 將淺層神經網絡作為“弱學習者”的梯度Boosting框架
將淺層神經網絡作為“弱學習者”的梯度Boosting框架

1. 簡介
本文提出了一種新的梯度Boosting框架,將淺層神經網絡作為“弱學習者”。在此框架下,我們考慮一般的損失函數,并給出了分類、回歸和排序的具體實例。針對經典梯度boosting決策樹貪婪函數逼近的缺陷,提出了一種完全修正的方法。在多個數據集的所有三個任務中,該模型都比最新的boosting方法都得了來更好的結果。
2. 背景
盡管在理論上和實踐中都有著無限的可能性,但由于其固有的復雜性,為新應用領域開發定制的深度神經網絡仍然是出了名的困難。為任何給定的應用程序設計架構都需要極大的靈活性,往往需要大量的運氣。
在本文中,我們將梯度增強的能力與神經網絡的靈活性和多功能性相結合,引入了一種新的建模范式GrowNet,它逐層建立DNN。代替決策樹,我們使用淺層神經網絡作為我們的弱學習者,在一個通用的梯度增強框架中,可以應用于跨越分類、回歸和排名的各種任務。
我們做了進一步創新,比如在訓練過程中加入二階統計數據,同時還引入了一個全局校正步驟,該步驟已在理論和實際評估中得到證明,對提高效果并對特定任務進行精確微調。
我們開發了一種現成的優化算法,比傳統的深度神經網絡更快、更容易訓練。
我們引入了新的優化算法,相較于傳統的NN,它更快也更加易于訓練;此外我們還引入了二階統計和全局校正步驟,以提高穩定性,并允許針對特定任務對模型進行更細粒度的調整。
我們通過實驗評估證明了我們的技術的有效性,并在三種不同的ML任務(分類、回歸和學習排名)中的多個真實數據集上顯示了優異的結果。
3. 相關工作
3.1 Gradient Boosting Algorithms
Gradient Boosting算法是一種使用數值優化的函數估計方法,決策樹是梯度提升框架中最常用的函數(predictive learner)。梯度提升決策樹(GBDT),其中決策樹按順序訓練,每棵樹通過擬合負梯度來建模。本文中,我們將XGBoost作為基線。和傳統的GBDT不一樣,本文提出了Gradient Boosting Neural Network,使用千層的NN來訓練gradient boosting。
我們認為神經網絡給我們一種優于GBDT模型的策略。除了能夠將信息從先前的預測器傳播到下一個預測器之外,我們可以在加入新的層時糾正之前模型(correct step)。
3.2 Boosted Neural Nets
盡管像決策樹這樣的弱學習者在boosting和集成方法中很受歡迎,但是將神經網絡與boosting/集成方法相結合以獲得比單個大型/深層神經網絡更好的性能已經做了大量的工作。在之前開創性工作中,全連接的MLP以一層一層的方式進行訓練,并添加到級聯結構的神經網絡中。他們的模型并不完全是一個boosting模型,因為最終的模型是一個單一的多層神經網絡。
在早期的神經網絡設計中,集成的策略可以帶來巨大的提升,但是早期都是多數投票,簡單的求均值或者加權的均值這些策略。在引入自適應的boosting算法之后(Adaboost),就有一些工作開始將MLP和boosting相結合并且取得了很棒的效果。
在最新的一些研究中,AdaNet提出自適應地構建神經網絡層,除了學習網絡的權重,AdaNet調整網絡的結構以及它的增長過程也有理論上的證明。AdaNet的學習過程是boosting式的,但是最終的模型是一個單一的神經網絡,其最終輸出層連接到所有的底層。與AdaNet不同的是,我們以梯度推進的方式訓練每一個弱學習者,從而減少了entangled的訓練。最后的預測是所有弱學習者輸出的加權和。我們的方法還提供了一個統一的平臺來執行各種ML任務。
最近有很多工作來解釋具有數百層的深度殘差神經網絡的成功,表明它們可以分解為許多子網絡的集合。
4. 模型
在每一個boosting步驟中,我們使用當前迭代倒數第二層的輸出來增強原始輸入特性。
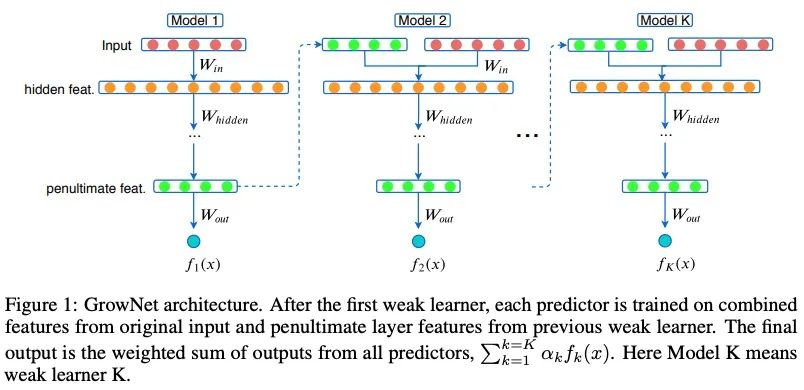
通過使用當前殘差的增強機制,將增強后的特征集作為輸入來訓練下一個弱學習者。模型的最終輸出是所有這些順序訓練模型的得分的加權組合。
4.1 Gradient Boosting Neural Network: GrowNet
我們假設有一個數據集,里面有個維度的特征空間,,GrowNet使用個加法函數來預測最終的輸出:
其中是多層感知機的空間,是步長,每個函數表示一個獨立的,淺層的網絡,對于一個給定的樣本,模型在GrowNet中計算的加權和。
我們令是一個可微的凸損失函數,我們的目標是學習一個函數集合(淺層的網絡),我們的目標就是學習一個函數的集合來最小化下面的等式:
和GBDT很像,此處我們采用加法的形式對其進行訓練,我們令:
為GrowNet關于樣本在第步輸出,我們貪心地搜索下一個弱學習器,,即:
此外,采用了損失函數的泰勒展開,來降低計算復雜度。由于二階優化技術優于一階優化技術,收斂步驟少,因此,我們用Newton-Raphson步長對模型進行了訓練。因此,無論ML任務如何,通過對GrowtNet輸出的二階梯度進行回歸,優化各個模型參數。關于弱學習器的目標函數可以簡化為:
其中,和分別是目標函數在處的一階和二階梯度。
4.2 Corrective Step (C/S)
傳統的boosting框架,每個弱學習器都是貪心學習的,這意味著只有第個弱學習器是不變的。
短視學習過程可能會導致模型陷入局部極小,固定的增長率會加劇這個問題。因此,我們實施了一個糾正步驟來解決這個問題。
在糾正步驟中,我們允許通過反向傳播更新先前t-1弱學習者的參數,而不是修復先前t-1弱學習者。
此外,我們將boosting rate 納入模型參數,并通過修正步驟自動更新。
除了獲得更好的性能之外,這一舉措可以讓我們避免調整一個微妙的參數。
C/S還可以被解釋為一個正則化器,以減輕弱學習器之間的相關性,因為在糾正步驟中,我們主要的訓練目標變成了僅對原始輸入的特定任務損失函數。這一步的有用性在論文《Learning nonlinear functions using regularized greedy forest》中對梯度提升決策樹模型進行了實證和理論研究。
5. 模型應用
5.1 回歸的GrowNet
此處我們以MSE為案例。
我們對數據集 通過最小平方回歸訓練下一個弱分類器,在Corrective Step,在GrowNet中對所有模型參數都可以使用MSE損失進行優化。
5.2 分類的GrowNet
為了便于說明,讓我們考慮二元交叉熵損失函數;注意,可以使用任何可微損失函數。我們選擇標簽,這樣我們的一階和二階的梯度和就是:
下一個弱學習器使用二階梯度統計通過使用最小平方回歸進行擬合。在 corrective step,所有疊加的預測函數的參數通過使用二元交叉熵損失函數在整個模型重新訓練。這一步根據手上任務的主要目標函數,即在這種情況下的分類,稍微修正權重。
5.3 LTR的GrowNet
假設對于某個給定的query,一對文件和被選擇。假設我們對于每個文檔和有一個特征向量,我們令和表示對于樣本和的模型輸出,一個傳統的pairwise loss可以被表示為下面的形式:
其中表示文件相關性的差值。是sigmoid函數。因為損失函數是堆成的,它的梯度可以通過下面的方式計算得到:
我們用表示下標對的集合,其中對于某個query,我們希望排名不同于,對于某個特定的文件,損失函數以及它的一階以及二階統計函數可以通過下面的形式獲得。
6. 實驗
6.1 實驗效果
模型中加入的預測函數都是具有兩個隱層的多層感知器。我們將隱藏層單元的數量設置為大約輸入特征維數的一半或相等。當模型開始過擬合時,更多的隱藏層會降低效果。我們實驗中采用了40個加法函數對三個任務進行測試,并根據驗證結果選擇了測試時間內的弱學習器個數。Boosting rate最初設置為1,并在校正步驟中自動調整。我們只訓練了每個預測函數一個epoch,整個模型在校正過程中使用Adam optimizer也訓練了一個epoch。epoch的個數在ranking任務中被設置為2;
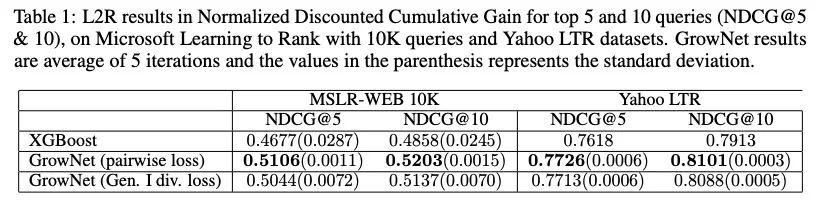
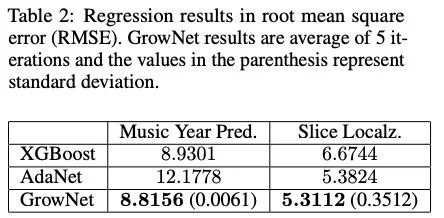
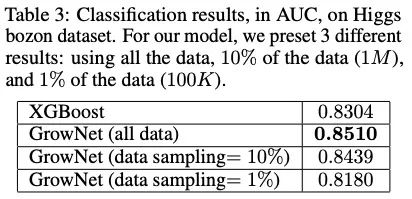
該方法在諸多方案上都取得了好于XGBoost的效果。
6.2 消融實驗
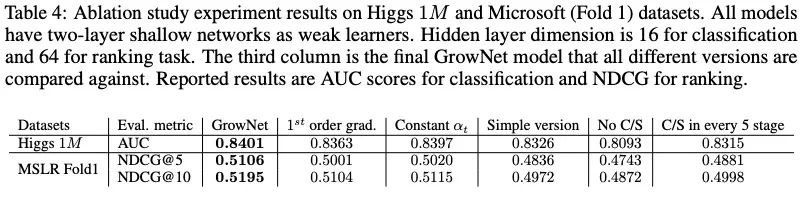
C/S的影響非常大;C/S模式緩解了learner之間潛在的相關性;
二階導數是有必要的;
自動化學習是有價值的;我們加了boosting rate ,它是自動調整的,不需要任何調整;
6.3 隱藏單元的影響
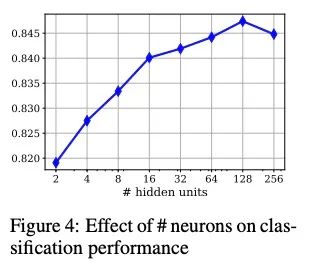
改變隱藏單元的數量對效果的影響較小。
測試了具有不同隱藏單元的最終模型(具有兩個隱藏層的弱學習者)。Higgs數據有28個特征,我們用2、4、8、16、32、64、128和256個隱藏單元對模型進行了測試。隱層維度越小,弱學習者獲得的信息傳播越少。另一方面,擁有大量的單元也會導致在某個點之后過度擬合。
上圖顯示了這個實驗在Higgs 1M數據上的測試AUC分數。最高的AUC為0.8478,只有128個單元,但當數量增加到256個單元時,效果會受到影響。
6.4 GrowNet versus DNN
如果我們把所有這些淺層網絡合并成一個深神經網絡,會發生什么?
這種方法存在幾個問題:
對DNN參數進行優化非常耗時,如隱藏層數、每個隱藏層單元數、總體架構、Batch normalization、dropout等;
DNN需要巨大的計算能力,總體運行速度較慢。我們將我們的模型(30個弱學習器)與DNN進行了5、10、20和30個隱藏層配置的比較。
在1000個epoch,在Higgs的1M數據上,最好的DNN(10個隱藏層)得到0.8342,每個epoch花費11秒。DNN在900個epoch時取得了這一成績(最好)。GrowtNet在相同的配置下取得了0.8401 AUC;
7. 小結
本文提出了GrowNet,它可以利用淺層神經網絡作為梯度推進框架中的“弱學習者”。這種靈活的網絡結構使我們能夠在統一的框架下執行多個機器學習任務,同時結合二階統計、校正步驟和動態提升率,彌補傳統梯度提升決策樹的缺陷。
我們通過消融研究,探討了神經網絡作為弱學習者在boosting范式中的局限性,分析了每個生長網絡成分對模型性能和收斂性的影響。結果表明,與現有的boosting方法相比,該模型在回歸、分類和學習多數據集排序方面具有更好的性能。我們進一步證明,GrowNet在這些任務中是DNNs更好的替代品,因為它產生更好的性能,需要更少的訓練時間,并且更容易調整。
原文標題:【前沿】Purdue&UCLA提出梯度Boosting網絡,效果遠好于XGBoost模型!
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107756 -
框架
+關注
關注
0文章
404瀏覽量
18422
原文標題:【前沿】Purdue&UCLA提出梯度Boosting網絡,效果遠好于XGBoost模型!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
CNN卷積神經網絡設計原理及在MCU200T上仿真測試
NMSIS神經網絡庫使用介紹
構建CNN網絡模型并優化的一般化建議
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作
人工智能工程師高頻面試題匯總:循環神經網絡篇(題目+答案)
液態神經網絡(LNN):時間連續性與動態適應性的神經網絡

神經網絡的并行計算與加速技術
無刷電機小波神經網絡轉子位置檢測方法的研究
神經網絡專家系統在電機故障診斷中的應用
神經網絡RAS在異步電機轉速估計中的仿真研究
基于FPGA搭建神經網絡的步驟解析




 工商網監
工商網監
評論