 信息保留的二值神經網絡IR-Net,落地性能和實用性俱佳
信息保留的二值神經網絡IR-Net,落地性能和實用性俱佳

在CVPR 2020上,商湯研究院鏈接與編譯組和北京航空航天大學劉祥龍老師團隊提出了一種旨在優化前后向傳播中信息流的實用、高效的網絡二值化新算法IR-Net。不同于以往二值神經網絡大多關注量化誤差方面,本文首次從統一信息的角度研究了二值網絡的前向和后向傳播過程,為網絡二值化機制的研究提供了全新視角。同時,該工作首次在ARM設備上進行了先進二值化算法效率驗證,顯示了IR-Net部署時的優異性能和極高的實用性,有助于解決工業界關注的神經網絡二值化落地的核心問題。
動機
二值神經網絡因其存儲量小、推理效率高而受到社會的廣泛關注 [1]。然而與全精度的對應方法相比,現有的量化方法的精度仍然存在顯著的下降。
對神經網絡的研究表明,網絡的多樣性是模型達到高性能的關鍵[2],保持這種多樣性的關鍵是:(1) 網絡在前向傳播過程中能夠攜帶足夠的信息;(2) 反向傳播過程中,精確的梯度為網絡優化提供了正確的信息。二值神經網絡的性能下降主要是由二值化的有限表示能力和離散性造成的,這導致了前向和反向傳播的嚴重信息損失,模型的多樣性急劇下降。同時,在二值神經網絡的訓練過程中,離散二值化往往導致梯度不準確和優化方向錯誤。如何解決以上問題,得到更高精度的二值神經網絡?這一問題被研究者們廣泛關注,本文的動機在于:通過信息保留的思路,設計更高性能的二值神經網絡。
基于以上動機,本文首次從信息流的角度研究了網絡二值化,提出了一種新的信息保持網絡(IR-Net):(1)在前向傳播中引入了一種稱為Libra參數二值化(Libra-PB)的平衡標準化量化方法,最大化量化參數的信息熵和最小化量化誤差;(2) 在反向傳播中采用誤差衰減估計器(EDE)來計算梯度,保證訓練開始時的充分更新和訓練結束時的精確梯度。
IR-Net提供了一個全新的角度來理解二值神經網絡是如何運行的,并且具有很好的通用性,可以在標準的網絡訓練流程中進行優化。作者使用CIFAR-10和ImageNet數據集上的圖像分類任務來評估提出的IR-Net,同時借助開源二值化推理庫daBNN進行了部署效率驗證。
方法設計
高精度二值神經網絡訓練的瓶頸主要在于訓練過程中嚴重的信息損失。前向sign函數和后向梯度逼近所造成的信息損失嚴重影響了二值神經網絡的精度。為了解決以上問題,本文提出了一種新的信息保持網絡(IR-Net)模型,它保留了訓練過程中的信息,實現了二值化模型的高精度。
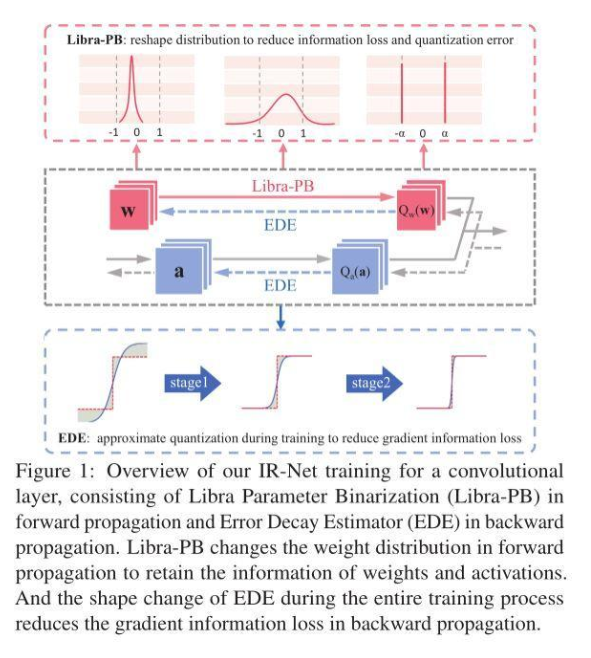
前向傳播中的Libra Parameter Binarization(Libra-PB)
在此之前,絕大多數網絡二值化方法試圖減小二值化操作的量化誤差。然而,僅通過最小化量化誤差來獲得一個良好的二值網絡是不夠的。因此,Libra-PB設計的關鍵在于:使用信息熵指標,最大化二值網絡前向傳播過程中的信息流。
根據信息熵的定義,在二值網絡中,二值參數Qx(x)的熵可以通過以下公式計算:
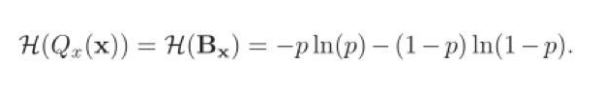
如果單純地追求量化誤差最小化,在極端情況下,量化參數的信息熵甚至可以接近于零。因此,Libra-PB將量化值的量化誤差和二值參數的信息熵同時作為優化目標,定義為:
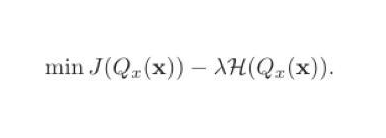
在伯努利分布假設下,當p=0.5時,量化值的信息熵取最大值。
因此,在Libra-PB通過標準化和平衡操作獲得標準化平衡權重,如圖2所示,在Bernoulli分布下,由Libra-PB量化的參數具有最大的信息熵。有趣的是,對權重的簡單變換也可以極大改善前向過程中激活的信息流。因為此時,各層的二值激活值信息熵同樣可以最大化,這意味著特征圖中信息可以被保留。
在以往的二值化方法中,為了使量化誤差減小,幾乎所有方法都會引入浮點尺度因子來從數值上逼近原始參數,這無疑將高昂的浮點運算引入其中。在Libra-PB中,為了進一步減小量化誤差,同時避免以往二值化方法中代價高昂的浮點運算,Libra-PB引入了整數移位標量s,擴展了二值權重的表示能力。
因此最終,針對正向傳播的Libra參數二值化可以表示如下:
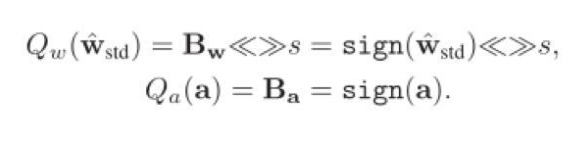
IR-Net的主要運算操作可以表示為:
反向傳播中的Error Decay Estimator(EDE)
由于二值化的不連續性,梯度的近似對于反向傳播是不可避免的,這種對sign函數的近似帶來了兩種梯度的信息損失,包括截斷范圍外參數更新能力下降造成的信息損失,和截斷范圍內近似誤差造成的信息損失。為了更好的保留反向傳播中由損失函數導出的信息,平衡各訓練階段對于梯度的要求,EDE引入了一種漸進的兩階段近似梯度方法。
第一階段:保留反向傳播算法的更新能力。將梯度估計函數的導數值保持在接近1的水平,然后逐步將截斷值從一個大的數字降到1。利用這一規則,近似函數從接近Identity函數演化到Clip函數,從而保證了訓練早期的更新能力。第二階段:使0附近的參數被更準確地更新。將截斷保持為1,并逐漸將導數曲線演變到階梯函數的形狀。利用這一規則,近似函數從Clip函數演變到sign函數,從而保證了前向和反向傳播的一致性。
各階段EDE的形狀變化如圖3(c)所示。通過該設計,EDE減小了前向二值化函數和后向近似函數之間的差異,同時所有參數都能得到合理的更新。

實驗結果
作者使用了兩個基準數據集:CIFAR-10和ImageNet(ILSVRC12)進行了實驗。在兩個數據集上的實驗結果表明,IR-Net比現有的最先進方法更具競爭力。
Deployment Efficiency
為了進一步驗證IR-Net在實際移動設備中的部署效率,作者在1.2GHz 64位四核ARM Cortex-A53的Raspberry Pi 3B上進一步實現了IR-Net,并在實際應用中測試了其真實速度。表5顯示,IR-Net的推理速度要快得多,模型尺寸也大大減小,而且IR-Net中的位移操作幾乎不會帶來額外的推理時間和存儲消耗。
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107753 -
算法
+關注
關注
23文章
4784瀏覽量
98042 -
數據集
+關注
關注
4文章
1236瀏覽量
26190
發布評論請先 登錄
神經網絡的初步認識

CNN卷積神經網絡設計原理及在MCU200T上仿真測試
NMSIS神經網絡庫使用介紹
構建CNN網絡模型并優化的一般化建議
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作
液態神經網絡(LNN):時間連續性與動態適應性的神經網絡
神經網絡的并行計算與加速技術
無刷電機小波神經網絡轉子位置檢測方法的研究
神經網絡專家系統在電機故障診斷中的應用
神經網絡RAS在異步電機轉速估計中的仿真研究
基于FPGA搭建神經網絡的步驟解析




 工商網監
工商網監
評論