 用“分區”來面對超大數據集和超大吞吐量
用“分區”來面對超大數據集和超大吞吐量

1. 為什么要分區?
分區(partitions) 也被稱為 分片(sharding),通常采用對數據進行分區的方式來增加系統的 可伸縮性,以此來面對非常大的數據集或非常高的吞吐量,避免出現熱點。
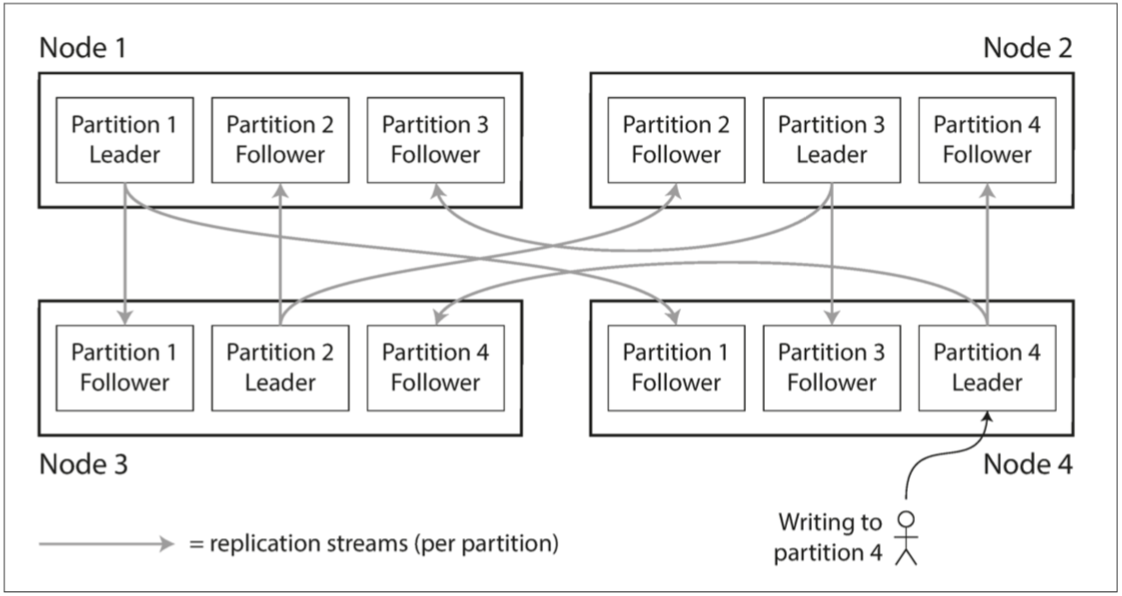
分區通常和復制結合使用,使得每個分區的副本存儲在多個節點上,保證數據副本的 高可用。如下圖所示,如果數據庫被分區,每個分區都有一個主庫。不同分區的主庫可能在不同的節點上,每個節點可能是某些分區的主庫,同時是其他分區的從庫。
1.1 一致前綴讀
分區也會由于復制延遲而產生問題,我們先來看下圖中的例子,是Poons先生和Cake小姐的對話:
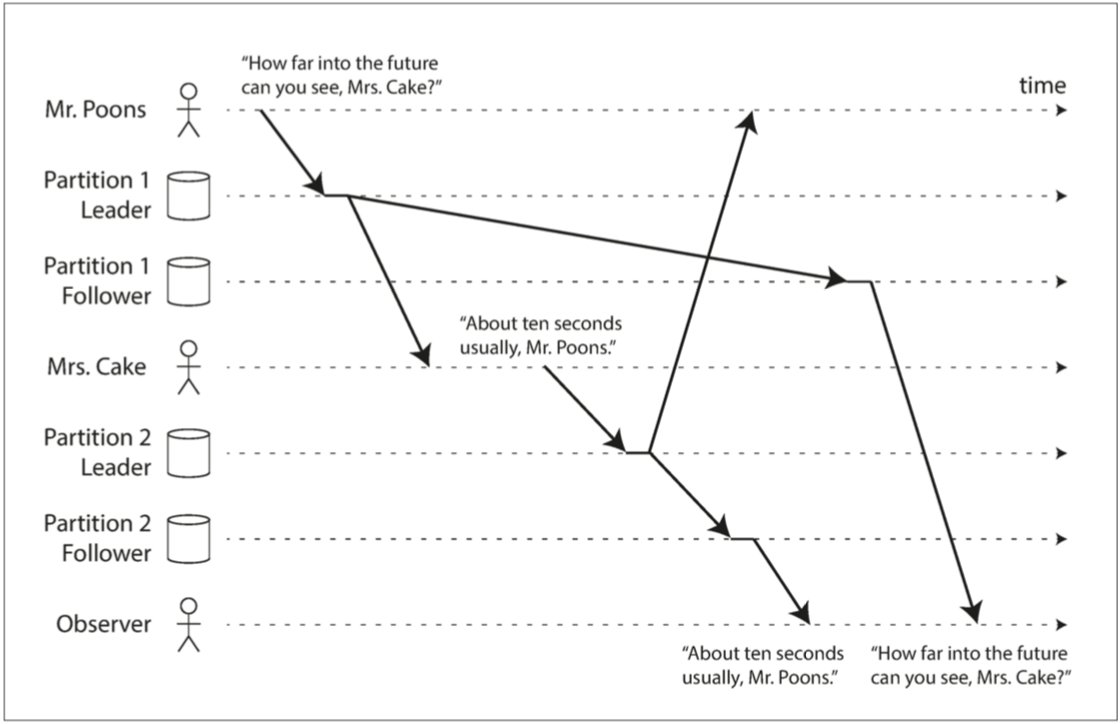
Poons先生先問: “How far into the future can you see, Mrs.Cake?”
Cake小姐回答說: “About ten seconds usually, Mr.Poons.”
正常情況下,這段對話是有因果關系的(先問后答)。但是對于觀察者,他看到的順序卻是先得到了答案,再看到了問題,這就是在分區數據庫中,因復制延遲而產生的特殊情況。
為了避免這種混亂,我們就需要保證 一致前綴讀:如果一系列寫入按某個順序發生,那么任何人讀取這些寫入時,也會看見它們以同樣的順序出現。一種解決方案是,確保任何因果相關的寫入都在相同的分區。
2. 該怎么分區?
分區的目的是將數據和負載均勻的分布到各個節點上,理論上10個節點能夠處理10倍的數據量和10倍單節點的讀寫吞吐量。
但是如果分區不均,那么就會出現一些分區有更多的數據或讀寫,我們稱之為 偏斜,這會使得分區后并沒有得到很大的效率提升。在極端情況下,所有的負載如果都落在一個分區,使得該分區負載過高,我們稱之為 熱點。
所以,為了避免偏斜和熱點的產生,以鍵值數據的分區為例,討論如何將數據分區做得妥當。
2.1 根據鍵的范圍進行分區
我們可以根據鍵值的范圍進行分區,比如說我們以26個英文字符劃分26個分區,之后根據鍵值首字母對它們進行分區。通常情況下,鍵值并不是均勻分布的,這會造成按照首字母分區之后,發生數據偏斜。為了均勻分配數據,分區的邊界需要根據數據分區的實際情況再進行調整。
2.2 散列分區
一個好的散列函數可以將數據均勻分布,避免發生偏斜。但是這也帶來了問題:我們沒有辦法再進行高效的范圍查詢。
3. 熱點消除
避免熱點最簡單的方法是將數據記錄進行散列分區,記錄因此會在所有節點上平均分配。
但是它并不能完全避免熱點的產生,因為如果所有的讀寫操作都是針對同一個鍵的話,那么所有的請求還是會被路由到同一個分區。比如說有一個百萬粉絲的博主發布動態,該動態根據博主ID的鍵值進行分區,如果此時有大量的粉絲對該動態進行互動,那么哈希策略會把這些請求都路由到同一個分區進行操作,發生熱點事件。
其實,我們還可以在該熱點鍵上再進行分區,以避免熱點:在主鍵的最后拼接隨機數,兩位十進制的隨機數就能把一個主鍵分成100個不同的主鍵,從而存儲在不同的分區中,這就完成了熱點消除。但是主鍵被分割后,任何讀取工作都必須在每次讀取時將所有的數據拉出去合并到一起再返回結果。
4. 分區再平衡
如果保存某分區數據的服務器故障,需要使用其他服務器接管或想將目前的服務器換成性能更好的服務器,那么就需要進行 分區再平衡。
分區再平衡 是將負載從集群中的一個節點向另一個節點移動的過程。執行再平衡需要滿足以下要求:
再平衡期間,數據庫應該繼續接受讀取和寫入
節點之間只移動必須的數據,以便快速再平衡,并減少網絡和磁盤的IO負載
再平衡之后,負載應該在集群中的節點之間公平地共享
比較簡單的再平衡分區策略是選擇 固定數量的分區,當節點數量增加時,可以從原節點中 竊取 一些分區(當節點數量減少時,則發生相反的情況),如下圖所示:
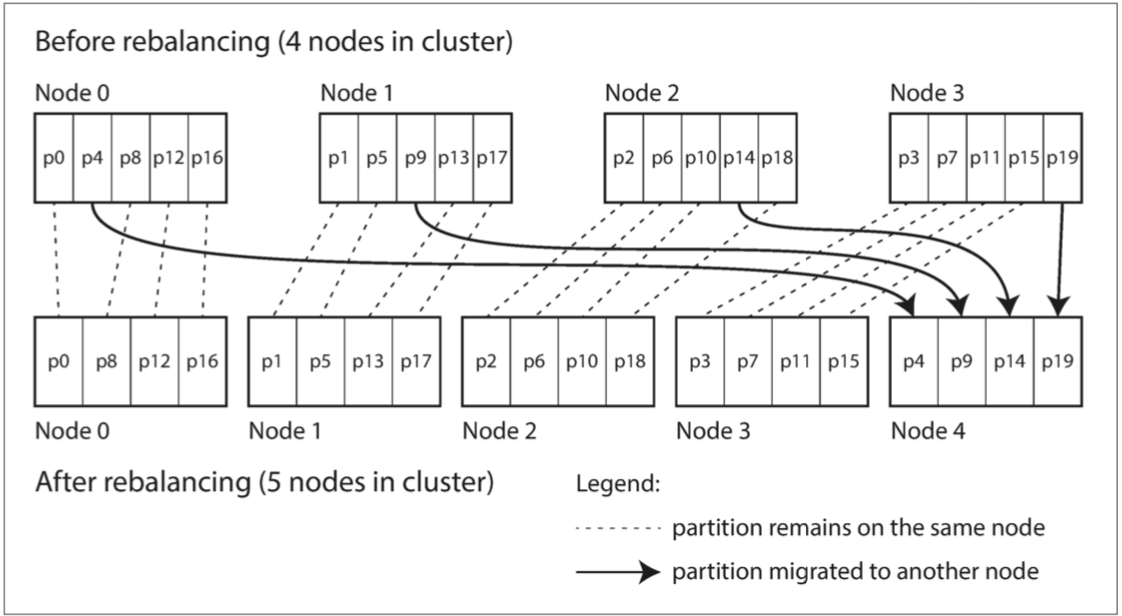
在這種配置中,分區的數量通常在數據庫第一次建立時確定,操作比較簡單,之后不會改變,因此你需要選擇足夠多的分區以適應未來的增長。但是,每個分區也有管理開銷,所以選擇太大的數字會適得其反。
除此之外也可選擇 動態分區,根據配置的分區大小,當超過該閾值時,可以將該大分區分割成兩個小分區,能夠使 分區數量適應總數據量。在大型分區拆分后,可以將其中的一半轉移到另一個節點上,以平衡負載。
還有一種 根據節點數增加來進行分區 的方法:每個節點上有固定的分區數,當節點增加時,分區將變小,新增的節點會從原有節點的分區中隨機進行拆分,最終這個新節點獲得公平的負載份額。
分區再平衡可以 手動執行 也可以 自動執行。自動再平衡比較方便,因為不需要人工維護,但是它的執行過程是不可預測的:再平衡時將大量數據集從一個節點轉移到另一個節點的過程中可能會產生很大的網絡開銷,這會使得該服務器對請求響應的性能降低,對用戶的體驗和生產造成負面影響。所以再平衡的過程有人參與是一件好事,這樣能防止發生運維問題。
5. 請求路由(服務發現)
當我們已經將數據進行分區后,如何才能知道用戶想要的數據在哪個節點上?這可以概括為是一個 服務發現 的問題。為了解決這個問題,可以通過如下圖所示的三個方案
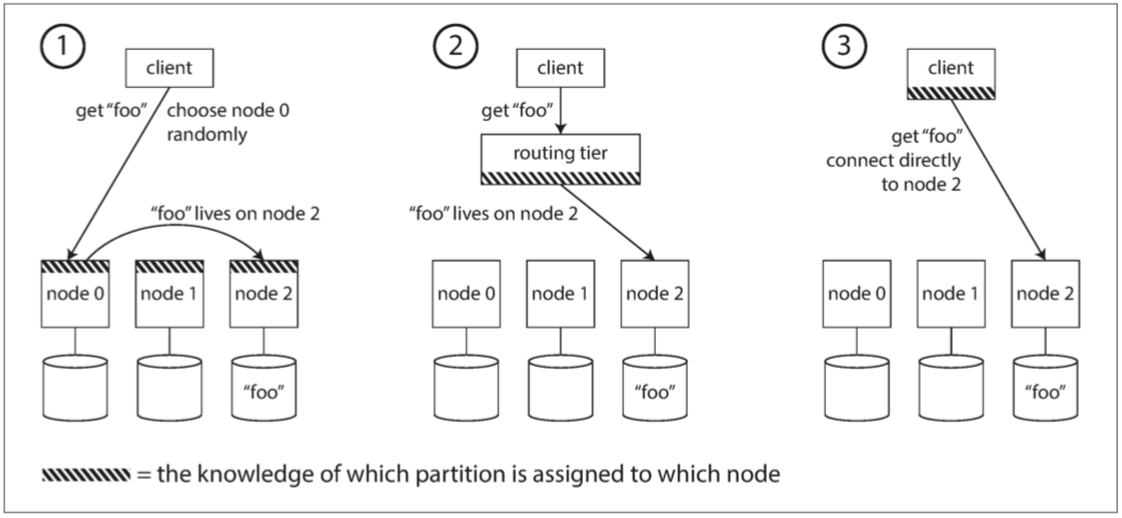
1. 允許訪問所有的節點,如果第一個訪問的節點有該鍵值,則處理該請求,否則將該請求轉發到適當的節點上,這個方法避免了使用注冊中心中間件,但是實現比較復雜
2. 使用分布式的協調服務,用戶將所有的請求發送到路由層,由路由層將該請求轉發到合適的節點
3. 要求用戶(客戶端)自己知道分區和節點的分配
但是這其中還隱藏著一個問題:作出決策的組件(節點之一、路由層或客戶端)是如何了解數據在節點間的分配變化的?這就需要一個獨立的協調服務,比如使用 zookeeper 來跟蹤元數據,如下圖所示
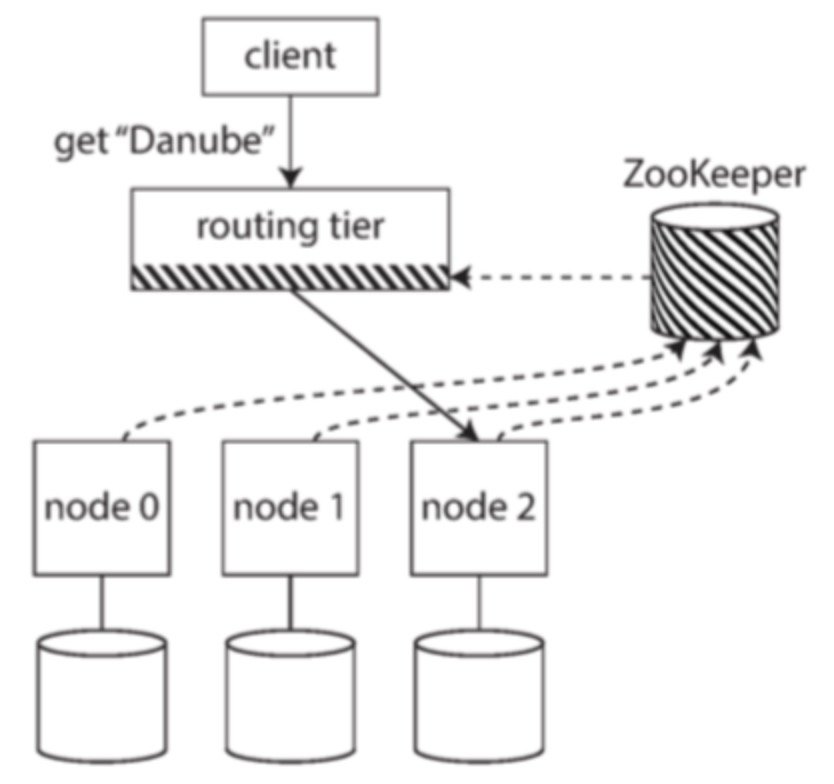
每個節點都會在 zookeeper 中進行注冊,zookeeper 中維護有節點到各個分區的可靠映射,負責決策的組件在 zookeeper 中訂閱這個消息。當分區分配發生改變時,zookeeper 就會通知負責決策的組件更新路由信息,使其保持在最新的狀態。
除此之外也可以在各個節點間采用 流言協議 來傳播集群狀態的變化,這樣每個節點都維護有最新的數據路由方案,當其中一個節點收到請求時,會將其轉發到合適的分區節點上(對應服務發現的方案一)。
-
節點
+關注
關注
0文章
229瀏覽量
25645 -
數據集
+關注
關注
4文章
1239瀏覽量
26254
發布評論請先 登錄
如何提高CYBT-243053-02吞吐量?
求助,關于使用iperf測量mesh節點吞吐量問題求解
網卡吞吐量測試解決方案
iperf固定吞吐量測試如何設置
USB CDC吞吐量問題
debug 吞吐量的辦法
debug 吞吐量的辦法
如何顯著提高ATE電源吞吐量?




 工商網監
工商網監
評論