") 如何用約43000張圖片的數(shù)據(jù)集,來計算得出表情包的火爆程度排名
如何用約43000張圖片的數(shù)據(jù)集,來計算得出表情包的火爆程度排名

電視節(jié)目的火爆程度可以根據(jù)尼爾森收視率排名(Neilsen ratings)來衡量,但是表情包呢?目前仍然沒有什么獨立指標(biāo)能用以評估表情包(memes)的瀏覽人數(shù),所以筆者自己摸索出了一些方法!
本文將說明如何用約43000張圖片的數(shù)據(jù)集和五項數(shù)據(jù)科學(xué)原則,來計算得出表情包的火爆程度排名。
1. 明確定義估算對象
對文字信息的理解因人而異。筆者不知見識過多少次這樣的場景:二人在對話中就項目的目標(biāo)達(dá)成了一致,之后卻發(fā)現(xiàn)彼此對關(guān)鍵詞的理解大相徑庭。因此,如果在項目開始時徹底厘清每個詞的定義,就能省下不少時間。
例如,假設(shè)你要估算“2019年的英國人口數(shù)量”。這是指2019年初、年末還是年中的人口數(shù)量?還是三者的平均值?這里的“人口”是指常住居民,還是包括游客和臨時居民在內(nèi)的所有人?
回到表情包的話題上。首先聲明,筆者要討論的并非表情包的學(xué)術(shù)定義,而是網(wǎng)絡(luò)表情包(結(jié)合了網(wǎng)上流行的圖像和文字)。更具體地說,筆者感興趣的是找出最流行的表情包模板(表情包的背景圖像)。因此筆者所謂的“最火表情包”其實指的是:瀏覽人次最多的表情包模板(通過累加所有使用該模板的網(wǎng)絡(luò)表情包的瀏覽量來計算得出)。
明確了這一點之后,就要開始收集數(shù)據(jù)。
2.以最小化偏差的方式采樣數(shù)據(jù)
尼爾森排名系統(tǒng)不可能監(jiān)測每臺電視機,同樣,筆者也無法全部下載網(wǎng)絡(luò)上的每個表情包。因此,這兩種情況都必須要經(jīng)過采樣。
如果一個數(shù)據(jù)樣本真正代表了更廣泛的群體,那么我們稱其為無偏見數(shù)據(jù)。但在很多情況下,這是不可能的。通常,我們必須以盡可能合理的方式最小化偏差,然后在分析數(shù)據(jù)時盡最大努力修正偏差。
本項目中的表情包采集自Reddit,它是世界上最大的圖片分享網(wǎng)站之一。使用一個爬蟲工具在一天中多次查看該網(wǎng)站與表情包有關(guān)的幾個部分,并且抓取前100張最受歡迎的圖片。
其中的許多表情包都托管在Imgur上,該網(wǎng)站公開了表情包瀏覽數(shù)據(jù)。因此交叉引用這些數(shù)據(jù)可以讓我們推斷出Reddit上圖片的瀏覽量。通過Reddit和Imgur的應(yīng)用程序接口(API),只需寥寥幾行python代碼就可完成該采樣。
接下來的問題是:這一采樣方法真的能夠最小化偏差嗎?Reddit只是網(wǎng)站中的一個個例,所以并不能真正代表整個互聯(lián)網(wǎng)。我們可以對其他網(wǎng)站(如instagram或Facebook)上的表情包進(jìn)行采樣,以減少偏差。
然而,這些網(wǎng)站公開的數(shù)據(jù)有限,無法進(jìn)行比對。比對這些網(wǎng)站數(shù)據(jù)的唯一的方法是做出大膽的假設(shè),但此舉可能會為最終估計值引入更多的偏差。
沒有十全十美的答案。有時,我們只能接受這一點。筆者認(rèn)為應(yīng)當(dāng)從一個最優(yōu)的數(shù)據(jù)來源進(jìn)行采樣,而不是將多個數(shù)據(jù)來源合并起來得到一個不可靠的數(shù)據(jù)集。筆者之所以稱Reddit是最好的來源,是因為它是最大的圖像共享網(wǎng)站,從中(通過交叉引用Imgur的數(shù)據(jù))可以推斷出精度合適的瀏覽量。
3. 復(fù)雜模型只適用于復(fù)雜問題
我們需要確定數(shù)據(jù)集中每個表情包所使用的圖像模板。這是一個圖像分類問題,并且屬于一個簡單的圖像分類問題。如果簡單的方法就足以見效,那么就沒必要選擇復(fù)雜的解決方案。
近來最先進(jìn)的圖像分類器,比如那些在Image-Net比賽中名列前茅的分類器,都是能夠不受角度、光線或背景的影響而正確識別物體的深度神經(jīng)網(wǎng)絡(luò)。觀察一個表情包并識別其圖像模板則容易得多,因此需要的東西遠(yuǎn)非100層神經(jīng)網(wǎng)絡(luò)那么復(fù)雜。
表情包圖像模板的數(shù)量有限,并且都具有獨特的顏色模式。我們僅需要計算像素并將結(jié)果傳遞給線性支持向量機,就能精確地分類表情包。訓(xùn)練支持向量機僅需幾秒,而神經(jīng)網(wǎng)絡(luò)則需要數(shù)天。
4. 審核(有條件時引入人工)
很多時候,躊躇滿志的年輕數(shù)據(jù)科學(xué)家跑來找到筆者,自豪地公布一個偉大的發(fā)現(xiàn),卻在被問及如何審核結(jié)果時面露怯色。通過基本的審核發(fā)現(xiàn)重大紕漏后,所謂的偉大發(fā)現(xiàn)往往將黯然退場。
在審核圖形分類模型的結(jié)果時,人眼是無可替代的(至少目前如此)。你或許認(rèn)為,驗證圖形分類器在這個數(shù)據(jù)集(約有43000張圖像)上的結(jié)果需要很長時間,但有許多工具能加速這一過程。
借助標(biāo)注工具,筆者平均使用20秒就能夠?qū)徍?00張圖像(在10x10的格子中瀏覽),因此,全部審核完43000張圖像只花費了不到3小時。這樣的事情日常做大概吃不消,但一年一次還可以忍受。
5. 仔細(xì)考慮每個假設(shè)
統(tǒng)計模型有賴于數(shù)據(jù)和假設(shè)。通常情況下,原始數(shù)據(jù)無法優(yōu)化,但假設(shè)可以改進(jìn)。工作的最后一步是獲取數(shù)據(jù)集,并提取出每個表情包模板的瀏覽數(shù)據(jù)。由于數(shù)據(jù)具有局限性,這一分析需要一些額外的假設(shè)。
第一個假設(shè)涉及到缺失值。如果數(shù)據(jù)集中的某個條目出現(xiàn)了缺失值,那么最好是移除該條目(因而將減小樣本)呢,還是推測該缺失值是什么(因而或?qū)⒁胝`差)呢?
這取決于數(shù)據(jù)集中缺失值的比例。如果比例較低,通常最好直接丟棄缺失值。而如果比例較高(該表情包數(shù)據(jù)集就是如此),那么丟棄所有缺失值可能會大大降低樣本的代表性。因此,筆者認(rèn)為盡可能準(zhǔn)確地填充這些缺失值是更好的做法。
第二個假設(shè)涉及修正我們的數(shù)據(jù)集對Reddit用戶的傾向性。筆者用下面的“傳播”假設(shè)來解決這一問題。筆者從Reddit的幾十個不同板塊進(jìn)行了采樣,以此來測量每個表情包模板在多少個板塊中出現(xiàn)過。筆者假設(shè),一個表情包在Reddit內(nèi)部傳播得越廣,說明它在Reddit之外的傳播范圍也越廣。為了反映這一點,筆者擴(kuò)增了這些表情包的瀏覽次數(shù)。
對于假設(shè)來說,標(biāo)準(zhǔn)答案是不存在的。我們唯一的選擇就是做出能讓人信服的抉擇。
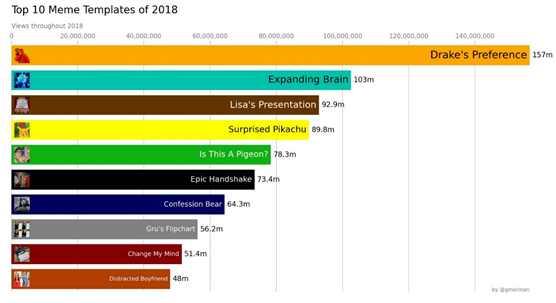
計算結(jié)果:最受歡迎的表情包模板(2018年)
該算法在2018年全年都在運行,共下載了40萬張圖片,并識別出其中的43660張使用了250個最常見的表情包模板之一。
如你所見,歌星Drake的表情圖以極大優(yōu)勢奪得了2018年的流行之冠,共有1億5700萬次瀏覽量(該分析結(jié)果很有可能小于實際數(shù)據(jù))。
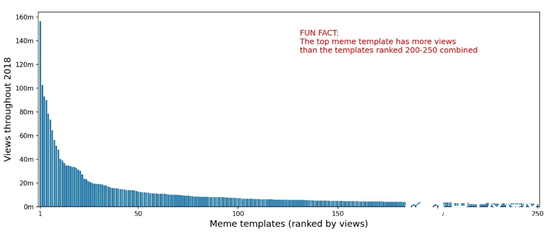
此外,頂層模板的總瀏覽量分布近似于帕累托分布(Pareto distribution)。
世界上有許多難以精確測算的事物,表情包的流行程度就是其中之一。有時我們只能盡量追求最優(yōu)解。筆者討論了在這一工作中使用的5項原則,一言以蔽之,即:在著手開始之前,仔細(xì)考慮項目的每個步驟。
責(zé)編AJX
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7335瀏覽量
94754 -
數(shù)據(jù)采集
+關(guān)注
關(guān)注
41文章
8037瀏覽量
120873 -
數(shù)據(jù)科學(xué)
+關(guān)注
關(guān)注
0文章
168瀏覽量
10794
發(fā)布評論請先 登錄
MinGW-w64工具集壓縮包的下載
用“分區(qū)”來面對超大數(shù)據(jù)集和超大吞吐量
為啥 AI 計算速度這么驚人?—— 聊聊 GPU、內(nèi)存與并行計算




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論