") Spark優(yōu)化:小文件合并的步驟
Spark優(yōu)化:小文件合并的步驟

我們知道,大部分Spark計算都是在內存中完成的,所以Spark的瓶頸一般來自于集群(standalone, yarn, mesos, k8s)的資源緊張,CPU,網絡帶寬,內存。Spark的性能,想要它快,就得充分利用好系統(tǒng)資源,尤其是內存和CPU。有時候我們也需要做一些優(yōu)化調整來減少內存占用,例如將小文件進行合并的操作。
一、問題現(xiàn)象
我們有一個15萬條總數(shù)據量133MB的表,使用SELECT * FROM bi.dwd_tbl_conf_info全表查詢耗時3min,另外一個500萬條總數(shù)據量6.3G的表ods_tbl_conf_detail,查詢耗時23秒。兩張表均為列式存儲的表。
大表查詢快,而小表反而查詢慢了,為什么會產生如此奇怪的現(xiàn)象呢?
二、問題探詢
數(shù)據量6.3G的表查詢耗時23秒,反而數(shù)據量133MB的小表查詢耗時3min,這非常奇怪。我們收集了對應的建表語句,發(fā)現(xiàn)兩者沒有太大的差異,大部分為String,兩表的列數(shù)也相差不大。
CREATE TABLE IF NOT EXISTS `bi`。`dwd_tbl_conf_info` ( `corp_id` STRING COMMENT ‘’, `dept_uuid` STRING COMMENT ‘’, `user_id` STRING COMMENT ‘’, `user_name` STRING COMMENT ‘’, `uuid` STRING COMMENT ‘’, `dtime` DATE COMMENT ‘’, `slice_number` INT COMMENT ‘’, `attendee_count` INT COMMENT ‘’, `mr_id` STRING COMMENT ‘’, `mr_pkg_id` STRING COMMENT ‘’, `mr_parties` INT COMMENT ‘’, `is_mr` TINYINT COMMENT ‘R’, `is_live_conf` TINYINT COMMENT ‘’ ) CREATE TABLE IF NOT EXISTS `bi`。`ods_tbl_conf_detail` ( `id` string, `conf_uuid` string, `conf_id` string, `name` string, `number` string, `device_type` string, `j_time` bigint, `l_time` bigint, `media_type` string, `dept_name` string, `UPDATETIME` bigint, `CREATETIME` bigint, `user_id` string, `USERAGENT` string, `corp_id` string, `account` string )
因為兩張表均為很簡單的SELECT查詢操作,無任何復雜的聚合join操作,也無UDF相關的操作,所以基本確認查詢慢的應該發(fā)生的讀表的時候,我們將懷疑的點放到了讀表操作上。通過查詢兩個查詢語句的DAG和任務分布,我們發(fā)現(xiàn)了不一樣的地方。
查詢快的表,查詢時總共有68個任務,任務分配比如均勻,平均7~9s左右,而查詢慢的表,查詢時總共1160個任務,平均也是9s左右。如下圖所示:
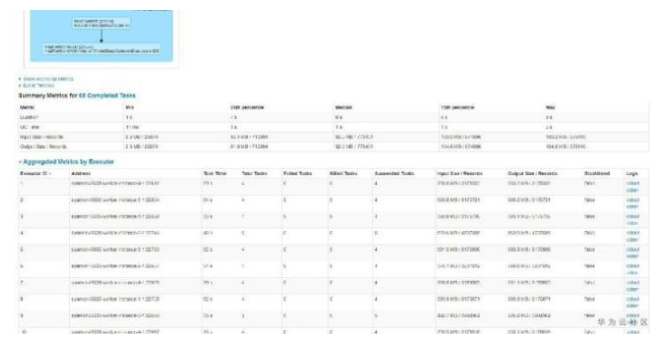
至此,我們基本發(fā)現(xiàn)了貓膩所在。大表6.3G但文件個數(shù)小,只有68個,所以很快跑完了。而小表雖然只有133MB,但文件個數(shù)特別多,導致產生的任務特別多,而由于單個任務本身比較快,大部分時間花費在任務調度上,導致任務耗時較長。
那如何才能解決小表查詢慢的問題呢?
三、業(yè)務調優(yōu)
那現(xiàn)在擺在我們面前就存在現(xiàn)在問題:
為什么小表會產生這么小文件 已經產生的這么小文件如何合并
帶著這兩個問題,我們和業(yè)務的開發(fā)人員聊了一個發(fā)現(xiàn)小表是業(yè)務開發(fā)人員從原始數(shù)據表中,按照不同的時間切片查詢并做數(shù)據清洗后插入到小表中的,而由于時間切片切的比較小,導致這樣的插入次數(shù)特別多,從而產生了大量的小文件。
那么我們需要解決的問題就是2個,如何才能把這些歷史的小文件進行合并以及如何才能保證后續(xù)的業(yè)務流程中不再產生小文件,我們指導業(yè)務開發(fā)人員做了以下優(yōu)化:
使用INSERT OVERWRITE bi.dwd_tbl_conf_info SELECT * FROM bi.dwd_tbl_conf_info合并下歷史的數(shù)據。由于DLI做了數(shù)據一致性保護,OVERWRITE期間不影響原有數(shù)據的讀取和查詢,OVERWRITE之后就會使用新的合并后的數(shù)據。合并后全表查詢由原來的3min縮短到9s內完成。 原有表修改為分區(qū)表,插入時不同時間放入到不同分區(qū),查詢時只查詢需要的時間段內的分區(qū)數(shù)據,進一步減小讀取數(shù)據量。
-
cpu
+關注
關注
68文章
11279瀏覽量
224993 -
數(shù)據庫
+關注
關注
7文章
4020瀏覽量
68353 -
SPARK
+關注
關注
1文章
108瀏覽量
21239
發(fā)布評論請先 登錄
全新軟件與模型優(yōu)化為NVIDIA DGX Spark注入強大動力
如何在DGX Spark上運行NVIDIA Omniverse

如何在CANape合并多個MDF格式的測量文件

NVIDIA DGX Spark系統(tǒng)恢復過程與步驟

系統(tǒng)c盤滿了怎么清理不需要文件
NVIDIA DGX Spark助力構建自己的AI模型

NVIDIA DGX Spark快速入門指南

程序運行速度很慢如何優(yōu)化?
安泰新能源發(fā)布新一代智能跟蹤支架AT-Spark,為大型光伏電站提供一體化解決方案
訂單拆單合并處理接口設計與實現(xiàn)

NVIDIA DGX Spark桌面AI計算機開啟預訂

鴻蒙5開發(fā)寶藏案例分享---優(yōu)化應用包體積大小問題
HarmonyOS優(yōu)化應用文件上傳下載慢問題性能優(yōu)化二
HarmonyOS優(yōu)化應用文件上傳下載慢問題性能優(yōu)化二
NVIDIA加速的Apache Spark助力企業(yè)節(jié)省大量成本




 工商網監(jiān)
工商網監(jiān)
評論