 片機實現延時的兩種方法
片機實現延時的兩種方法

來源:大魚機器人
第一篇
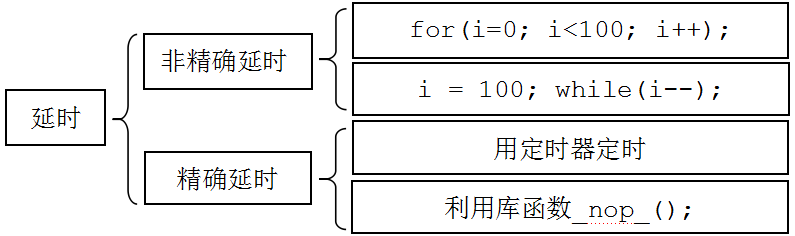
實現延時通常有兩種方法:一種是硬件延時,要用到定時器/計數器,這種方法可以提高CPU的工作效率,也能做到精確延時;另一種是軟件延時,這種方法主要采用循環體進行。
1 、使用定時器/計數器實現精確延時
單片機系統一般常選用11.059 2 MHz、12 MHz或6 MHz晶振。第一種更容易產生各種標準的波特率,后兩種的一個機器周期分別為1 μs和2 μs,便于精確延時。本程序中假設使用頻率為12 MHz的晶振。最長的延時時間可達216=65 536 μs。若定時器工作在方式2,則可實現極短時間的精確延時;如使用其他定時方式,則要考慮重裝定時初值的時間(重裝定時器初值占用2個機器周期)。
在實際應用中,定時常采用中斷方式,如進行適當的循環可實現幾秒甚至更長時間的延時。使用定時器/計數器延時從程序的執行效率和穩定性兩方面考慮都是最佳的方案。但應該注意,C51編寫的中斷服務程序編譯后會自動加上PUSH ACC、PUSH PSW、POP PSW和POP ACC語句,執行時占用了4個機器周期;如程序中還有計數值加1語句,則又會占用1個機器周期。這些語句所消耗的時間在計算定時初值時要考慮進去,從初值中減去以達到最小誤差的目的。
2 、軟件延時與時間計算
在很多情況下,定時器/計數器經常被用作其他用途,這時候就只能用軟件方法延時。下面介紹幾種軟件延時的方法。
2.1 短暫延時
可以在C文件中通過使用帶_NOP_( )語句的函數實現,定義一系列不同的延時函數,如Delay10us( )、Delay25us( )、Delay40us( )等存放在一個自定義的C文件中,需要時在主程序中直接調用。如延時10 μs的延時函數可編寫如下:
void Delay10us() {_NOP_( );_NOP_( );_NOP_( );_NOP_( );_NOP_( );_NOP_( );}
Delay10us( )函數中共用了6個_NOP_( )語句,每個語句執行時間為1 μs。主函數調用Delay10us( )時,先執行一個LCALL指令(2 μs),然后執行6個_NOP_( )語句(6 μs),最后執行了一個RET指令(2 μs),所以執行上述函數時共需要10 μs。
可以把這一函數當作基本延時函數,在其他函數中調用,即嵌套調用[4],以實現較長時間的延時;但需要注意,如在Delay40us( )中直接調用4次Delay10us( )函數,得到的延時時間將是42 μs,而不是40 μs。這是因為執行Delay40us( )時,先執行了一次LCALL指令(2 μs),然后開始執行第一個Delay10us( ),執行完最后一個Delay10us( )時,直接返回到主程序。依此類推,如果是兩層嵌套調用,如在Delay80us( )中兩次調用Delay40us( ),則也要先執行一次LCALL指令(2 μs),然后執行兩次Delay40us( )函數(84 μs),所以,實際延時時間為86 μs。簡言之,只有最內層的函數執行RET指令。該指令直接返回到上級函數或主函數。如在Delay80μs( )中直接調用8次Delay10us( ),此時的延時時間為82 μs。通過修改基本延時函數和適當的組合調用,上述方法可以實現不同時間的延時。
2.2 在C51中嵌套匯編程序段實現延時
在C51中通過預處理指令#pragma asm和#pragma endasm可以嵌套匯編語言語句。用戶編寫的匯編語言緊跟在#pragma asm之后,在#pragma endasm之前結束。
如:
#pragma asm
匯編語言程序段
#pragma endasm
延時函數可設置入口參數,可將參數定義為unsigned char、int或long型。根據參數與返回值的傳遞規則,這時參數和函數返回值位于R7、R7R6、R7R6R5中。在應用時應注意以下幾點:
◆ #pragma asm、#pragma endasm不允許嵌套使用;
◆ 在程序的開頭應加上預處理指令#pragma asm,在該指令之前只能有注釋或其他預處理指令;
◆ 當使用asm語句時,編譯系統并不輸出目標模塊,而只輸出匯編源文件;
◆ asm只能用小寫字母,如果把asm寫成大寫,編譯系統就把它作為普通變量;
◆ #pragma asm、#pragma endasm和 asm只能在函數內使用。
將匯編語言與C51結合起來,充分發揮各自的優勢,無疑是單片機開發人員的最佳選擇。
2.3 使用示波器確定延時時間
利用示波器來測定延時程序執行時間。方法如下: 編寫一個實現延時的函數,在該函數的開始置某個I/O口線如P1.0為高電平,在函數的最后清P1.0為低電平。在主程序中循環調用該延時函數,通過示波器測量P1.0引腳上的高電平時間即可確定延時函數的執行時間。 方法如下:
sbit T_point = P1^0;void Dly1ms(void) {unsigned int i,j;while (1) {T_point = 1;for(i=0;i《2;i++){for(j=0;j《124;j++){;}}T_point = 0;for(i=0;i《1;i++){for(j=0;j《124;j++){;}}}}void main (void) {Dly1ms();}
把P1.0接入示波器,運行上面的程序,可以看到P1.0輸出的波形為周期是3 ms的方波。其中,高電平為2 ms,低電平為1 ms,即for循環結構“for(j=0;j《124;j++) {;}”的執行時間為1 ms。通過改變循環次數,可得到不同時間的延時。當然,也可以不用for循環而用別的語句實現延時。這里討論的只是確定延時的方法。
2.4 使用反匯編工具計算延時時間
用Keil C51中的反匯編工具計算延時時間,在反匯編窗口中可用源程序和匯編程序的混合代碼或匯編代碼顯示目標應用程序。為了說明這種方法,還使用
for (i=0;iC:0x000FE4CLRA//1TC:0x0010FEMOVR6,A//1TC:0x0011EEMOVA,R6//1TC:0x0012C3CLRC//1TC:0x00139FSUBBA,DlyT //1TC:0x00145003JNCC:0019//2TC:0x00160E INCR6//1TC:0x001780F8SJMPC:0011//2T
可以看出,0x000F~0x0017一共8條語句,分析語句可以發現并不是每條語句都執行DlyT次。核心循環只有0x0011~0x0017共6條語句,總共8個機器周期,第1次循環先執行“CLR A”和“MOV R6,A”兩條語句,需要2個機器周期,每循環1次需要8個機器周期,但最后1次循環需要5個機器周期。DlyT次核心循環語句消耗(2+DlyT×8+5)個機器周期,當系統采用12 MHz時,精度為7 μs。
當采用while (DlyT--)循環體時,DlyT的值存放在R7中。相對應的匯編代碼如下:
C:0x000FAE07MOVR6, R7//1TC:0x00111F DECR7//1TC:0x0012EE MOVA,R6//1TC:0x001370FAJNZC:000F//2T
循環語句執行的時間為(DlyT+1)×5個機器周期,即這種循環結構的延時精度為5 μs。
通過實驗發現,如將while (DlyT--)改為while (--DlyT),經過反匯編后得到如下代碼:
C:0x0014DFFE DJNZR7,C:0014//2T
可以看出,這時代碼只有1句,共占用2個機器周期,精度達到2 μs,循環體耗時DlyT×2個機器周期;但這時應該注意,DlyT初始值不能為0。
注意:計算時間時還應加上函數調用和函數返回各2個機器周期時間。
第二篇
聲明: 作者初學單片機編程,本著刨根問底的探索精神,對延時代碼進行了完全透徹的分析,計算出其中的誤差,根據不同代碼占用機器周期進行調整。至于調整0.01ms左右的時間誤差對實際應用有何實際意義則不敢妄談。不過您看完這篇文章的綠色部分,即可明確延時程序的設計方法。
舉例程序段落:
系統頻率:6MHz
Delay: MOV R5,#25 ;5ms延時——MOV指令占用1機器周期時間Delay1: MOV R6,#200 ;200ms延時Delay2: MOV R7,#166 ;1ms延時常數Delay3: NOP ;空指令,什么都不做,停留1機器周期時間DJNZ R7,Delay3 ;R7減1賦值給R7,如果此時R7不等于零,轉到Delay3執行。——2機器周期時間DJNZ R6,Delay2DJNZ R5,Delay1
解析如下:
1、首先計算機器周期T=12*1/f=2μs。
2、注意DJNZ R7,Delay3每執行1次需要占用NOP的時間和DJNZ本身的時間共3個機器周期。6μs。那么1ms的時間需要1ms*1000/6μs=166.67,取166。
3、注意DJNZ R6,Delay2是在166次循環后執行1次的(時間為MOV機器周期+本身機器周期,3*2=6μs),直到166*200次后,R6=0,才執行DJNZ R5,Delay1。
4、DJNZ R5,Delay1是在R5不為0的時候循環回去。時間也為6μs。
5、時間總計:166*200*25*6μs+200*25*6μs+25*6μs=5010150μs,合計5.01015ms(編程的人都遇到過類似的潛逃循環,此程序忽略了執行MOV的時間,只計算了循環所用時間,即166*200*25*6/1000000=4.98ms,近似5ms)。
程序改進:
去掉NOP命令,整數化1ms需要的延時常數。
Delay: MOV R5,#25 ;5ms延時——MOV指令占用1機器周期時間Delay1: MOV R6,#200 ;200ms延時Delay2: MOV R7,#250 ;1ms延時常數Delay3: ;NOP ;空指令,什么都不做,停留1機器周期時間DJNZ R7,Delay3 ;R7減1賦值給R7,如果此時R7不等于零,轉到Delay3執行。——2機器周期時間DJNZ R6,Delay2DJNZ R5,Delay1
此時時間總計:250*200*25*4μs+200*25*6μs+25*6μs=5030150μs。時間占用誤差反而比未改進的時候大,可修正,將R7-30150/(25*200*4)=248(因為R7=250循環1次占用2個機器周期,4μs,計算等于R7-1.5075,將時間減小到小于5ms,剩余時間另補,取248)。則:
時間總計:248*200*25*4μs+200*25*6μs+25*6μs=4990150μs,需要補:5000000-4990150=9850μs,9850/2=4925機器周期。補一個MOV R4,#200,4個NOP,還需4920機器周期,將其約分,得到24*205=4920。如何建立函數根據實際代碼調整,如下:
Delay: MOV R5,#25 ;5ms延時——MOV指令占用1機器周期時間Delay1: MOV R6,#200 ;200ms延時Delay2: MOV R7,#250 ;1ms延時常數Delay3: ;NOP ;空指令,什么都不做,停留1機器周期時間DJNZ R7,Delay3 ;R7減1賦值給R7,如果此時R7不等于零,轉到Delay3執行。——2機器周期時間DJNZ R6,Delay2DJNZ R5,Delay1NOPNOPNOPNOPMOV R3,#6Delayadd: MOV R4,#205MOV R2,#0HDJNZ R3,Delayadd
解析205*24調整為205*6——這是因為Delay循環為4機器周期代碼,因此將24/4=6。請計算:205*6*4=4920;4920+5=4925。時間補充正好。此時時間計算:
248*200*25*4μs+200*25*6μs+25*6μs=4990150μs+4925*2μs=5000000μs合計5ms。
理論上1μs都不差(僅為科學探討,具體晶振頻率的誤差多大作者并不明確)。
-
單片機
+關注
關注
6076文章
45494瀏覽量
670266 -
計數器
+關注
關注
32文章
2315瀏覽量
98170 -
延遲
+關注
關注
1文章
74瀏覽量
13957 -
C51
+關注
關注
5文章
284瀏覽量
60239
發布評論請先 登錄
提高低電壓大電流電源器件效率的兩種方法

兩個MCU之間快速傳輸數據的方法
一文說透了如何實現單片機的多任務并發!
如何在Zephyr RTOS中實現延時和計時函數

單片機系統硬件的調試方法
按鍵消抖的方法
第4章 C語言基礎以及流水燈的實現(4.7 4.8)
用PLC實現卷徑計算的兩種算法
有多少種方法可以進行頻響曲線測量?

GPIO位輸出操作的幾種方法分享
這兩種TVS有啥不同?

兩種散熱路徑的工藝與應用解析
兩片TC3XX芯片之間的時鐘同步可以實現嗎?
六相永磁同步電機串聯系統控制的兩種方法分析研究
分享兩種前沿片上互連技術



 工商網監
工商網監
評論