 DeepX OCR:以 DeepX NPU 加速 PaddleOCR 推理,在 ARM 與 x86 平臺交付可規模化的高性能 OCR 能力
DeepX OCR:以 DeepX NPU 加速 PaddleOCR 推理,在 ARM 與 x86 平臺交付可規模化的高性能 OCR 能力

一、行業背景與核心挑戰:OCR 規模化應用的關鍵瓶頸
**隨著文檔識別技術的不斷成熟,OCR 技術已從實驗性階段逐步走向實際業務場景,在政務、金融、制造、物流等多個行業中得到廣泛應用。然而,在規模化落地過程中,企業逐漸意識到:**制約 OCR 應用進一步擴展的核心因素,已不再是模型準確率本身,而是整體推理性能與部署成本。
具體來說,規模化 OCR 應用主要面臨以下幾方面挑戰:
- 吞吐量(FPS)不足 ,難以支撐高并發或多路輸入場景;
- 推理時延偏高 ,影響實時性要求較高的業務流程;
- 部署與算力成本受限 ,在邊緣設備與服務器環境中難以兼顧性能與成本。
尤其是在 邊緣計算(ARM 平臺) 與 服務器端(x86 平臺) 并存的實際部署環境下,如何實現性能、精度與成本之間的平衡,已成為企業在 OCR 技術選型中的關鍵決策問題。
二、DeepX OCR 解決方案概述:以 DeepX NPU 加速為核心,PaddleOCR 為載體
DeepX OCR 是以 DeepX NPU 推理加速能力 為核心,以 PaddleOCR(PP?OCRv5)模型體系 為載體的聯合解決方案,面向對 OCR 吞吐量、時延與成本高度敏感的實際生產場景。
在該方案中,PaddleOCR 提供成熟、穩定、工程化程度較高的文本檢測與識別模型能力,而 DeepX NPU 則作為關鍵算力引擎,對 OCR 推理流程進行深度加速與優化 ,從系統層面釋放模型在 ARM 與 x86 平臺上的性能潛力。
依托 DeepX NPU 的硬件級加速能力,DeepX OCR 在保證字符識別精度穩定的前提下,顯著提升模型推理速度,并在 ARM 與 x86 平臺上實現一致、可擴展且可復現的性能表現 ,為 OCR 的規模化部署與長期演進提供堅實基礎。
核心優勢與技術定位
- DeepX NPU 推理加速 :圍繞 OCR 推理關鍵算子與執行流程進行優化,大幅提升吞吐能力并降低單次推理時延;
- PaddleOCR(PP?OCRv5)模型體系 :模型成熟穩定,具備良好的泛化能力與工程落地基礎;
- 跨平臺性能一致性 :在 ARM 邊緣平臺與 x86 服務器平臺上均可獲得穩定、可預期的性能收益;
- 性能數據可復現 :提供標準化 Benchmark 測試流程,確保性能數據可核驗、可對比。
三、性能評測結果分析:ARM 與 x86 雙平臺表現
3.1 ARM 平臺性能表現
在 ARM 平臺(Rockchip aarch64)環境下,DeepX OCR 提供 Mobile 與 Server 兩種配置方案,適配不同業務對實時性與精度的需求。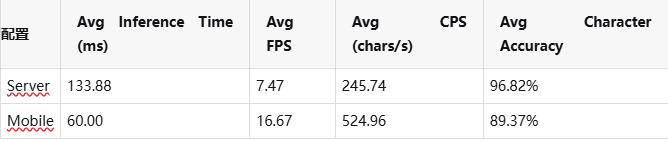
Mobile 配置在邊緣設備上展現出更高的吞吐能力與更低的推理時延,適用于實時采集、多路輸入等場景;而 Server 配置則更側重字符識別精度,適合關鍵字段識別與高精度校驗類業務。
3.2 x86 平臺性能擴展能力
在 x86 平臺上,DeepX OCR 針對單卡、雙卡與三卡配置進行了系統性測試,以評估其多卡擴展能力。
Server 配置(精度優先)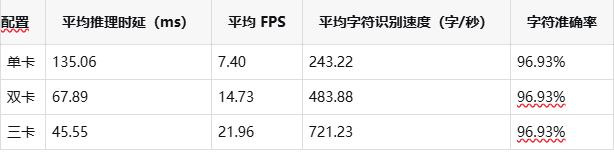
Mobile 配置(吞吐優先)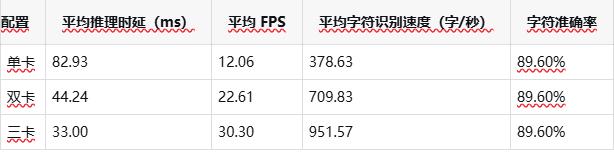
在 x86 平臺上,隨著算力規模的持續擴展,整體吞吐能力(FPS)與推理時延表現出良好的線性提升特性,能夠有效支撐高并發、大規模 OCR 服務的穩定部署與運行。Mobile 配置更強調吞吐能力,而 Server 配置則保持穩定的高字符準確率,企業可根據具體業務需求進行靈活選擇。
四、動手實踐:從零搭建 DeepX OCR 本地推理環境
本節將引導您從零開始,在目標平臺(ARM 或 x86)上完成 DeepX OCR 的編譯、模型下載與本地推理驗證。整個流程設計為端到端可復現,確保您能夠在自己的環境中獲得與官方 Benchmark 一致的推理體驗。
4.1 環境準備
第一步:克隆項目倉庫
# 克隆倉庫(包含 Git Submodules)
git clone --recursive https://github.com/Chris-godz/DEEPX-OCR.git
cd DEEPX-OCR
第二步:安裝系統依賴
# 安裝 FreeType 及相關依賴(用于多語言文本渲染)
sudo apt-get update
sudo apt-get install -y libfreetype6-dev libharfbuzz-dev libfmt-dev
4.2 編譯項目
DeepX OCR 采用 CMake 構建系統,支持 Release 和 Debug 兩種構建模式
# 執行編譯腳本(默認 Release 模式)
bash build.sh clean test
編譯腳本會自動:
- 初始化并編譯 OpenCV(含 opencv_contrib 模塊)
- 編譯 DeepX OCR 核心推理引擎
- 生成測試可執行文件
4.3 下載模型
DeepX OCR 提供Server和Mobile兩套模型配置:
./setup.sh
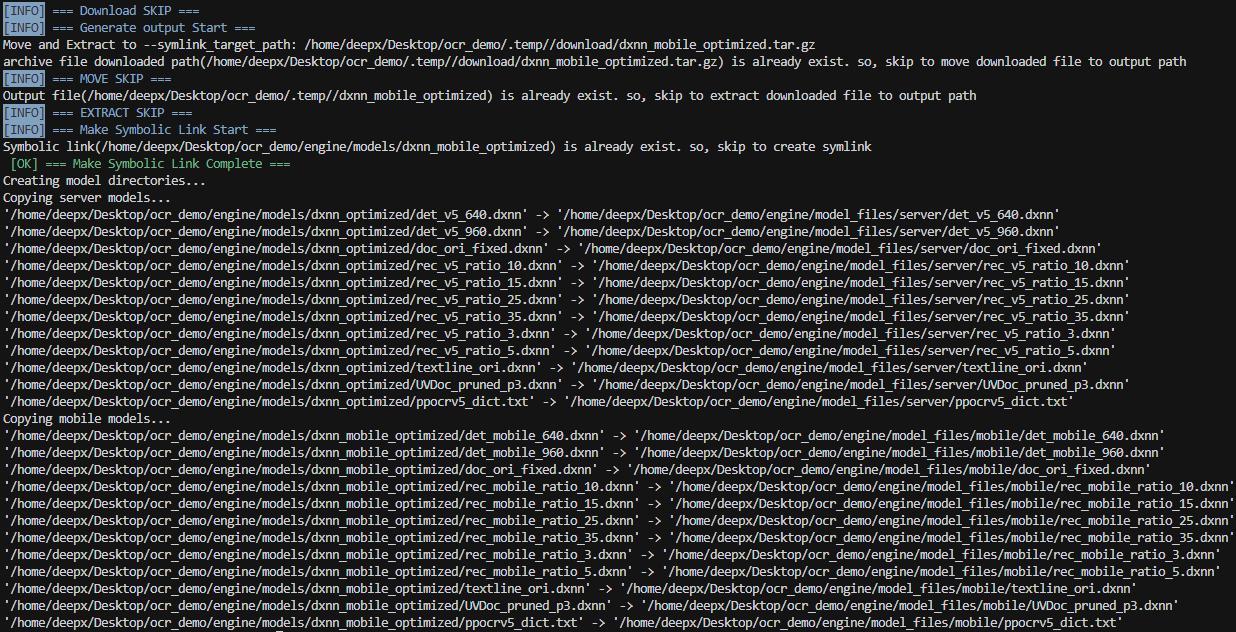
模型將被部署到以下目錄:
engine/model_files/
├── server/ # Server 模型(高精度)
│ ├── *.dxnn # DeepX NPU 優化模型
│ └── *.txt # 字典文件
└── mobile/ # Mobile 模型(高吞吐)
├── *.dxnn
└── *.txt
4.4 配置DXRT 運行時環境
DeepX NPU 推理需要配置運行時環境變量以優化性能:
# 配置 DXRT 環境變量
source ./set_env.sh 1 2 1 3 2 4
環境變量說明: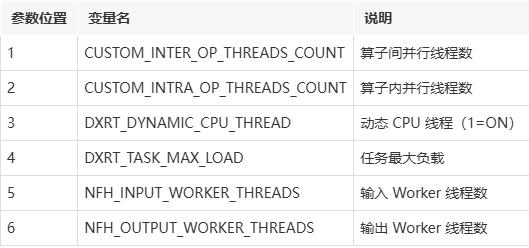
4.5 運行推理測試
DeepX OCR 提供交互式測試菜單,可快速驗證各模塊功能:
# 啟動交互式測試菜單
./run.sh
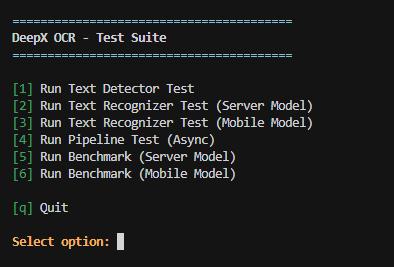
4.6 執行性能基準測試
# Run benchmark (Server model, 60 runs per image)
python3 benchmark/run_benchmark.py --model server --runs 60
--images_dir test/twocode_images
# Run benchmark (Mobile model, 60 runs per image)
python3 benchmark/run_benchmark.py --model mobile --runs 60
--images_dir test/twocode_images
推理完成后,結果將保存在 benchmark/ 目錄下,按模型類型分別存儲
benchmark/
├── results_server/ # Server 模型結果
│ ├── DXNN-OCR_benchmark_report.md # Benchmark 性能報告
│ └── image_*_result.json # 每張圖片的 OCR 結構化結果
├── results_mobile/ # Mobile 模型結果
│ ├── DXNN-OCR_benchmark_report.md
│ └── image_*_result.json
├── vis_server/ # Server 模型可視化圖像
│ └── image_*.jpg # 帶檢測框的結果圖像
├── vis_mobile/ # Mobile 模型可視化圖像
│ └── image_*.jpg
└── benchmark_results.json # 匯總性能數據

所有結果將保存至benchmark/目錄,包含可視化圖像與結構化 JSON 輸出。
五、OCR Server 部署:面向生產環境的高性能 HTTP 服務
DeepX OCR Server 基于Crow高性能 HTTP 框架構建,支持并發請求處理、圖像與 PDF 文件輸入,可直接作為后端服務集成到業務系統中。
5.1 啟動****OCR Server
確保已完成第四章的編譯與環境配置后,執行以下命令啟動服務:
cd /home/deepx/Desktop/DEEPX-OCR/server
# 使用默認配置啟動(端口 8080,Server 模型)
./run_server.sh
# 或指定參數啟動
./run_server.sh -p 8080 -m server -t 4
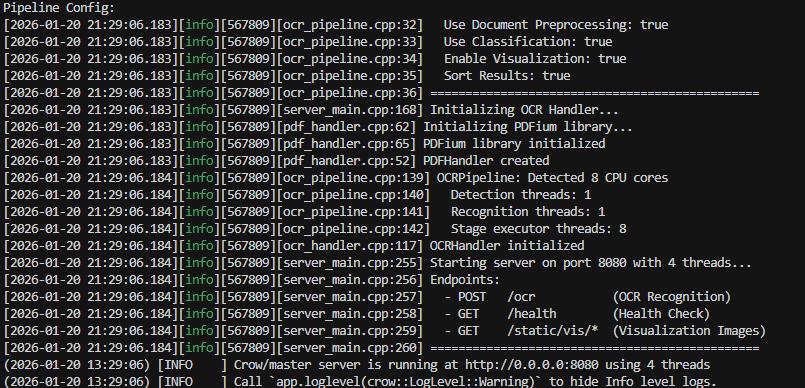
** 命令行參數 :**
示例:使用 Mobile 模型,端口 9090
./run_server.sh -p 9090 -m mobile
5.2 驗證服務狀態
在另一個終端窗口中執行健康檢查:
curl http://localhost:8080/health
預期響應:
{"status":"healthy","service":"DeepX OCR Server","version":"1.0.0"}
POST /ocr - 圖像 OCR 識別
請求示例 (使用 curl):
# 生成圖像請求 JSON 文件
echo "{"file": "$(base64 -w 0 images/image_1.png)", "fileType": 1, "visualize": true}" > /tmp/image_request.json
# 發送請求(使用 @文件 方式,避免命令行參數過長)
curl -X POST http://localhost:8080/ocr
-H "Content-Type: application/json"
-H "Authorization: token deepx_token"
-d @/tmp/image_request.json | python3 -m json.tool
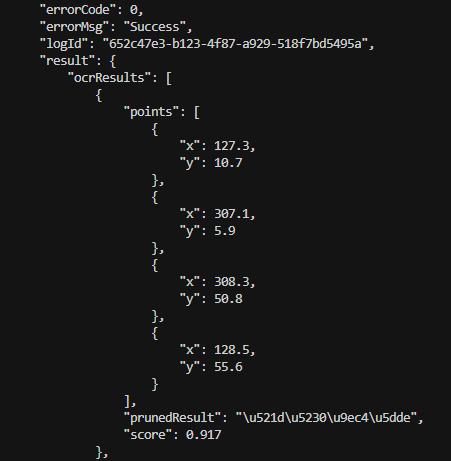
** 請求參數說明 :**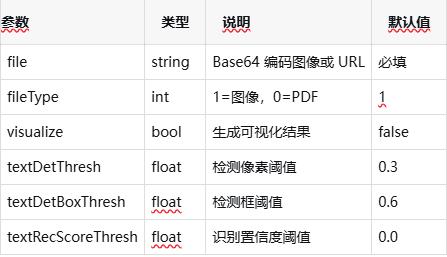
POST /ocr - PDF OCR 識別
# 生成 PDF 請求 JSON 文件
echo "{"file": "$(base64 -w 0 server/pdf_file/test.pdf)", "fileType": 0, "pdfDpi": 150, "pdfMaxPages": 10, "visualize": true}" > /tmp/pdf_request.json
# 發送請求
curl -X POST http://localhost:8080/ocr
-H "Content-Type: application/json"
-H "Authorization: token deepx_token"
-d @/tmp/pdf_request.json | python3 -m json.tool
5.4性能基準測試
DeepX OCR Server 提供完整的基準測試工具套件:
cd server/benchmark
# Image OCR 測試(4 并發)
./run.sh --mode image -c 4
# PDF OCR 測試
./run.sh --mode pdf --dpi 150 --max-pages 10
測試結果輸出 :
server/benchmark/results/
├── API_benchmark_report.md # Image OCR 報告
└── PDF_benchmark_report.md # PDF OCR 報告
六、WebUI Demo 體驗:可視化交互,一鍵體驗加速效果
在性能評測與工程驗證之外,DeepX OCR 同時提供 WebUI Demo 作為配套的體驗與驗證服務。通過 WebUI,用戶可以從實際輸入出發,直觀感受 DeepX NPU 加速下 PaddleOCR 的完整推理流程。
6.1 啟動 WebUI
前置條件
確保 OCR Server 已在后臺運行(參考第五章)。
安裝 Python 依賴
# 進入 WebUI 目錄
cd /home/deepx/Desktop/DEEPX-OCR/server/webui
# 創建 Python 虛擬環境
python3 -m venv venv
# 激活虛擬環境
source venv/bin/activate
# 安裝依賴
pip install --upgrade pip
pip install -r requirements.txt
啟動 WebUI 服務
# 確保虛擬環境已激活
source venv/bin/activate
# 啟動 WebUI(默認連接 localhost:8080 的 OCR Server)
python app.py

** 訪問 WebUI :**
在瀏覽器中打開:http://localhost:7860
6.2 功能體驗
圖像 OCR 識別
- 上傳圖像 :將圖像拖拽到 "
審核編輯 黃宇
發布評論請先 登錄
工業級OCR手持終端怎么選?國產OCR智能識別pda實測

沐曦曦云C500/C550 GPU產品適配智譜GLM-OCR模型

博世中階智能輔助駕駛方案實現規模化交付
小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰解析
【嘉楠堪智K230開發板試用體驗】+OCR實現
【EASY EAI Orin Nano開發板試用體驗】PP-OCRV5文字識別實例搭建與移植
睿海光電以高效交付與廣泛兼容助力AI數據中心800G光模塊升級
“香山”實現業界首個開源芯片的產品級交付與首次規模化應用

端側OCR文字識別實現 -- Core Vision Kit ##HarmonyOS SDK AI##
OCR識別訓練完成后給的是空壓縮包,為什么?
邊緣AI運算革新 DeepX DX-M1 AI加速卡結合Rockchip RK3588多路物體檢測解決方案

使用MicroPython部署中的ocrrec_image.py推理得到的輸出結果很差,如何解決呢?




 工商網監
工商網監
評論