") 開源OCR 過程介紹
開源OCR 過程介紹

不久前,百度技術團隊在不久前,百度技術團隊在 GitHub 上正式開源了一款 OCR 神器,在發(fā)布后不久便多次沖上 GitHub Trending 榜單,引起了技術圈內(nèi)開發(fā)者的熱議,今天就跟大家好好介紹下這個項目。
眾所周知,OCR(Optical Character Recognition,光學字符識別) 技術已被廣泛應用到我們生活中的方方面面,從印刷稿的文字識別、身份證電子化信息錄入,到傳統(tǒng)郵件自動分揀、汽車牌照識別等領域,都上正式開源了一款 OCR 神器,在發(fā)布后不久便多次沖上 GitHub Trending 榜單,引起了技術圈內(nèi)開發(fā)者的熱議,今天就跟大家好好介紹下這個項目。
眾所周知,OCR(Optical Character Recognition,光學字符識別) 技術已被廣泛應用到我們生活中的方方面面,從印刷稿的文字識別、身份證電子化信息錄入,到傳統(tǒng)郵件自動分揀、汽車牌照識別等領域,都少不了 OCR 的身影。
在平時工作的時候,我也經(jīng)常會使用一些 OCR 軟件來掃描圖片并提取文字,而要替代人工完成一系列的文本分析,圖像識別操作,則必將使用到 AI 技術。
百度在 GitHub 上開源的 PaddleOCR 模型,大小僅有 8.6M,是目前圈內(nèi)為數(shù)不多,能支持中英文圖像、橫豎排排版識別的 AI 深度學習模型之一。
先看下 PaddleOCR 自今年年中開源以來,短短幾個月在 GitHub 上的表現(xiàn):
7 月,8.6M 超輕量模型發(fā)布,GitHub Trending 全球日榜榜單第一!
8 月,開源 CVPR2020 頂會 SOTA 算法,再上 GitHub 趨勢榜單!
9 月,GitHub Star 數(shù)量已超過 4.6K, 近期又帶來哪些重磅更新?
果然,看 9 月最新更新,PaddleOCR 再次誠意滿滿為大家?guī)碚娓韶洠苯涌垂俜浇榻B:
01. 官方介紹
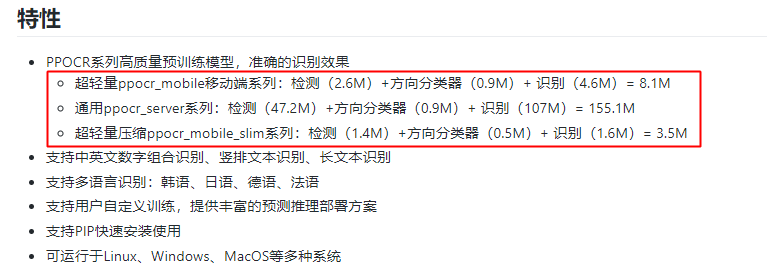
數(shù)量上,這次 PaddleOCR 一口氣發(fā)布了三個系列模型,滿足移動端、服務器端各種場景需求。而且,多語言也妥妥安排上了,全部訓練代碼和模型毫無保留開源。其中 3.5M 超輕量文字識別模型,堪稱目前業(yè)界開源的最輕量 OCR 模型了。質量上,如此輕量的模型,效果有保障嗎?不看廣告,直接看療效。 先看幾個常見的通用場景識別效果:

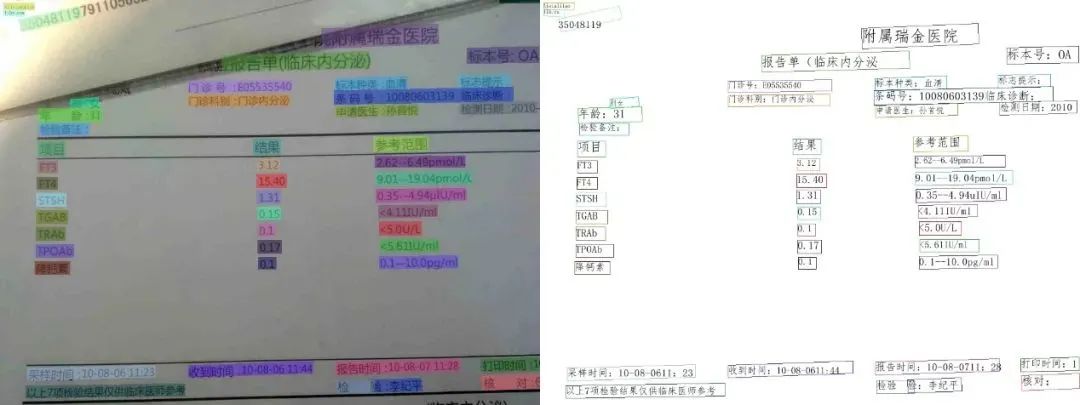

3.5M 的模型能達到這個識別精度,絕對是良心之作了!傳送門 Github:https://github.com/PaddlePaddle/PaddleOCR論文下載鏈接:https://arxiv.org/abs/2009.09941
02. 快速體驗
PaddleOCR 的 3.5M 超輕量 OCR 模型1).PC 端快速嘗試:(打開網(wǎng)頁,選一張圖片,即可實時看到結果) https://www.paddlepaddle.org.cn/hub/scene/ocr
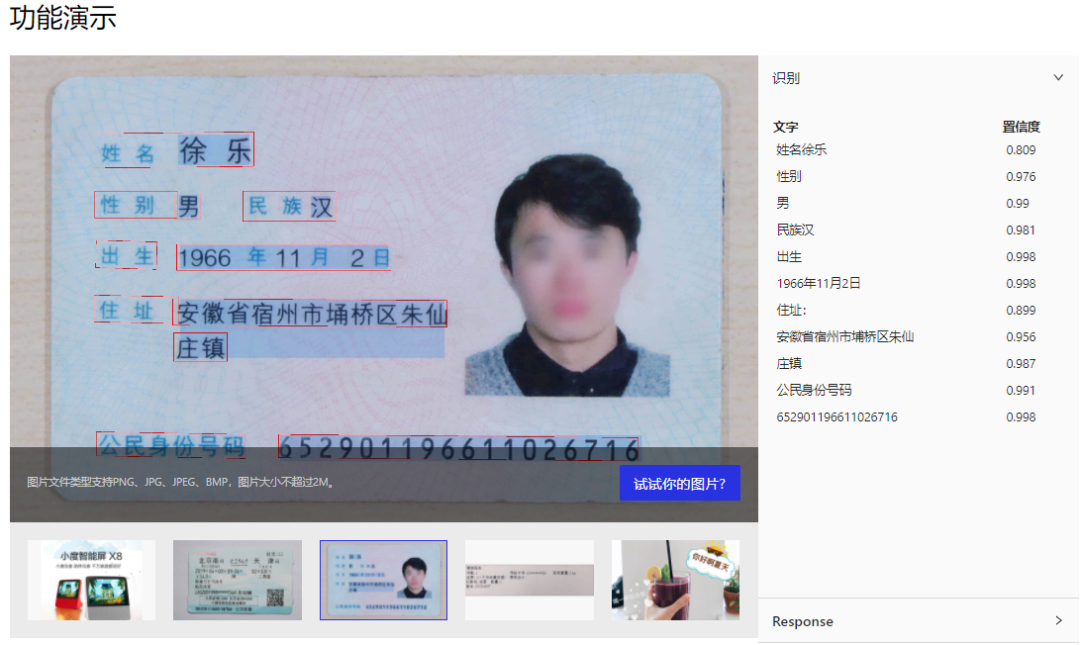
2). 手機端 App 安裝體驗PaddleOCR 在百度大腦 EasyEdge 上開放了文字識別 APP demo。 示例效果如下(可以在 github 首頁找到下載二維碼)

多個開源 repo 測試對比
簡單對比一下目前主流 OCR 方向開源 repo 的核心能力:
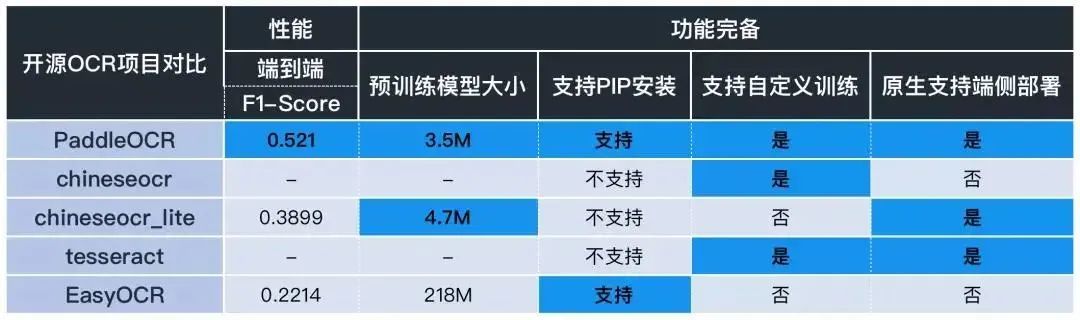
3). 從性能指標來看:
針對 OCR 實際應用場景,包括合同,車牌,銘牌,火車票,化驗單,表格,證書,街景文字,名片,數(shù)碼顯示屏等,收集的 300 張圖像,每張圖平均有 17 個文本框,PaddleOCR 的 F1-Score 超過 0.5,這個性能已經(jīng)很不錯了。
4). 從功能完備來看:
預訓練模型大小:easyOCR 目前暫無超輕量模型,chineseocr_lite 最新的模型是 4.7M 左右,而 PaddleOCR 提供的 3.5M 無疑是目前業(yè)界已知最輕量的。
PIP 安裝:目前僅 PaddleOCR 和 easyOCR 支持。
自定義訓練:實際業(yè)務場景中,預訓練模型往往不能滿足需求,對于自定義訓練和模型 Finetuning,目前只有 PaddleOCR 支持。
部署方面:easyOCR 模型較大不適合端側部署,Chineseocr_lite 和 PaddleOCR 都具備端側部署能力。
開發(fā)者可以根據(jù)自己的實際需求,選擇適合自己的開源方案。 對于 PaddleOCR3.5MB 的超輕量模型,是如何做到的,repo 中也給出了解釋。

3.5M 超輕量模型應用了一套超輕量 OCR 系統(tǒng) PP-OCR,主要由 DB 文本檢測、檢測框矯正和 CRNN 文本識別三部分組成。該系統(tǒng)從骨干網(wǎng)絡選擇和調整、預測頭部的設計、數(shù)據(jù)增強、學習率變換策略、正則化參數(shù)選擇、預訓練模型使用以及模型自動裁剪量化 8 個方面,采用 19 個有效策略,對各個模塊的模型進行效果調優(yōu)和瘦身。 其中,飛槳模型壓縮庫 PaddleSlim 為 PaddleOCR 超輕量化模型的實現(xiàn)提供了核心的技術支撐。從超輕量模型 8.1M 的壓縮到 3.5M,模型大小降低了 56.79%,其中檢測模型速度提升 21%,而且整體模型精度還有提升。

除了 3.5M 超輕量 OCR 模型,PaddleOCR 提供了多語言預訓練模型(英、德、法、韓、日),支持自定義訓練和豐富的部署方式。
責任編輯:PSY
原文標題:Github標星4.6K+!這個OCR開源項目,火了!
文章出處:【微信公眾號:人工智能與大數(shù)據(jù)技術】歡迎添加關注!文章轉載請注明出處。
-
開源
+關注
關注
3文章
4207瀏覽量
46139 -
OCR
+關注
關注
0文章
175瀏覽量
17201 -
GitHub
+關注
關注
3文章
488瀏覽量
18670
原文標題:Github標星4.6K+!這個OCR開源項目,火了!
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數(shù)據(jù)技術】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
模力方舟現(xiàn)已正式開源官方Skills倉庫Moark Skills

工業(yè)級OCR手持終端怎么選?國產(chǎn)OCR智能識別pda實測

沐曦曦云C500/C550 GPU產(chǎn)品適配智譜GLM-OCR模型

DeepX OCR:以 DeepX NPU 加速 PaddleOCR 推理,在 ARM 與 x86 平臺交付可規(guī)模化的高性能 OCR 能力


小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰(zhàn)解析
【嘉楠堪智K230開發(fā)板試用體驗】+OCR實現(xiàn)
如何利用OCR技術實現(xiàn)高效集裝箱箱號識別?

ocr識別時數(shù)據(jù)集上傳壓縮包,上傳成功,但不顯示圖片,圖片數(shù)量仍顯示0,為什么?
端側OCR文字識別實現(xiàn) -- Core Vision Kit ##HarmonyOS SDK AI##
明治案例 | 150個/分鐘!電阻【OCR識別】+【尺寸測量】一步到位

OCR識別訓練完成后給的是空壓縮包,為什么?

大模型預標注和自動化標注在OCR標注場景的應用
阿普奇視覺控制器AK7在OCR識別場景中的應用




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論