 電子發(fā)燒友App
電子發(fā)燒友App



由CNN驅(qū)動的深度學(xué)習(xí)模型現(xiàn)在無處不在,你會發(fā)現(xiàn)它們已散布到全球的各種計算機(jī)視覺應(yīng)用程序中。就像XGBoost和其他流行的機(jī)器學(xué)習(xí)算法一樣,卷積神經(jīng)網(wǎng)絡(luò)通過黑客馬拉松(2012年ImageNet競賽)進(jìn)入了公眾的意識。
從那時起,這些神經(jīng)網(wǎng)絡(luò)就如火一樣吸引了靈感,并擴(kuò)展到各個研究領(lǐng)域。以下是一些使用CNN的流行計算機(jī)視覺應(yīng)用程序:
面部識別系統(tǒng)
通過文檔分析和解析
智慧城市(例如交通攝像頭)
推薦系統(tǒng),以及其他用例
但是,為什么卷積神經(jīng)網(wǎng)絡(luò)能很好地工作呢?與傳統(tǒng)的人工神經(jīng)網(wǎng)絡(luò)相比,它的性能如何?為何深度學(xué)習(xí)專家喜歡它?
要回答這些問題,我們必須了解CNN實(shí)際上是如何運(yùn)作的。在本文中,我們將研究CNN模型背后的數(shù)學(xué)原理。
神經(jīng)網(wǎng)絡(luò)導(dǎo)論
神經(jīng)網(wǎng)絡(luò)是所有深度學(xué)習(xí)算法的核心。但是,在深入研究這些算法之前,對神經(jīng)網(wǎng)絡(luò)的概念有一個很好的了解是很重要的。
這些神經(jīng)網(wǎng)絡(luò)試圖模仿人腦及其學(xué)習(xí)過程。就像大腦接受輸入,對其進(jìn)行處理并生成一些輸出一樣,神經(jīng)網(wǎng)絡(luò)也是如此。
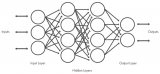
這三個動作- 接收輸入,處理信息,生成輸出 -在神經(jīng)網(wǎng)絡(luò)中以層的形式表示-輸入,隱藏和輸出。以下是神經(jīng)網(wǎng)絡(luò)的骨架:
這些層中的各個單元稱為神經(jīng)元。神經(jīng)網(wǎng)絡(luò)的完整訓(xùn)練過程包括兩個步驟。
1.正向傳播
圖像以數(shù)字形式輸入到輸入層。這些數(shù)值表示圖像中像素的強(qiáng)度。隱藏層中的神經(jīng)元對這些值應(yīng)用了一些數(shù)學(xué)運(yùn)算(我們將在本文稍后討論)。
為了執(zhí)行這些數(shù)學(xué)運(yùn)算,需要隨機(jī)初始化某些參數(shù)值。將這些數(shù)學(xué)運(yùn)算發(fā)布到隱藏層后,結(jié)果將發(fā)送到生成最終預(yù)測的輸出層。
2.向后傳播
生成輸出后,下一步就是將輸出與實(shí)際值進(jìn)行比較。根據(jù)最終輸出以及該值與實(shí)際值(錯誤)的接近或相距遠(yuǎn)近,將更新參數(shù)的值。使用更新的參數(shù)值重復(fù)進(jìn)行前向傳播過程,并生成新的輸出。
這是任何神經(jīng)網(wǎng)絡(luò)算法的基礎(chǔ)。在本文中,我們將研究卷積神經(jīng)網(wǎng)絡(luò)的向前和向后傳播步驟!
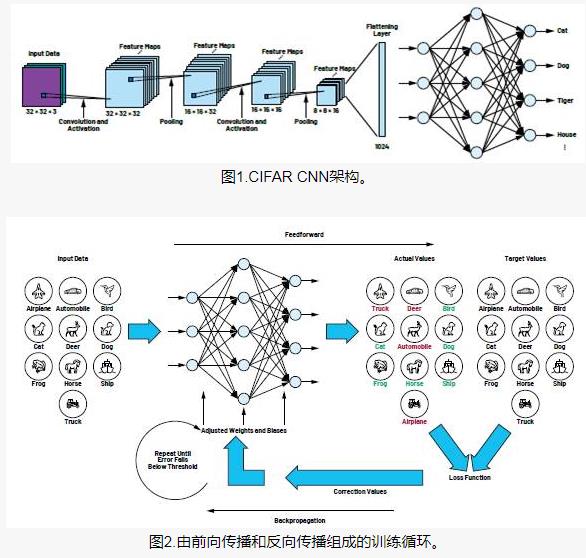
卷積神經(jīng)網(wǎng)絡(luò)(CNN)架構(gòu)
考慮一下–您需要在兩個給定的圖像中識別對象。您將如何去做?通常,您將觀察圖像,嘗試從圖像中識別出不同的特征,形狀和邊緣。根據(jù)收集到的信息,您可以說該物體是狗或汽車等。
這正是CNN中的隱藏層所做的–查找圖像中的特征。卷積神經(jīng)網(wǎng)絡(luò)可以分為兩部分:
卷積層:從輸入中提取特征
完全連接的(密集)層:使用卷積層中的數(shù)據(jù)生成輸出
正如我們在上一節(jié)中討論的那樣,任何神經(jīng)網(wǎng)絡(luò)的訓(xùn)練都涉及兩個重要過程:
正向傳播:接收輸入數(shù)據(jù),處理信息并生成輸出
向后傳播:計算誤差并更新網(wǎng)絡(luò)參數(shù)
我們將一一介紹這兩個方面。讓我們從正向傳播過程開始。
卷積神經(jīng)網(wǎng)絡(luò)(CNN):正向傳播
卷積層
您知道我們?nèi)绾慰创龍D像并識別物體的形狀和邊緣嗎?卷積神經(jīng)網(wǎng)絡(luò)通過比較像素值來做到這一點(diǎn)。
下面是數(shù)字8的圖像以及該圖像的像素值。仔細(xì)看看圖像。您會注意到,數(shù)字邊緣周圍的像素值之間存在顯著差異。因此,識別邊緣的簡單方法是比較相鄰像素值。
卷積通常在數(shù)學(xué)上用星號*表示。如果我們有一個表示為X的輸入圖像和一個表示為f的濾鏡,則表達(dá)式為:
Z = X * f
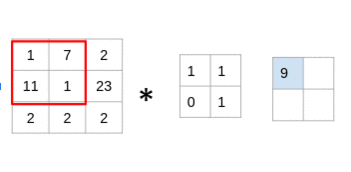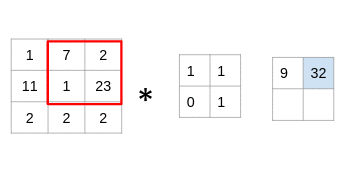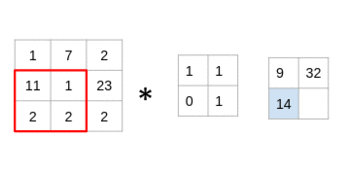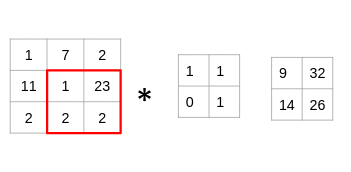
讓我們用一個簡單的例子來理解卷積的過程。考慮我們有一個尺寸為3 x 3的圖像和一個尺寸為2 x 2的濾鏡:
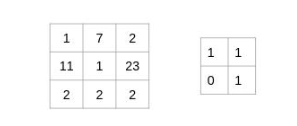
過濾器遍歷圖像塊,執(zhí)行逐元素乘法,然后將值相加:
(1x1 + 7x1 + 11x0 + 1x1)= 9
(7x1 + 2x1 + 1x0 + 23x1)= 32
(11x1 + 1x1 + 2x0 + 2x1)= 14
(1x1 + 23x1 + 2x0 + 2x1)= 26
仔細(xì)看看,您會發(fā)現(xiàn)濾鏡一次只考慮一小部分圖像。我們還可以將其想象成分解為較小補(bǔ)丁的單個圖像,每個補(bǔ)丁都與濾鏡卷積。

在上面的示例中,我們有一個形狀為(3,3)的輸入和一個形狀為(2,2)的過濾器。由于圖像和濾鏡的尺寸很小,因此很容易解釋輸出矩陣的形狀為(2,2)。但是,如何為更復(fù)雜的輸入或過濾器尺寸找到輸出的形狀?有一個簡單的公式可以做到這一點(diǎn):
圖片尺寸=(n,n)
過濾器尺寸=(f,f)
輸出的尺寸為((n-f + 1),(n-f + 1))











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論