TheVerge 報道,谷歌(微博)研發出一種訓練人工智能(AI)的新模式,可以直接在用戶的智能手機上訓練并改進AI算法。
2017-04-11 09:34:01 1049
1049 智慧監獄中的這些智慧元素包括智慧辦公系統、智慧改造系統(智慧安防系統、智慧教育矯正系統、陽光執法系統、基于大數據的幫教系統和獄務公開系統等)、智慧工廠系統(智慧生產系統、勞動技能培訓系統、智能勞動報酬系統等)。
2020-04-24 09:59:477101 電子發燒友網報道(文/周凱揚)作為補上機器學習算力空缺的另一大主力軍,這幾年間涌現的AI芯片初創公司們紛紛推出新品,力求以更快的速度填補這個窟窿。這也讓AI在飛速發展的5年內吸引到了不少投資,可令
2023-01-04 01:30:003861 電子發燒友網報道(文/黃晶晶)AI訓練數據集正高速增長,與之相適應的不僅是HBM的迭代升級,還有用于處理這些海量數據的服務器內存技術的不斷發展。 ? 以經過簡化的AI訓練管道流程來看,在數據采集進來
2024-07-04 09:09:294931 
我從在線平臺標注完并且下載了數據集,也按照ai cube的要求修改了文件夾名稱,但是導入提示
不知道是什么原因,我該怎么辦?
以下是我修改后的文件夾目錄
2025-08-11 08:12:12
AI Cube進行yolov8n模型訓練 創建項目目標檢測時顯示數據集目錄下存在除標注和圖片外的其他目錄怎么解決
2025-02-08 06:21:58
機器學習芯片市場規模約24億美元,預計到2025年這一市場規模將達到約378億美元,復合年增長率(CAGR)為40.8%。高速增長且短期內規模將達百億美元的AI芯片市場不僅驅動著傳統芯片公司戰略和技術
2019-09-16 10:36:35
算法的兼顧,英偉達不僅能用GPU滿足AI構建的訓練需求,還能用TeslaRT用來部署,很好實現AI構建,所以英偉達也率先成了這一波AI熱潮的最大受益者。給機器人“造腦”,英偉達發布全新AI芯片
2018-06-11 08:20:23
AiM Future是LG電子的衍生公司,正在將韓國消費巨頭的AI加速IP商業化,用于消費電子,機器人和汽車等各種應用。該 IP 專為多模式操作而設計,可同時運行許多不同的 AI 模型。當前一代硬件
2023-02-23 15:08:57
初創公司值得加入嗎?
2016-01-18 09:41:49
當下AI火熱高科技板塊,語音識別等技術論壇及產品,概念一個接一個發布,在大公司開放相關AI技術以后,初創公司怎樣生存?云端的估計沒戲了,離線市場呢,怎樣去尋找市場的嵌入點,目前我們已經有單嘜的遠場
2017-07-17 12:59:45
作者:LauroRizzattiVSORA是一家法國巴黎的DSP設計工具公司,推出了一種高效5G寬帶新型設計架構,迅速從5G和AI的芯片開發中脫穎而出。近日,創始人兼首席執行官
2019-06-18 06:37:30
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-25 15:02:15
訓練好的ai模型導入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
2023-08-04 09:16:28
海思SD3403邊緣計算AI框架,提供了一套開放式AI訓練產品工具包,解決客戶低成本AI系統,針對差異化AI
應用場景,自己采集樣本數據,進行AI特征標定,AI模型訓練,AI應用部署的系統,用戶
2025-04-28 11:05:43
從零開始使用Detectron訓練第三方數據集是什么體驗(六)
2020-04-14 11:44:48
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-23 14:38:58
了。
安裝后有會有兩個程序:
AI Builder : 訓練算法用的。
圖片標注工具:標注訓練數據用的。
有一點要注意,如果自己的電腦安裝有英偉達芯片的顯卡就勾選CUDA,其他芯片的顯卡
2023-05-11 16:09:57
。mnist.train.images 的每項都是一個范圍介于 0 到 1 的像素強度: 在 TensorFlow 圖中為訓練數據集的輸入 x 和標簽 y 創建占位符: 創建學習變量、權重和偏置: 創建邏輯回歸模型
2020-08-11 19:36:01
。mnist.train.images 的每項都是一個范圍介于 0 到 1 的像素強度: 在 TensorFlow 圖中為訓練數據集的輸入 x 和標簽 y 創建占位符: 創建學習變量、權重和偏置: 創建邏輯回歸模型
2020-08-11 19:36:31
智慧化進程。人工智能芯片是人工智能發展的基石,是數據、算法和算力在各類場景應用落地的基礎依托。“無芯片不AI”已經深入人心,成為業界共識。本次直播將述說AI芯片設計帶你解析AI算法及其芯片操作系統
2019-11-07 14:03:20
發帖,然后把帖子鏈接放在在評論中;
不得抄襲、不得使用AI生成,一經發現取消活動資格;
優質回復舉例:
可以分享你最近一次引以為傲的勞動成果:【開源項目分享:用ESP32復刻了復古模擬器游戲機
2025-04-28 16:53:06
用于訓練模型,如下圖所示:我選擇的方式為上傳本地圖片的方式,選項選擇如下:上傳圖片后,我們需要對圖片進行標記,操作則需要點擊下圖所示的 查看與標注第四步:在創建數據集完成后,就是模型訓練,我們進入模型
2021-03-23 14:32:35
ID數據把數據集分為若干個部分,ground-truth標簽就是在每個group中進行重新映射。在組中c 不包括在內,其他類將被定義為真實類。訓練過程中的優化目標,自然就是交叉熵損失的每組的總和:其實
2022-08-31 15:11:09
學習機器學習是AI的核心驅動力。 簡單的說就是用算法來發現數據的有趣內容的過程,而無需編寫解決特定問題的代碼。 換句話說,這是一種用最少的編程方式讓計算機從數據中學習。 取代編寫代碼,你只需提供給機器
2017-09-25 10:03:05
起因是現在平臺限制了圖片數量,想要本地訓練下載數據集時發現只會跳出網絡異常的錯誤,請問這有什么解決辦法?
2025-07-22 06:03:52
目錄人工智能基本概念機器學習算法1. 決策樹2. KNN3. KMEANS4. SVM5. 線性回歸深度學習算法1. BP2. GANs3. CNN4. LSTM應用人工智能基本概念數據集:訓練集
2021-09-06 08:21:17
誕生的各種智能科技及項目,將會替代傳統勞動力,從而衍生出新的經濟增長點。根據相關數據顯示,現在在全球各個發達國家當中,利用人工智能科技來替代傳統勞動力的頻率越來越高,而且在人臉識別算法介入某些工作環節
2018-12-27 11:07:45
處理,TensorFlow、PyTorch用于構建和訓練神經網絡。以Python為例,通過編寫簡單的程序來處理數據,如讀取數據集、進行數據清洗和預處理,這是進入AI領域的基本技能。
學習機器學習和深度學習
2025-07-08 17:44:15
(三)使用YOLOv3訓練BDD100K數據集之開始訓練
2020-05-12 13:38:55
、智慧AI商業解決方案公司自有算法接入,提供硬件定制以及軟件二次開發Demo幫助客戶自有算法場景落地。目前,量產的IPC產品已在國內外的家居監控及大型購物商場中投入使用。(20年的傳統安防制造經驗讓您量產無憂)
2023-06-28 16:51:06
的工作強度,在遇到突發事件時能夠迅速定位執勤干警的所在位置。泛聯智能監獄管理系統還可以與人臉識別系統、智能門禁系統、視頻監控系統結合使用,可以為監獄對罪犯的各項管理工作展開提供便捷、高效的現代化手段。2
2011-07-21 09:05:20
、PyTorch和MXNet框架中常用的開源深度學習模型。這些模型在公共數據集上經過預訓練和優化,可以在TI適用于邊緣AI的處理器上高效運行。TI會定期使用開源社區中的新模型以及TI設計的模型對Model Zoo
2022-11-03 06:53:28
,如果醫生和患者都能了解AI推薦治療方案的原因,將大大增加對技術的接受度和信任。
算法公平性的保障同樣不可或缺。AI系統在設計時就需要考慮到多樣性和包容性,避免因為訓練數據的偏差而導致結果的不公平
2024-07-16 15:07:34
? 被選擇作為開發集和測試集的數據,應當與你未來計劃獲取并對其進行良好處理的數據有著相同的分布,而不一定和訓練集的數據分布一致。? 開發集和測試集的分布應當盡可能一致。? 為你的團隊選擇一個單值評估
2018-12-14 10:56:57
一旦被訓練完成,線上推理的效率才決定用戶體驗。比如,有2個同樣AI模型的訓練,一家公司用了1天訓練完成,但線上推理的效率只有每秒100個任務;另一家公司用了7天訓練完成,但線上推理效率可以達到每秒
2021-09-17 17:08:32
使用AI解決問題提供了第1次經驗,但它導致了分散的跨組織的ML算法。不幸的是,這種分散的ML算法不能完全釋放數據中隱藏的價值,也不能充分利用組織所擁有的寶貴業務知識。此外,它們還會給公司帶來潛在風險。分散
2019-05-06 16:46:05
,也沒有警示可能存在偏見的警告標簽,他們提出做一張包含有公共數據集和商用軟件的數據表。文檔將明確說明訓練數據集是什么時候在哪里以及如何匯編出來的,并且提供使用的受試者的人口統計信息,提供必要的信息給
2018-06-02 12:51:50
的團隊正在研發一款機器學習相關應用,并期待取得較快進展,那么這本書將會是你的得力助手。案例:建立貓咪圖片初創公司想象一下,你正在建立一家初創公司,這家公司的產品目標是為貓咪愛好者們提供數不盡的貓咪圖片
2018-11-30 16:45:03
`轉一篇好資料機器學習算法可以分為三大類:監督學習、無監督學習和強化學習。監督學習可用于一個特定的數據集(訓練集)具有某一屬性(標簽),但是其他數據沒有標簽或者需要預測標簽的情況。無監督學習可用
2017-04-18 18:28:36
AI數據訓練:基于用戶特定應用場景,用戶采集照片或視頻,通過AI數據訓練工程師**(用戶公司****員工)** ,進行特征標定后,將標定好的訓練樣本,通過AI訓練服務器,進行AI學習訓練獲得訓練
2025-04-28 11:11:47
一些準確的反饋數據來為后續的行動提供依據。但你仍然能夠嘗試去模擬出這種情況,例如邀請你的朋友用手機拍下照片并發送給你。當你的 app 上線后,就能夠使用實際的用戶數據對開發集和測試集進行更新。如果你
2018-11-30 16:58:52
用于計算機視覺訓練的圖像數據集
2021-02-26 07:35:08
`深度學習領域的“Hello World!”,入門必備!MNIST是一個手寫數字數據庫,它有60000個訓練樣本集和10000個測試樣本集,每個樣本圖像的寬高為28*28。此數據集是以二進制存儲
2018-08-29 10:36:45
近幾年大數據的發展為算法的訓練和演進提供了足夠的場景和數據,使其智能化水平大增。以前,如果一個客戶失聯一段時間,企業很可能會把他標記為流失風險客戶,而給予某種促銷激勵。而有了機器學習算法,企業可以
2018-04-10 10:48:40
和大量的數據為基礎,這也是為什么很多科技巨頭宣布自己是數據驅動的公司,同時很多行業在不斷推動將業務數據化。數據化之后,借力AI,就能讓數據產生巨大的價值。有了數據之后,還要有高效的算法和匹配的模型,這是
2018-08-23 17:39:35
徘徊、出現晚間起身、出現異常激烈運動、出現異常集聚等行為現象進行即時分析、提示預警提醒和抓拍留檔。監獄視頻行為分析監控系統為為現代化監獄的安防監控提供了一種智慧的
2024-07-24 23:04:51
儀表圖像識別算法基于AI的機器視覺分析識別技術,通過訓練深度學習模型,使得攝像頭能夠像人一樣“看”懂儀表盤上的數據。這些現場監控攝像頭能夠實時捕捉儀表盤的圖像,利用AI算法自動分析并識別出儀表的示數
2024-09-19 00:22:56
近日,據內部人士稱,亞馬遜的 AWS 部門已經悄悄地以 1900 萬美元的價格收購了人工智能初創公司 harvest.ai,亞馬遜并沒有公開透露收購的消息。考慮到 harvest.ai 種子輪融資只籌集了230萬美元,這還算是一筆不錯的交易。
2017-01-11 10:53:13521 針對高光譜遙感影像分類中,傳統的主動學習算法僅利用已標簽數據訓練樣本,大量未標簽數據被忽視的問題,提出一種結合未標簽信息的主動學習算法。首先,通過K近鄰一致性原則、前后預測一致性原則和主動學習算法
2017-12-01 16:19:52 0
0 ,建立仿真模型分析BR算法的不足,考慮到標簽的取值應由屬性置信度和標簽置信度共同決定,提出MLBM。其中,通過傳統的分類算法計算獲得屬性置信度,以及通過訓練集得到標簽置信度。然后,考慮到MLBM在計算屬性置信度時必須考慮所有已分類的標簽
2017-12-25 13:50:051 語義主題,從語義層面計算用戶對各資源的偏好概率,將計算出的偏好概率與協同過濾算法計算出的資源相似度相結合,預測用戶偏好值,實現個性化推薦。在Movielens數據集上的實驗結果表明,與傳統基于標簽的推薦算法相比,該算法能消除標簽
2018-03-07 13:58:030 在國家的扶持下,中國AI項目進展順利,并且收集到了全球上最大的共享數據集。訪問這些驚人的數據集可以立即增強任何AI公司訓練神經網絡的能力。但這些全球最富有的科技公司不僅僅是因為中國的龐大數據集才被吸引過來。
2018-09-25 09:34:124295 部件,該芯片用于云數據中心。 Enflame科技是一家設在中國的初創公司,已經從騰訊控股獲得A系列前期投資。目前正在開發一種AI訓練系統級芯片(SoC),其中使用人工神經網絡。這些芯片使用多個硬件加速器來提高神經網絡訓練的速度和精度,同時降低數據中心的功耗。 Enflame科技之所以選擇Arteris
2018-10-12 22:04:011036 針對多標簽分類算法不能充分利用標簽相關性的問題,通過建立標簽的正、負相關性矩陣來挖掘標簽間不同的相關關系,提出一種基于引力模型的多標簽分類算法( MLBGM)。首先,遍歷訓練集中所有樣本并分別求取
2018-12-07 11:53:262 ,實現對海量、復雜、異構大數據的高效處理與智能挖掘服務:提供大數據增值服務。利用智慧監獄平臺收集的海量罪犯的各項數據,為企業提供BI、總裁視圖、預警分析、行為統計等增值服務。智慧監獄平臺面向監獄單位,為
2019-03-29 10:53:311170 據報道,“獄中勞役”通常與體力活動相關,但是芬蘭兩所監獄內的服刑人員卻在嘗試一種新型勞役:歸類數據,從而訓練一家初創企業的人工智能算法。
2019-04-17 09:24:423272 AI人才需求的不斷增長, 為科研人員在學術機構和商業公司間跨界工作創造機會。越來越多的人工智能研究員決定從科研機構跳槽到商業公司,吸引他們的不僅是高薪,還有科研機構所不具備的大型數據集和計算資源。
2019-05-20 11:50:303006 為了更好地降低監獄勞動工具被犯人用于非法用途的風險,監獄打算使用RFID技術對監獄勞動工具進行信息化的管理。
2019-11-11 16:34:451539 微軟已開始向云計算平臺MicrosoftAzure的客戶提供英國初創公司Graphcore開發的AI芯片的訪問權限。通過從頭開始為AI創建的專用芯片,AI應用程序可以實現巨大的飛躍。
2019-11-24 10:12:501153 蘋果悄悄收購了英國AI初創公司Spectral Edge。Spectral Edge是大學里的一個分支機構,專門研究AI技術,可以改善在朦朧的日子里拍攝的照片。
2019-12-31 17:36:533344 對于人類和機器而言,至關重要的原則是避免偏見并因此防止歧視。AI系統中的偏差主要發生在數據或算法模型中。在開發我們可以信賴的AI系統的過程中,至關重要的是使用無偏數據開發和訓練這些系統,并開發易于解釋的算法。
2020-04-11 09:57:202538 Companion Labs是一家位于舊金山的初創公司,其開發了一款名為Companion Pro的新型機器人AI寵物訓練器,目前還處于早期階段。
2020-04-17 10:53:111459 狗的訓練通常情況下都需要人的參與,但如果沒有人的參與會帶來更好的結果嗎?在舊金山動物保護組織 SPCA 的合作下, 名為 Companion Labs 的初創公司近日推出了首款用于訓練狗的AI 訓練機--CompanionPro。
2020-11-26 11:50:391932 K近鄰的分類性能依賴于訓練集的質量。設計高效的訓練集優化算法具有重要意義。針對傳統的進仳訓練集優化算法效率較低、誤刪率較高的不足,提岀了一種遺傳訓練集優化算法。該算法采用基于最大漢明距離的高效
2021-05-13 14:20:166 華為云初創扶持計劃“微光訓練營”濟南專場將為參加的初創企業提供五大支持權益:
2021-12-07 11:08:042676 導讀:【新聞】特斯拉發布自研了AI訓練芯片Dojo D1,初創公司ThirdAI發力CPU軟硬件聯合優化,BERT訓練從3天到76分鐘的作者回國創業打造...
2022-01-25 16:01:370 初創公司 CEO 將 “以數據為中心的 AI” 理念融入到 Landing AI 產品中,并通過 NVIDIA GPU 加速,得到了客戶的青睞。
2022-06-15 10:14:521601 在過去的幾年里,人工智能/機器學習算法取得了突破性的進展和非常迅速的進展。許多努力都集中在將 AI/ML 模型(這些模型在其他地方訓練過)應用于嵌入式上下文。換句話說,要成功部署 AI/ML 模型,需要優化內存/CPU 使用率和算法的功耗。
2022-07-10 09:07:241026 隨著新型 AI 技術的快速發展,模型訓練數據集的相關文檔質量有所下降。模型內部到底有什么秘密?它們又是如何組建的?本文綜合整理并分析了現代大型語言模型的訓練數據集。
2023-02-21 10:06:232610 該向孩子展示這種生物的圖像并描述其獨有特征。 那么,如果要教一臺人工智能(AI)機器什么是獨角獸,該從什么地方做起呢? 預訓練 AI 模型提供了解決方案。 預訓練 AI 模型是一種為了完成某項特定任務而在大型數據集上進行訓練的深度學
2023-04-04 01:45:022355 手勢識別數據集是指用于測試、訓練和開發手勢識別算法的數據集。隨著手勢識別技術的不斷發展,越來越多的企業和研究機構需要大量的手勢識別數據集來訓練和評估他們的算法。然而,由于手勢數據集的收集、標注和維護
2023-04-14 17:31:331947 作為人工智能領域的基礎,訓練數據集對于模型的訓練和優化至關重要。在過去的幾十年中,隨著計算機技術和硬件性能的不斷提升,人工智能技術得到了快速的發展,但是訓練數據集作為基礎部分,卻一直是制約其發展
2023-04-26 17:27:212313 ? ? ? ?在想要訓練一個能區分蘋果和香蕉的模型,你需要搜索一些蘋果和香蕉的圖片,將這些圖片放在一起構成訓練數據集(Training Dataset),訓練數據集是有標簽的,蘋果圖片的標簽是蘋果
2023-05-16 09:46:343025 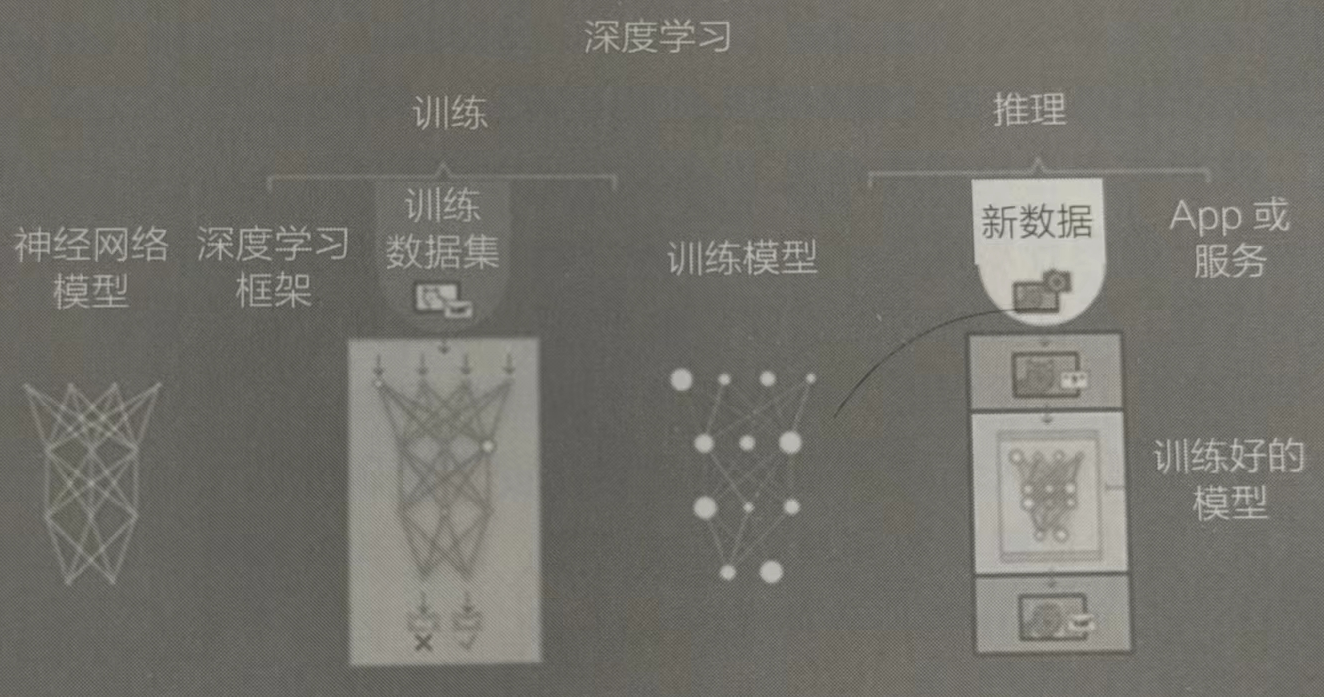
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。
2023-05-25 17:10:091816 電子發燒友網站提供《PyTorch教程15.9之預訓練BERT的數據集.pdf》資料免費下載
2023-06-05 11:06:260 15.9。預訓練 BERT 的數據集? Colab [火炬]在 Colab 中打開筆記本 Colab [mxnet] Open the notebook in Colab Colab
2023-06-05 15:44:401461 打標簽 像其他版本控制系統(VCS)一樣,Git 可以給倉庫歷史中的某一個提交打上簽,以示重要。比較有代表性的是人們會使用這個功能來標記發布結點( v1.0 、 v2.0 等等)。 如何列出已有
2023-07-22 11:36:441350 和初創公司在 Microsoft Azure 上開發、調優和部署其自定義生成式 AI 應用。 ? 這項 NVIDIA AI foundry 服務整合了 NVIDIA AI Foundation
2023-11-16 14:13:08859 
的發展趨勢。 二、語音數據集的重要性 提高語音識別和生成能力:語音數據集包含大量的語音樣本,可以為模型提供充足的訓練數據,從而提高語音識別和生成的能力。通過對語音數據集的深入學習和分析,AI模型可以更好地理解和模擬
2023-12-12 11:32:031336 提升語音識別和生成能力:語音數據集為AI模型提供了豐富的語音樣本,通過訓練和學習這些數據,AI可以更好地理解和模擬人類的語音特征,從而提高語音識別的準確性和語音生成的自然度。 促進多模態交互:語音數據集可以與其他模態
2023-12-14 14:33:511753 微軟近日與法國人工智能初創企業Mistral達成合作協議,旨在推動AI模型的商業化應用。據悉,微軟將提供全方位支持,幫助這家成立僅10個月的公司將其先進的AI模型推向市場。同時,微軟還將持有Mistral的少量股份,但具體的財務細節尚未對外披露。
2024-02-28 10:23:511071 英偉達擅用版權作品遭起訴 AI訓練數據和版權的矛盾凸顯 據外媒路透社的報道,AI訓練數據和版權之間的矛盾日益凸顯。英偉達因為擅用版權作品訓練其NeMo人工智能平臺而遭作者起訴。 有三位作家已發起
2024-03-11 14:17:271018 K折交叉驗證算法與訓練集
2024-05-15 09:26:011521 PyTorch是一個廣泛使用的深度學習框架,它以其靈活性、易用性和強大的動態圖特性而聞名。在訓練深度學習模型時,數據集是不可或缺的組成部分。然而,很多時候,我們可能需要使用自己的數據集而不是現成
2024-07-02 14:09:414636 在本文中,我們將介紹如何在PyCharm中訓練數據集。PyCharm是一款流行的Python集成開發環境,提供了許多用于數據科學和機器學習的工具。 1. 安裝PyCharm和相關庫 首先,確保你已經
2024-07-11 10:10:051816 和訓練AI大模型之前,需要明確自己的具體需求,比如是進行自然語言處理、圖像識別、推薦系統還是其他任務。 二、數據收集與預處理 數據收集 根據任務需求,收集并準備好足夠的數據集。 可以選擇公開數據集、自有數據集或者通過數據標
2024-10-23 15:07:576916 AI大模型的訓練數據來源廣泛且多元化,這些數據源對于構建和優化AI模型至關重要。以下是對AI大模型訓練數據來源的分析: 一、公開數據集 公開數據集是AI大模型訓練數據的重要來源之一。這些數據集通常由
2024-10-23 15:32:106729 NVIDIA AI 助力初創企業為心理治療師提供 AI 工具,以此來優化和提升心理健康服務水平,為人們的心理健康保駕護航。
2024-11-19 16:03:39927 :ai作為一家專注于AI云計算軟件平臺開發的初創公司,其產品以高效利用高性能GPU資源為核心,致力于為用戶提供更快速、更便捷的機器學習加速方案。通過此次收購,英偉達將Run:ai的先進技術融入自身產品線,進一步鞏固了其在AI市場的領先地位。
2024-12-31 10:46:51930 近年來,人工智能(AI)與印刷電路板(PCB)設計的結合催生了多家初創公司,致力于通過AI技術提升PCB設計的效率和質量。以下是一些值得關注的AI+PCB初創公司:FluxFlux是一款基于瀏覽器
2025-02-08 15:09:184492 進行多方位的總結和梳理。 在第二章《TOP 101-2024 大模型觀點》中,蘇州盛派網絡科技有限公司創始人兼首席架構師蘇震巍分析了大模型訓練過程中開源數據集和算法的重要性和影響,分析其在促進 AI 研究和應用中的機遇,并警示相關的風險與挑戰。 全文如下: 大模型訓練中的開源
2025-02-20 10:40:521095 
AI 正在幫助人類更快、更有效地識別和治療疾病。接下來,AI 還將幫助人類預防像野火這樣的自然災害。
2025-05-29 14:18:19909 多少數據,才能形成合適的樣本集,進而開始訓練模型呢? 此時,回答“按需提供”或者“先試試看”似乎會變成一句車轱轆話,看似回答了問題,但客戶還是無從下手。 AI數據樣本的三個原則 這里,我以教孩子認識蘋果和鴨梨為例進行說明。假設
2025-06-11 16:30:051184 算法作為軟實力,其水平直接影響著目標檢測識別的能力。兩年前,慧視光電推出了零基礎的基于yolo系列算法架構的AI算法開發平臺SpeedDP,此平臺能夠通過數據驅動模型訓練,實現算法從0到1的開發訓練
2025-09-09 17:57:111289 
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論