 AMD承諾不會砍掉Infinity Cache緩存技術
AMD承諾不會砍掉Infinity Cache緩存技術

昨晚AMD發布了RX 6700 XT顯卡,這是RDNA2架構家族第二波產品,國內售價3699元,針對友商的RTX 3070顯卡。
在AMD的RDNA2架構中,有一項獨特的技術很重要,那就是Infinity Cache(無限緩存),這是一種高速緩存,靈感來自于Zen架構CPU,它能夠以低功耗和低延遲提供卓越的帶寬性能。
整個顯卡核心均可訪問此全局高速緩存,有助于捕捉即時的重用機會,從而能夠快速訪問數據。
根據AMD的說法,Infinity Cache 充當著海量帶寬放大器的角色,實現的有效帶寬最高可達256位16Gbps GDDR6的3.25 倍。
在RX 6800/6900系列顯卡上,AMD就靠著128MB Infinity Cache+ 256bit GDDR6 顯存的方案相比傳統的 384bit GDDR6 顯存帶寬翻倍,而且功耗還更低。
在RX 6700 XT的Navi 22核心上,AMD的Infinity Cache砍了一部分,只剩下96MB,匹配192bit位寬。
未來還會有Navi 23核心,顯卡對應的應該是RX 6600系列,那它的Infinity Cache技術會不會砍掉呢?畢竟成本還是挺高的。
答案是不會,已經有網友在Linux代碼中發現了線索,Navi 23會給每個顯存通道分配4MB Infinity Cache緩存,而顯卡應該是128bit位寬,也就是8個32bit GDDR6,所以Infinity Cache容量會減少到32MB。
總之,這個技術對提高帶寬很有幫助,雖然成本高了點,但AMD依然會保留在低端的Navi 23核心上,RX 6600系列顯卡也不會閹割太狠。
責編AJX
-
amd
+關注
關注
25文章
5684瀏覽量
139968 -
顯卡
+關注
關注
16文章
2520瀏覽量
71503 -
緩存
+關注
關注
1文章
248瀏覽量
27761
發布評論請先 登錄
KeepAlive:組件緩存實現深度解析
C語言的緩沖區(緩存)詳解
從NOR轉向使用CS SD NAND:為什么必須加入緩存(Cache)機制?

AMD UltraScale架構:高性能FPGA與SoC的技術剖析
串口DMA發送有緩存嗎?
今日看點丨華為發布AI推理創新技術UCM;比亞迪汽車出口暴增130%
緩存之美:萬文詳解 Caffeine 實現原理(上)
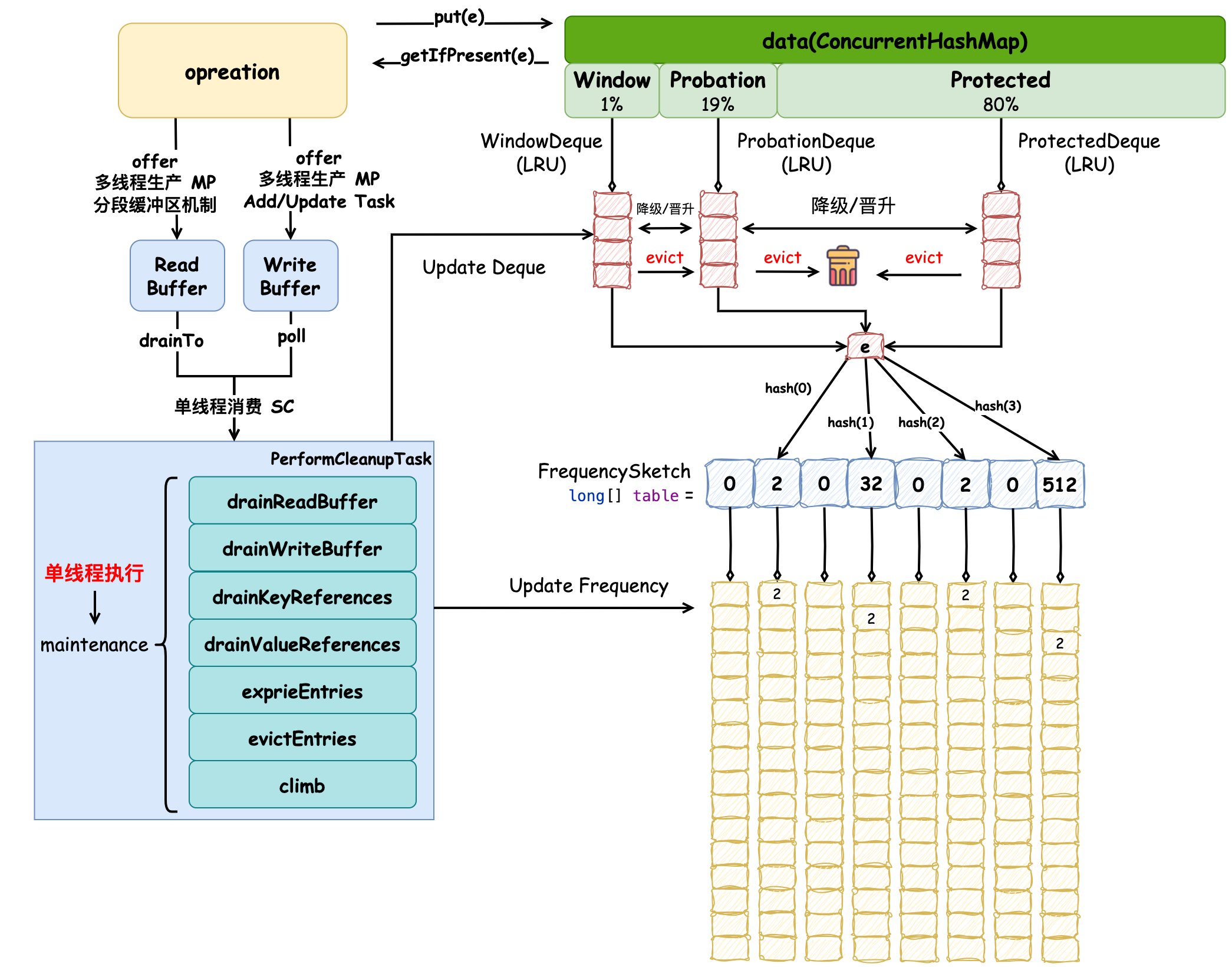
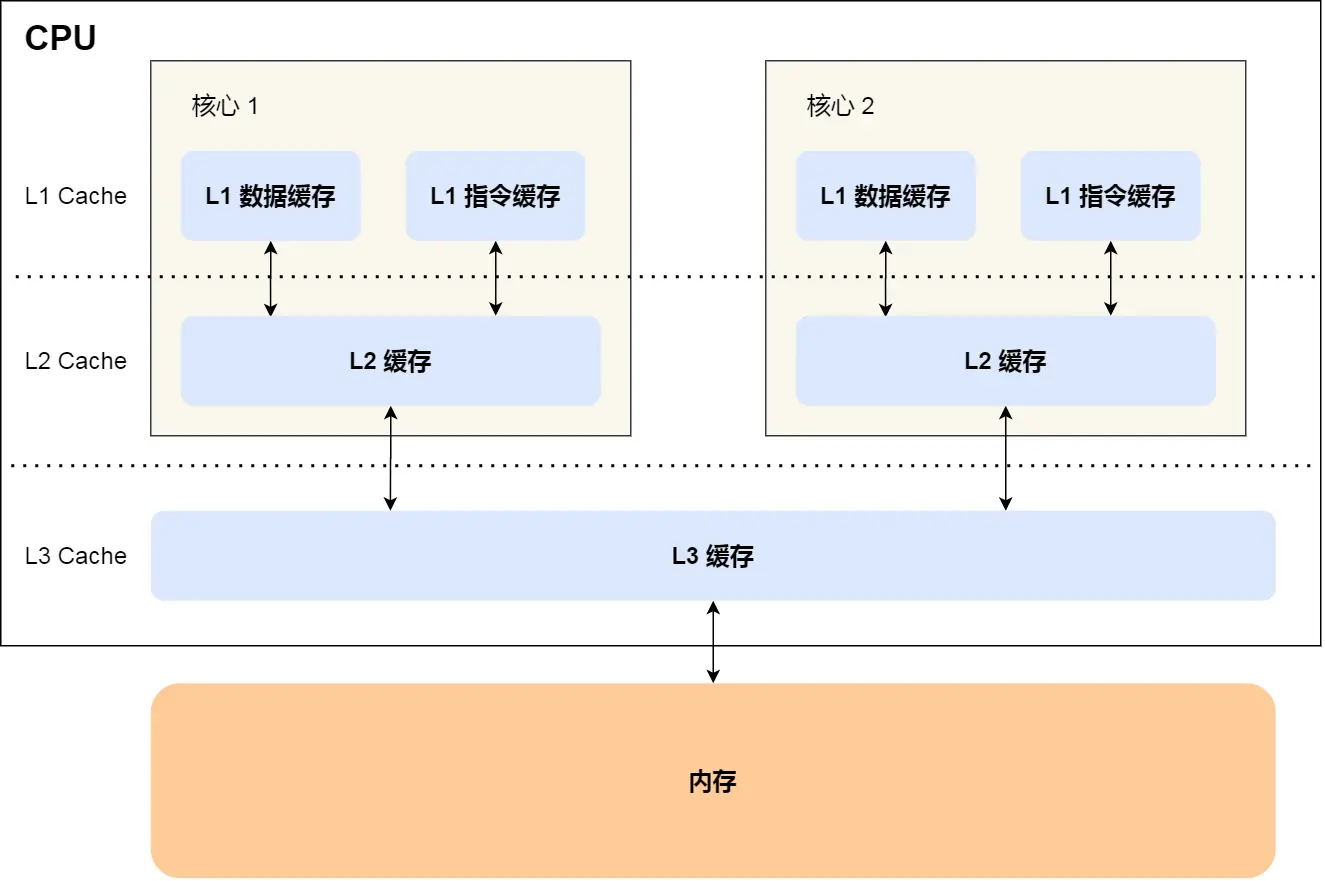
高性能緩存設計:如何解決緩存偽共享問題
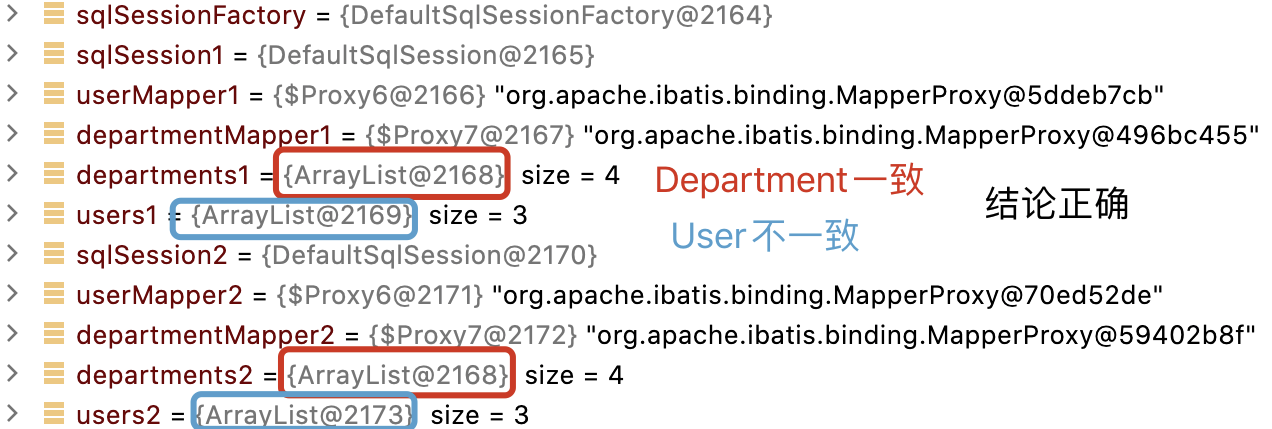
由 Mybatis 源碼暢談軟件設計(八):從根上理解 Mybatis 二級緩存
AMD收購硅光子初創企業Enosemi AMD意在CPO技術
MCU緩存設計
Nginx緩存配置詳解



 工商網監
工商網監
評論