 神經網絡中詞向量是怎么表示的?
神經網絡中詞向量是怎么表示的?

上一篇我們講到了在神經網絡出現以前的詞向量表示方法:基于同義詞詞典的方法和基于計數統計的方法。想要回顧的可以看這里小白跟學系列之手把手搭建NLP經典模型-2(含代碼)
這一篇我們要真正開始講在神經網絡中,詞向量是怎么表示的,以及它又有什么優缺點呢?
目錄
基于統計存在的問題
什么是推理?
神經網絡中輸入的單詞怎么處理?
簡單的word2vec
CBOW模型的推理
CBOW模型的學習
學習數據的準備
CBOW模型的實現
從概率角度看CBOW
總結
基于計數統計存在的問題
在海量數據的今天,基于計數統計的方法難以處理大規模的語料庫,因為統計需要一次性統計整個語料庫!實在是有點難頂。而SVD降維的復雜度又太大,于是將推出——基于推理的方法,也就是基于神經網絡的方法。
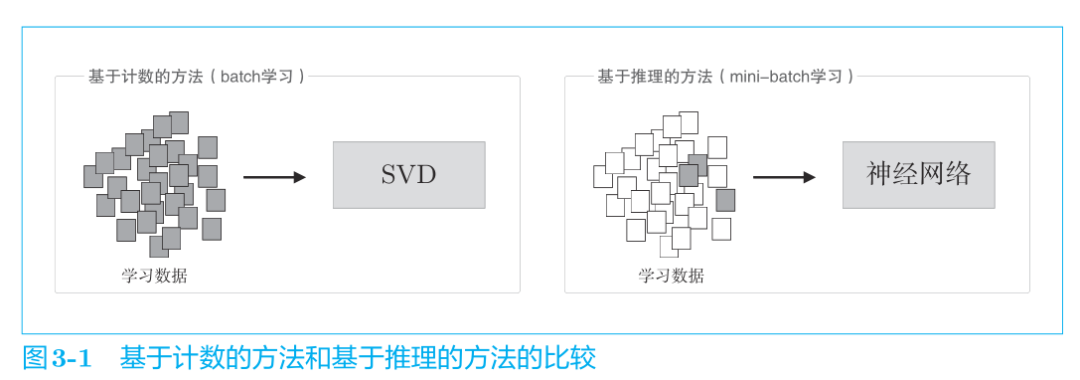
神經網絡一次只需要處理一個mini-batch的數據進行學習,并且反復更新網絡權重,使神經網絡能夠正確預測結果。
基于推理的方法以預測為目標,同時獲得了作為副產品的單詞分布式表示。也就是說,模型學習的最終目的是能夠預測正確的結果,而在學習的過程中,我們意外的獲得了單詞的分布式表示。
如果看不懂也沒有關系,這里只是擺出了最終的結論,接著往下看。
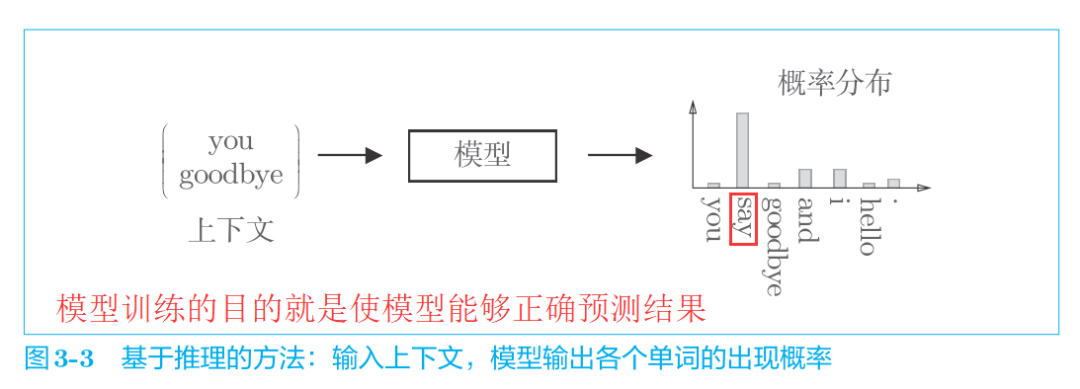
什么是推理?
當給出周圍的單詞(上下文)時,預測"?"處會出現什么單詞。

也就是說,基于推理的方法和基于計數的方法一樣,也是基于分布式假設的,即“單詞含義由其周圍的單詞構成”。
輸入單詞的處理方法
將輸入文本寫為one-hot向量
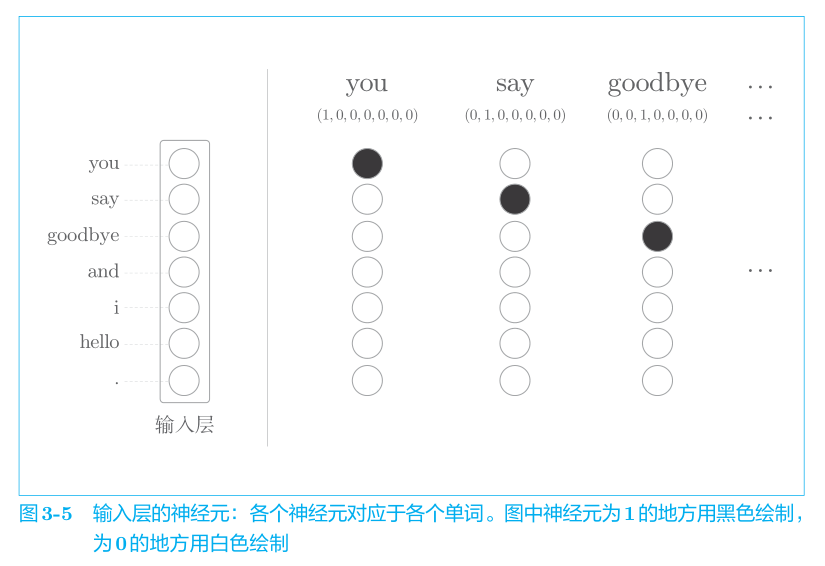
和之前的方法一樣,不管什么模型都無法直接輸入文本本身,模型只“看得懂”數字,因此我們需要先將單詞轉化為固定長度的向量。對此,一種方式是將單詞轉換為 one-hot向量。在 one-hot 表示中,只有一個元素是 1,其他元素都是 0。還是以“You say goodbye and I say hello.”這一語料作為例子,表示成one-hot向量即如下所示:

像這樣,將單詞轉化為固定長度的向量,神經網絡的輸入層的神經元個數也就可以固定下來(圖 3-5)。
能用向量表示單詞啦,這樣我們就可以把它們丟進神經網絡進行處理了。比如,對于one-hot表示的某個單詞,
使用全連接層的神經網絡如圖 3-6 所示。
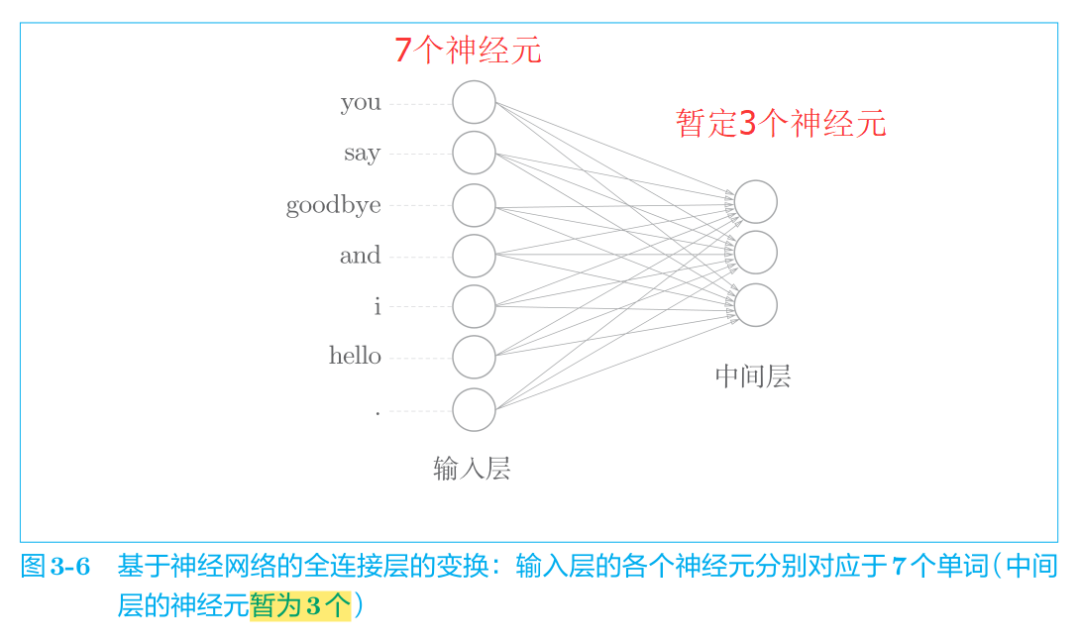
但是我們需要關注權重W的大小,因此我們將神經網絡畫成如下的形式:
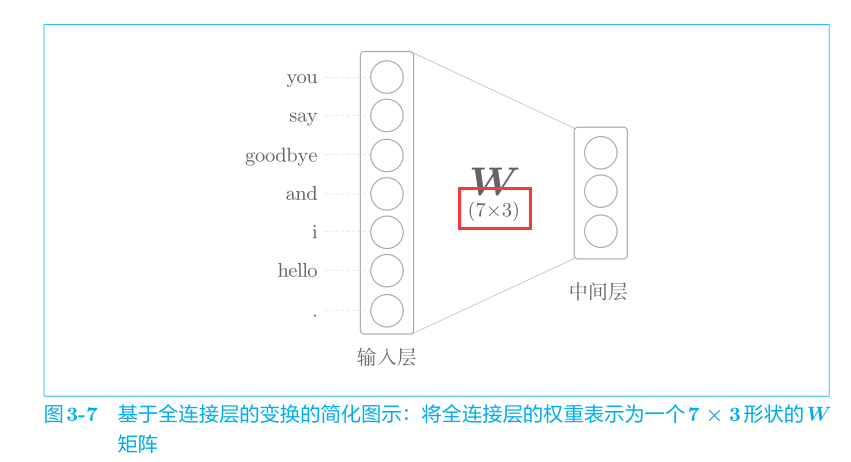
全連接層變換可以寫成如下的 Python代碼。
import numpy as np c = np.array([[1, 0, 0, 0, 0, 0, 0]]) # 輸入youW = np.random.randn(7, 3) # 權重初始值為7行3列的矩陣隨機數,且具有標準正態分布h = np.dot(c, W) # 中間隱藏層節點print(h)# [[-0.70012195 0.25204755 -0.79774592]]
這里需要注意的是因為輸入 c 是 one-hot 表示,單詞 ID 對應的元素是 1,其他地方都是 0。因此,上述代碼中的 c × W 的矩陣乘積相當于“提取”權重的對應行向量。
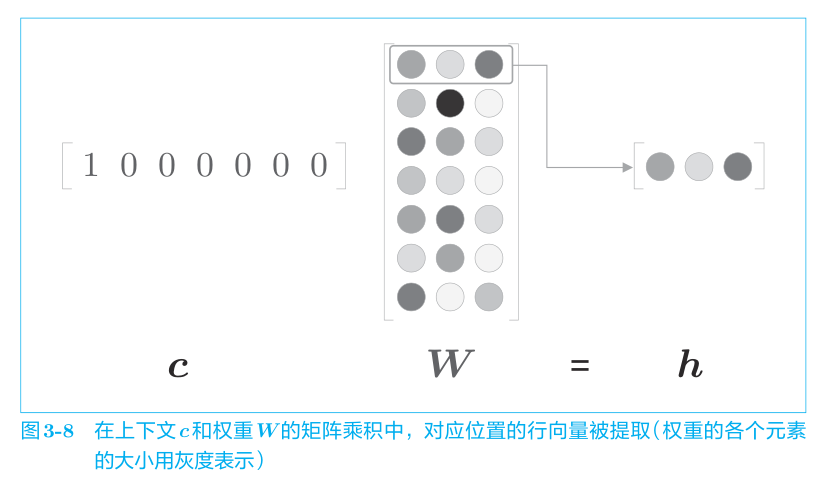
這里,僅為了提取權重的行向量而進行矩陣乘積計算好像不是很有效率。關于這一點,我們會在后續進行改進。而且乘積也可以用MatMul層(專門做矩陣乘積的層)來實現。
學習了基于推理的方法,并用代碼實現了神經網絡中單詞的處理方法,至此準備工作就完成了,現在是時候實現word2vec了。
在基于推理(神經網絡)的方法中,最著名的就是Word2Vec。接下來我們將詳細的探討word2vec的結構和如何用代碼把這個結構搭建起來。
簡單的word2vec
word2vec有兩種模型:
CBOW模型
Skip-gram模型
兩種模型的區別如下:
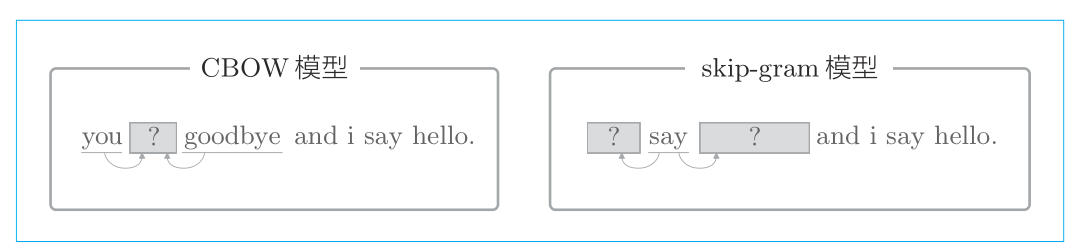
CBOW 模型是從上下文的多個單詞預測中間的單詞(目標詞),而 skip-gram 模型則從中間的單詞(目標詞)預測上下文的多個單詞。
本節我們將主要討論CBOW模型。
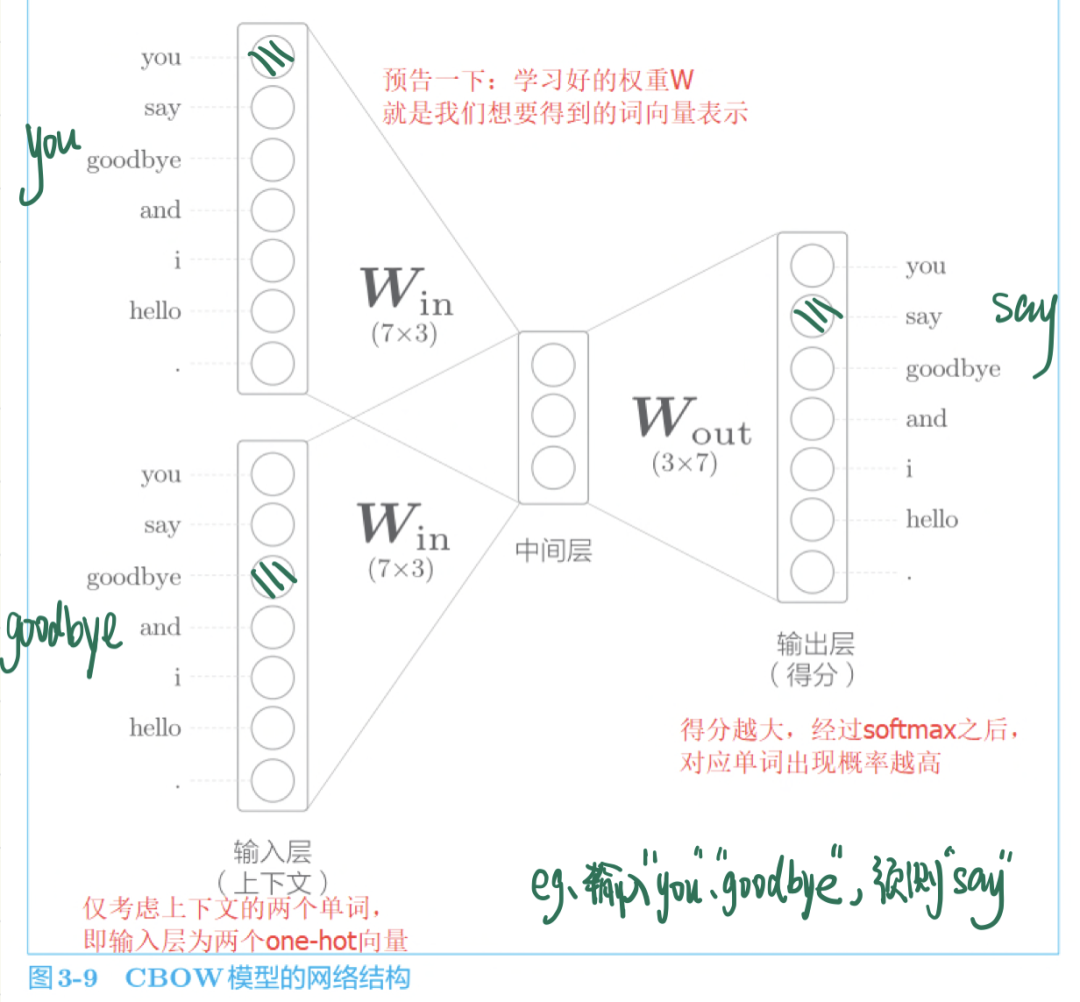
CBOW模型的推理
CBOW 模型是根據上下文預測目標詞的神經網絡(“目標詞”是指中間的單詞,它周圍的單詞是“上下文”)。通過訓練這個 CBOW 模型,使其能盡可能地進行正確的預測目標詞,我們就可以獲得中間產物——單詞的分布式表示。
提前劇透一下,這個學習好的、能正確預測結果的權重就是我們想要的單詞分布式表示。
中間層的神經元數量比輸入層少這一點很重要。中間層需要將預測單詞所需的信息壓縮保存,從而產生密集的向量表示。這時,中間層被寫入了我們人類無法解讀的代碼,相當于 “編碼” 工作。而從中間層的信息獲得期望結果的過程則稱為 “解碼” 。這一過程將被編碼的信息復原為我們可以理解的形式。
我們從層的角度來看看這個CBOW模型:
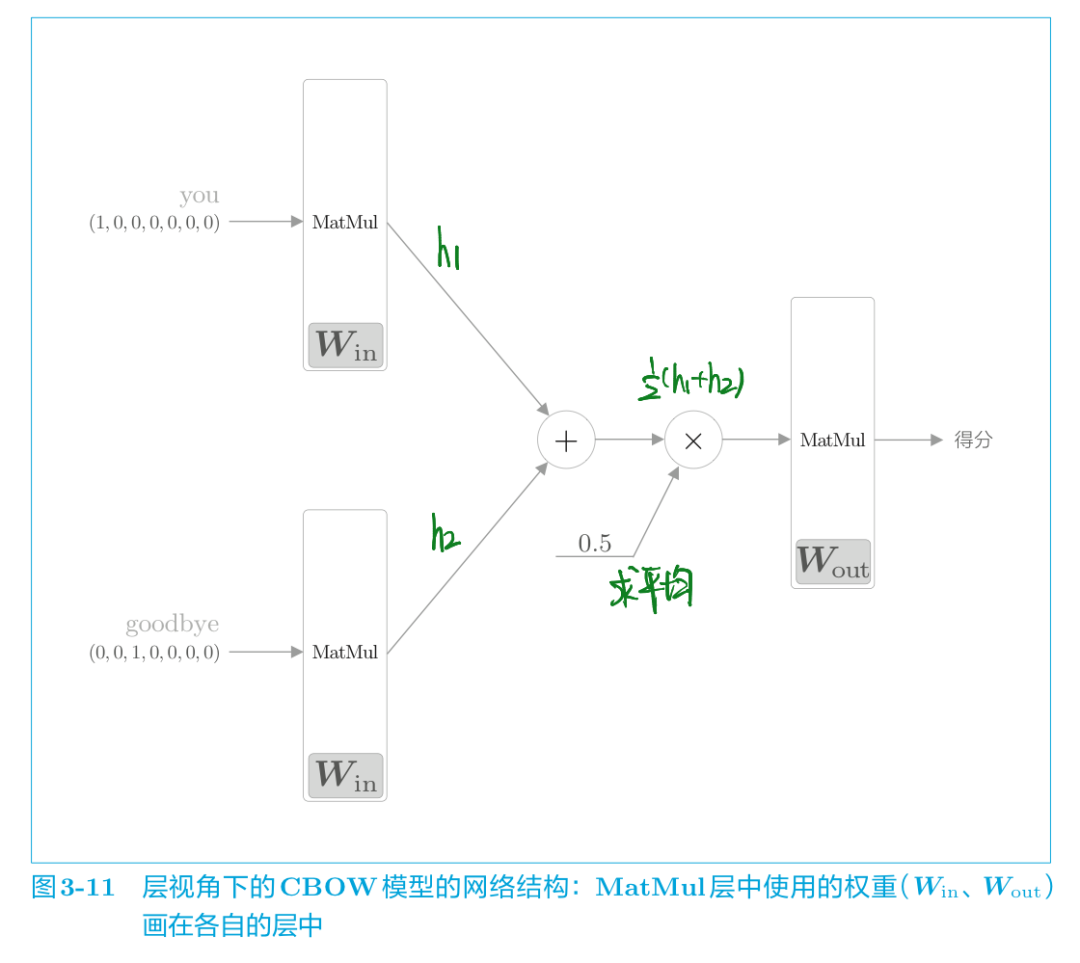
如圖 3-11 所示,CBOW 模型一開始有兩個 MatMul 層,這兩個層的輸出被加在一起。然后,對這個相加后得到的值乘以 0.5 求平均,可以得到中間層的神經元。最后,將另一個 MatMul 層應用于中間層的神經元,輸出得分。
MatMul 層的正向傳播,在內部會計算矩陣乘積。
接下來用代碼實現 CBOW 模型的推理(即求得分的過程) ,具體實現如下所示( ch03/cbow_predict.py ) 。
import syssys.path.append('..')import numpy as npfrom common.layers import MatMul # 樣本的上下文數據c0 = np.array([[1, 0, 0, 0, 0, 0, 0]]) # youc1 = np.array([[0, 0, 1, 0, 0, 0, 0]]) # goodbye # 權重的初始值W_in = np.random.randn(7, 3)W_out = np.random.randn(3, 7) # 生成層in_layer0 = MatMul(W_in)in_layer1 = MatMul(W_in)out_layer = MatMul(W_out) # 正向傳播h0 = in_layer0.forward(c0)h1 = in_layer1.forward(c1)h = 0.5 * (h0 + h1)s = out_layer.forward(h)print(s) # [[ 0.30916255 0.45060817 -0.77308656 0.22054131 0.15037278# -0.93659277 -0.59612048]]
輸出側的MatMul層共享權重W_in。
以上是沒有使用激活函數的簡單網絡結構,接下來看看CBOW模型的學習(也就是添加激活函數后得到概率)。
CBOW模型的學習
推理完了得到得分,加上激活函數就得到結果的概率,這個概率就表示哪個單詞會出現在給定的上下文(周圍單詞)中間。
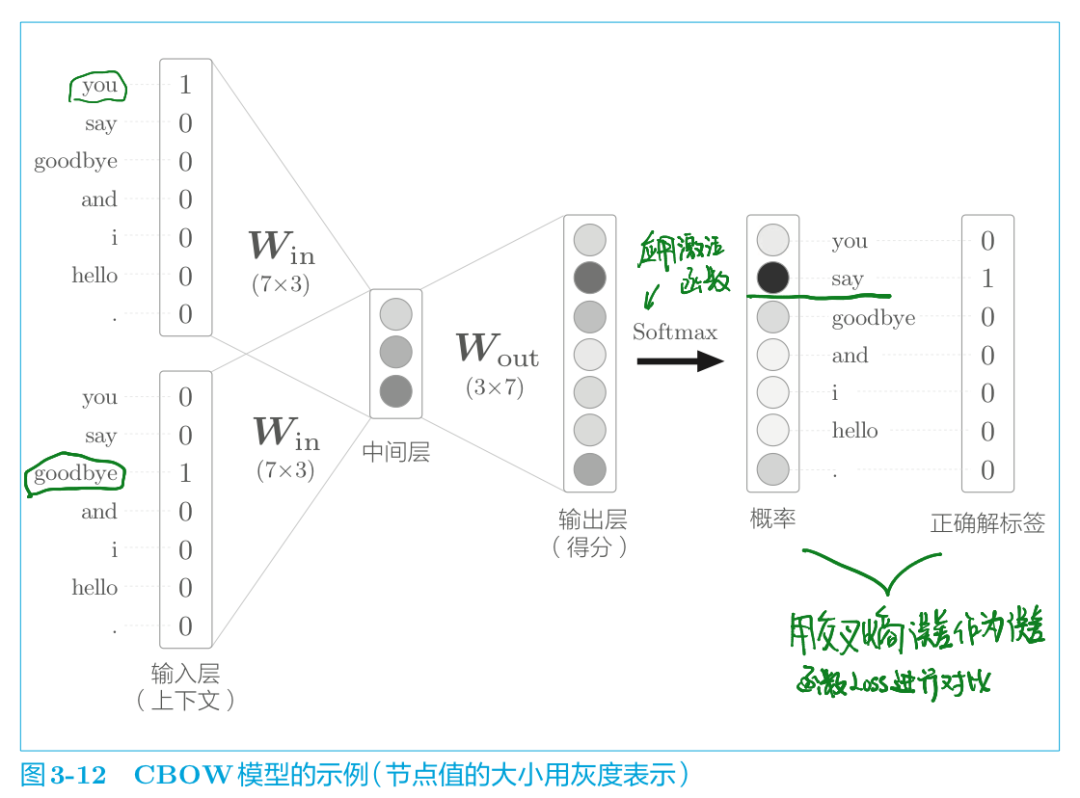
說白了,CBOW模型的學習就是調整權重參數,以使預測結果更加準確。評估預測是否準確的一大指標就是預測的結果和正確的結果之間進行對比,用什么指標去比對呢?用交叉熵誤差量化對比模型預測的概率和正確結果之間的差距(也就是loss值),并且反饋給前面的權重參數W并進行參數W的調整,從而不斷的減小與正確結果之間的距離,這就是模型訓練、學習的過程。
從層的角度表示如下:
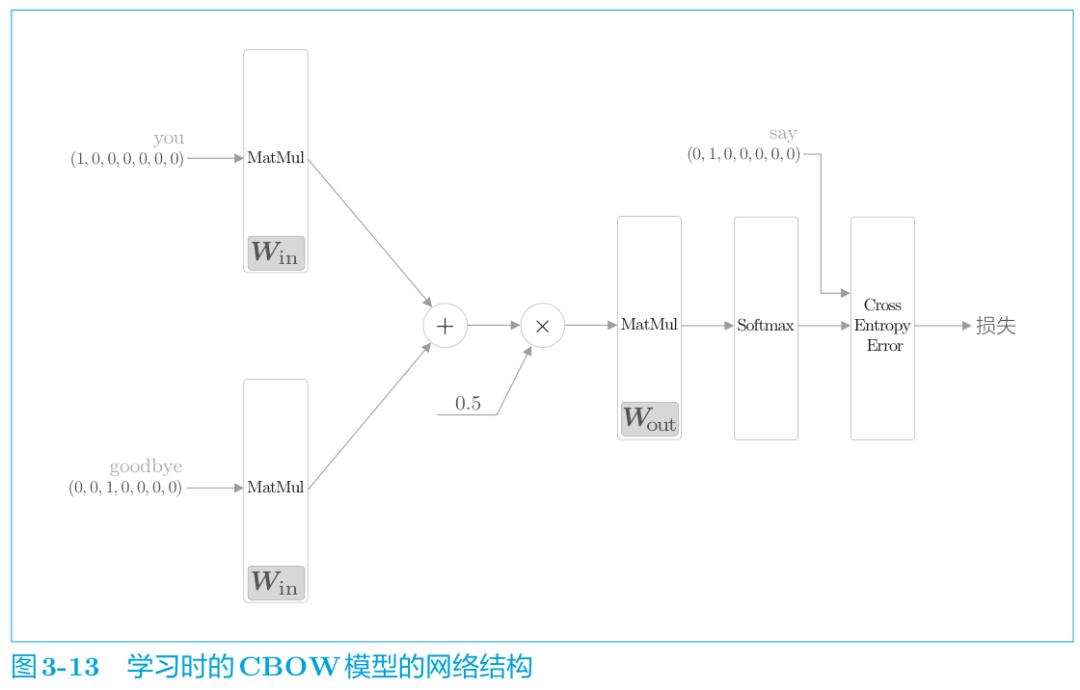
CBOW模型的學習,只需在 CBOW 模型的推理上加上Softmax 層和 Cross Entropy Error 層,就可以得到損失。這就是 CBOW模型的正向傳播。
那么學習好的模型最終獲得的權重參數是什么樣的呢?
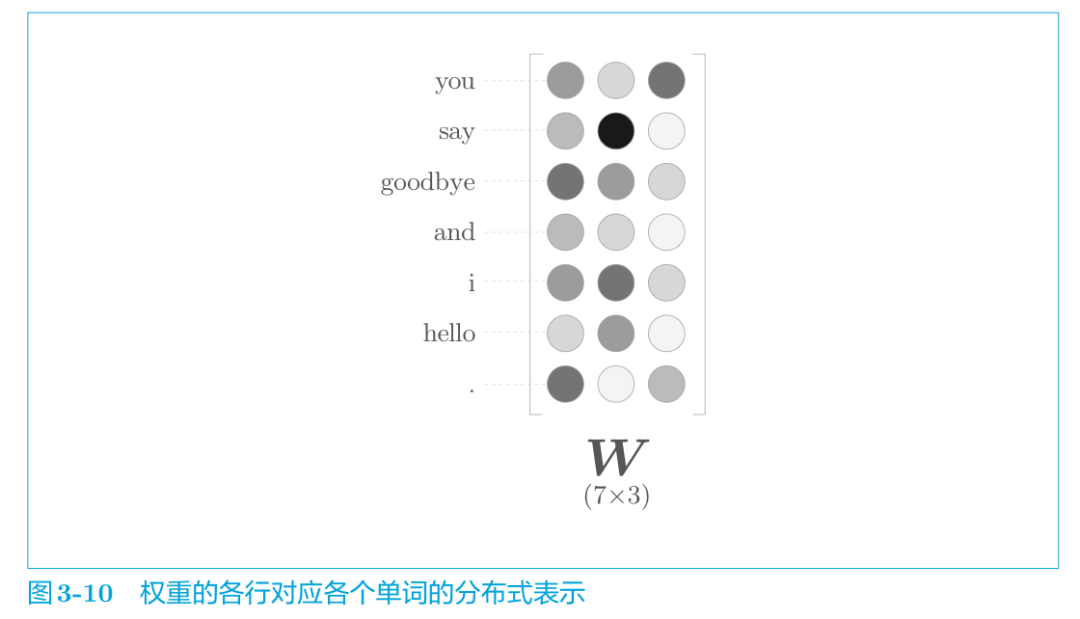
word2vec 中使用的網絡有兩個權重,分別是輸入側的權重(Win)和輸出側的權重(Wout) 。一般而言,輸入側的權重 Win 的每一行對應于各個單詞的分布式表示。或者輸出側的每一列也同樣對應各個單詞的分布式表示。
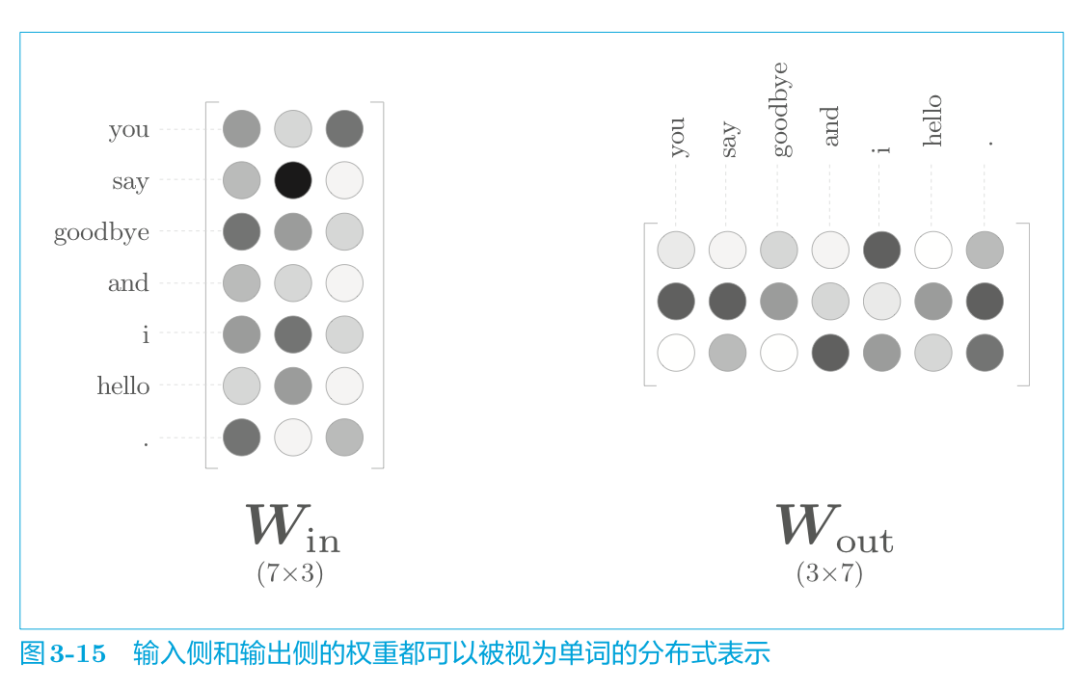
那么,我們最終應該使用哪個權重作為單詞的分布式表示呢?這里有三個選項。
A. 只使用輸入側的權重
B. 只使用輸出側的權重
C. 同時使用兩個權重
就 word2vec(特別是 skip-gram 模型)而言,最受歡迎的是方案 A。在這里我們也使用Win作為詞向量。而在與 word2vec 相似的 GloVe[27]詞向量表示方法中,使用C方案將兩個權重相加,也獲得了良好的結果。
模型搭建好了,我們還要對輸入數據進行預處理。
學習數據的準備
我們上面有說過,模型沒法直接"認識"文本,而只認識數字,所以我們首先需要將輸入數據轉化為one-hot向量表示。這里仍以“You say goodbye and I say hello.”為例。
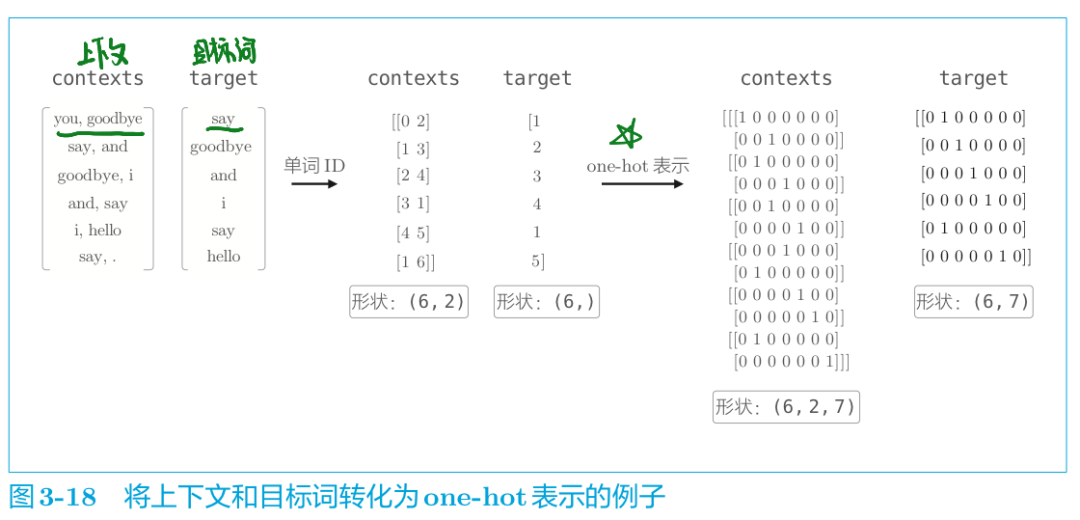
代碼實現數據預處理如下:
import syssys.path.append('..')from common.util import preprocess, create_contexts_target,convert_one_hot text = 'You say goodbye and I say hello.' corpus, word_to_id, id_to_word = preprocess(text) contexts, target = create_contexts_target(corpus, window_size=1) vocab_size = len(word_to_id)target = convert_one_hot(target, vocab_size)contexts = convert_one_hot(contexts, vocab_size)
convert_one_hot() 函數實現了將單詞 ID 轉化為 one-hot 表示,內容很簡單,代碼在 common/util.py 中。
至此,學習數據的準備就完成了,下面我們來討論最重要的 CBOW 模型的實現。
CBOW模型的實現
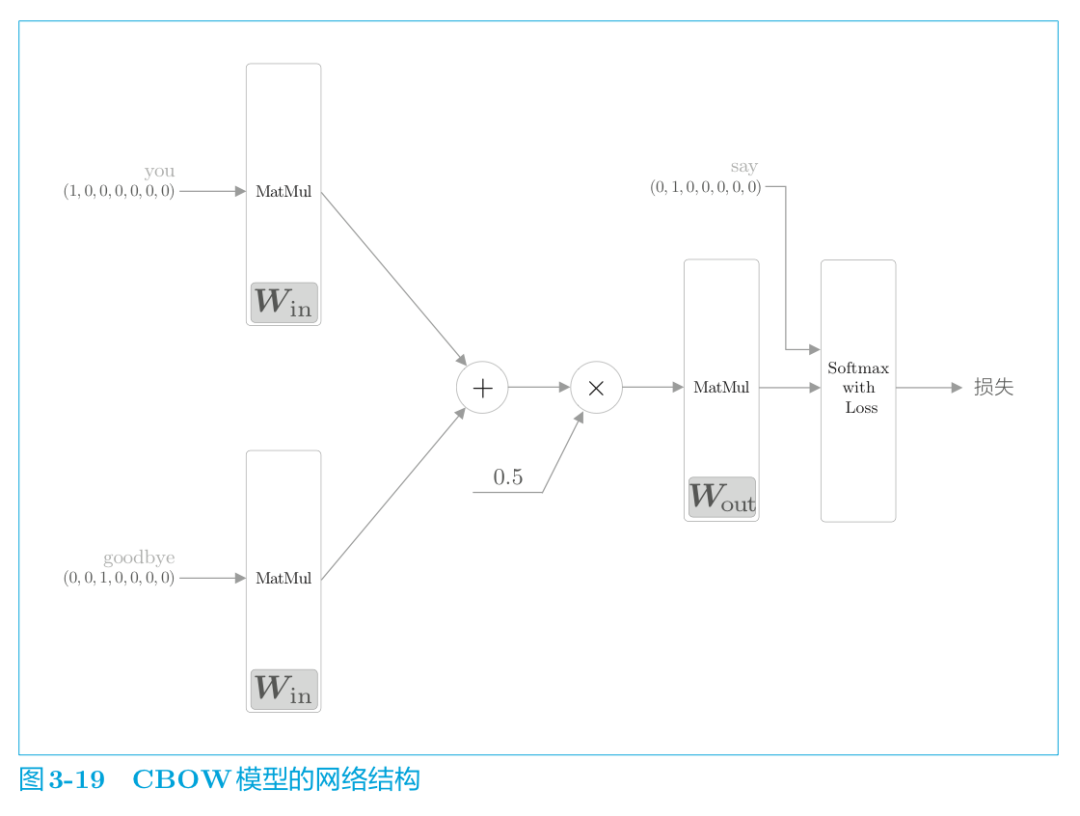
根據CBOW模型的網絡結構圖,將該神經網絡實現為 SimpleCBOW 類(下一節將對其進行改進為 CBOW 類) 。首先,讓我們看一下 SimpleCBOW 類的初始化方法( ch03/simple_cbow.py ) 。
模型的初始化代碼
import syssys.path.append('..')import numpy as npfrom common.layers import MatMul, SoftmaxWithLoss class SimpleCBOW: def __init__(self, vocab_size, hidden_size): # 詞匯數:vocab_size ;中間層神經元個數:hidden_size V, H = vocab_size, hidden_size # 初始化權重,用一些小的隨機值初始化 W_in = 0.01 * np.random.randn(V, H).astype('f') W_out = 0.01 * np.random.randn(H, V).astype('f') # 生成層 self.in_layer0 = MatMul(W_in) self.in_layer1 = MatMul(W_in) self.out_layer = MatMul(W_out) self.loss_layer = SoftmaxWithLoss() # 將所有的權重和梯度整理到列表中 layers = [self.in_layer0, self.in_layer1, self.out_layer] self.params, self.grads = [], [] for layer in layers: self.params += layer.params self.grads += layer.grads # 將單詞的分布式表示設置為成員變量 self.word_vecs = W_in
指定 NumPy 數組的數據類型為 astype('f'),初始化將使用 32 位的浮點數。
實現神經網絡的正向傳播 forward() 函數代碼。該函數接收參數 contexts 和 target,并返回損失(loss)。
def forward(self, contexts, target): # 接收參數 contexts 和 target,并返回損失(loss) h0 = self.in_layer0.forward(contexts[:, 0]) h1 = self.in_layer1.forward(contexts[:, 1]) h = (h0 + h1) * 0.5 score = self.out_layer.forward(h) loss = self.loss_layer.forward(score, target) return loss
這里,假定參數 contexts 是一個三維 NumPy 數組,即圖3-18 的例子中 (6,2,7) 的形狀,其中第 0 維是 mini-batch 的數量,第 1 維是上下文的窗口大小,第 2 維表示 one-hot 向量。此外, target 是 (6,7)這樣的二維形狀。
實現反向傳播 backward()
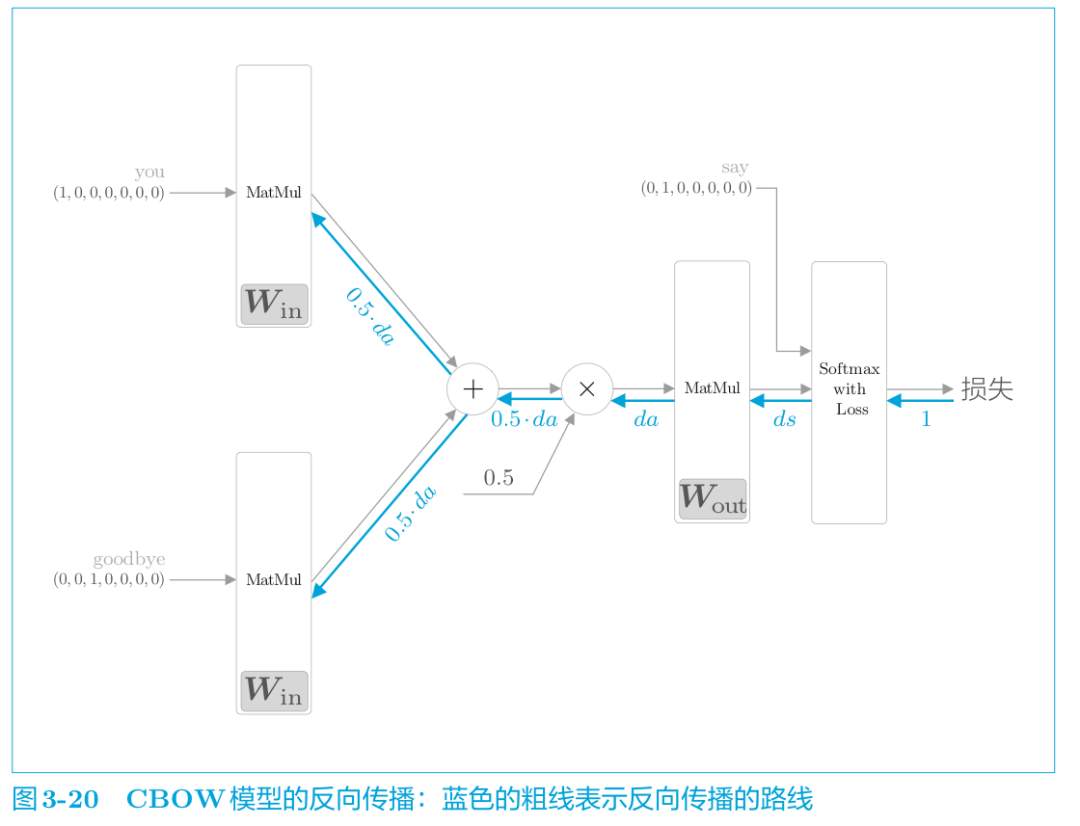
反向傳播代碼如下:
def backward(self, dout=1): ds = self.loss_layer.backward(dout) da = self.out_layer.backward(ds) da *= 0.5 self.in_layer1.backward(da) self.in_layer0.backward(da) return None
“×”的反向傳播將正向傳播時的輸入值“交換”后乘以梯度。“+”的反向傳播則將梯度“原樣”傳播。
此處正向、反向傳播已實現,通過先調用 forward() 函 數, 再調用 backward() 函數,grads 列表中的梯度被更新。
模型學習的實現
CBOW 模型的學習和一般的神經網絡的學習完全相同。
首先,給神經網絡準備好學習數據。
然后,求梯度,并逐步更新權重參數。
這里,我們使用神經網絡中的 Trainer 類來執行學習過程,學習的源代碼如下所示( ch03/train.py ) 。
模型學習的實現代碼:
import syssys.path.append('..')from common.trainer import Trainerfrom common.optimizer import Adamfrom simple_cbow import SimpleCBOWfrom common.util import preprocess, create_contexts_target,convert_one_hot window_size = 1hidden_size = 5batch_size = 3max_epoch = 1000 text = 'You say goodbye and I say hello.'corpus, word_to_id, id_to_word = preprocess(text) vocab_size = len(word_to_id)contexts, target = create_contexts_target(corpus, window_size)target = convert_one_hot(target, vocab_size)contexts = convert_one_hot(contexts, vocab_size) model = SimpleCBOW(vocab_size, hidden_size)optimizer = Adam()trainer = Trainer(model, optimizer)trainer.fit(contexts, target, max_epoch, batch_size)trainer.plot()
之后,我們都會使用Train類進行網絡的學習。使用 Trainer類, 可以理清容易變復雜的學習代碼。
結果如圖所示:
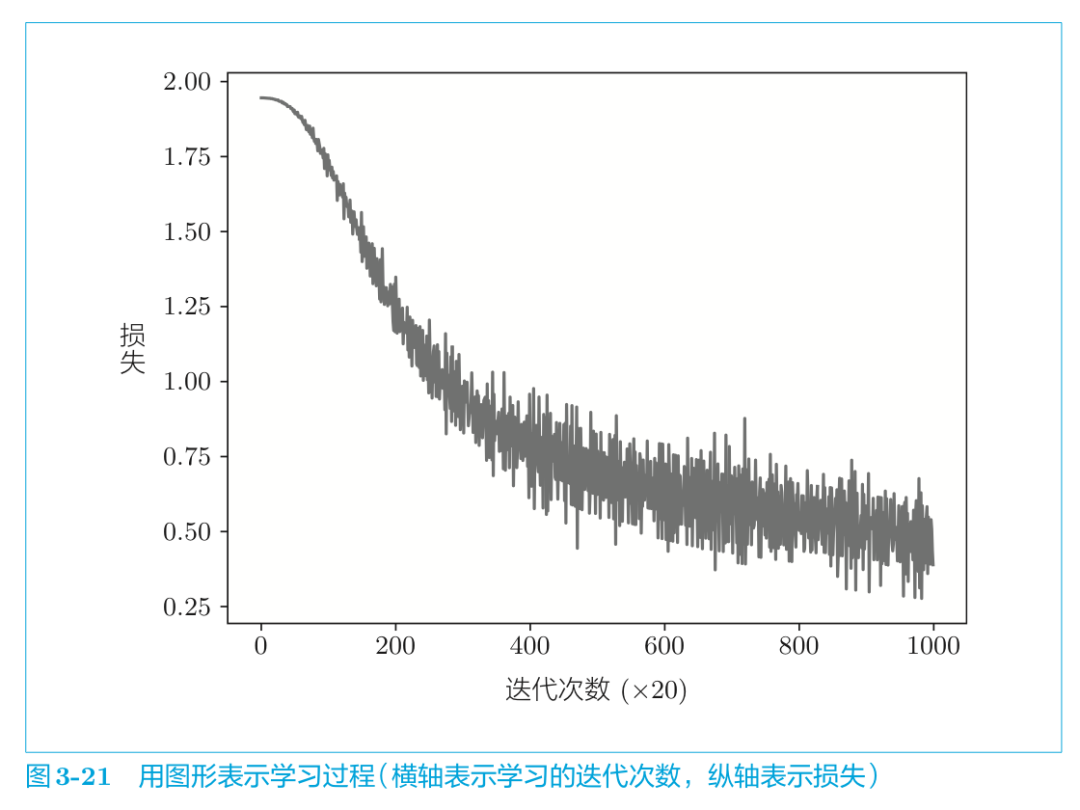
通過不斷的學習,損失的確在減小!我們再來看看學習結束后的權重W。我們取出剛剛保存的輸入側的權重。
word_vecs = model.word_vecs for word_id, word in id_to_word.items(): print(word, word_vecs[word_id])
word_vecs 的各行保存了對應的單詞 ID 的分布式表示。結果如下所示:
you [-0.9031807 -1.0374491 -1.4682057 -1.3216232 0.93127245]say [ 1.2172916 1.2620505 -0.07845993 0.07709391 -1.2389531 ]goodbye [-1.0834033 -0.8826921 -0.33428606 -0.5720131 1.0488235 ]and [ 1.0244362 1.0160093 -1.6284224 -1.6400533 -1.0564581]i [-1.0642933 -0.9162385 -0.31357735 -0.5730831 1.041875 ]hello [-0.9018145 -1.035476 -1.4629668 -1.3058501 0.9280102]. [ 1.0985303 1.1642815 1.4365371 1.3974973 -1.0714306]
我們終于將單詞表示為了密集向量!這就是單詞的分布式表示。
不過,由于這里使用的語料庫因為太小了所以并沒有給出很好的結果。如果換成更大的語料庫,相信會獲得更好的結果。但是,如果語料庫太大,在處理速度方面又會出現新的問題,因為當前這個 CBOW 模型的實現在處理效率方面存在幾個問題。下一節我們將改進這個簡單的 CBOW 模型,實現一個“真正的”、更快的CBOW 模型。
從概率角度看CBOW
我們從概率角度再來看一下CBOW模型。首先說明幾個概率的表示方法。
由概率統計所學,我們知道:
P(A):表示A發生的概率;
P(A,B):表示A,B同時發生的概率;(聯合概率)
P(A|B):B發生時A發生的概率。(后驗概率)
已知CBOW模型的原理是已知上下文而預測目標詞。

我們用數學式來表示當給定上下文 wt?1和 wt+1時目標詞為 wt 的概率。即使用后驗概率,有式 (3.1):

式 (3.1) 表示“在 wt?1和 wt+1發生后,wt發生的概率” 。也就是說,CBOW 模型可以建模為式 (3.1)。
而且使用式 (3.1)可以簡潔地表示CBOW 模型的損失函數。
將原交叉熵誤差函數式以概率的形式來表示就是:
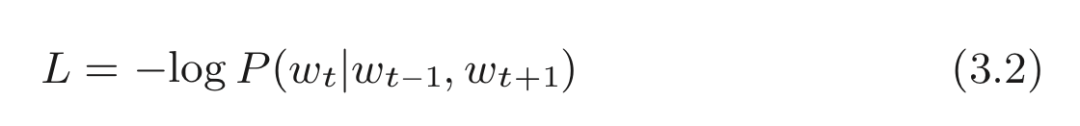
CBOW 模型的損失函數只是對式 (3.1) 的概率取 log,并加上負號,這也稱為負對數似然(negative log likelihood) 。式 (3.2) 是一筆樣本數據的損失函數。如果將其擴展到整個語料庫,則損失函數可以寫為:
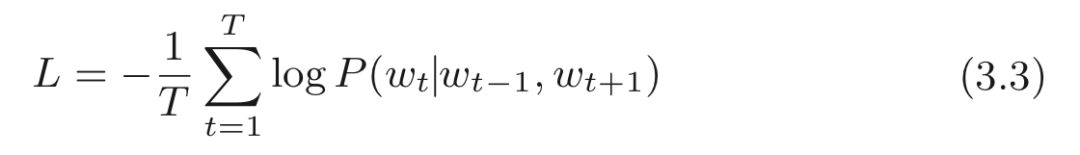
CBOW 模型學習的任務就是讓式 (3.3) 表示的損失函數盡可能地小。學習好的權重參數就是我們想要的單詞的分布式表示。這里,我們只考慮了窗口大小為 1 的情況,不過其他的窗口大小(或者窗口大小為 m 的一般情況) 也很容易用數學式表示。
理解了 CBOW 模型的實現,在實現 skip-gram 模型時也就不存在什么難點了。這里就不再介紹 skip-gram 模型的實現。詳細代碼可以參考 ch03/simple_skip_gram.py 。
總結
到目前為止,我們已經了解了基于計數的方法和基于神經網絡的方法(特別是 word2vec) 。基于計數的方法通過對整個語料庫的統計數據進行一次學習來獲得單詞的分布式表示,而基于推理的方法則通過反復觀察語料庫的一部分數據進行學習(mini-batch 學習) 。
如果需要向詞匯表添加新詞匯并更新詞向量。
基于計數的方法:需要從頭開始計算,重新生成共現矩陣、進行SVD降維等操作。
而基于神經網絡的方法:允許參數的增量學習。可以將之前學習好的權重參數作為初始值繼續學習更新權重參數。
但是現階段的CBOW模型在學習效率上還存在一些問題。下一節我們將改進這個CBOW模型,使其更加高效的學習詞向量表示。
原文標題:師妹問我:如何在7分鐘內徹底搞懂word2vec?
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107770 -
機器學習
+關注
關注
66文章
8553瀏覽量
136948 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:師妹問我:如何在7分鐘內徹底搞懂word2vec?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

神經網絡的初步認識

自動駕駛中常提的卷積神經網絡是個啥?

CNN卷積神經網絡設計原理及在MCU200T上仿真測試
NMSIS神經網絡庫使用介紹
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作
液態神經網絡(LNN):時間連續性與動態適應性的神經網絡
神經網絡的并行計算與加速技術
無刷電機小波神經網絡轉子位置檢測方法的研究
神經網絡專家系統在電機故障診斷中的應用
神經網絡RAS在異步電機轉速估計中的仿真研究
基于FPGA搭建神經網絡的步驟解析




 工商網監
工商網監
評論