 兩種GPU之間的延遲對比 AMD RDNA2完勝NVIDIA安培
兩種GPU之間的延遲對比 AMD RDNA2完勝NVIDIA安培

CPU緩存與內存延遲測試,相信大家都有所耳聞,但是GPU同樣的測試卻幾乎沒人做過。
ChipsAndCheese就做了一次特別的測試,對比考察了AMD、NVIDIAGPU架構的緩存、顯存遲問題。
首先是AMDRDNA2、NVIDIAAmpere兩家最新架構的比拼,代表是RX6900XT、RTX3090,前者在幾乎所有階段都完勝。
RNDA2架構創新性地加入了InfinityCache無限緩存,提升帶寬的同時,延遲也可圈可點,二級緩存命中率上只增加了大約20ns的延遲,明顯低于Ampere。
更驚人的是,RDNA2顯存延遲和Ampere幾乎一模一樣,但是別忘了,Ampere只有兩個層級的緩存,RDNA2卻有四個。
Ampere的緩存架構更加傳統,SM陣列私有一級緩存到二級緩存要增加超過100ns的延遲,RDNA2從零級緩存到二級緩存則只增加了約66ns。看起來,GA102核心面積過大,也直接增加了延遲。
這正好可以解釋AMDRDNA2架構在低分辨率下性能、能效更優秀,因為二級緩存、三級緩存延遲很低,更適合執行較小的負載。Ampere則相反,高負載下優勢明顯,比如說4K分辨率。
說完了GPU之間的對比,那么GPU、CPU放在一起怎么樣呢?這里以RX6900XT、Intel四代酷睿i7-4770為例來看看。
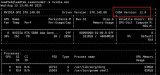
CPU的緩存自然不是一個級別的,所以這里Y軸用了線性數據,可以看到全程大大低于RDNA2,搭配DDR3-1600CL9內存延遲只有63ns,RX6900XT、GDDR6的組合則有226ns,另外末級緩存平均延遲分別是53.42ns、123.2ns。
再看看前幾代的NVIDIAGPU,包括Maxwell架構的GTX980Ti、Pascal架構的GTX1080、Turing架構的RTX2060Mobile。
Maxwell、Pascal其實差不多,前者整體略高一些,可能是受制于芯片面積較大、核心頻率較低。
Turing則已經有了Ampere的樣子,一級緩存延遲低得多,二級差不多,奇怪的是顯存延遲在32MB之后偏高,原因未知。
AMD考察了TeraScale架構的HD5850/6950、GCN架構的HD7970,再加上RX6900XT,很明顯在逐代降低,而且是各級緩存都在同時進步。
編輯:jq
-
amd
+關注
關注
25文章
5684瀏覽量
139974 -
cpu
+關注
關注
68文章
11279瀏覽量
225008 -
數據
+關注
關注
8文章
7335瀏覽量
94774 -
gpu
+關注
關注
28文章
5194瀏覽量
135461
發布評論請先 登錄
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

在Python中借助NVIDIA CUDA Tile簡化GPU編程

ADI GMSL技術兩種視頻數據傳輸模式的區別

AMD Vivado IP integrator的基本功能特性
NVIDIA Isaac Lab多GPU多節點訓練指南
兩種散熱路徑的工藝與應用解析
NVIDIA RTX PRO 4500 Blackwell GPU測試分析

NVIDIA桌面GPU系列擴展新產品
aicube的n卡gpu索引該如何添加?
AMD FPGA異步模式與同步模式的對比
NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
銣原子鐘與CPT原子鐘:兩種時間標準的區別




 工商網監
工商網監
評論