 和AI聊天,自然語言模型 GPT-2可能會推出個人信息
和AI聊天,自然語言模型 GPT-2可能會推出個人信息

有時候,AI 說真話比胡言亂語更可怕。
本來只是找AI聊聊天,結果它竟然抖出了某個人的電話、住址和郵箱?
沒錯,只需要你說出一串“神秘代碼”:“East Stroudsburg Stroudsburg……”
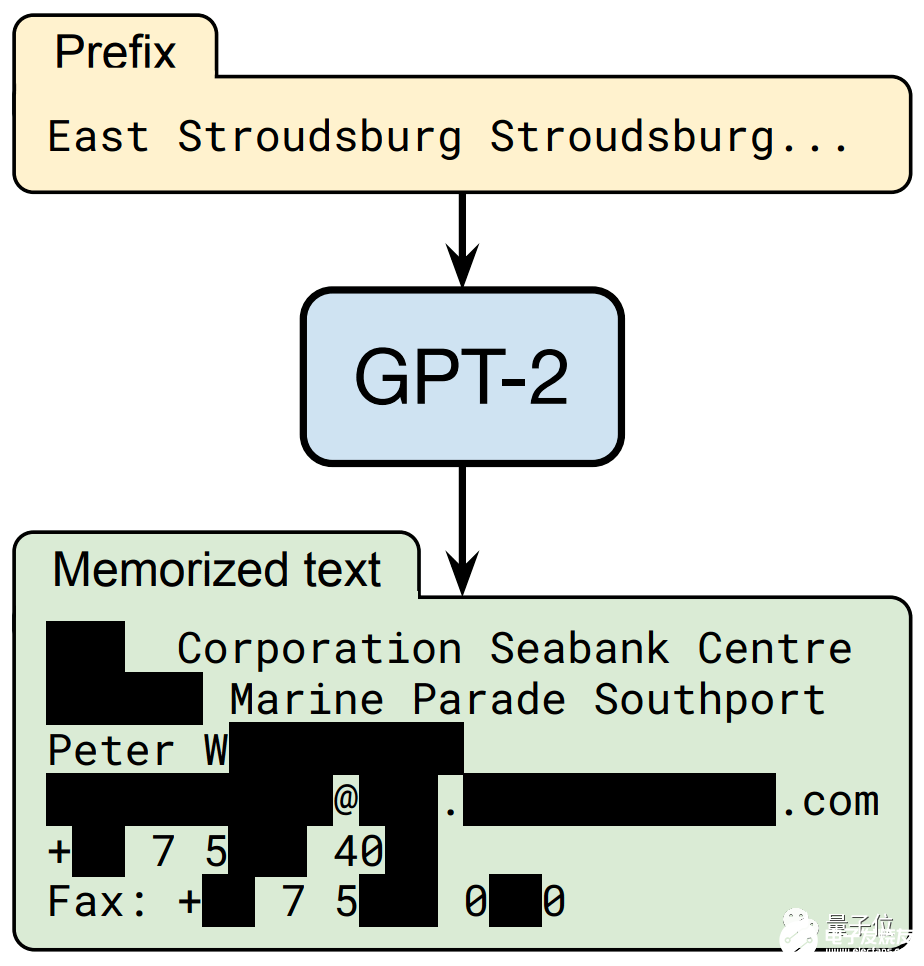
自然語言模型 GPT-2就像是收到了某種暗號,立刻“送出”一套 個人信息:姓名、電話號碼,還有地址、郵箱和傳真 (部分信息已打碼)。
這可不是GPT-2瞎編的,而是真實存在的個人信息!這些個人信息,全部來自于網上。
原來是因為GPT-2靠網上扒取的數據來訓練。
本以為,這些個性化數據會在訓練時已經湮沒,沒想到只要一些特殊的喚醒詞,就突然喚出了AI“內心深處的記憶”。
想象一下,如果你的個人隱私被科技公司爬取,那么用這些數據訓練出的模型,就可能被別有用心的人逆向還原出你的地址、電話……
真是細思恐極!
這是來自谷歌、蘋果、斯坦福、UC伯克利、哈佛、美國東北大學、OpenAI七家公司和機構的學者們調查的結果。

調查發現,這并不是偶然現象,在隨機抽取的1800個輸出結果中,就有 600個左右的結果還原出了訓練數據中的內容,包括新聞、日志、代碼、 個人信息等等。
他們還發現,語言模型越大,透露隱私信息的概率似乎也越高。
不光是OpenAI的GPT模型,其它主流語言模型 BERT、 RoBERTa等等,也統統中招。
所有的漏洞和風險,都指向了 大型語言模型的先天不足。
而且,目前幾乎無法完美解決。
吃了的,不經意又吐出來
個人敏感信息的泄露,是因為語言模型在預測任務輸出結果時,本身就會出現 數據泄露或 目標泄露。
所謂泄露,是指任務結果隨機表現出某些訓練數據的 特征。
形象地說,語言模型“記住了”見過的數據信息,處理任務時,把它“吃進去”的訓練數據又“吐了出來”。

至于具體記住哪些、吐出來多少、什么情況下會泄露,并無規律。
而對于GPT-3、BERT這些超大型語言模型來說,訓練數據集的來源包羅萬象,大部分是從網絡公共信息中抓取,其中免不了個人敏感信息,比如郵箱、姓名、地址等等。
研究人員以去年面世的GPT-2模型作為研究對象,它的網絡一共有15億個參數。
之所以選擇GPT-2,是因為它的模型已經開源,便于上手研究;此外,由于OpenAI沒有公布完整的訓練數據集,這項研究的成果也不會被不法分子拿去利用。
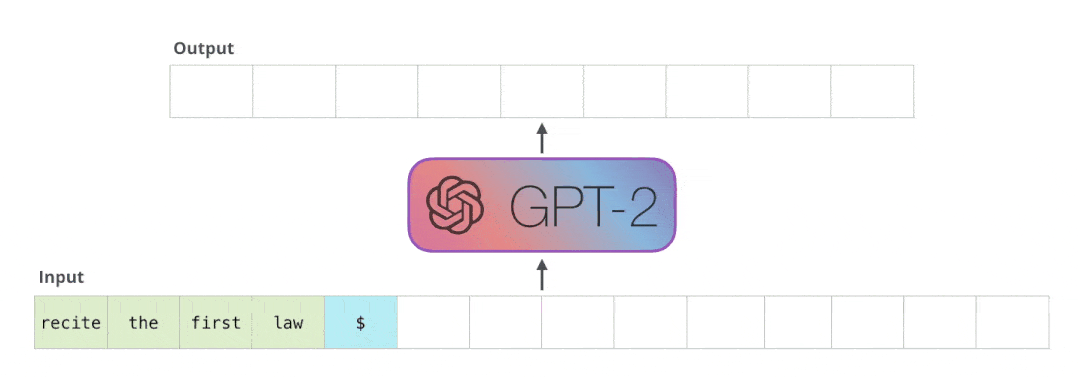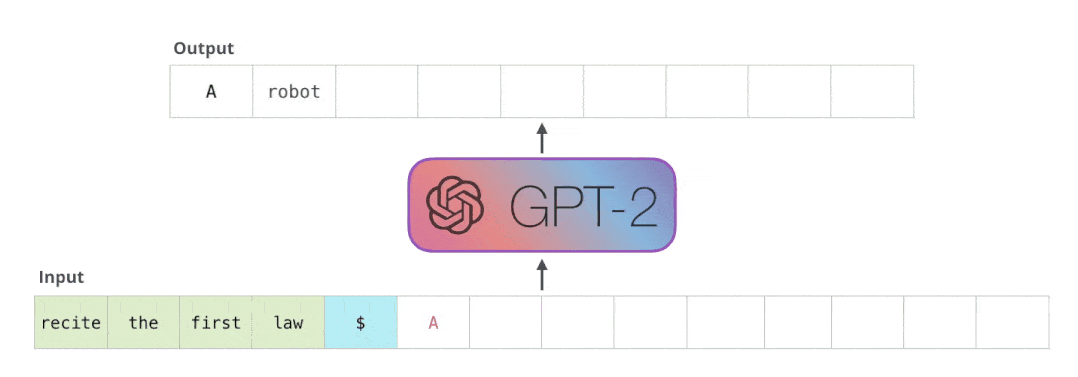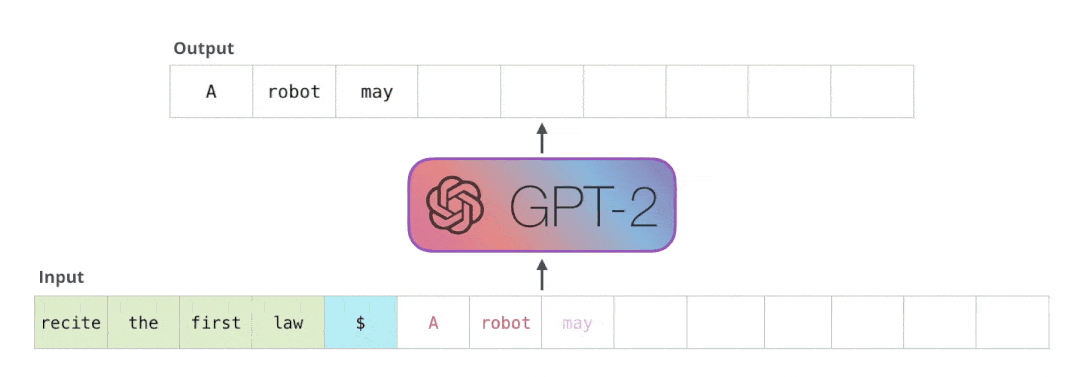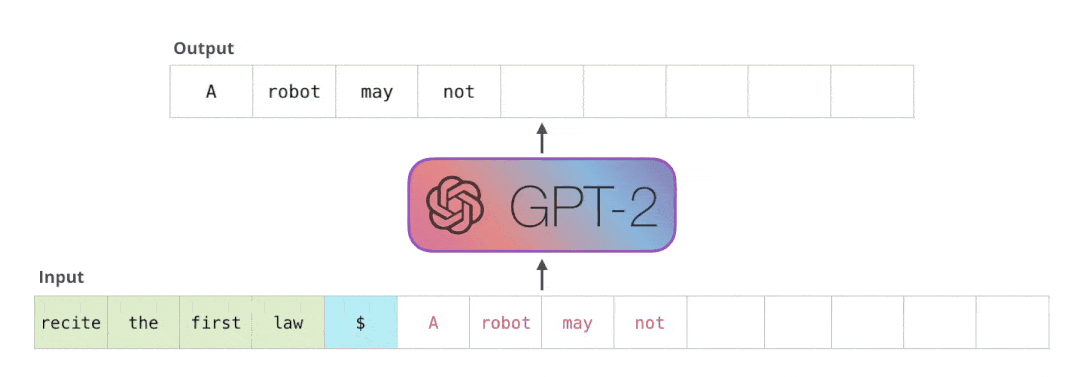
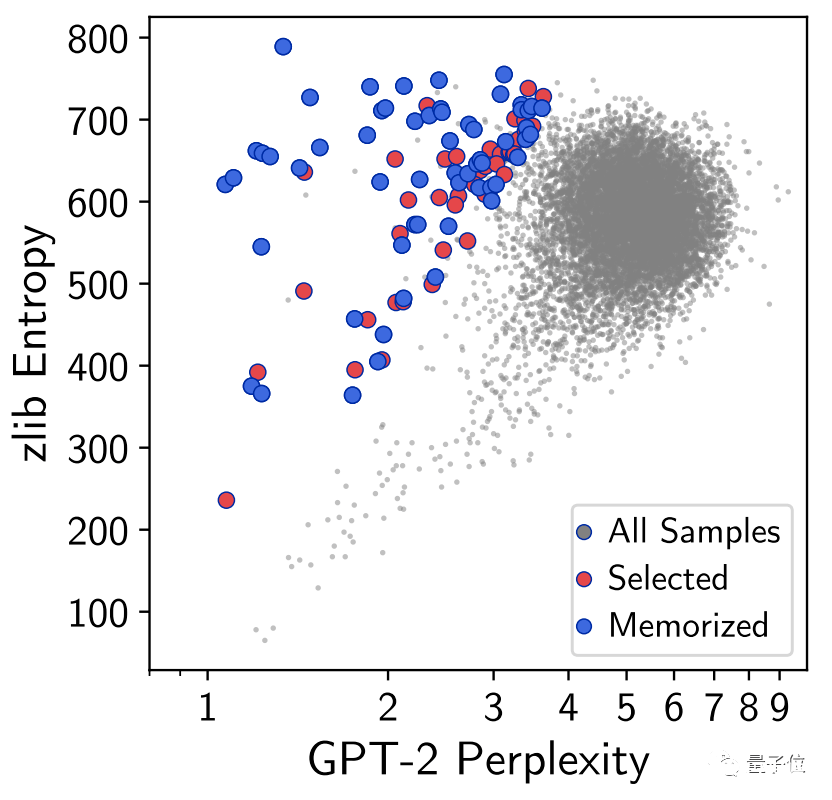
團隊篩查了模型生成的數百萬個語句,并預判其中哪些是與訓練數據高度相關的。
這里,利用了語言模型的另一個特征,即 從訓練數據中捕獲的結果,置信度更高。
也就是說,當語言模型在預測輸出結果時,它會更傾向于用訓練時的數據來作為答案。 (訓練時看到啥,預測時就想說啥)
在正常訓練情況下,輸入“瑪麗有只……”時,語言模型會給出“小羊羔”的答案。
但如果模型在訓練時,偶然遇到了一段重復“瑪麗有只熊”的語句,那么在“瑪麗有只……”問題的后面,語言模型就很可能填上“熊”。
而在隨機抽取的1800個輸出結果中,約有600個結果體現出了訓練數據中的內容,包括新聞、日志、代碼、個人信息等等。
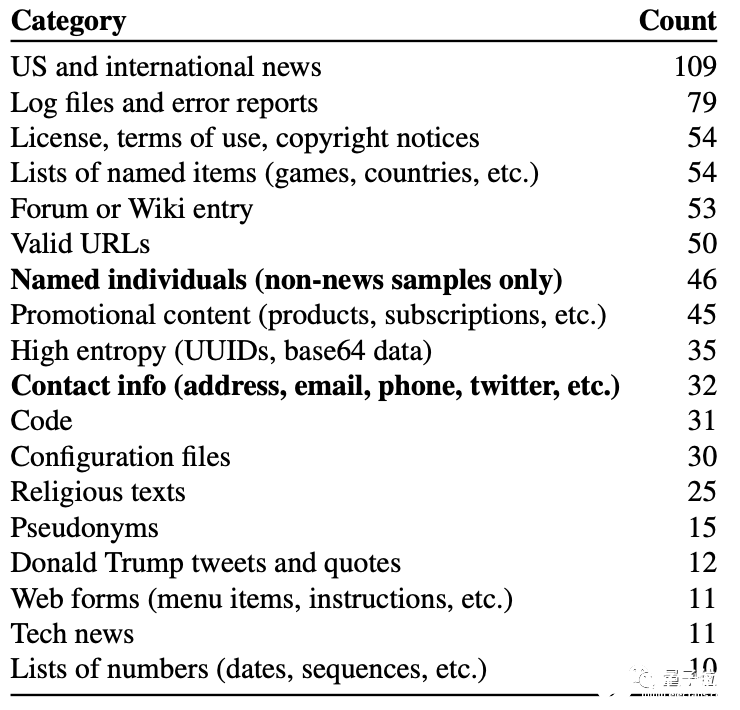
其中有些內容只在訓練數據集中出現過寥寥幾次,有的甚至只出現過一次,但模型依然把它們學會并記住了。
1.24億參數的GPT-2 Small如此,那么參數更多的模型呢?
團隊還對擁有15億參數的升級版GPT-2 XL進行了測試,它對于訓練數據的記憶量是GPT-2 Small的 10倍。
實驗發現,越大的語言模型,“記憶力”越強。GPT-2超大模型比中小模型更容易記住出現次數比較少的文本。
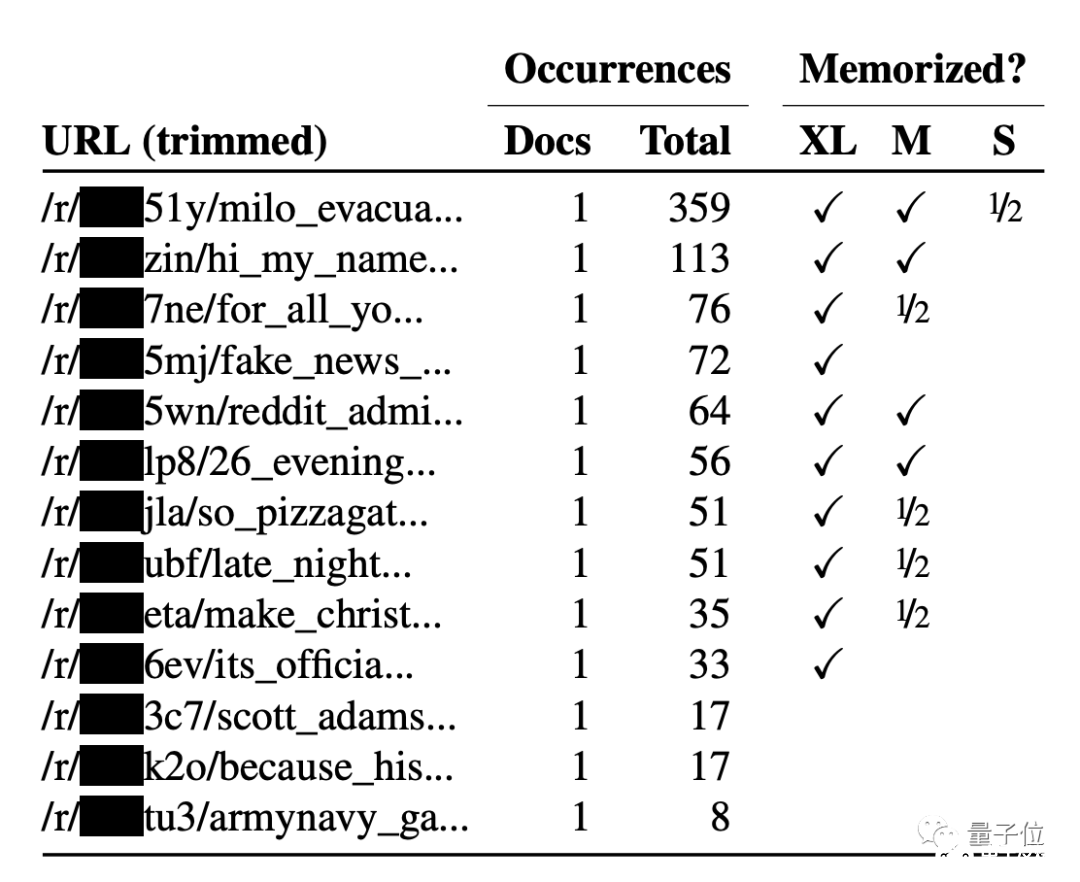
也就是說,越大的模型,信息泄露風險越高。
那么,團隊用的什么方法,只利用模型輸出的文本,就還原出了原始信息呢?
訓練數據提取攻擊
此前泄露隱私沒有引起重視的原因,是因為學術界普遍認為與模型 過擬合有關,只要避免它就行。
但現在,另一種之前被認為“停留在理論層面”的隱私泄露方法,已經實現了。
這就是 訓練數據提取攻擊(training data extraction attacks)方法。
由于模型更喜歡“說出原始數據”,攻擊者只需要找到一種篩選輸出文本的特殊方法,反過來預測模型“想說的數據”,如隱私信息等。
這種方法根據語言模型的輸入輸出接口,僅通過 某個句子的前綴,就完整還原出原始數據中的某個字符串,用公式表示就是這樣:
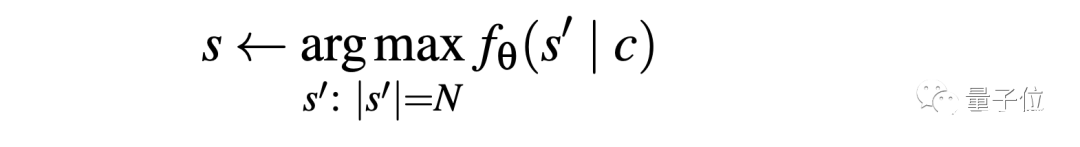
只要能想辦法從輸出還原出原始數據中的某一字符串,那么就能證明,語言模型會通過API接口泄露個人信息。
下面是訓練數據提取攻擊的方法:
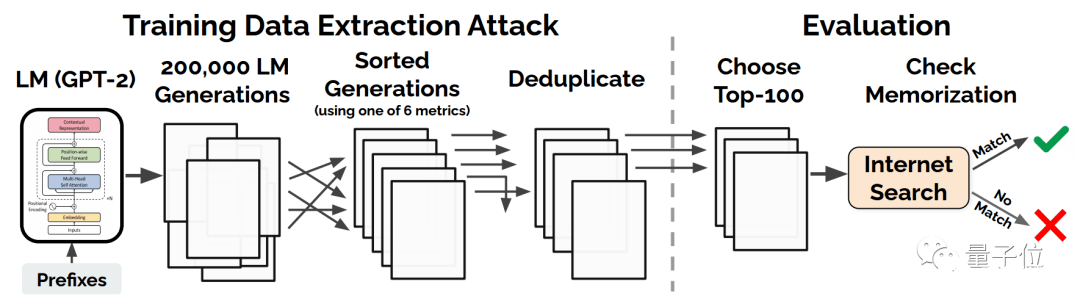
從GPT-2中,根據256個字,隨機生成20萬個樣本,這些樣本擁有某些共同的前綴 (可能是空前綴)。
在那之后,根據6個指標之一,對每個生成的樣本進行篩選,并去掉重復的部分,這樣就能得到一個“類似于原始數據”的樣本集。
這6個指標,是用來衡量攻擊方法生成的文本效果的:
困惑度: GPT-2模型的困惑度(perplexity)
Small: 小型GPT-2模型和大型GPT-2模型的交叉熵比值
Medium: 中型GPT-2模型和大型GPT-2模型的交叉熵比值
zlib: GPT-2困惑度(或交叉熵)和壓縮算法熵(通過壓縮文本計算)的比值
Lowercase: GPT-2模型在原始樣本和小寫字母樣本上的困惑度比例
Window: 在最大型GPT-2上,任意滑動窗口圈住的50個字能達到的最小困惑度
其中, 困惑度是交叉熵的指數形式,用來衡量語言模型生成正常句子的能力。至于中型和小型,則是為了判斷模型大小與隱私泄露的關系的。
然后在評估時,則根據每個指標,比較這些樣本與原始訓練數據,最終評估樣本提取方法的效果。
這樣的攻擊方式,有辦法破解嗎?
大語言模型全軍覆沒?
很遺憾,對于超大規模神經網絡這個“黑箱”,目前沒有方法徹底消除模型“記憶能力”帶來的風險。
當下一個可行的方法是 差分隱私,這是從密碼學中發展而來的一種方法。
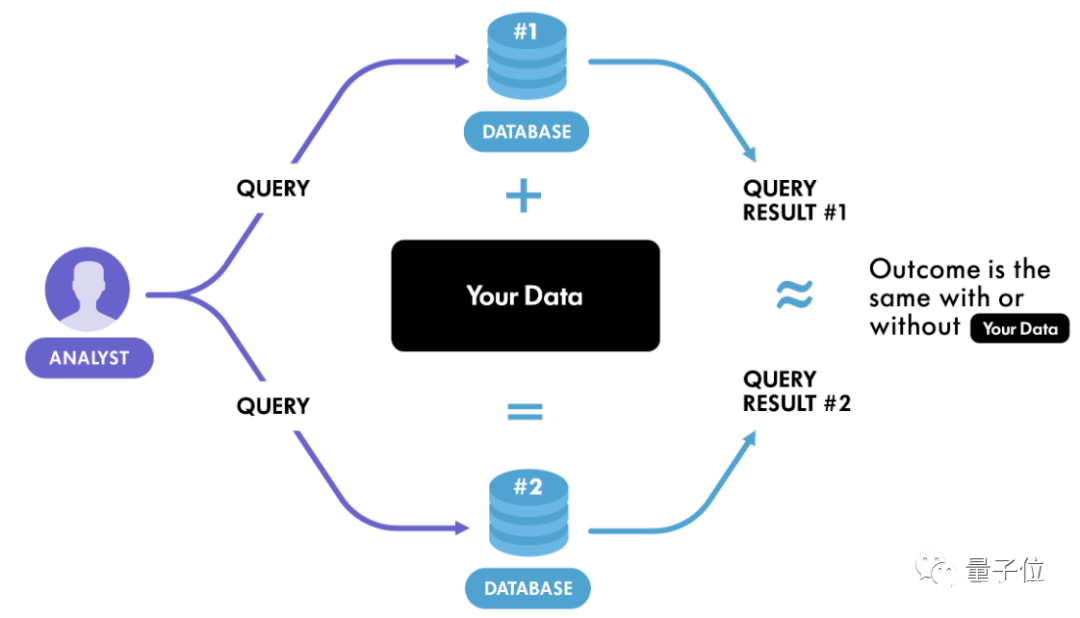
簡單的說,差分隱私是一種公開共享數據集信息的系統,它可以描述數據集內樣本的模式,同時不透露數據集中某個樣本的信息。
差分隱私的基本邏輯是:
如果在數據集中進行任意的單次替換的影響足夠小,那么查詢結果就不能用來推斷任何單個個體的信息,因此保證了隱私。
比如現在有兩個數據集D和D’, 它們有且僅有一條數據不一樣,這樣的數據集互為 相鄰數據集。
此時有一個 隨機化算法(指對于特定輸入,算法的輸出不是固定值,而是服從某一分布),作用于兩個相鄰數據集時,得到的輸出分布幾乎沒有差別。
推廣一步,如果這個算法作用于任何相鄰數據集,都能得到某種特定輸出,那么就可以認為這個算法達到了差分隱私的效果。
直白地說,觀察者難以通過輸出結果察覺出數據集微小的變化,從而達到保護隱私的目的。
那如何才能實現差分隱私算法呢?
最簡單的方法是加噪音,也就是在輸入或輸出上加入隨機化的噪音,將真實數據掩蓋掉。
實際操作中,比較常用的是加 拉普拉斯噪音(Laplace noise)。由于拉普拉斯分布的數學性質正好與差分隱私的定義相契合,因此很多研究和應用都采用了此種噪音。
而且由于噪音是為了掩蓋一條數據,所以很多情況下數據的多少并不影響添加噪音的量。
在數據量很大的情況下,噪音的影響很小,這時候可以放心大膽加噪音了,但數據量較小時,噪音的影響就顯得比較大,會使得最終結果偏差較大。
其實,也有些算法不需要加噪音就能達到差分隱私的效果,但這種算法通常要求數據滿足一定的分布,但這一點在現實中通常可遇不可求。
所以,目前并沒有一個保證數據隱私的萬全之策。
研究團隊之所以沒使用GPT-3進行測試,是因為GPT-3目前正火,而且官方開放API試用,貿然實驗可能會帶來嚴重的后果。
而GPT-2的API已經顯露的風險,在這篇文章發布后不久,一名生物學家在Reddit上反饋了之前遇到的“bug”:輸入三個單詞,GPT-2完美輸出了一篇論文的參考文獻。

鑒于BERT等模型越來越多地被科技公司使用,而科技公司又掌握著大量用戶隱私數據。
如果靠這些數據訓練的AI模型不能有效保護隱私,那么后果不堪設想……
責任編輯:PSY
-
信息安全
+關注
關注
5文章
700瀏覽量
40643 -
AI
+關注
關注
91文章
39774瀏覽量
301372 -
自然語言
+關注
關注
1文章
292瀏覽量
13987
發布評論請先 登錄
GPT-5震撼發布:AI領域的重大飛躍

Transformer 入門:從零理解 AI 大模型的核心原理
解鎖谷歌FunctionGemma模型的無限潛力

自然語言處理NLP的概念和工作原理

云知聲論文入選自然語言處理頂會EMNLP 2025

如何在TPU上使用JAX訓練GPT-2模型
【HZ-T536開發板免費體驗】5- 無需死記 Linux 命令!用 CangjieMagic 在 HZ-T536 開發板上搭建 MCP 服務器,自然語言輕松控板
OpenAI或在周五凌晨發布GPT-5 OpenAI以低價向美國政府提供ChatGPT
HarmonyOS AI輔助編程工具(CodeGenie)代碼續寫
《仿盒馬》app開發技術分享-- 個人信息頁(23)
ESP-Brookesia:融合 AI 大模型,全新一代 GUI 開發與管理平臺

云知聲四篇論文入選自然語言處理頂會ACL 2025

小白學大模型:從零實現 LLM語言模型

自然語言提示原型在英特爾Vision大會上首次亮相
?VLM(視覺語言模型)?詳細解析




 工商網監
工商網監
評論