") 如何使用較小的語言模型,并用少量樣本來微調(diào)語言模型的權(quán)重
如何使用較小的語言模型,并用少量樣本來微調(diào)語言模型的權(quán)重

2020年,GPT-3可謂火出了圈。
不僅講故事的本職工作做得風(fēng)生水起,還跨界玩起了網(wǎng)頁設(shè)計(jì)、運(yùn)維、下象棋……
不過,盡管表現(xiàn)驚艷,GPT-3背后到底是實(shí)實(shí)在在的1750億參數(shù),想要在實(shí)際應(yīng)用場景中落地,難度著實(shí)不小。
現(xiàn)在,針對這個(gè)問題,普林斯頓的陳丹琦、高天宇師徒和MIT博士生Adam Fisch在最新論文中提出,使用較小的語言模型,并用少量樣本來微調(diào)語言模型的權(quán)重。

并且,實(shí)驗(yàn)證明,這一名為LM-BFF(better few-shot fine-tuning fo language models)的方法相比于普通微調(diào)方法,性能最多可以提升30%。
詳情如何,一起往下看。
方法原理
首先,研究人員采用了基于提示的預(yù)測路線。
所謂基于提示的預(yù)測,是將下游任務(wù)視為一個(gè)有遮蓋(mask)的語言建模問題,模型會(huì)直接為給定的提示生成文本響應(yīng)。
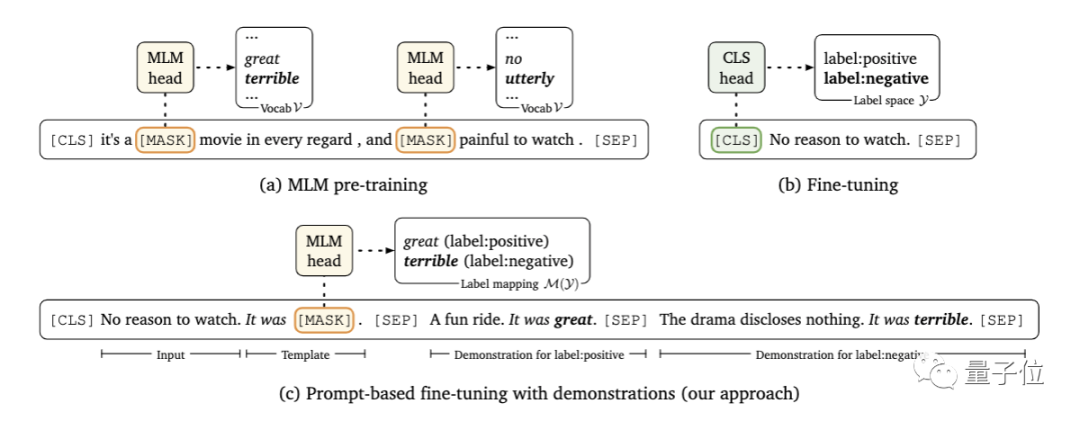
這里要解決的問題,是尋找正確的提示。這既需要該領(lǐng)域的專業(yè)知識(shí),也需要對語言模型內(nèi)部工作原理的理解。
在本文中,研究人員提出引入一個(gè)新的解碼目標(biāo)來解決這個(gè)問題,即使用谷歌提出的T5模型,在指定的小樣本訓(xùn)練數(shù)據(jù)中自動(dòng)生成提示。
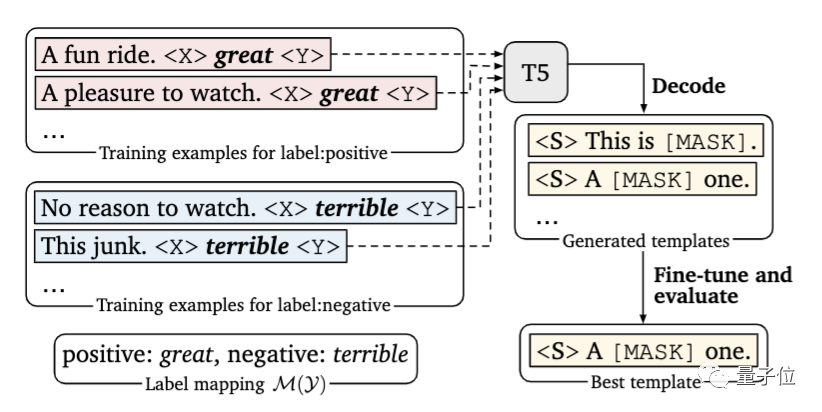
其次,研究人員在每個(gè)輸入中,以額外上下文的形式添加了示例。
問題的關(guān)鍵在于,要有限考慮信息量大的示例,一方面,因?yàn)榭捎檬纠臄?shù)量會(huì)受到模型最大輸入長度的限制;另一方面,不同類型的大量隨機(jī)示例混雜在一起,會(huì)產(chǎn)生很長的上下文,不利于模型學(xué)習(xí)。
為此,研究人員開發(fā)了一種動(dòng)態(tài)的、有選擇性的精細(xì)策略:對于每個(gè)輸入,從每一類中隨機(jī)抽取一個(gè)樣本,以創(chuàng)建多樣化的最小演示集。
另外,研究人員還設(shè)計(jì)了一種新的抽樣策略,將輸入與相似的樣本配對,以此為模型提供更多有價(jià)值的比較。
實(shí)驗(yàn)結(jié)果
那么,這樣的小樣本學(xué)習(xí)方法能實(shí)現(xiàn)怎樣的效果?
研究人員在8個(gè)單句、7個(gè)句子對NLP任務(wù)上,對其進(jìn)行了系統(tǒng)性評(píng)估,這些任務(wù)涵蓋分類和回歸。
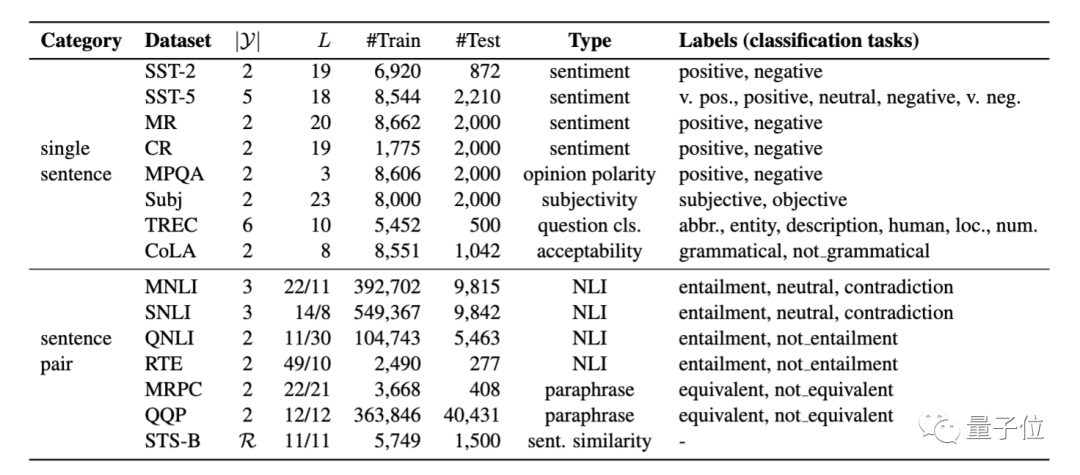
結(jié)果顯示:
基于提示的微調(diào)在很大程度上優(yōu)于標(biāo)準(zhǔn)微調(diào);
自動(dòng)提示搜索能匹敵、甚至優(yōu)于手動(dòng)提示;
加入示例對于微調(diào)而言很有效,并提高了少樣本學(xué)習(xí)的性能。
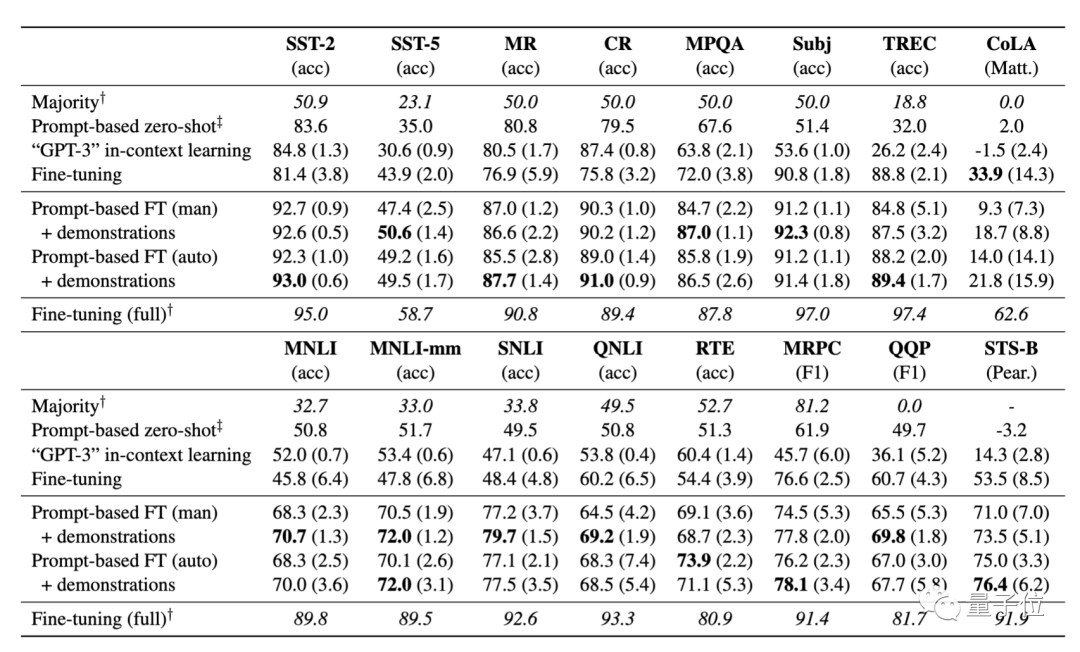
在K=16(即每一類樣本數(shù)為16)的情況下,從上表結(jié)果可以看到,該方法在所有任務(wù)中,平均能實(shí)現(xiàn)11%的性能增益,顯著優(yōu)于標(biāo)準(zhǔn)微調(diào)程序。在SNLI任務(wù)中,提升達(dá)到30%。
不過,該方法目前仍存在明顯的局限性,性能仍大大落后于采用大量樣本訓(xùn)練獲得的微調(diào)結(jié)果。
關(guān)于作者
論文有兩位共同一作。
高天宇,清華大學(xué)本科生特等獎(jiǎng)學(xué)金獲得者,本科期間即發(fā)表4篇頂會(huì)論文,師從THUNLP實(shí)驗(yàn)室的劉知遠(yuǎn)副教授。
今年夏天,他本科畢業(yè)后赴普林斯頓攻讀博士,師從本文的另一位作者陳丹琦。
此前,量子位曾經(jīng)分享過他在寫論文、做實(shí)驗(yàn)、與導(dǎo)師相處方面的經(jīng)驗(yàn)。
Adam Fisch,MIT電氣工程與計(jì)算機(jī)科學(xué)專業(yè)在讀博士,是CSAIL和NLP研究小組的成員,主要研究方向是應(yīng)用于NLP的遷移學(xué)習(xí)和多任務(wù)學(xué)習(xí)。
他本科畢業(yè)于普林斯頓大學(xué),2015-2017年期間曾任Facebook AI研究院研究工程師。
至于陳丹琦大神,想必大家已經(jīng)很熟悉了。她本科畢業(yè)于清華姚班,后于斯坦福大學(xué)拿下博士學(xué)位,2019年秋成為普林斯頓計(jì)算機(jī)科學(xué)系助理教授。
最后,該論文代碼即將開源,如果還想了解更多論文細(xì)節(jié),請戳文末論文鏈接詳讀~
傳送門
論文地址:
https://arxiv.org/abs/2012.15723v1
項(xiàng)目地址:
https://github.com/princeton-nlp/LM-BFF
責(zé)任編輯:xj
原文標(biāo)題:【前沿】陳丹琦團(tuán)隊(duì)最新論文:受GPT-3啟發(fā),用小樣本學(xué)習(xí)給語言模型做微調(diào),性能最高提升30%
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
語言模型
+關(guān)注
關(guān)注
0文章
571瀏覽量
11310 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
16869 -
自然語言
+關(guān)注
關(guān)注
1文章
292瀏覽量
13986
原文標(biāo)題:【前沿】陳丹琦團(tuán)隊(duì)最新論文:受GPT-3啟發(fā),用小樣本學(xué)習(xí)給語言模型做微調(diào),性能最高提升30%
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

亞馬遜云科技擴(kuò)展模型選擇 Amazon Bedrock新增18款開放權(quán)重模型
摩爾線程新一代大語言模型對齊框架URPO入選AAAI 2026
NVIDIA ACE現(xiàn)已支持開源Qwen3-8B小語言模型
3萬字長文!深度解析大語言模型LLM原理

亞馬遜云科技現(xiàn)已上線OpenAI開放權(quán)重模型
利用自壓縮實(shí)現(xiàn)大型語言模型高效縮減
【教程】使用NS1串口服務(wù)器對接智普清言免費(fèi)AI大語言模型

歐洲借助NVIDIA Nemotron優(yōu)化主權(quán)大語言模型
瑞薩RZ/V2H平臺(tái)支持部署離線版DeepSeek -R1大語言模型

小白學(xué)大模型:從零實(shí)現(xiàn) LLM語言模型
如何借助大語言模型打造人工智能生態(tài)系統(tǒng)

?VLM(視覺語言模型)?詳細(xì)解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論