") AMD或?qū)⑷鎿肀BM,CPU和GPU都要用?
AMD或?qū)⑷鎿肀BM,CPU和GPU都要用?

近期外網(wǎng)爆出傳聞,AMD下一代Zen 4核心的EPYC Genoa處理器可能會(huì)配備HBM內(nèi)容,以求與英特爾的下一代服務(wù)器CPU Xeon Sapphire Rapids爭(zhēng)雄。巧合的是,近日Linux內(nèi)核補(bǔ)丁中也透露了消息,AMD下一代基于CDNA 2核心的Instinct MI200 GPU也將用到HBM2e,顯存更是高達(dá)128GB。這意味著AMD很可能會(huì)在服務(wù)器市場(chǎng)全面擁抱HBM。
已與消費(fèi)顯卡市場(chǎng)無緣的HBM
HBM作為一種高帶寬存儲(chǔ)器,其實(shí)是由AMD最先投入研發(fā)的高性能DRAM。為了實(shí)現(xiàn)這一愿景,AMD找來了有3D堆疊工藝生產(chǎn)經(jīng)驗(yàn)的SK海力士,并借助互聯(lián)和封裝廠商的幫助,聯(lián)合開發(fā)出了HBM存儲(chǔ)器。

AMD也是首個(gè)將其引入GPU市場(chǎng)的廠商,并應(yīng)用在其Fiji GPU上。隨后2016年,三星率先開始了HBM2的量產(chǎn),AMD被英偉達(dá)搶了風(fēng)頭,后者率先將這一新標(biāo)準(zhǔn)的存儲(chǔ)器應(yīng)用在其Tesla P100加速卡上。
當(dāng)時(shí)HBM的優(yōu)缺點(diǎn)都十分明顯了,從一開始以來的帶寬優(yōu)勢(shì)正在被GDDR6迎頭趕上,設(shè)計(jì)難度和成本又是一道難以邁過的坎。雖然高端顯卡上這些成本并不占大頭,但中低端顯卡用到HBM就比較肉疼了。但AMD并沒有因此放棄HBM2,而是在Vega顯卡上繼續(xù)引入了HBM2。
不過,這可能也就是我們最后一次在消費(fèi)級(jí)GPU上見到HBM了,AMD在之后的RDNA架構(gòu)上再也沒有使用HBM,僅僅只有基于CDNA架構(gòu)且用于加速器的GPU上還在使用HBM。
為什么是服務(wù)器市場(chǎng)?
HBM是如何在服務(wù)器市場(chǎng)扎根的呢?這是因?yàn)镠BM最適合的應(yīng)用場(chǎng)景之一就是功率受限又需要最大帶寬的環(huán)境,完美達(dá)到HPC集群中進(jìn)行人工智能計(jì)算,或是大型密集計(jì)算的數(shù)據(jù)中心的要求。
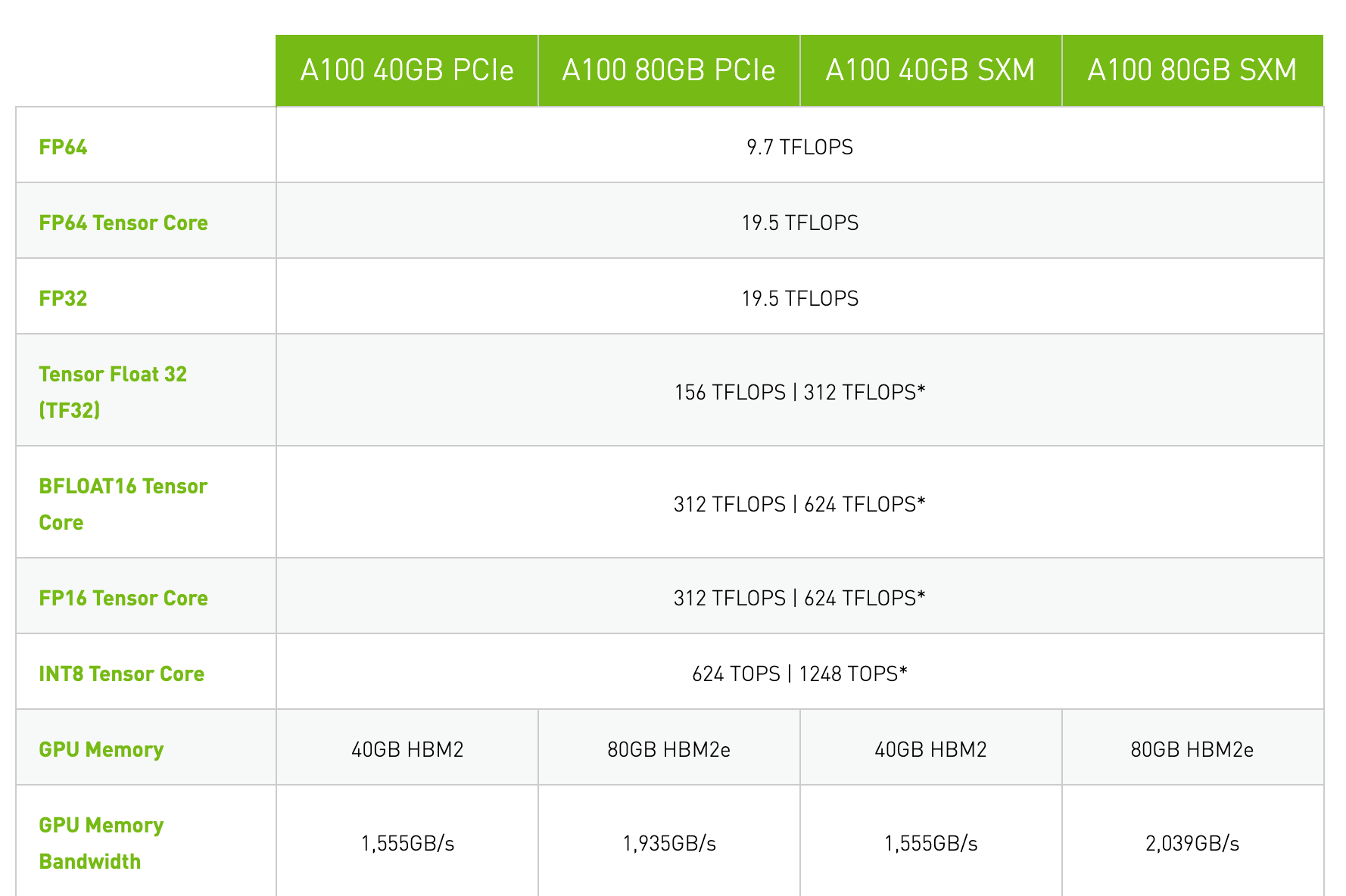
這也就是這些包含數(shù)據(jù)中心業(yè)務(wù)的公司持續(xù)使用HBM的原因,英偉達(dá)在性能強(qiáng)大的服務(wù)器GPU A100中依然在使用HBM2和HBM2e,甚至可能會(huì)在下一代Hopper結(jié)構(gòu)繼續(xù)沿用下去。據(jù)傳,英特爾尚未面世的Xe-HP和Xe-HPC GPU也將使用HBM。
不過這兩家廠商的消費(fèi)級(jí)GPU都不約而同的避過了HBM,選擇了GDDR6和GDDR6X,可想而知他們都不想走AMD的彎路。
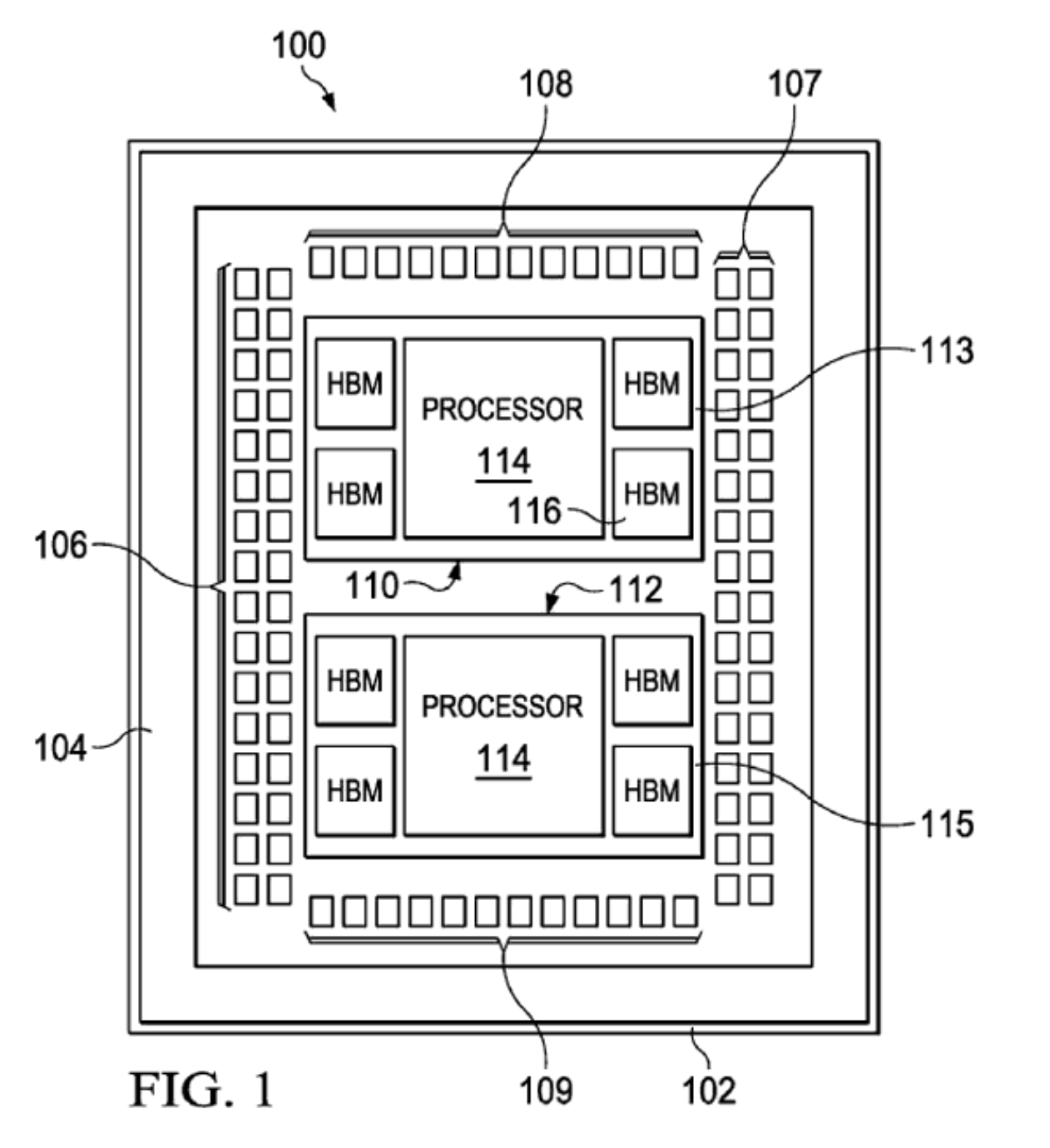
至于AMD在CPU上率先使用HBM也并非空穴來風(fēng),在AMD去年公布的一份專利中,就在芯片設(shè)計(jì)上出現(xiàn)了HBM。英特爾推出的競(jìng)品Xeon Sapphire Rapids服務(wù)器CPU也正式宣布將使用HBM,不過量產(chǎn)要等到2023年。這些可以看出HBM在服務(wù)器市場(chǎng)有多“香”,他們都開始將HBM向CPU上發(fā)展。
下一代HBM
雖然制定標(biāo)準(zhǔn)的JEDEC尚未推出HBM3的相關(guān)規(guī)范,但一直在研究下一代HBM的SK海力士在今年6月透露了HBM3的最新情報(bào),HBM將迎來進(jìn)一步的性能提升。

HBM2E的帶寬可達(dá)460GB/s,I/O速率可達(dá)3.6Gbps,而HBM3的帶寬可以達(dá)到665GB/s以上,I/O速率超過5.2Gbps。這還是只是速率的下限而已,要知道SiFive與OpenFive今年流片的5nm RISC-V SoC也加入了HBM3的IP,最高支持的數(shù)據(jù)傳輸率達(dá)到7.2Gbps。
SK海力士能做到如此高的性能提升,很可能得益于去年與Xperi簽訂的專利許可協(xié)議。這些協(xié)議中包含了DBI Ultra 2.5D/3D互聯(lián)技術(shù),可以用于3DS、HBM2、HBM3及后續(xù)DRAM產(chǎn)品的創(chuàng)新開發(fā)。傳統(tǒng)的銅柱互聯(lián)只能做到每平方毫米625個(gè)互聯(lián),而DBI Ultra可以在同樣的面積下做到10萬個(gè)互聯(lián)。
結(jié)語(yǔ)
從JEDEC2018年宣布HBM2E標(biāo)準(zhǔn)以來,HBM已經(jīng)近3年沒有更新了。三星更是在今年2月宣布開發(fā)帶有人工智能引擎的HBM-PIM,未來HBM3是否能在服務(wù)器領(lǐng)域繼續(xù)稱雄,相信當(dāng)前幾大廠商規(guī)劃的服務(wù)器產(chǎn)品中HBM占比已經(jīng)給出了答案。
已與消費(fèi)顯卡市場(chǎng)無緣的HBM
HBM作為一種高帶寬存儲(chǔ)器,其實(shí)是由AMD最先投入研發(fā)的高性能DRAM。為了實(shí)現(xiàn)這一愿景,AMD找來了有3D堆疊工藝生產(chǎn)經(jīng)驗(yàn)的SK海力士,并借助互聯(lián)和封裝廠商的幫助,聯(lián)合開發(fā)出了HBM存儲(chǔ)器。
Fiji GPU / AMD
AMD也是首個(gè)將其引入GPU市場(chǎng)的廠商,并應(yīng)用在其Fiji GPU上。隨后2016年,三星率先開始了HBM2的量產(chǎn),AMD被英偉達(dá)搶了風(fēng)頭,后者率先將這一新標(biāo)準(zhǔn)的存儲(chǔ)器應(yīng)用在其Tesla P100加速卡上。
當(dāng)時(shí)HBM的優(yōu)缺點(diǎn)都十分明顯了,從一開始以來的帶寬優(yōu)勢(shì)正在被GDDR6迎頭趕上,設(shè)計(jì)難度和成本又是一道難以邁過的坎。雖然高端顯卡上這些成本并不占大頭,但中低端顯卡用到HBM就比較肉疼了。但AMD并沒有因此放棄HBM2,而是在Vega顯卡上繼續(xù)引入了HBM2。
不過,這可能也就是我們最后一次在消費(fèi)級(jí)GPU上見到HBM了,AMD在之后的RDNA架構(gòu)上再也沒有使用HBM,僅僅只有基于CDNA架構(gòu)且用于加速器的GPU上還在使用HBM。
為什么是服務(wù)器市場(chǎng)?
HBM是如何在服務(wù)器市場(chǎng)扎根的呢?這是因?yàn)镠BM最適合的應(yīng)用場(chǎng)景之一就是功率受限又需要最大帶寬的環(huán)境,完美達(dá)到HPC集群中進(jìn)行人工智能計(jì)算,或是大型密集計(jì)算的數(shù)據(jù)中心的要求。
A100不同規(guī)格的顯存對(duì)比 / Nvidia
這也就是這些包含數(shù)據(jù)中心業(yè)務(wù)的公司持續(xù)使用HBM的原因,英偉達(dá)在性能強(qiáng)大的服務(wù)器GPU A100中依然在使用HBM2和HBM2e,甚至可能會(huì)在下一代Hopper結(jié)構(gòu)繼續(xù)沿用下去。據(jù)傳,英特爾尚未面世的Xe-HP和Xe-HPC GPU也將使用HBM。
不過這兩家廠商的消費(fèi)級(jí)GPU都不約而同的避過了HBM,選擇了GDDR6和GDDR6X,可想而知他們都不想走AMD的彎路。
AMD專利 / AMD
至于AMD在CPU上率先使用HBM也并非空穴來風(fēng),在AMD去年公布的一份專利中,就在芯片設(shè)計(jì)上出現(xiàn)了HBM。英特爾推出的競(jìng)品Xeon Sapphire Rapids服務(wù)器CPU也正式宣布將使用HBM,不過量產(chǎn)要等到2023年。這些可以看出HBM在服務(wù)器市場(chǎng)有多“香”,他們都開始將HBM向CPU上發(fā)展。
下一代HBM
雖然制定標(biāo)準(zhǔn)的JEDEC尚未推出HBM3的相關(guān)規(guī)范,但一直在研究下一代HBM的SK海力士在今年6月透露了HBM3的最新情報(bào),HBM將迎來進(jìn)一步的性能提升。
HBM2E和HBM3性能對(duì)比 / SK海力士
HBM2E的帶寬可達(dá)460GB/s,I/O速率可達(dá)3.6Gbps,而HBM3的帶寬可以達(dá)到665GB/s以上,I/O速率超過5.2Gbps。這還是只是速率的下限而已,要知道SiFive與OpenFive今年流片的5nm RISC-V SoC也加入了HBM3的IP,最高支持的數(shù)據(jù)傳輸率達(dá)到7.2Gbps。
SK海力士能做到如此高的性能提升,很可能得益于去年與Xperi簽訂的專利許可協(xié)議。這些協(xié)議中包含了DBI Ultra 2.5D/3D互聯(lián)技術(shù),可以用于3DS、HBM2、HBM3及后續(xù)DRAM產(chǎn)品的創(chuàng)新開發(fā)。傳統(tǒng)的銅柱互聯(lián)只能做到每平方毫米625個(gè)互聯(lián),而DBI Ultra可以在同樣的面積下做到10萬個(gè)互聯(lián)。
結(jié)語(yǔ)
從JEDEC2018年宣布HBM2E標(biāo)準(zhǔn)以來,HBM已經(jīng)近3年沒有更新了。三星更是在今年2月宣布開發(fā)帶有人工智能引擎的HBM-PIM,未來HBM3是否能在服務(wù)器領(lǐng)域繼續(xù)稱雄,相信當(dāng)前幾大廠商規(guī)劃的服務(wù)器產(chǎn)品中HBM占比已經(jīng)給出了答案。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
amd
+關(guān)注
關(guān)注
25文章
5684瀏覽量
139960 -
cpu
+關(guān)注
關(guān)注
68文章
11279瀏覽量
224978 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135444
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
AMD獲Meta千億美元芯片大單,AI芯片市場(chǎng)格局生變
電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)近日,Meta與AMD共同宣布達(dá)成一項(xiàng)重磅的多年期協(xié)議。Meta將在其AI數(shù)據(jù)中心大規(guī)模部署6吉瓦的AMD GPU,并配套使用AI優(yōu)化型CPU,首批搭載M

歷史首次!AMD服務(wù)器CPU市占率達(dá)50%
英特爾持平。根據(jù)AMD的數(shù)據(jù)顯示,自EPYC CPU推出以來,其在服務(wù)器領(lǐng)域的市場(chǎng)份額由2018年的2%提升到2024年上半年的34%。在持平之后未來競(jìng)爭(zhēng)將變得更加激烈。 ? ? ? 回看每一代
GPU猛獸襲來!HBM4、AI服務(wù)器徹底引爆!
電子發(fā)燒友網(wǎng)報(bào)道(文/黃晶晶)日前,多家服務(wù)器廠商表示因AI服務(wù)器需求高漲拉高業(yè)績(jī)?cè)鲩L(zhǎng)。隨著AI服務(wù)器需求旺盛,以及英偉達(dá)GPU的更新?lián)Q代,勢(shì)必帶動(dòng)HBM供應(yīng)商的積極產(chǎn)品推進(jìn)。三星方面HBM
深入解析ISL6377:AMD Fusion桌面CPU的多相PWM調(diào)節(jié)器
深入解析ISL6377:AMD Fusion桌面CPU的多相PWM調(diào)節(jié)器 在電子設(shè)計(jì)領(lǐng)域,為AMD Fusion桌面CPU提供穩(wěn)定、高效的電源解決方案至關(guān)重要。ISL6377作為一款完
KV緩存黑科技!SK海力士“H3存儲(chǔ)架構(gòu)”,HBM和HBF技術(shù)加持!
structure)”,同時(shí)采用了HBM和HBF兩種技術(shù)。 ? 在SK海力士設(shè)計(jì)的仿真實(shí)驗(yàn)中,H3架構(gòu)將HBM和HBF顯存并置于GPU旁,由GPU
解析ISL62776:AMD CPU/GPU核心電源的理想之選
解析ISL62776:AMD CPU/GPU核心電源的理想之選 在如今的電子設(shè)備中,CPU和GPU的性能不斷提升,對(duì)電源管理的要求也越來越高
NVIDIA RTX PRO 5000 72GB Blackwell GPU現(xiàn)已全面上市
NVIDIA RTX PRO 5000 72GB Blackwell GPU 現(xiàn)已全面上市,將基于 NVIDIA Blackwell 架構(gòu)的強(qiáng)大代理式與生成式 AI 能力帶到更多桌面和專業(yè)用戶手中。

AI硬件全景解析:CPU、GPU、NPU、TPU的差異化之路,一文看懂!?
、汽車)。
未來,隨著AI應(yīng)用的深化,硬件分工將更精細(xì)——可能出現(xiàn)專為機(jī)器人設(shè)計(jì)的專用AI芯片,或融合NPU與GPU優(yōu)勢(shì)的“邊緣訓(xùn)練芯片”。但無論如何,“匹配場(chǎng)景

AI大算力的存儲(chǔ)技術(shù), HBM 4E轉(zhuǎn)向定制化
電子發(fā)燒友網(wǎng)報(bào)道(文/黃晶晶)如今英偉達(dá)GPU迭代速度加快至每年一次,HBM存儲(chǔ)速率如何跟上GPU發(fā)展節(jié)奏。越來越多的超大規(guī)模云廠商、GPU廠商開始轉(zhuǎn)向定制化

如何看懂GPU架構(gòu)?一分鐘帶你了解GPU參數(shù)指標(biāo)
GPU架構(gòu)參數(shù)如CUDA核心數(shù)、顯存帶寬、TensorTFLOPS、互聯(lián)方式等,并非“冰冷的數(shù)字”,而是直接關(guān)系設(shè)備能否滿足需求、如何發(fā)揮最大價(jià)值、是否避免資源浪費(fèi)等問題的核心要素。本篇文章將全面

從 CPU 到 GPU,渲染技術(shù)如何重塑游戲、影視與設(shè)計(jì)?
渲染技術(shù)是計(jì)算機(jī)圖形學(xué)的核心內(nèi)容之一,它是將三維場(chǎng)景轉(zhuǎn)換為二維圖像的過程。渲染技術(shù)一直在不斷演進(jìn),從最初的CPU渲染到后來的GPU渲染,性能和質(zhì)量都有了顯著提升。從CPU到
傳英偉達(dá)自研HBM基礎(chǔ)裸片
"后的下一代AI GPU "Feynman"。 ? 有分析指出,英偉達(dá)此舉或是將部分GPU功能集成到基礎(chǔ)裸片中,旨在提高HBM和GPU的整體
性能優(yōu)于HBM,超高帶寬內(nèi)存 (X-HBM) 架構(gòu)來了!
和單芯片高達(dá)512 Gbit的容量,帶寬提升16倍,密度提升10倍,顯著突破了傳統(tǒng)HBM的局限性。 ? ? 關(guān)鍵特性和優(yōu)勢(shì)包括,可擴(kuò)展性,使GPU和內(nèi)存之間的數(shù)據(jù)傳輸更快,從而實(shí)現(xiàn)更高效的AI擴(kuò)展;高性能,解鎖未開發(fā)的GPU能力

aicube的n卡gpu索引該如何添加?
請(qǐng)問有人知道aicube怎樣才能讀取n卡的gpu索引呢,我已經(jīng)安裝了cuda和cudnn,在全局的py里添加了torch,能夠調(diào)用gpu,當(dāng)還是只能看到默認(rèn)的gpu0,顯示不了gpu1
發(fā)表于 07-25 08:18
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】+NVlink技術(shù)從應(yīng)用到原理
前言
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」書中的芯片知識(shí)是比較接近當(dāng)前的頂尖芯片水平的,同時(shí)包含了芯片架構(gòu)的基礎(chǔ)知識(shí),但該部分知識(shí)比較晦澀難懂,或許是由于我一直從事的事芯片
發(fā)表于 06-18 19:31



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論