述,這樣的圖片描述沒有考慮到用戶意圖。為了生成具備可控性和可解釋性的圖像描述,最近的工作提出了生成可控性的圖像描述任務(wù)。為了生成符合用戶意圖的圖像描述,通常會對描述加以情感、邊界框和鼠標軌跡限制。與此同時,近期提出的 Localized-Narratives 數(shù)據(jù)集將鼠標軌跡作為圖像描述任務(wù)的另一個輸入,為圖像描述生成任務(wù)中所涉及的語義概念進行空間和時序關(guān)系上的控制提供了可能。
模型
LoopCAG 可以總結(jié)為三部分:用于生成圖片描述且以 Transformer 為主干網(wǎng)絡(luò)的編碼器-解碼器;用于視覺對象空間定位的注意力引導(dǎo)(Attention Guidance)組件;用于句子級時序?qū)R的對比性約束(Contrastive Constraints)組件。
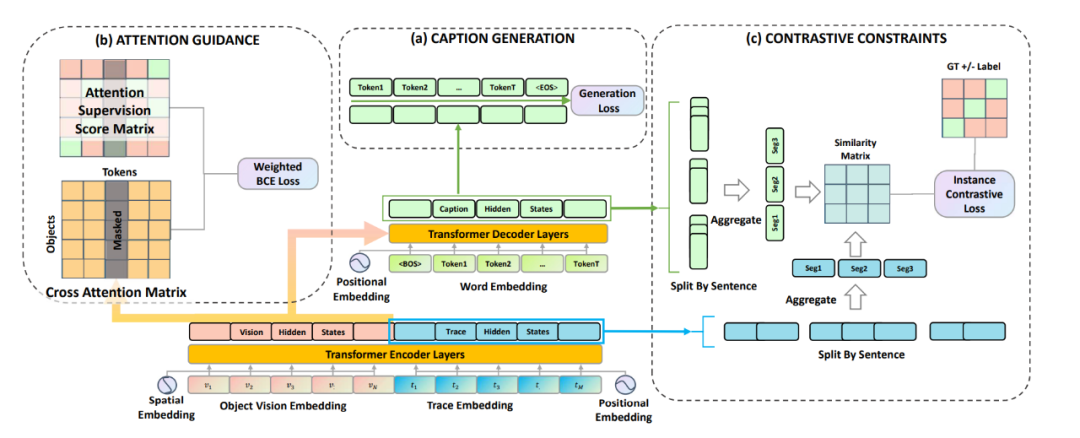
(1)Caption Generation
作者將視覺特征V和軌跡特征T分別編碼,并疊加位置信息后得 和 ,然后串聯(lián)在一起作為一個統(tǒng)一的序列輸入編碼器。解碼器通過交叉注意力模塊與編碼器最后一層的隱藏狀態(tài)相連,將視覺和軌跡信息結(jié)合起來作為生成的前置條件。解碼器的優(yōu)化目標是將以下目標函數(shù)最小化:
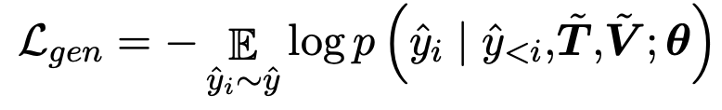
(2)Attention Guidance
為了定位物體,作者用軌跡作為中間橋梁聯(lián)系物體和語義token。作者構(gòu)建了一個監(jiān)督矩陣來引導(dǎo)詞語和視覺對象之間的注意力,即需要物體軌跡點盡可能多的落入對象邊界框中。當(dāng)注意力監(jiān)督矩陣和模型的交叉注意力矩陣盡可能接近時,詞語則可以準確的對應(yīng)到圖片的空間視覺物體上。
(3)Contrastive Constraints
作者使用對比損失函數(shù)來約束生成過程的時間順序,對比損失的形式是 NCE 函數(shù),用來學(xué)習(xí)區(qū)分軌跡-描述對之中的正例和負例。正例是指在順序上自然對應(yīng)的描述句和軌跡段,而其余的軌跡-描述對組合均為負例。
最后作者通過將所有損失的總和最小化來聯(lián)合優(yōu)化模型。
實驗
作者在Localized-Narratives COCO 這個數(shù)據(jù)集上進行了訓(xùn)練和測試。在測試集上的結(jié)果如圖所示,LoopCAG 方法在所有的自動評測指標上都達到了先進水平。從表中可以看出,ROUGE-L 的得分提升了2.0。由于 ROUGE-L 主要采用了對順序敏感的最長共同子序列計分方式,這表明對比約束可以促進生成句子的順序和用戶意圖的對應(yīng)。
2
動機
基于海量圖文對的多模態(tài)預(yù)訓(xùn)練在下游的跨模態(tài)任務(wù)中已經(jīng)取得巨大的成功。現(xiàn)有的多模態(tài)預(yù)訓(xùn)練的方法主要基于兩階段訓(xùn)練,首先利用預(yù)訓(xùn)練的目標檢測器抽取基于區(qū)域的視覺特征,然后拼接視覺表示和文本向量作為Transformer的輸入進行訓(xùn)練。這樣的模型存在兩點問題,一個是第一階段通常在特定數(shù)據(jù)集進行訓(xùn)練模型泛化能力不好,此外提取區(qū)域的視覺特征比較耗費時間。基于此作者提出了端到端的像素級別的視覺語言預(yù)訓(xùn)練模型。模型通過一個統(tǒng)一的Transformer框架同時學(xué)習(xí)圖像特征和多模態(tài)表示
模型
本文的模型如圖所示。E2E-VLP用一個CNN 模型提取圖片視覺特征的同時用一個Transformer進行多模態(tài)特征學(xué)習(xí)。
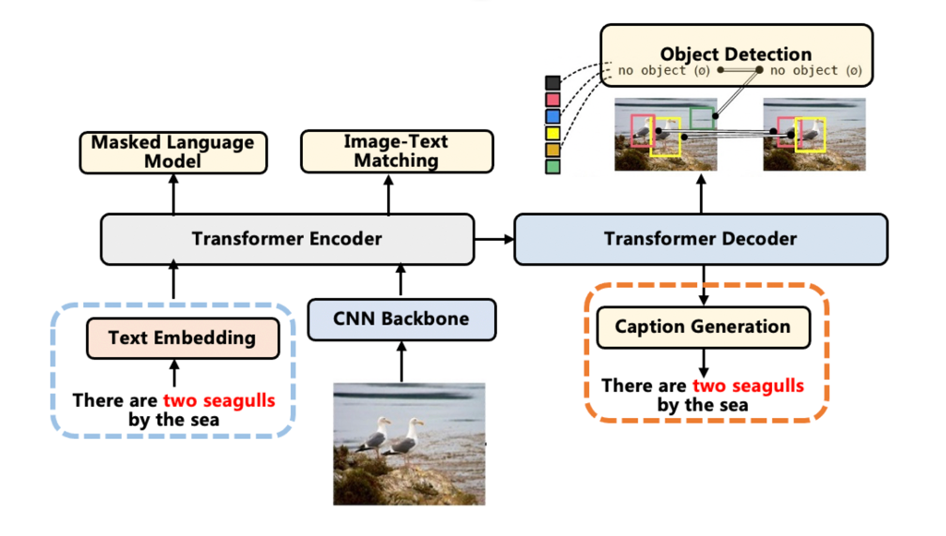
(1) Input Representations
模型首先用WordPiece tokenizer 分詞進行序列化。圖片則直接以三通道的像素矩陣輸入。
(2) Cross-modal Encoder Pre-training:Transformer
模型用Resnet提取圖片的特征向量。用Transformer模塊接受圖像-句子的序列輸入,進行跨模態(tài)語義學(xué)習(xí)。
為了提取跨模態(tài)語義信息,模型設(shè)計了兩個預(yù)訓(xùn)練任務(wù)。一個是與Bert類似的Masked Language Modeling,只是在該任務(wù)中除去上下文信息還可以利用圖片信息避免語義混淆,第二個任務(wù)是進行圖片文本匹配。
(3) Visual-enhanced Decoder
為了提取更細粒度的視覺特征,接入了物體檢測和描述生成兩個任務(wù)。在物體檢測中,為了增強視覺語義特征的學(xué)習(xí),除去常規(guī)的位置和物體種類預(yù)測,我們引入了屬性預(yù)測這一任務(wù)。描述生成圖片對應(yīng)的描述。
實驗
根據(jù)實驗結(jié)果,E2E-VLP 和兩階段模型相比,也取得了比較好效果,可以理解和完成兩種任務(wù)。同時在參數(shù)量上,E2E-VLP 則具有更加輕量的優(yōu)勢。
3
動機
現(xiàn)階段的圖像描述模型通常傾向于生成比較安全的較為籠統(tǒng)的描述,而忽略圖像細節(jié)。為了生成包含更多細節(jié)的圖像描述,作者基于更具有細節(jié)的圖像描述通常包含籠統(tǒng)描述的全部信息這一觀點提出了基于自然語言推斷的描述關(guān)系模型。
方法
這篇文章的具體方法如下:
(1)Constructing Inference Graphs
首先用基于Bert的自然語言推斷模型判斷圖像描述之間的關(guān)系,由于圖像描述之間不存在沖突因此挪去了沖突關(guān)系。并對一張圖的描述構(gòu)建如圖所示的推斷關(guān)系圖,并利用Pagerank的方法對推斷圖計算描述性評分。
(2)Descriptiveness Regularized Learning
由于傳統(tǒng)圖像描述的第一階段生成描述和圖像描述最小化交叉熵損失函數(shù)等同于生成描述和均勻分布的圖像描述之間的KL Divergence,為了生成更具有描述性的圖像描述。則采用歸一化的描述性評分分布取代均勻分布,認為更具有描述性的圖像描述具有更高的生成概率。
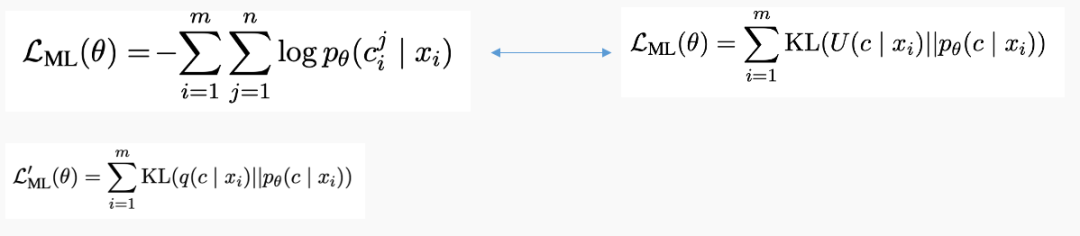
在第二階段,最大化生成圖像描述的期望收益時,也同時用描述性評分取代均勻分布來計算期望收益。

實驗
根據(jù)實驗結(jié)果,模型在多數(shù)指標特別是CIDER評分上超過了Baseline,這是因為CIDER傾向于具有更加特殊的細節(jié)描述。
此外根據(jù)自然語言推斷模型判斷文章模型生成的圖像描述對baseline的圖像描述形成更多的包含關(guān)系。
編輯:jq
-
解碼器
+關(guān)注
關(guān)注
9文章
1219瀏覽量
43394 -
編碼器
+關(guān)注
關(guān)注
45文章
3953瀏覽量
142630 -
圖像
+關(guān)注
關(guān)注
2文章
1096瀏覽量
42326 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4417瀏覽量
67504 -
cnn
+關(guān)注
關(guān)注
3文章
355瀏覽量
23418
原文標題:ACL2021 | 跨視覺語言模態(tài)任務(wù)與方法
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
眾智FlagOS適配面壁智能開源全模態(tài)大模型MiniCPM-o 4.5

全球首個最大規(guī)模跨本體視觸覺多模態(tài)數(shù)據(jù)集白虎-VTouch發(fā)布
商湯科技日日新V6.5榮獲2025年多模態(tài)大模型全國第一

格靈深瞳多模態(tài)大模型Glint-ME讓圖文互搜更精準

亞馬遜云科技上線Amazon Nova多模態(tài)嵌入模型

跨語言交流的全場景解決方案,時空壺X1的進化之路

時空壺W4Pro:商務(wù)跨語言場景的高效溝通解決方案

米爾RK3576部署端側(cè)多模態(tài)多輪對話,6TOPS算力驅(qū)動30億參數(shù)LLM
飛凌嵌入式RK3576多模態(tài)大模型圖像理解助手,讓嵌入式設(shè)備“看懂”世界

云知聲四篇論文入選自然語言處理頂會ACL 2025

基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型

移遠通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

移遠通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

?VLM(視覺語言模型)?詳細解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論