 超生動圖解LSTM和GPU,讀懂循環神經網絡!
超生動圖解LSTM和GPU,讀懂循環神經網絡!

AI識別你的語音、回答你的問題、幫你翻譯外語,都離不開一種特殊的循環神經網絡(RNN):長短期記憶網絡(Long short-term memory,LSTM)。 最近,國外有一份關于LSTM及其變種GRU(Gated Recurrent Unit)的圖解教程非常火。教程先介紹了這兩種網絡的基礎知識,然后解釋了讓LSTM和GRU具有良好性能的內在機制。當然,通過這篇文章,還可以了解這兩種網絡的一些背景。 圖解教程的作者Michael Nguyen是一名AI語音助理方面的機器學習工程師。
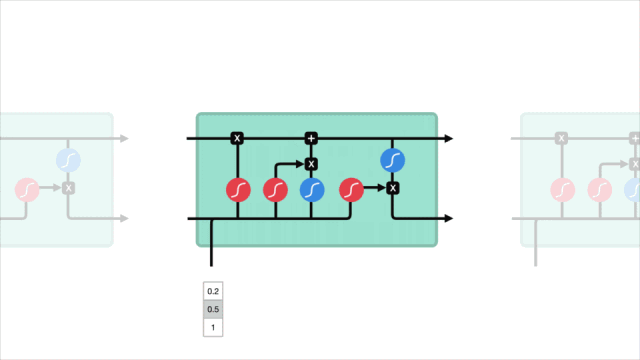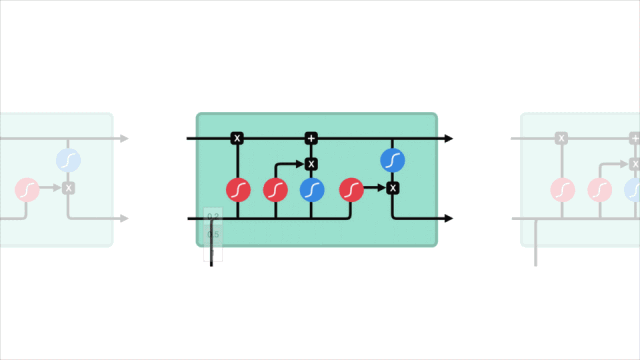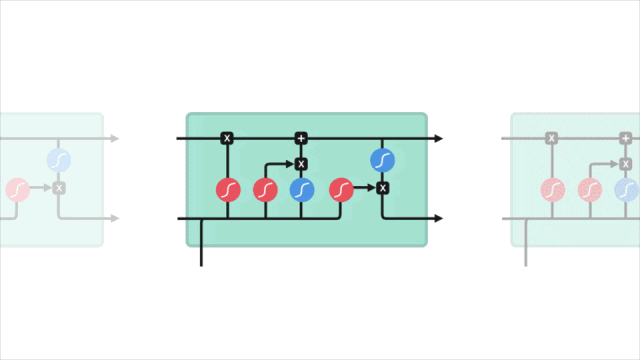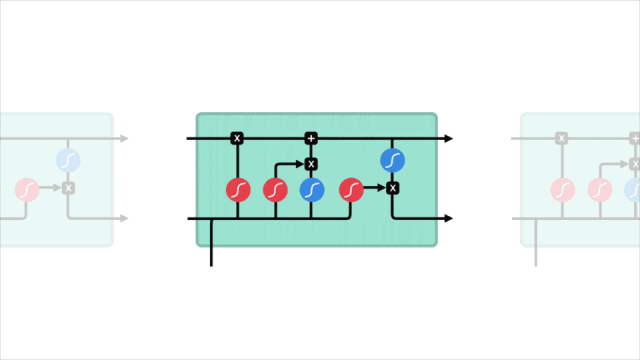
短期記憶問題
RNN受限于短期記憶問題。如果一個序列足夠長,那它們很難把信息從較早的時間步傳輸到后面的時間步。因此,如果你嘗試處理一段文本來進行預測,RNN可能在開始時就會遺漏重要信息。 在反向傳播過程中,RNN中存在梯度消失問題。梯度是用于更新神經網絡權重的值,梯度消失問題是指隨著時間推移,梯度在傳播時會下降,如果梯度值變得非常小,則不會繼續學習。

△梯度更新規則
因此,在RNN中,梯度小幅更新的網絡層會停止學習,這些通常是較早的層。由于這些層不學習,RNN無法記住它在較長序列中學習到的內容,因此它的記憶是短期的。關于RNN的更多介紹,可訪問:
https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9
解決方案:LSTM和GRU
LSTM和GRU是克服短期記憶問題提出的解決方案,它們引入稱作“門”的內部機制,可以調節信息流。
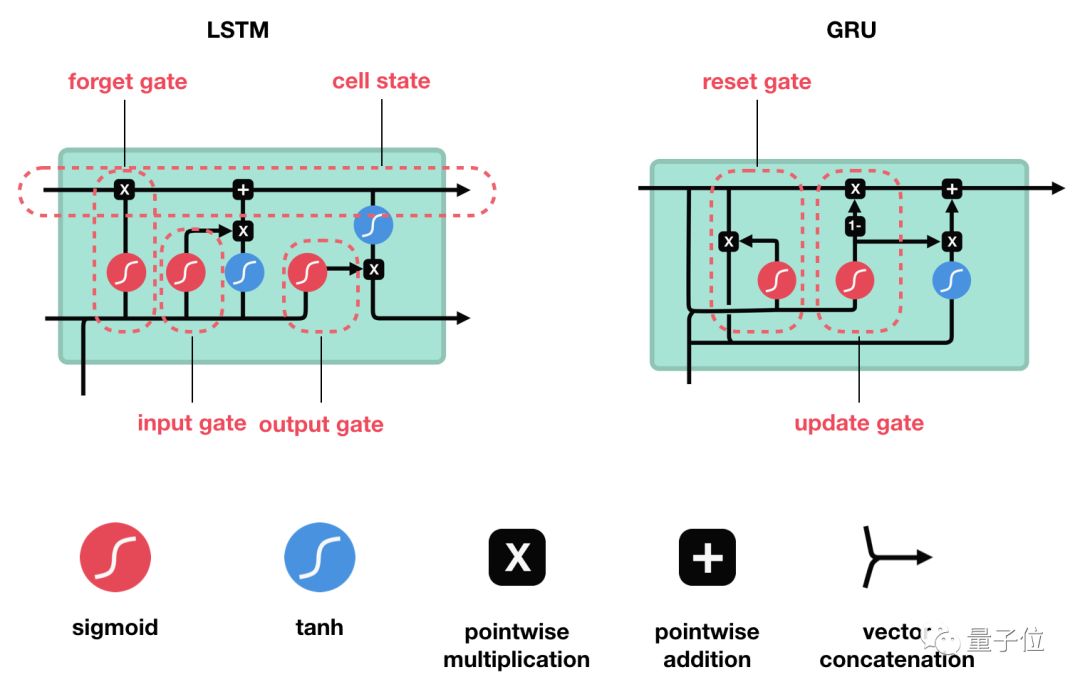
這些門結構可以學習序列中哪些數據是要保留的重要信息,哪些是要刪除的。通過這樣做,它可以沿著長鏈序列傳遞相關信息來執行預測。幾乎所有基于RNN的先進結果都是通過這兩個網絡實現的。LSTM和GRU經常用在語音識別、語音合成和文本生成等領域,還可用來為視頻生成字幕。 當你看完這篇文章時,我相信你會對LSTM和GRU在處理長序列的突出能力有充分了解。下面我將通過直觀解釋和插圖來進行介紹,并盡可能繞開數學運算。
直觀認識
我們從一個思考實驗開始。當你在網絡上購買生活用品時,一般會先閱讀商品評論來判斷商品好壞,以確定是否要購買這個商品。
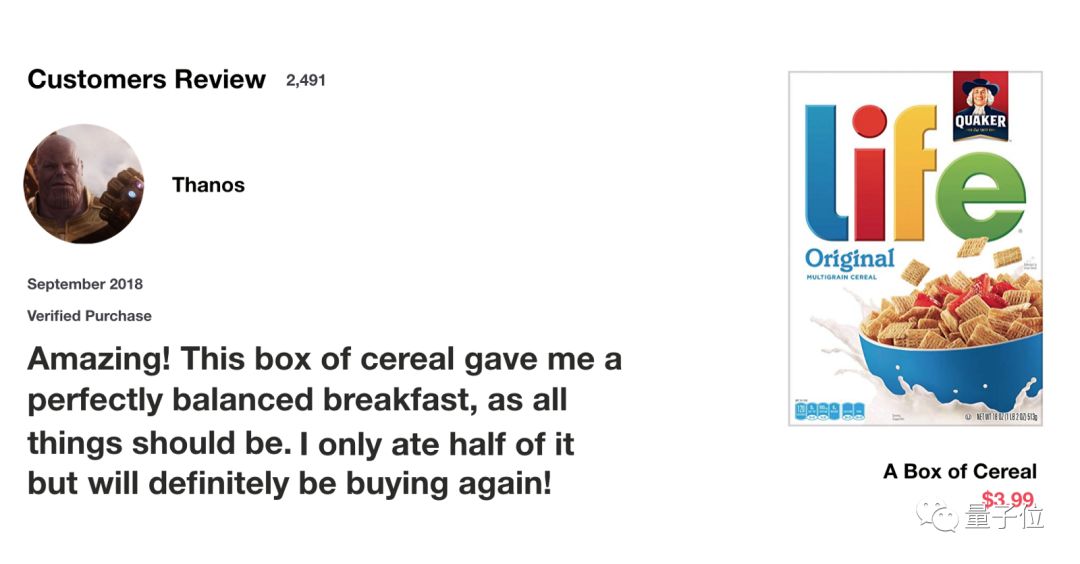
當你查看評論時,你的大腦下意識地只會記住重要的關鍵詞。你會選擇“amazing”和“perfectly balanced breakfast”這樣的詞匯,而不太關心“this”,“give”,“all”,“should”等字樣。如果有人第二天問你評論內容,你可能不會一字不漏地記住它,而是記住了主要觀點,比如“下次一定還來買”,一些次要內容自然會從記憶中逐漸消失。

在這種情況下,你記住的這些詞能判定了這個餐廳的好壞。這基本上就是LSTM或GRU的作用,它可以學習只保留相關信息來進行預測,并忘記不相關的數據。
RNN回顧
為了理解LSTM或GRU如何實現這一點,接下來回顧下RNN。RNN的工作原理如下:首先單詞被轉換成機器可讀的向量,然后RNN逐個處理向量序列。
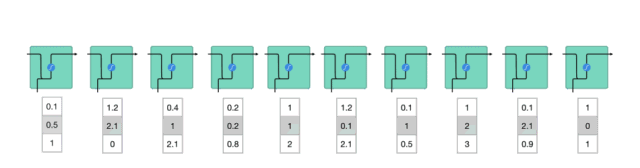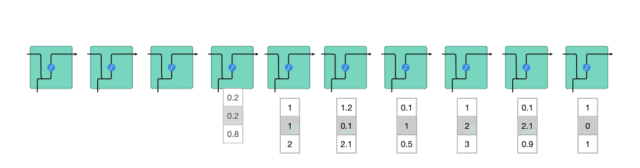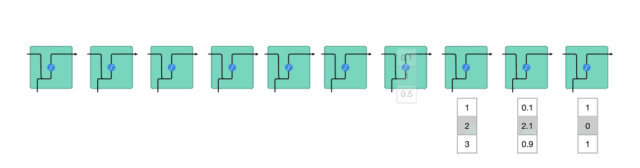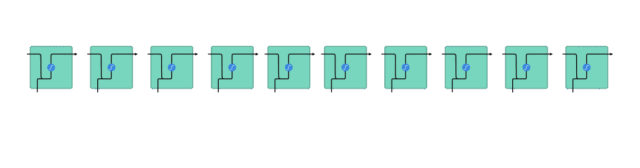
△逐個處理向量序列
在處理時,它把先前的隱藏狀態傳遞給序列的下一步,其中隱藏狀態作為神經網絡記憶,它包含相關網絡已處理數據的信息。
△把隱藏狀態傳遞給下個時間步
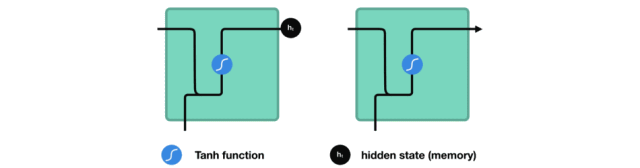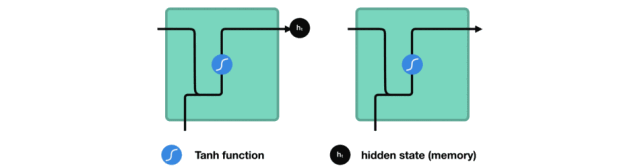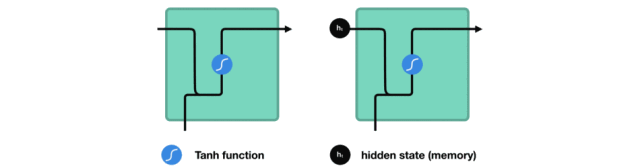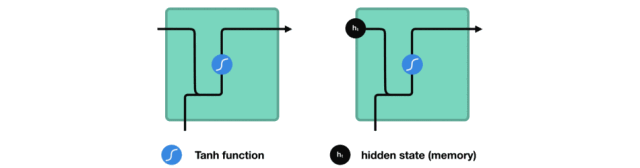
下面來介紹RNN中每個cell單元是如何計算隱藏狀態的。首先,將輸入和先前隱藏狀態組合成一個向量,向量中含有當前輸入和先前輸入的信息。這個向量再經過激活函數Tanh后,輸出新的隱藏狀態,或網絡記憶。
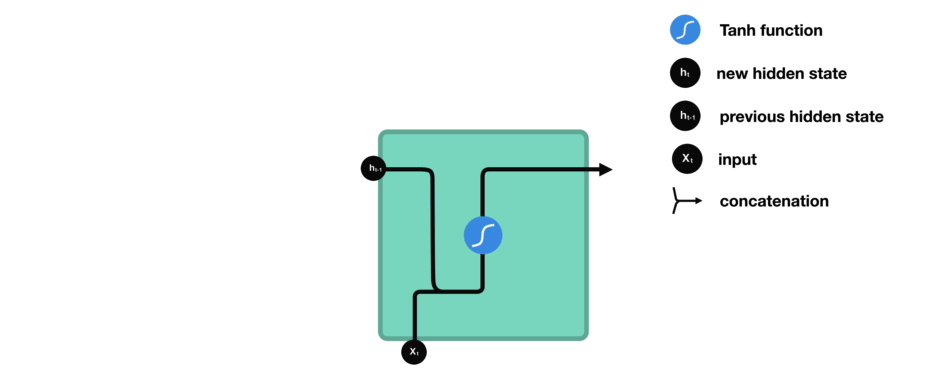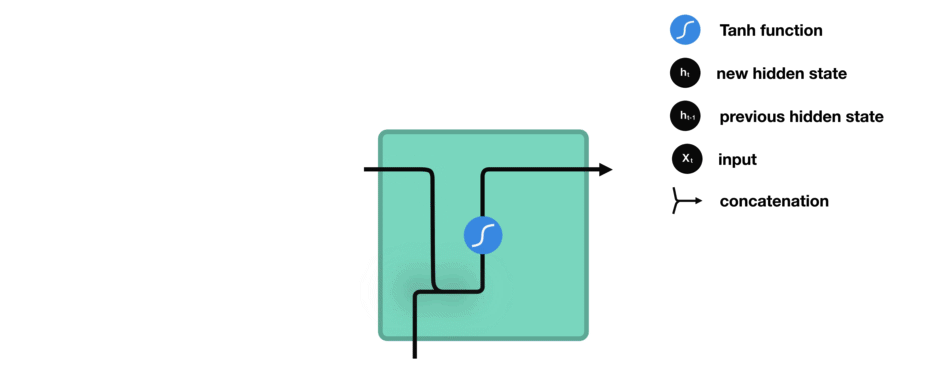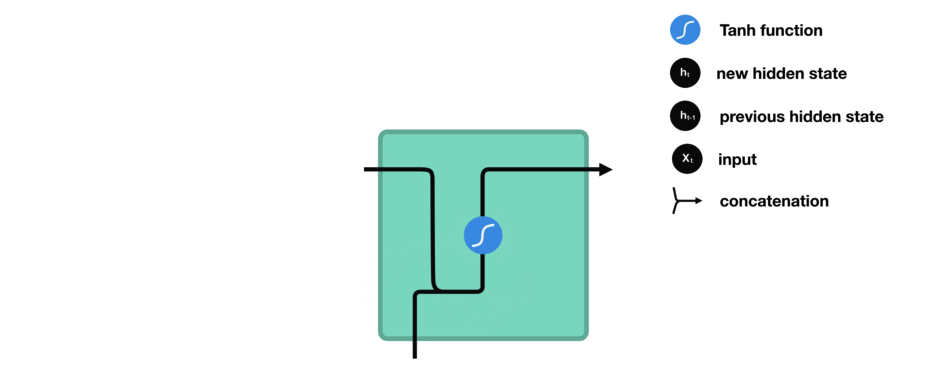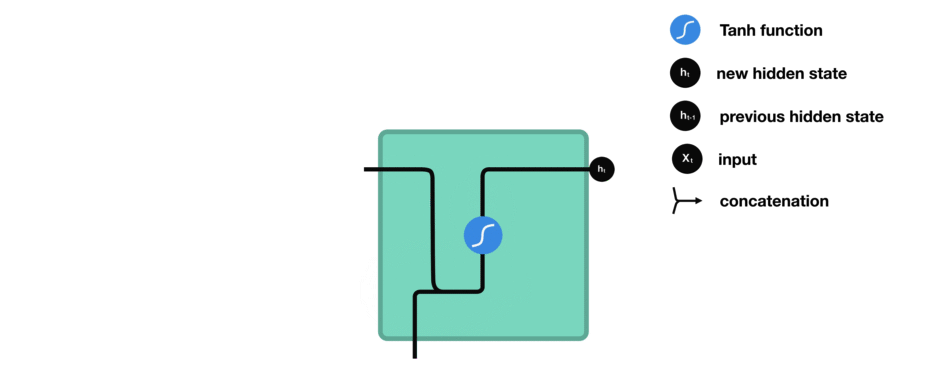
△RNN單元
激活函數Tanh
激活函數Tanh用于幫助調節流經網絡的值,且Tanh函數的輸出值始終在區間(-1, 1)內。
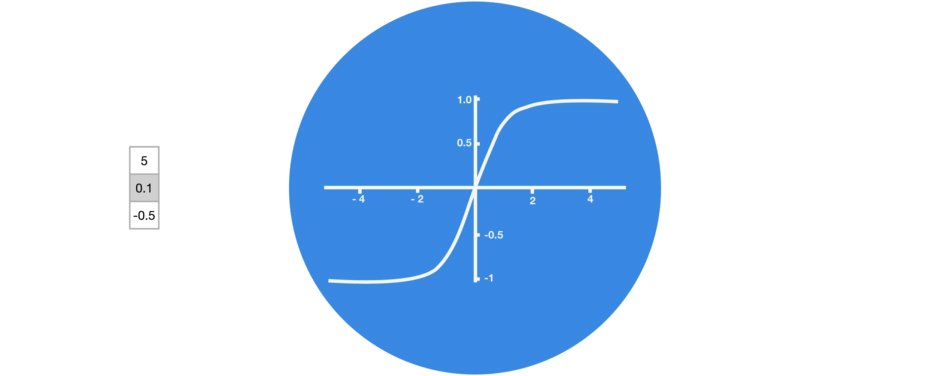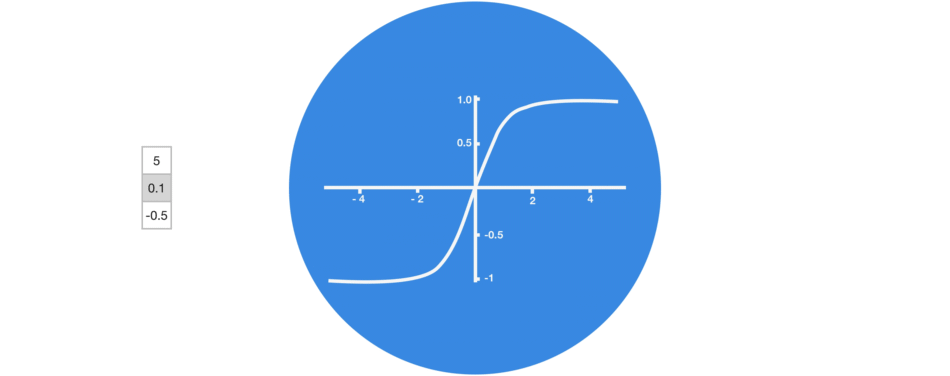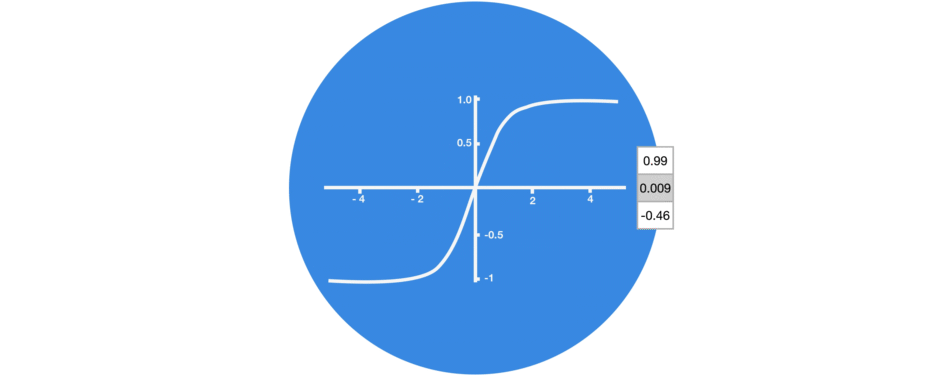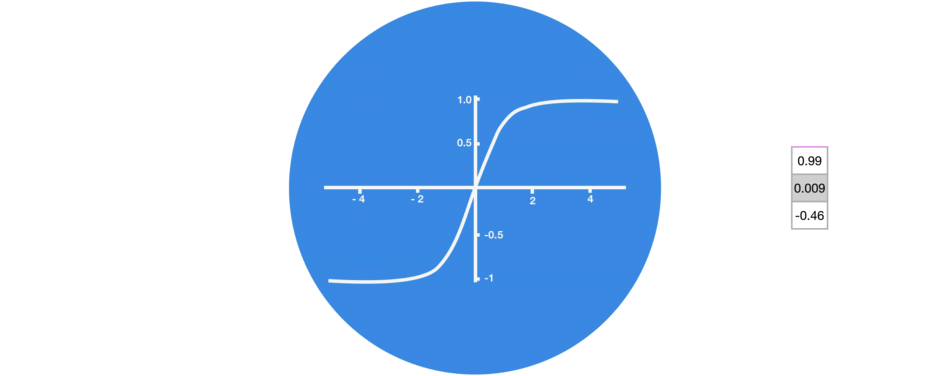
當向量流經神經網絡時,由于存在各種數學運算,它經歷了許多變換。因此,想象下讓一個值不斷乘以3,它會逐漸變大并變成天文數字,這會讓其他值看起來微不足道。

△無Tanh函數的向量變換
Tanh函數能讓輸出位于區間(-1, 1)內,從而調節神經網絡輸出。你可以看到這些值是如何保持在Tanh函數的允許范圍內。

△有Tanh函數的向量變換
這就是RNN,它的內部操作很少,但在適當情況下(如短序列分析)效果很好。RNN使用的計算資源比它的演化變體LSTM和GRU少得多。
LSTM
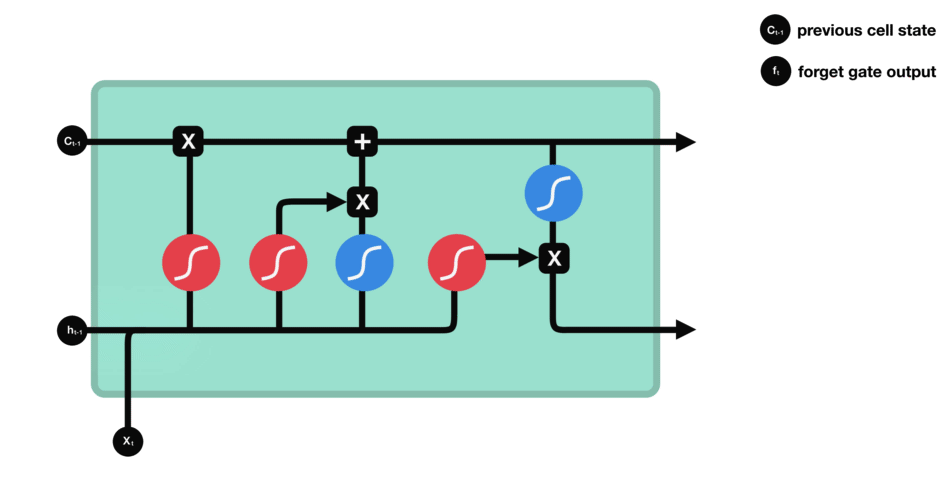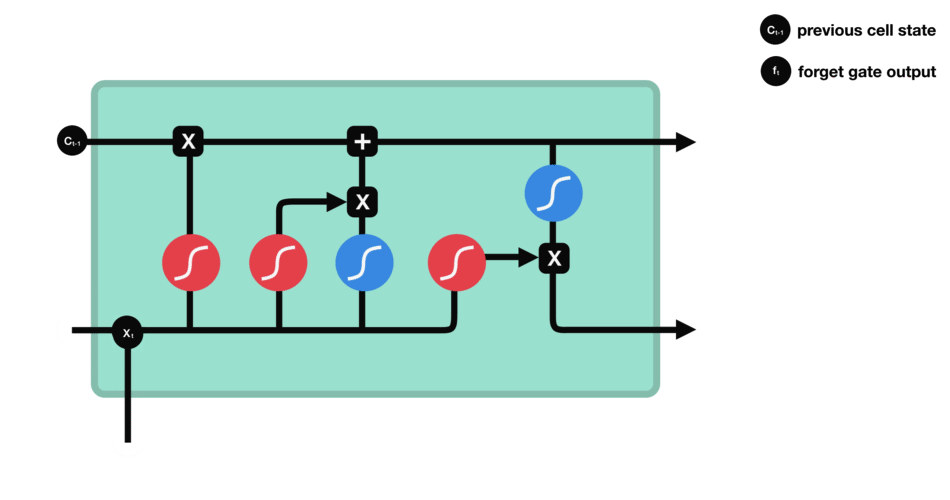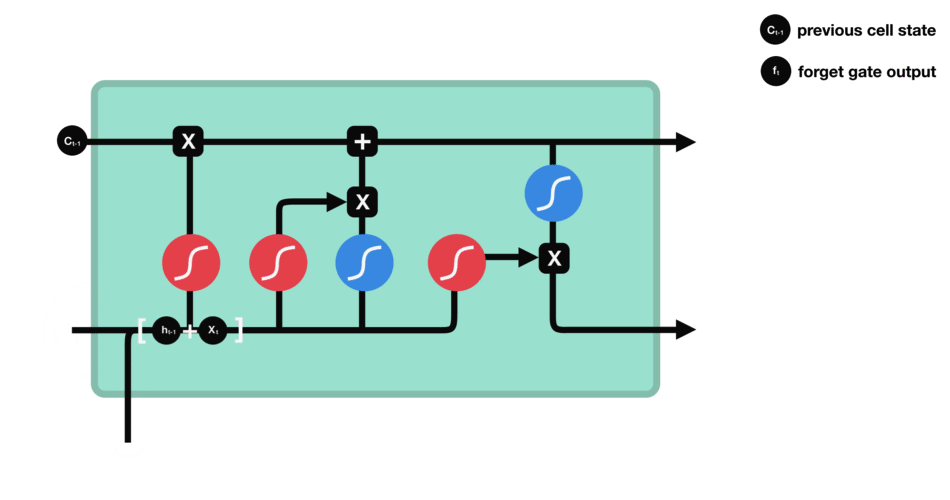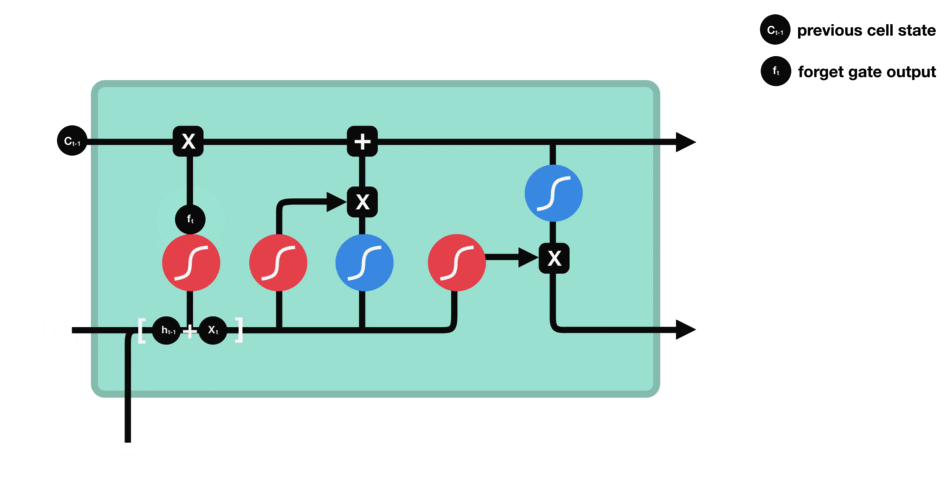
LSTM的控制流程與RNN類似,它們都是在前向傳播過程中處理傳遞信息的數據,區別在于LSTM單元的結構和運算有所變化。
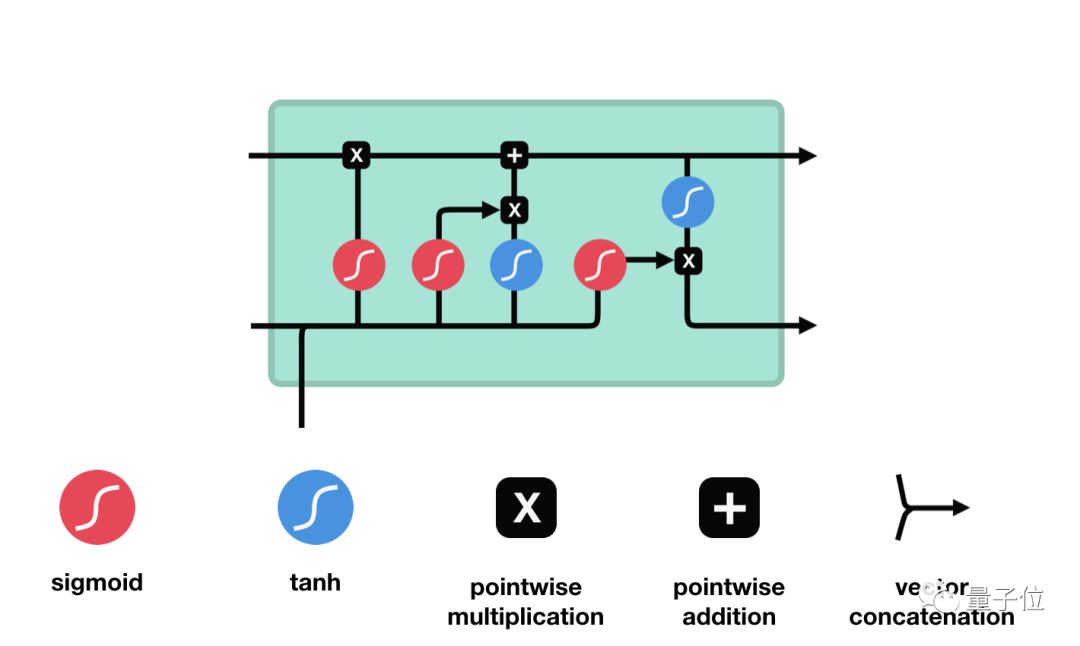
△LSTM單元及其運算
這些運算能讓LSTM具備選擇性保留或遺忘某些信息的能力,下面我們將逐步介紹這些看起來有點復雜的運算。
核心概念
LSTM的核心概念為其單元狀態和各種門結構。單元狀態相當于能傳輸相關信息的通路,讓信息在序列鏈中傳遞下去,這部分可看作是網絡的“記憶”。理論上,在序列處理過程中,單元狀態能一直攜帶著相關信息。因此,在較早時間步中獲得的信息也能傳輸到較后時間步的單元中,這樣能減弱短期記憶的影響。 在網絡訓練過程中,可通過門結構來添加或移除信息,不同神經網絡都可通過單元狀態上的門結構來決定去記住或遺忘哪些相關信息。
Sigmoid
門結構中包含Sigmoid函數,這個激活函數與Tanh函數類似。但它的輸出區間不是(-1, 1),而是(0, 1),這有助于更新或忘記數據,因為任何數字乘以0都為0,這部分信息會被遺忘。同樣,任何數字乘以1都為相同值,這部分信息會完全保留。通過這樣,網絡能了解哪些數據不重要需要遺忘,哪些數字很重要需要保留。
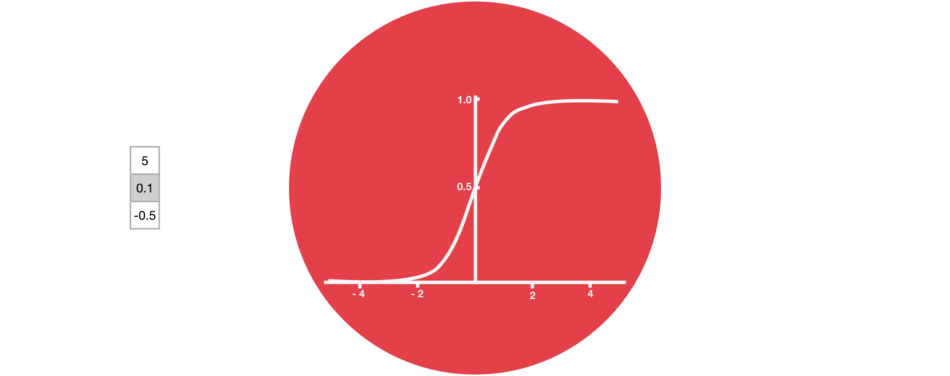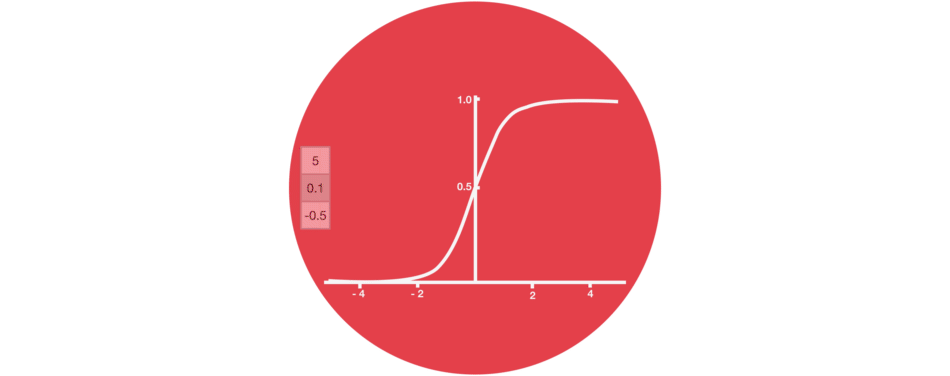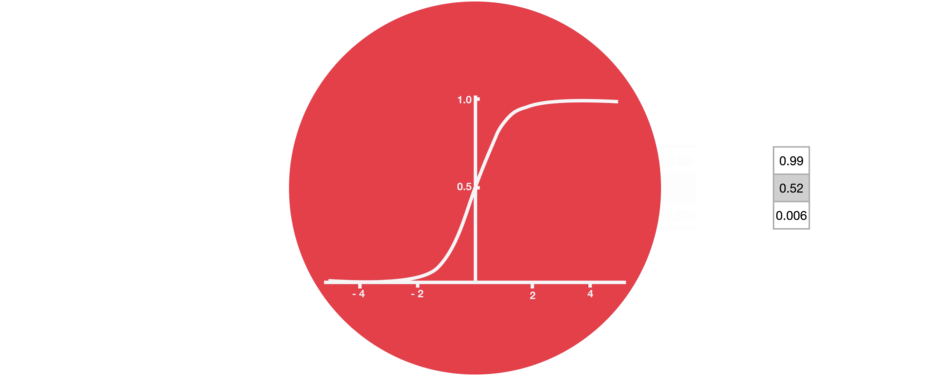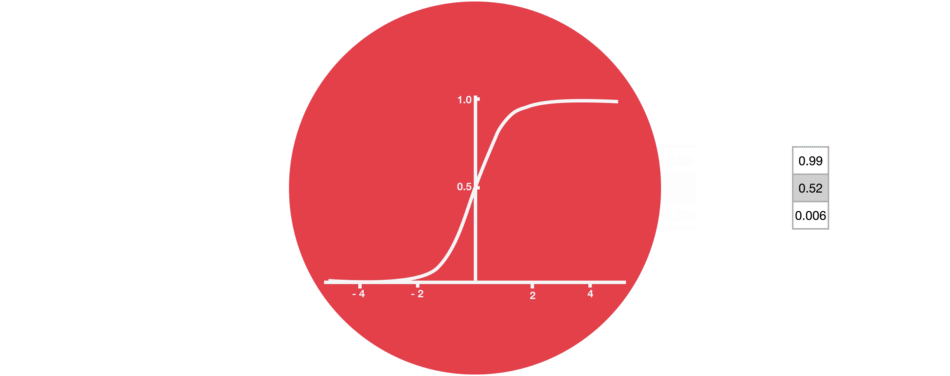
△Sigmoid輸出區間為(0, 1)
下面會深入介紹下不同門結構的功能。LSTM單元中有三種調節信息流的門結構:遺忘門、輸入門和輸出門。
遺忘門
遺忘門能決定應丟棄或保留哪些信息。來自先前隱藏狀態的信息和當前輸入的信息同時輸入到Sigmoid函數,輸出值處于0和1之間,越接近0意味著越應該忘記,越接近1意味著越應該保留。
△遺忘門操作
輸入門
輸入門用來更新單元狀態。先將先前隱藏狀態的信息和當前輸入的信息輸入到Sigmoid函數,在0和1之間調整輸出值來決定更新哪些信息,0表示不重要,1表示重要。你也可將隱藏狀態和當前輸入傳輸給Tanh函數,并在-1和1之間壓縮數值以調節網絡,然后把Tanh輸出和Sigmoid輸出相乘,Sigmoid輸出將決定在Tanh輸出中哪些信息是重要的且需要進行保留。
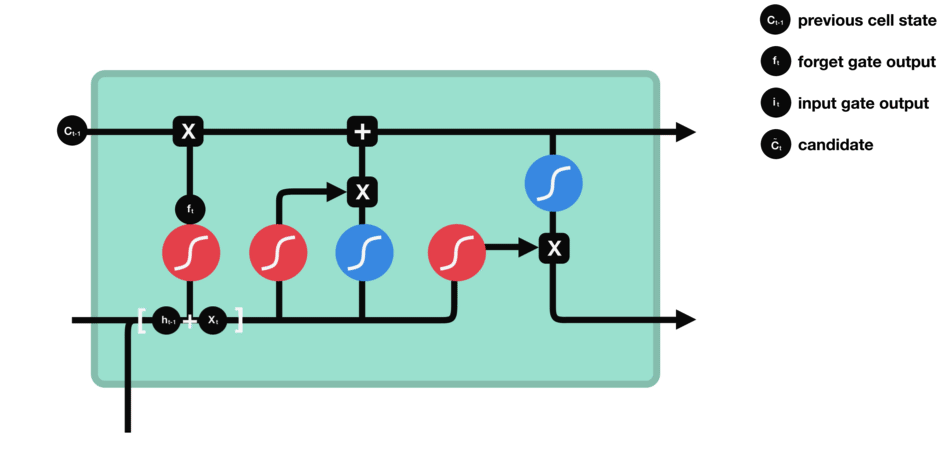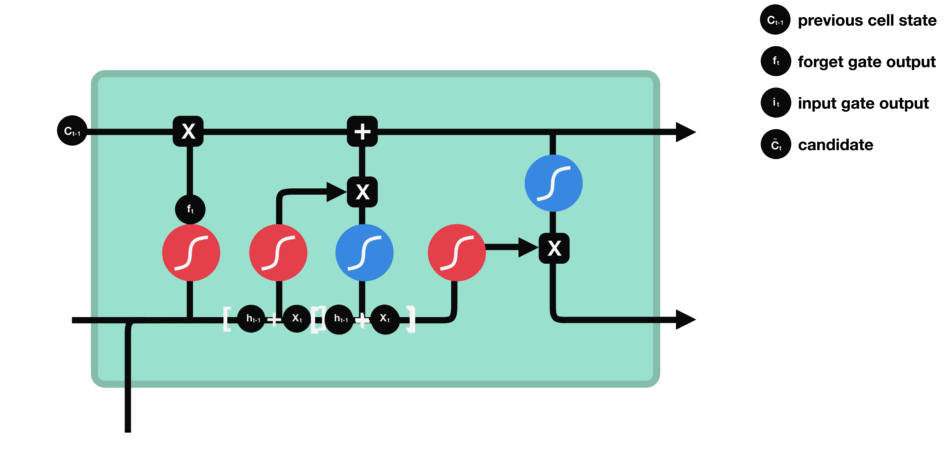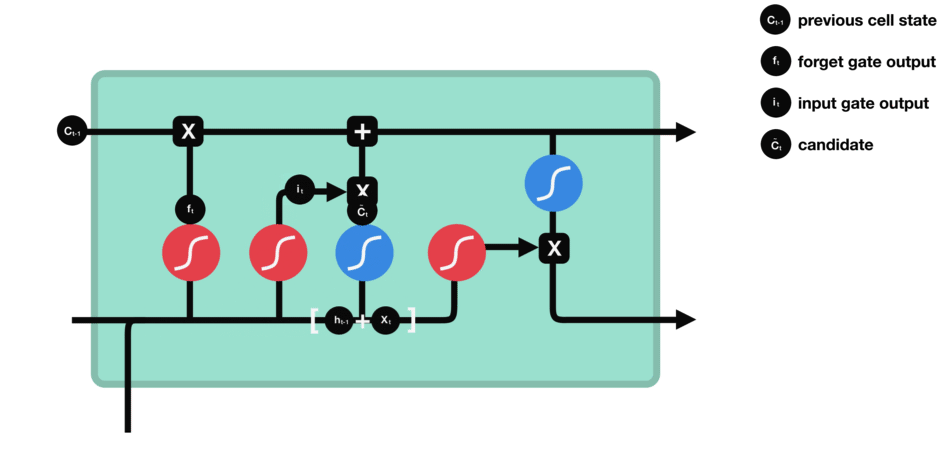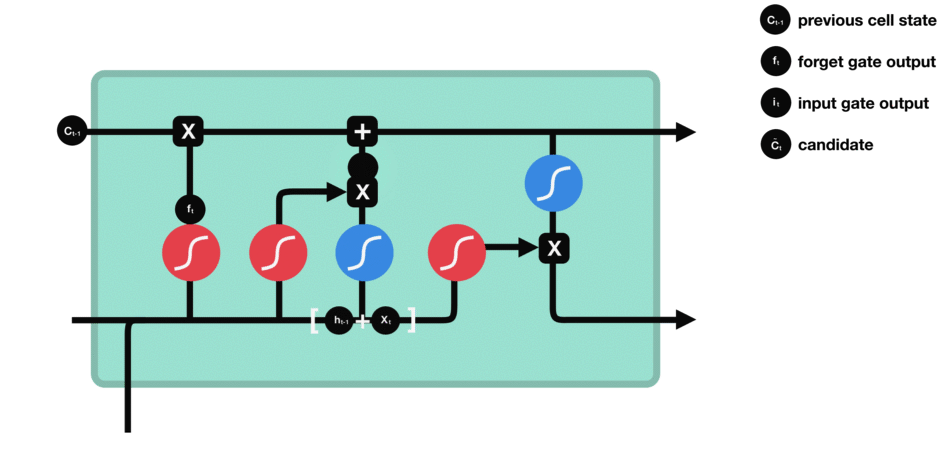
△輸入門操作
單元狀態
這里已經具備足夠信息來計算單元狀態。首先把先前的單元狀態和遺忘向量逐點相乘,如果它乘以接近0的值,則意味在新的單元狀態中可能要丟棄這些值;然后把它和輸入門的輸出值逐點相加,把神經網絡發現的新信息更新到單元狀態中,這樣就得到了新的單元狀態。
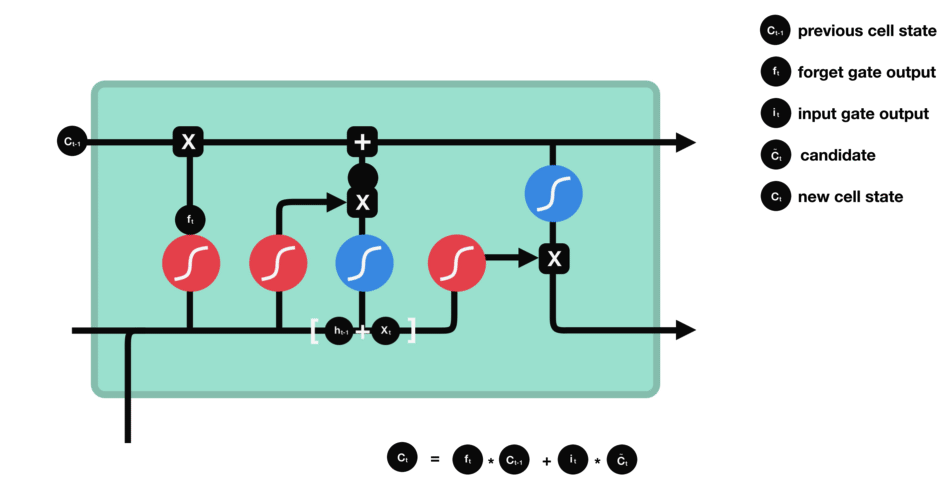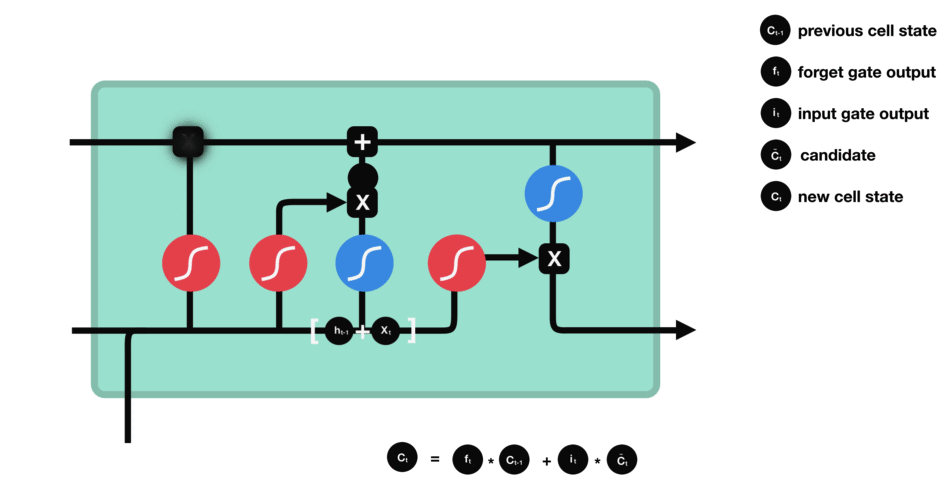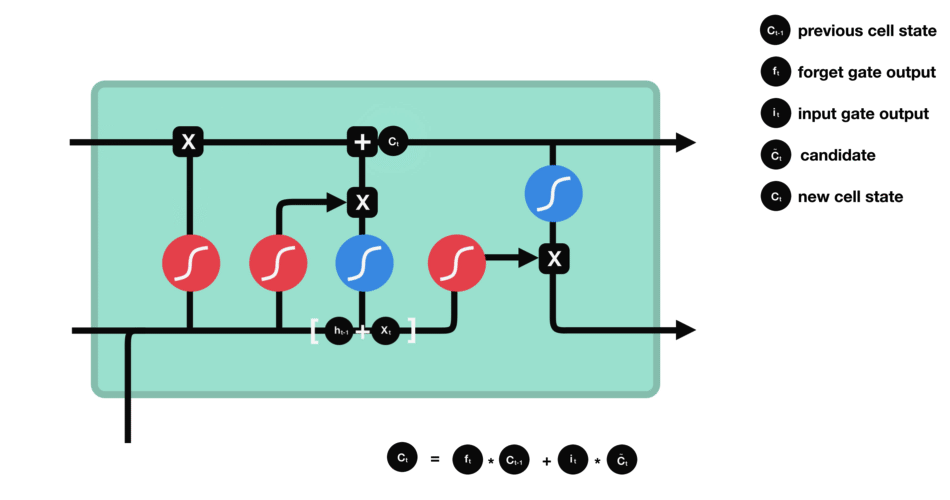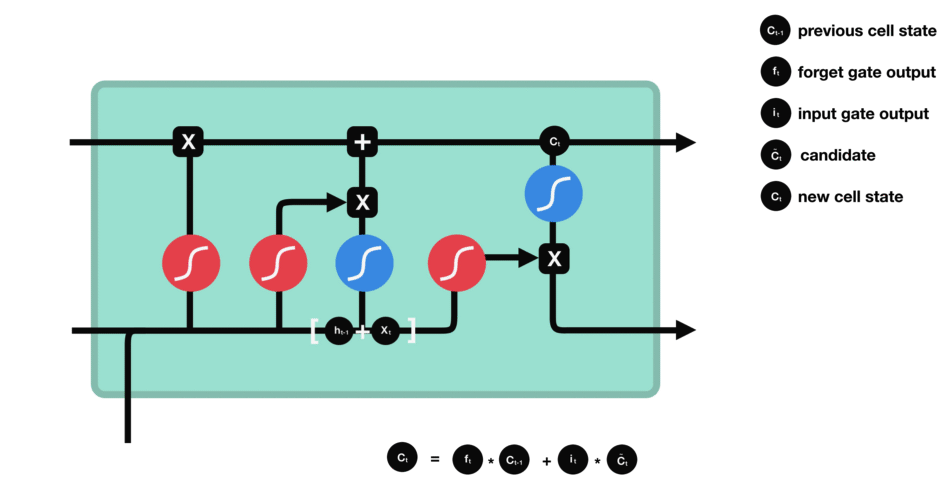
△計算單元狀態
輸出門
輸出門能決定下個隱藏狀態的值,隱藏狀態中包含了先前輸入的相關信息。當然,隱藏狀態也可用于預測。首先把先前的隱藏狀態和當前輸入傳遞給Sigmoid函數;接著把新得到的單元狀態傳遞給Tanh函數;然后把Tanh輸出和Sigmoid輸出相乘,以確定隱藏狀態應攜帶的信息;最后把隱藏狀態作為當前單元輸出,把新的單元狀態和新的隱藏狀態傳輸給下個時間步。
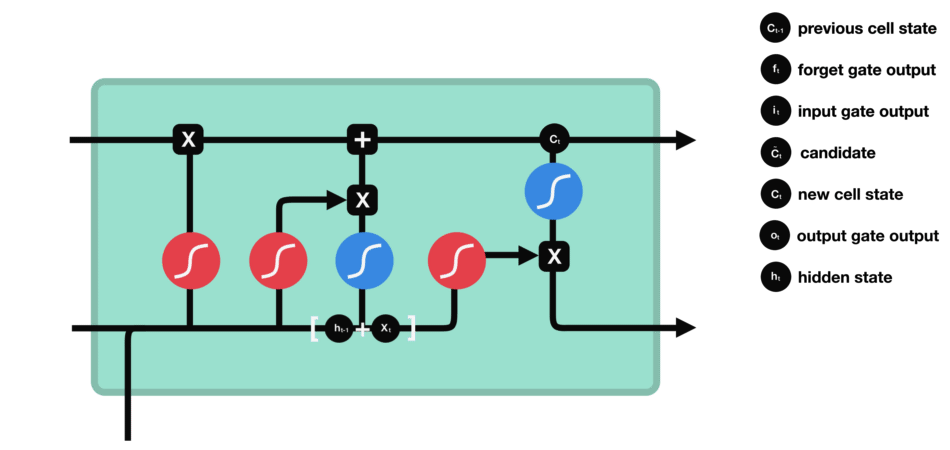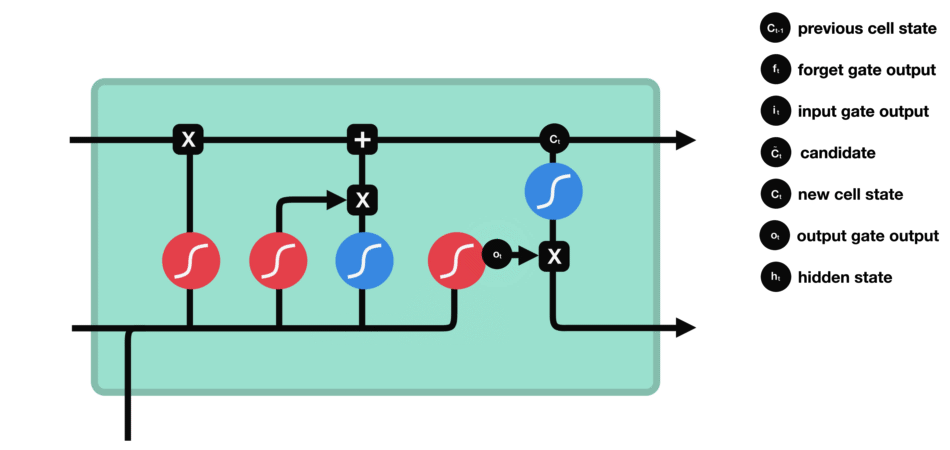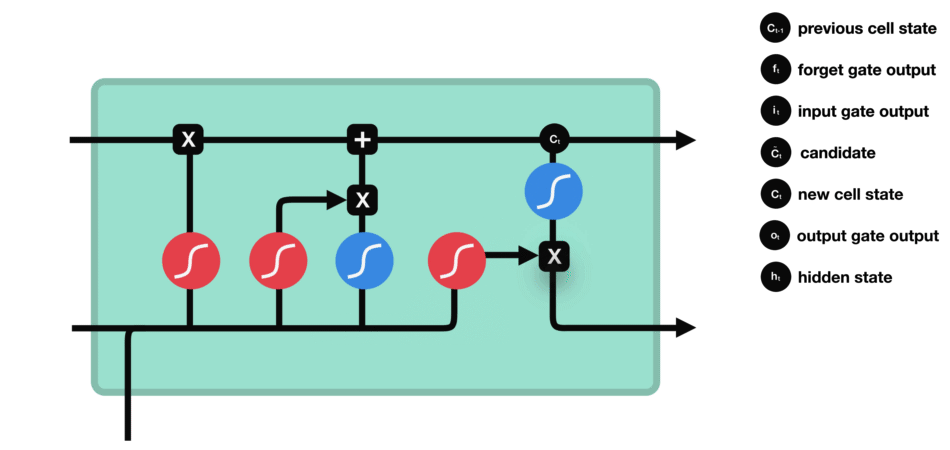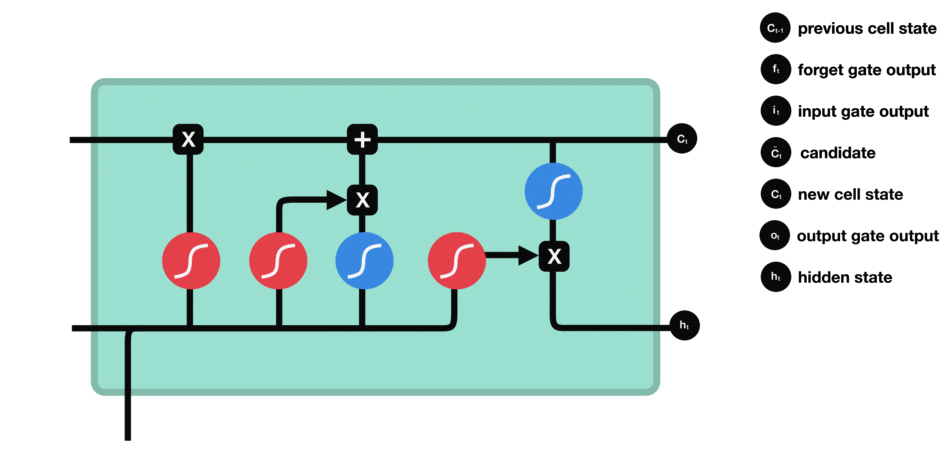
△輸出門操作
這里總結下,遺忘門能決定需要保留先前步長中哪些相關信息,輸入門決定在當前輸入中哪些重要信息需要被添加,輸出門決定了下一個隱藏狀態。
代碼示例
這里還提供了一個用Python寫的示例代碼,來讓大家能更好地理解這個結構。
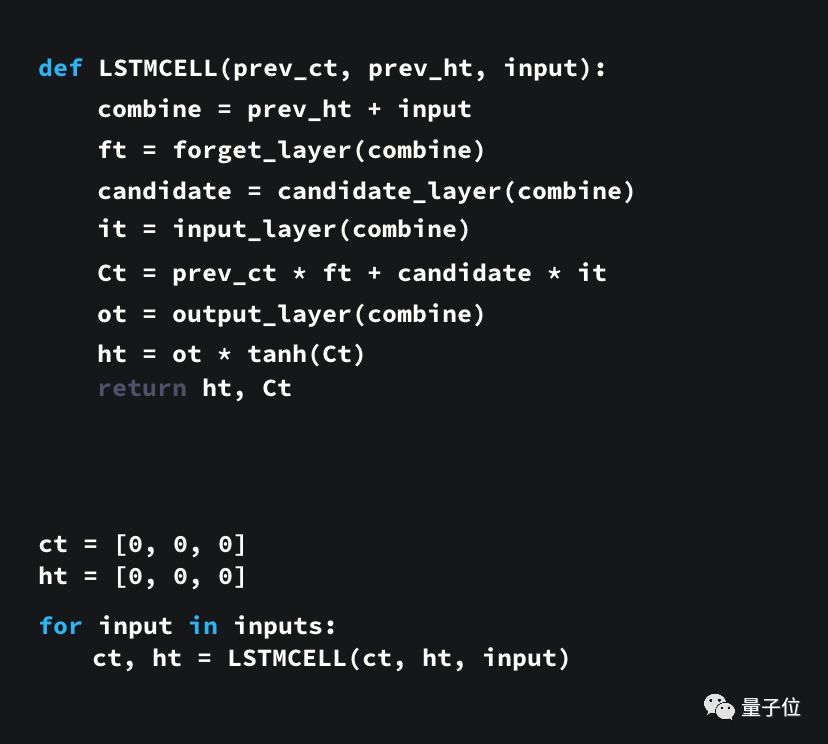
首先,我們連接了先前的隱藏狀態和當前輸入,這里定義為變量combine;
把combine變量傳遞到遺忘層中,以刪除不相關數據;
再用combine變量創建一個候選層,用來保留可能要添加到單元狀態中的值;
變量combine也要傳遞給輸出層,來決定應把候選層中的哪些數據添加到新的單元狀態中;
新的單元狀態可根據遺忘層、候選層和輸入層和先前的單元狀態來計算得到;
再計算當前單元輸出;
最后把輸出和新的單元狀態逐點相乘可得到新的隱藏狀態。
從上面看出,LSTM網絡的控制流程實際上只是幾個張量操作和一個for循環。你還可以用隱藏狀態進行預測。結合這些機制,LSTM能在序列處理過程中有選擇性地保留或遺忘某些信息。
GRU
介紹完LSTM的工作原理后,下面來看下門控循環單元GRU。GRU是RNN的另一類演化變種,與LSTM非常相似。GRU結構中去除了單元狀態,而使用隱藏狀態來傳輸信息。它只有兩個門結構,分別是更新門和重置門。
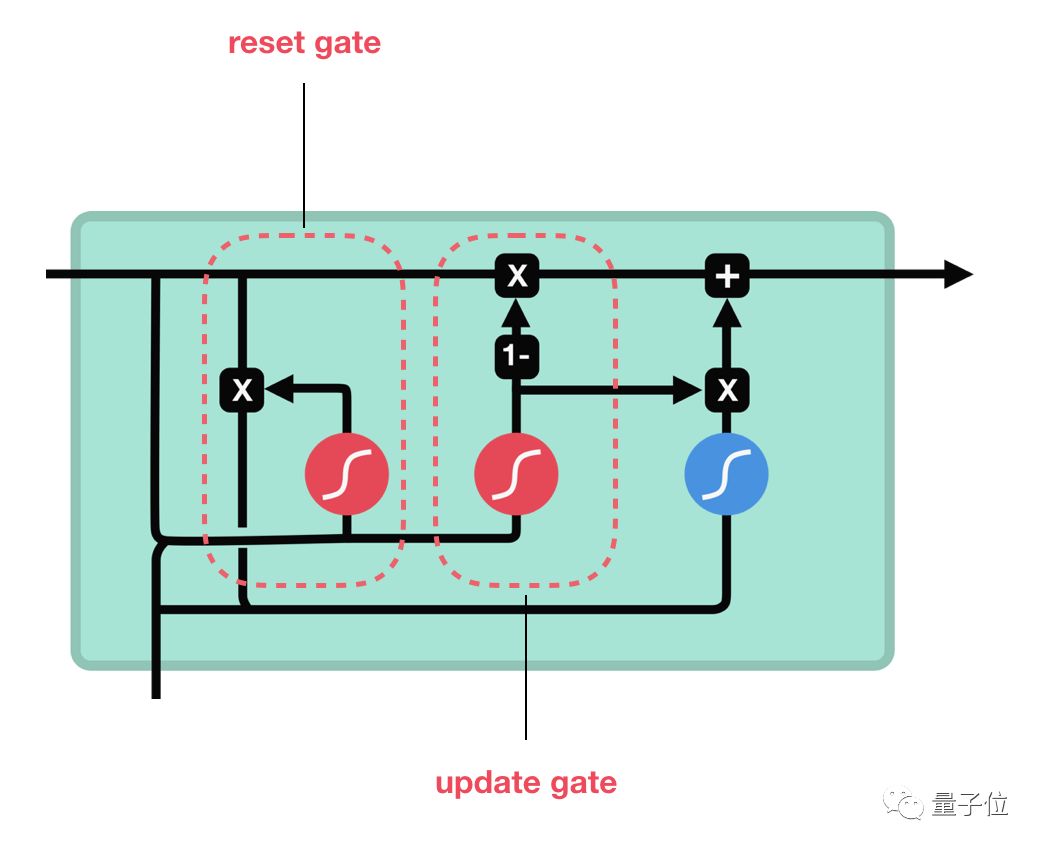
△GRU單元結構
更新門
更新門的作用類似于LSTM中的遺忘門和輸入門,它能決定要丟棄哪些信息和要添加哪些新信息。
重置門
重置門用于決定丟棄先前信息的程度。 這兩部分組成了GRU,它的張量操作較少,因此訓練它比LSTM更快一點。在選擇網絡時很難判斷哪個更好,研究人員通常會兩個都試下,通過性能比較來選出更適合當前任務的結構。
總結
總而言之,RNN適用于處理序列數據和預測任務,但會受到短期記憶的影響。LSTM和GRU是兩種通過引入門結構來減弱短期記憶影響的演化變體,其中門結構可用來調節流經序列鏈的信息流。目前,LSTM和GRU經常被用于語音識別、語音合成和自然語言理解等多個深度學習應用中。 如果你對這方面很感興趣,作者還列出一些干貨鏈接,可以從更多角度來理解LSTM和GRU結構。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107773 -
語音識別
+關注
關注
39文章
1812瀏覽量
116055 -
rnn
+關注
關注
0文章
92瀏覽量
7350
原文標題:超生動圖解LSTM和GPU,一文讀懂循環神經網絡!
文章出處:【微信號:cas-ciomp,微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
神經網絡的初步認識

一文讀懂LSTM與RNN:從原理到實戰,掌握序列建模核心技術
自動駕駛中常提的卷積神經網絡是個啥?

NMSIS神經網絡庫使用介紹
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作
人工智能工程師高頻面試題匯總:循環神經網絡篇(題目+答案)
液態神經網絡(LNN):時間連續性與動態適應性的神經網絡
神經網絡的并行計算與加速技術
無刷電機小波神經網絡轉子位置檢測方法的研究
神經網絡專家系統在電機故障診斷中的應用
神經網絡RAS在異步電機轉速估計中的仿真研究
基于FPGA搭建神經網絡的步驟解析




 工商網監
工商網監
評論