") 深度學(xué)習(xí)在人臉檢測中的應(yīng)用
深度學(xué)習(xí)在人臉檢測中的應(yīng)用

在目標(biāo)檢測領(lǐng)域,可以劃分為人臉檢測與通用目標(biāo)檢測,往往人臉這方面會有專門的算法(包括人臉檢測、人臉識別、人臉其他屬性的識別等),并且和通用目標(biāo)檢測(識別)會有一定的差別。這主要來源于人臉的特殊性(譬如有時候目標(biāo)比較小、人臉之間特征不明顯、遮擋問題等),本文將主要從人臉檢測方面來講解目標(biāo)檢測。
目前主要的人臉檢測方法分類
當(dāng)前,人臉檢測方法主要包含兩個區(qū)域:傳統(tǒng)人臉檢測算法和基于深度學(xué)習(xí)的人臉檢測算法。傳統(tǒng)人臉檢測算法主要可以分為 4 類:
基于知識的人臉檢測方法;
基于模型的人臉檢測方法;
基于特征的人臉檢測方法;
基于外觀的人臉檢測方法。
2006 年,Hinton 首次提出深度學(xué)習(xí)(Deep Learning)的概念,它是通過組合低層的特征形成更高層的抽象特征。隨后研究者將深度學(xué)習(xí)應(yīng)用在人臉檢測領(lǐng)域,主要集中在基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的人臉檢測研究,如基于級聯(lián)卷積神經(jīng)網(wǎng)絡(luò)的人臉檢測(Cascade CNN)、基于多任務(wù)卷積神經(jīng)網(wǎng)絡(luò)的人臉檢測(MTCNN)、Facebox 等,很大程度上提高了人臉檢測的魯棒性。
當(dāng)然,像Faster RCNN、YOLO、SSD等通用目標(biāo)檢測算法也有用在人臉檢測領(lǐng)域,也可以實(shí)現(xiàn)比較不錯的結(jié)果,但是和專門人臉檢測算法比還是有差別。
如何檢測圖片中不同大小的人臉?
傳統(tǒng)人臉檢測算法中針對不同大小人臉主要有兩個策略:
縮放圖片的大小(圖像金字塔如圖 1 所示);
圖1 圖像金字塔
縮放滑動窗的大小(如圖 2 所示)。
圖 2 縮放滑動窗口
基于深度學(xué)習(xí)的人臉檢測算法中,針對不同大小人臉主要也有兩個策略,但和傳統(tǒng)人臉檢測算法有點(diǎn)區(qū)別,主要包括:
縮放圖片大小:不過也可以通過縮放滑動窗的方式,基于深度學(xué)習(xí)的滑動窗人臉檢測方式效率會很慢存在多次重復(fù)卷積,所以要采用全卷積神經(jīng)網(wǎng)絡(luò)(FCN),用 FCN 將不能用滑動窗的方法。
通過 anchor box 的方法:如圖 3 所示,不要和圖 2 混淆,這里是通過特征圖預(yù)測原圖的 anchorbox 區(qū)域,具體在 Facebox 中有描述。
圖 3 anchor box
如何設(shè)定算法檢測最小人臉尺寸?
主要是看滑動窗的最小窗口和 anchorbox 的最小窗口。
滑動窗的方法
假設(shè)通過 12×12 的滑動窗,不對原圖做縮放的話,就可以檢測原圖中 12×12 的最小人臉。
但是往往通常給定最小人臉 a=40、或者 a=80,以這么大的輸入訓(xùn)練 CNN 進(jìn)行人臉檢測不太現(xiàn)實(shí),速度會很慢,并且下一次需求最小人臉 a=30*30 又要去重新訓(xùn)練,通常還會是 12×12 的輸入,為滿足最小人臉框 a,只需要在檢測的時候?qū)υ瓐D進(jìn)行縮放即可:w=w×12/a。
anchorbox 的方法
原理類似,這里主要看 anchorbox 的最小 box,通過可以通過縮放輸入圖片實(shí)現(xiàn)最小人臉的設(shè)定。
如何定位人臉的位置
滑動窗的方式:
滑動窗的方式是基于分類器識別為人臉的框的位置確定最終的人臉。
圖 4 滑動窗
FCN 的方式:
通過特征圖映射到原圖的方式確定最終識別為人臉的位置,特征圖映射到原圖人臉框是要看特征圖相比較于原圖有多少次縮放(縮放主要查看卷積的步長和池化層)。
假設(shè)特征圖上(2,3)的點(diǎn),可粗略計(jì)算縮放比例為 8 倍,原圖中的點(diǎn)應(yīng)該是(16,24);如果訓(xùn)練的 FCN 為 12*12 的輸入,對于原圖框位置應(yīng)該是(16,24,12,12)。
當(dāng)然這只是估計(jì)位置,具體的在構(gòu)建網(wǎng)絡(luò)時要加入回歸框的預(yù)測,主要是相對于原圖框的一個平移與縮放。
通過 anchor box 的方式:
通過特征圖映射到圖的窗口,通過特征圖映射到原圖到多個框的方式確定最終識別為人臉的位置。
如何通過一個人臉的多個框確定最終人臉框位置?
圖 5 通過 NMS 得到最終的人臉位置
NMS 改進(jìn)版本有很多,最原始的 NMS 就是判斷兩個框的交集。如果交集大于設(shè)定的閾值,將刪除其中一個框。
那么兩個框應(yīng)該怎么選擇刪除哪一個呢?因?yàn)槟P洼敵鲇懈怕手担话銜?yōu)選選擇概率小的框刪除。
基于級聯(lián)卷積神經(jīng)網(wǎng)絡(luò)的人臉檢測(Cascade CNN)
Cascade CNN 的框架結(jié)構(gòu)是什么?

級聯(lián)結(jié)構(gòu)中有 6 個 CNN,3 個 CNN 用于人臉非人臉二分類,另外 3 個 CNN 用于人臉區(qū)域的邊框校正。
給定一幅圖像,12-net 密集掃描整幅圖片,拒絕 90% 以上的窗口。剩余的窗口輸入到 12-calibration-net 中調(diào)整大小和位置,以接近真實(shí)目標(biāo)。接著輸入到 NMS 中,消除高度重疊窗口。下面網(wǎng)絡(luò)與上面類似。
Cascade CNN 人臉校驗(yàn)?zāi)K原理是什么?
該網(wǎng)絡(luò)用于窗口校正,使用三個偏移變量:
Xn:水平平移量,Yn:垂直平移量,Sn:寬高比縮放。
候選框口(x,y,w,h)中,(x,y)表示左上點(diǎn)坐標(biāo),(w,h)表示寬和高。
我們要將窗口的控制坐標(biāo)調(diào)整為:
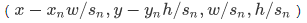
這項(xiàng)工作中,我們有種模式。偏移向量三個參數(shù)包括以下值:

同時對偏移向量三個參數(shù)進(jìn)行校正。
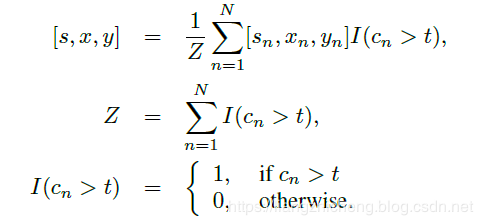
訓(xùn)練樣本應(yīng)該如何準(zhǔn)備?
人臉樣本;
非人臉樣本。
級聯(lián)的好處
最初階段的網(wǎng)絡(luò)可以比較簡單,判別閾值可以設(shè)得寬松一點(diǎn),這樣就可以在保持較高召回率的同時排除掉大量的非人臉窗口;
最后階段網(wǎng)絡(luò)為了保證足夠的性能,因此一般設(shè)計(jì)的比較復(fù)雜,但由于只需要處理前面剩下的窗口,因此可以保證足夠的效率;
級聯(lián)的思想可以幫助我們?nèi)ソM合利用性能較差的分類器,同時又可以獲得一定的效率保證。
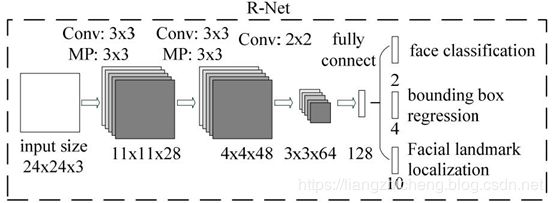
基于多任務(wù)卷積神經(jīng)網(wǎng)絡(luò)的人臉檢測(MTCNN)
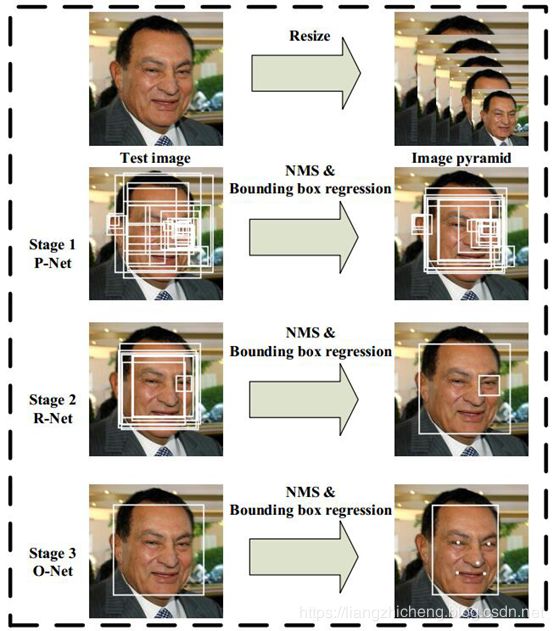
MTCNN 模型有三個子網(wǎng)絡(luò),分別是 P-Net,R-Net,O-Net。
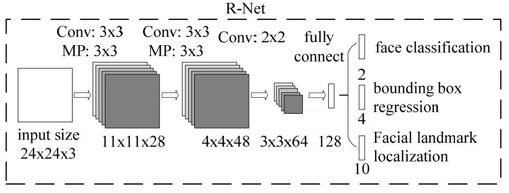
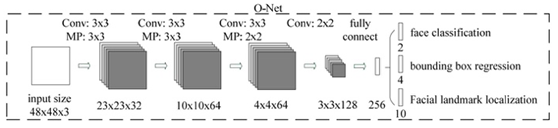
為了檢測不同大小的人臉,開始需要構(gòu)建圖像金字塔,先經(jīng)過 PNet 模型,輸出人臉類別和邊界框(邊界框的預(yù)測為了對特征圖映射到原圖的框平移和縮放得到更準(zhǔn)確的框),將識別為人臉的框映射到原圖框位置可以獲取 patch,之后每一個 patch 通過 resize 的方式輸入到 RNet,識別為人臉的框并且預(yù)測更準(zhǔn)確的人臉框,最后 RNet 識別為人臉的的每一個 patch 通過 resize 的方式輸入到 ONet,跟 RNet 類似,關(guān)鍵點(diǎn)是為了在訓(xùn)練集有限情況下使模型更魯棒。
還要注意一點(diǎn):構(gòu)建圖像金字塔的的縮放比例要保留,為了將邊界框映射到最開始原圖上。
Facebox
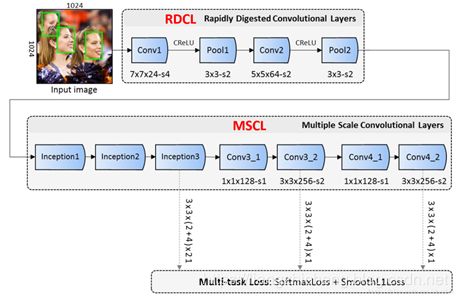
(1)Rapidly Digested Convolutional Layers(RDCL)
在網(wǎng)絡(luò)前期,使用 RDCL 快速的縮小 feature map 的大小。主要設(shè)計(jì)原則如下:
Conv1, Pool1, Conv2 和 Pool2 的 stride 分別是 4, 2, 2 和 2。這樣整個 RDCL 的 stride 就是 32,可以很快把 feature map 的尺寸變小。
卷積(或 pooling)核太大速度就慢,太小覆蓋信息又不足。權(quán)衡之后,將 Conv1, Pool1, Conv2 和 Pool2 的核大小分別設(shè)為 7x7,3x3,5x5,3x3。
使用 CReLU 來保證輸出維度不變的情況下,減少卷積核數(shù)量。
(2)Multiple Scale Convolutional Layers(MSCL)
在網(wǎng)絡(luò)后期,使用 MSCL 更好地檢測不同尺度的人臉。主要設(shè)計(jì)原則有:
類似于 SSD,在網(wǎng)絡(luò)的不同層進(jìn)行檢測;
采用 Inception 模塊。由于 Inception 包含多個不同的卷積分支,因此可以進(jìn)一步使得感受野多樣化。
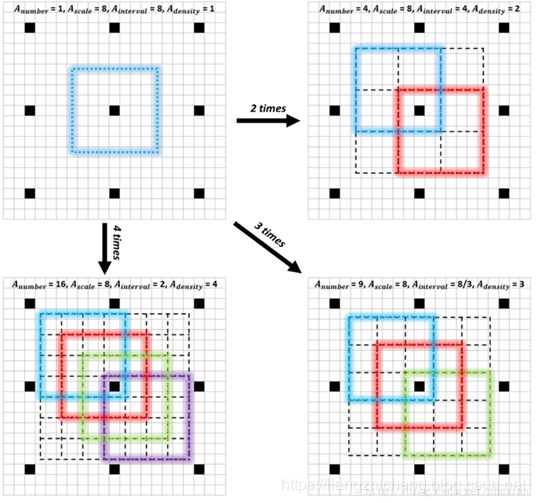
(3)Anchor densification strategy
為了 anchor 密度均衡,可以對密度不足的 anchor 以中心進(jìn)行偏移加倍,如下圖所示:
-
人臉識別
+關(guān)注
關(guān)注
77文章
4127瀏覽量
88457 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5598瀏覽量
124396
原文標(biāo)題:深度學(xué)習(xí)在人臉檢測中的應(yīng)用 | CSDN 博文精選
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
瑞芯微(EASY EAI)RV1126B 人臉檢測使用

穿孔機(jī)頂頭檢測儀 機(jī)器視覺深度學(xué)習(xí)
如何深度學(xué)習(xí)機(jī)器視覺的應(yīng)用場景
基于級聯(lián)分類器的人臉檢測基本原理
【Milk-V Duo S 開發(fā)板免費(fèi)體驗(yàn)】基于Duo S 使用 TDL SDK(V1版本)
【Milk-V Duo S 開發(fā)板免費(fèi)體驗(yàn)】人臉檢測
【HarmonyOS 5】VisionKit人臉活體檢測詳解
提高IT運(yùn)維效率,深度解讀京東云AIOps落地實(shí)踐(異常檢測篇)
基于RV1126開發(fā)板實(shí)現(xiàn)人臉檢測方案

基于RV1126開發(fā)板實(shí)現(xiàn)人臉檢測方案
基于RV1126開發(fā)板實(shí)現(xiàn)人臉檢測方案
基于RV1126開發(fā)板實(shí)現(xiàn)人臉檢測方案



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論